













LoveLive!出了一篇AI論文:生成模型自動寫曲譜

知名偶像企劃 LoveLive! 發 AI 論文了,是的沒錯。
最近,預印版論文平臺 arXiv 上的一篇論文引起了人們的注意,其作者來自游戲開發商 KLab 和九州大學。他們提出了一種給偶像歌曲自動寫譜的模型,更重要的是,作者表示這種方法其實已經應用過很長一段時間了。
通過深度學習技術,AI 算法在圖像分類,語音識別等任務上有了優異的表現,但在理解復雜、非結構化數據方面,機器學習面臨的挑戰更大,比如理解音頻,視頻,文本內容,以及它們產生的機制。物理學家費曼曾說過:「凡是我不能親自創造出來的,我就不是真正理解。」
而隨著技術的發展,深度生成模型已在學界和業界獲得了廣泛應用。在如今的游戲開發過程中,生成模型正在幫助我們構建各種內容,包括圖形、聲音、角色動作、對話、場景和關卡設計。
KLab 等機構提交的論文介紹了自己的節奏動作游戲生成模型。KLab Inc 是一家智能手機游戲開發商。該公司在線運營的節奏動作游戲包括《Love Live!學院偶像季:群星閃耀》(簡稱 LLAS)已以 6 種語言在全球發行,獲得了上千萬用戶。已經有一系列具有類似影響的類似游戲,這使得該工作與大量玩家密切相關。
在 LLAS 中,開發者面臨的挑戰是為不同歌曲生成樂譜,提示玩家在不同時機點擊或拉拽按鍵,這是節奏音樂游戲中所定義的挑戰。在一局游戲中,飄過來的按鈕被稱為音符,它們形成類似于樂譜的空間圖案,與后臺播放的歌曲節奏對應。一首歌曲存在不同的難度模式,從初級、中級、高級和專家到挑戰,復雜度順序遞增。

相對其他音游,LLAS 雖然不怎么考驗反應速度,但機制相對復雜得多在全部按準的前提下還有 buff、debuff、三種屬性分別對應體力、暴擊和分數,想要高分還需要在打歌時不停切換隊伍。
由于 LoveLive!是一個有 12 年歷史的企劃,包含四個團體和數個小團體,個人還有角色歌,很多歌曲都會在游戲中出現,設計對應的樂譜變成了一件極具挑戰的工作。
隨便一搜就上千首歌曲。
游戲開發者表示,他們的做法是通過 AI 輔助的半自動化方式:先由 AI 生成樂譜,再由 KLab 的藝術家進行微調,另一種方式是 AI 生成低難度樂譜,游戲設計師在這個基礎上設計高難度。
KLab 表示,他們使用的 GenéLive! 模型成功地降低了一半業務成本,該模型已部署在公司日常的業務運營中,并在可預見的未來時間里持續應用。
降低樂譜生成的成本對于在線音游開發者來說是一個重要挑戰,因為它是日常運營的瓶頸。KLab 提出的方法實現了只需要音頻,就可以直接生成樂譜。
在研究過程中,開發者們首先提出了 Dance Dance Convolution (DDC) ,生成了具有人類高水平的,較高難度游戲模式的樂譜,但低難度反而效果不好。隨后研究者們通過改進數據集和多尺度 conv-stack 架構,成功捕捉了樂譜中四分音符之間的時間依賴性以及八分音符和提示節拍的位置,它們是音游中放置按鍵的較好時機。
DDC 由兩個子模型組成:onset(生成音符的時機)和 sym(決定音符類型,如輕按或滑動)
目前正在使用的 AI 模型在所有難度的曲譜上都獲得了很好的效果,研究人員還展望了該技術擴展到其他領域的可能性。

論文鏈接:https://arxiv.org/abs/2202.12823
KLab 應用深度生成模型來合成樂譜,并改進樂譜的制作流程,將業務成本降低了一半。該研究闡明了如何通過專門用于節奏動作的多尺度新模型 GenéLive!,借助節拍等來克服挑戰,并使用 KLab 的生產數據集和開放數據集進行了評估。
方法
此前,KLab 樂譜的生成工作流是在不考慮自動化的情況下形成的,幾乎沒有達成明確的規則或數學優化目標。因此,該研究選擇使用監督機器學習。到 2019 年底,KLab 已經發布了數百首歌曲的音頻序列和相應的人工生成樂譜。
一方面,這個項目被要求快速交付并起到協助的作用;另一方面,項目的目標具有挑戰性,旨在改進 SOTA 深度生成模型。通常,研究新型神經網絡架構需要大量的反復試驗,這個過程需要六個月或更長時間。
為了解決時間上的問題,該研究組織了一個模型開發團隊和一個模型服務團隊,通過與藝術家團隊保持聯系獲得反饋,將其反映到模型開發和服務中,并在第一時間提供更新的模型,從而使他們保持一致。
GenéLive! 的基礎模型由卷積神經網絡 CNN 層和長短期記憶網絡 LSTM 層組成。對于頻域中的信號,作者利用 CNN 層來捕獲頻率特征,對于時域利用 LSTM 層來完成任務。
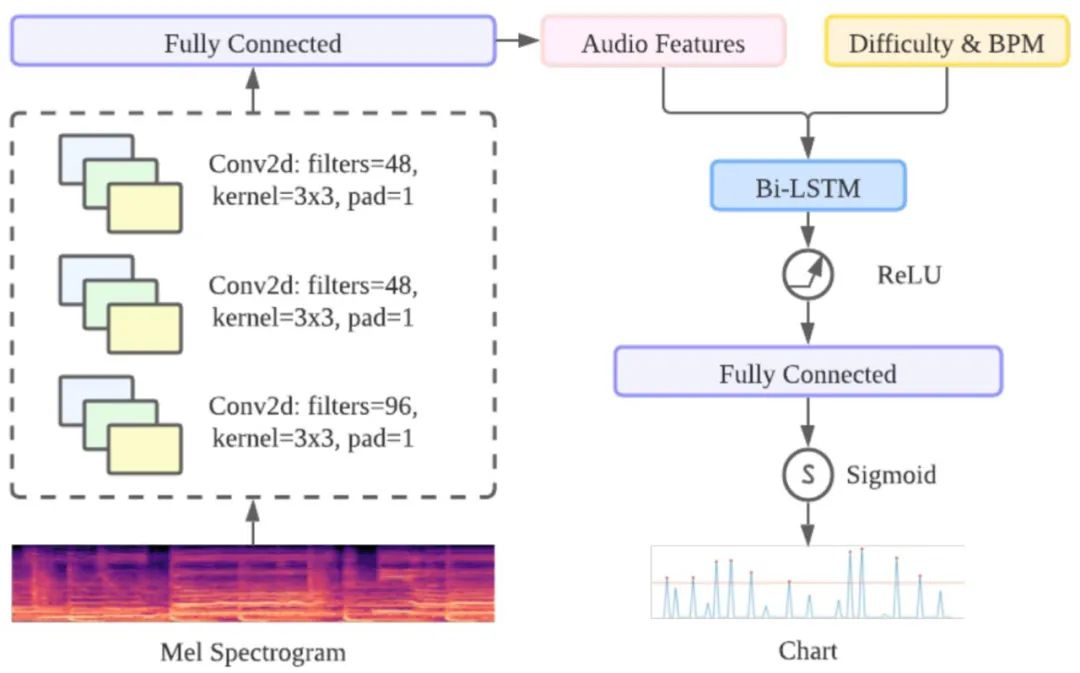
GenéLive! 的模型架構。
在這里,卷積堆棧(conv-stack)的主要任務是使用 CNN 層從 mel 頻譜圖中提取特征。conv-stack 包括一個具有批量標準化的標準 CNN 層、一個最大池化層和一個 dropout 層,激活函數是 ReLU。最后為了規范輸出,這里使用了全連接層。
時域方面采用了 BiLSTM,提供前一個 conv-stack 的輸出作為輸入。為了實現不同的難度模式,作者將難度編碼為一個標量(初級是 10,中級是 20,以此類推)并將這個值作為新特征附加到 convstack 的輸出中。
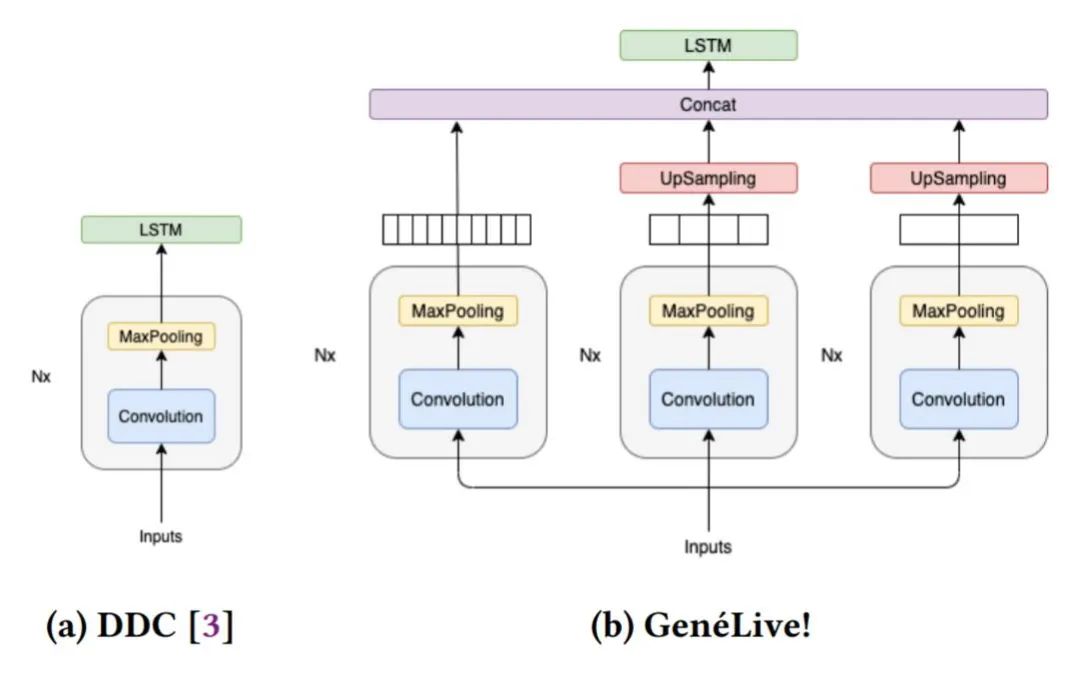
Conv-stack 架構。
在訓練數據方面,GenéLive! 使用了幾百首早期的 LLAS 歌曲,《歌之王子殿下》的歌曲,以及音樂游戲引擎「Stepmania」中可公開訪問的音樂和樂譜。
模型開發
該模型是由 KLab 和九州大學合作完成的。兩個團隊之間需要一個基于 Web 的協作平臺來共享源代碼、數據集、模型和實驗等。具體來說,該研究用于模型開發的系統架構如下圖所示。
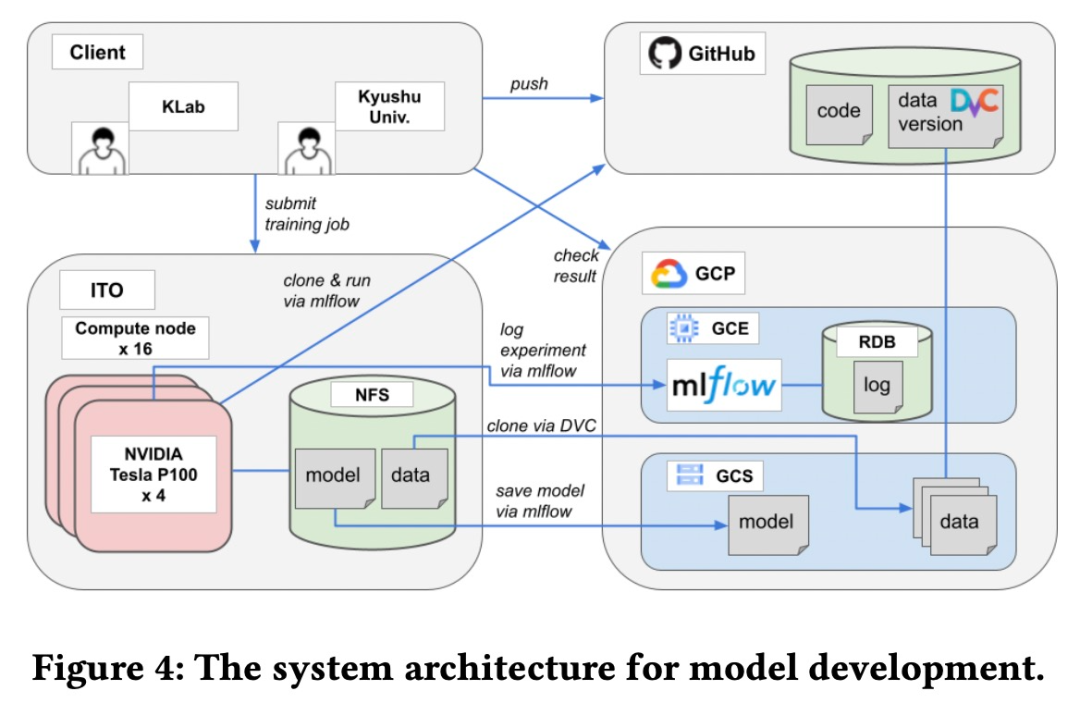
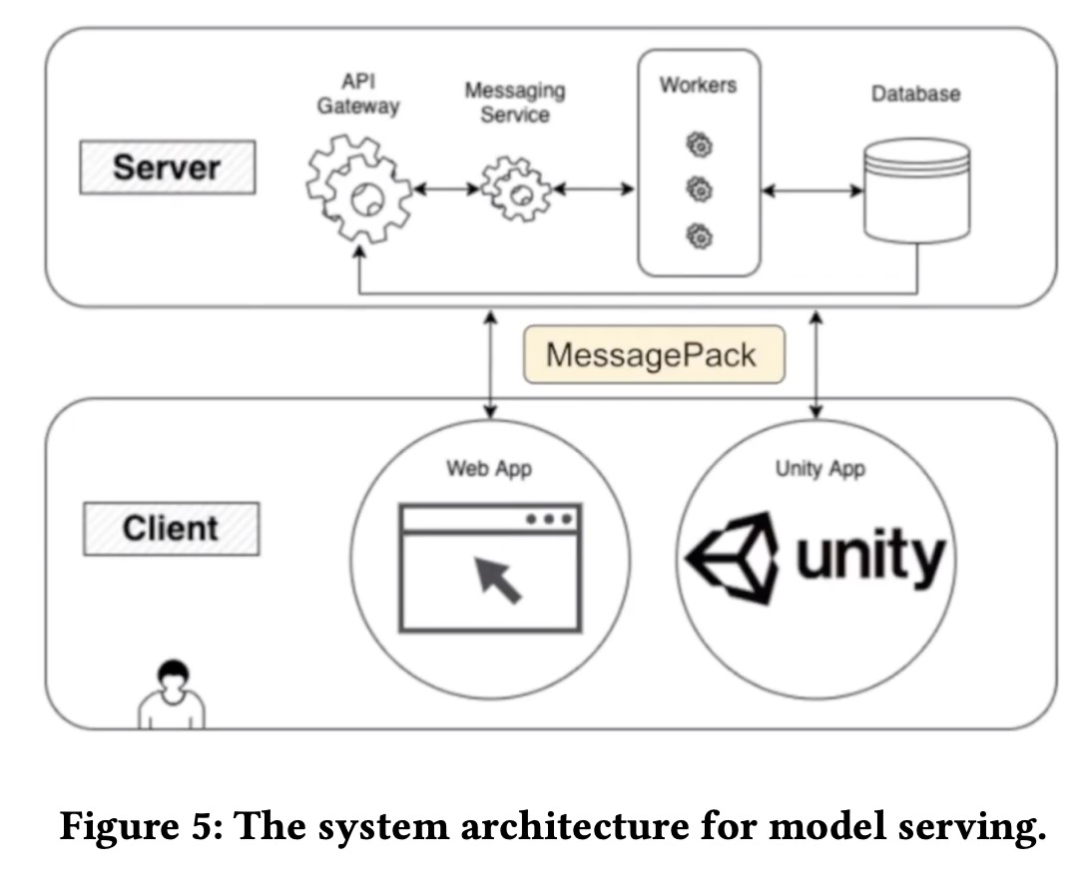
模型服務
為了使樂譜生成程序可供藝術家按需使用,它應該方便藝術家自行使用而無需 AI 工程師的幫助。并且由于該程序需要高端 GPU,將其安裝在藝術家的本地計算機上并不是一個合適的選擇。該模型服務系統架構如下圖所示。
實驗結果
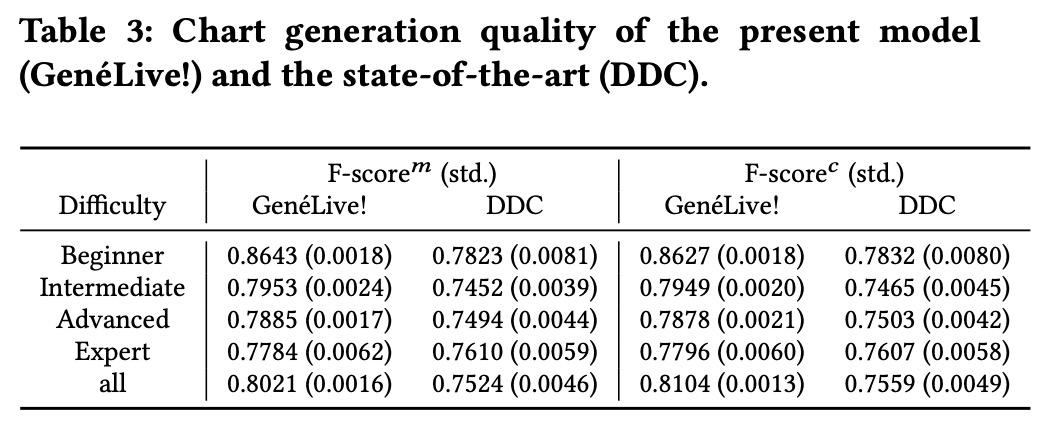
為了度量該方法中每個組件的性能,研究者在「Love Live! All Stars」數據集上進行了消融實驗。
下表 3 的結果表明 GenéLive! 模型優于此前的 SOTA 模型 DDC。
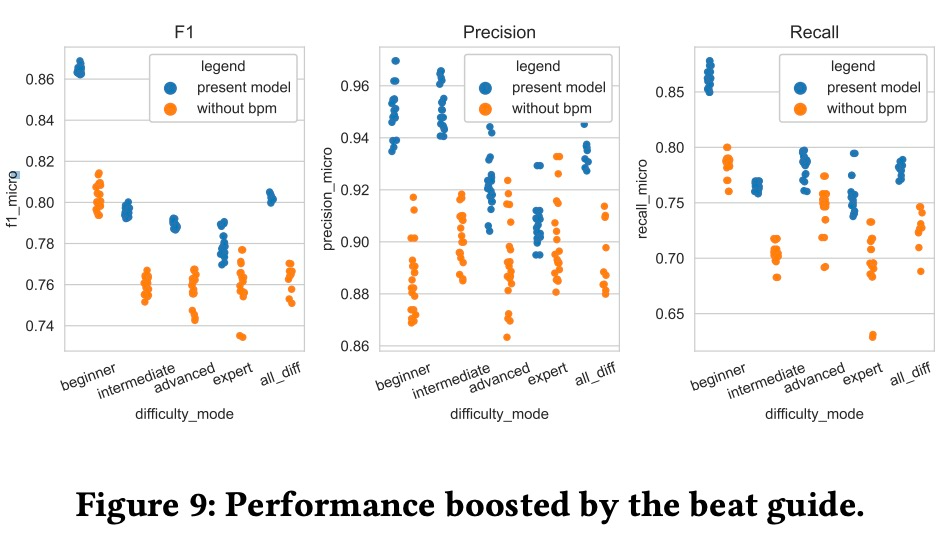
為了評估節拍指導的作用,消融實驗的結果如下圖 9 所示。
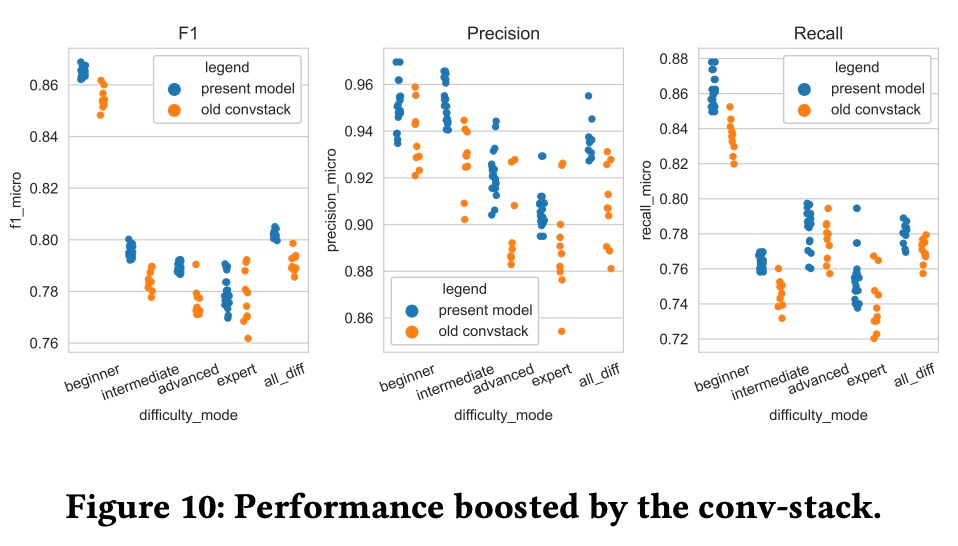
使用未修改版 conv-stack 訓練模型和當前 GenéLive! 模型的結果差異如下圖所示。
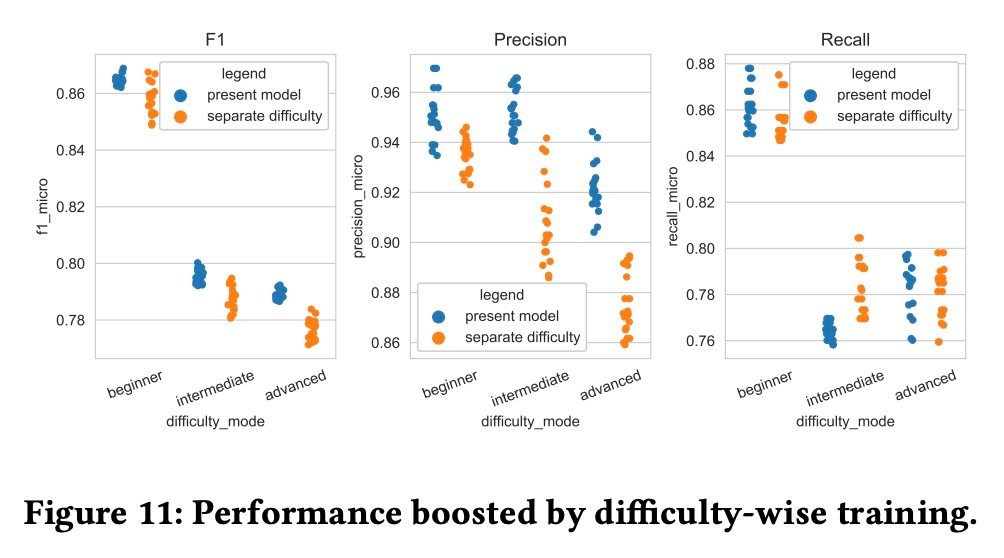
GenéLive! 模型一次性訓練全部難度模式,為了查看這種訓練方式的優勢。該研究將其與每種難度模式單獨訓練的結果進行了比較,結果如下圖所示。
LoveLive! 企劃的活動范圍包括動漫、游戲和真人偶像團體。音樂游戲《Love Live! School Idol Festival》自 2013 年開始運營,截至 2019 年 9 月在日本擁有超過 2500 萬用戶。新一代的游戲《Love Live! School Idol Festival All Stars》目前在全球已有上千萬用戶。
GenéLive! 的研究,說不定也能讓音游在 AI 領域里火起來。
























