













Spark 在供應鏈核算中的應用總結
一、業務背景
(會計)核算是使用會計語言與方法,對產品業務的結果進行登記與反映,從而為利益相關者提供直觀、準確、有價值的信息,主要服務對象是財務、審計、外部監管、合規以及管理層,同時核算也是資金管理風險防范的其中一個手段。整體流程可以概括為基于核算規則從業務事件(采購入庫、退供、TOC確認收貨、開票等)關聯單據中提取業務要素(采購/銷售主體、業務時間、客商、金額等)轉換為會計語言表達的數據(會計分錄,會計要素主要包括OU/收益部門/預算部門/往來段/明細段/行業段/成本中心等),供應鏈核算主要鏈路如下圖所示:
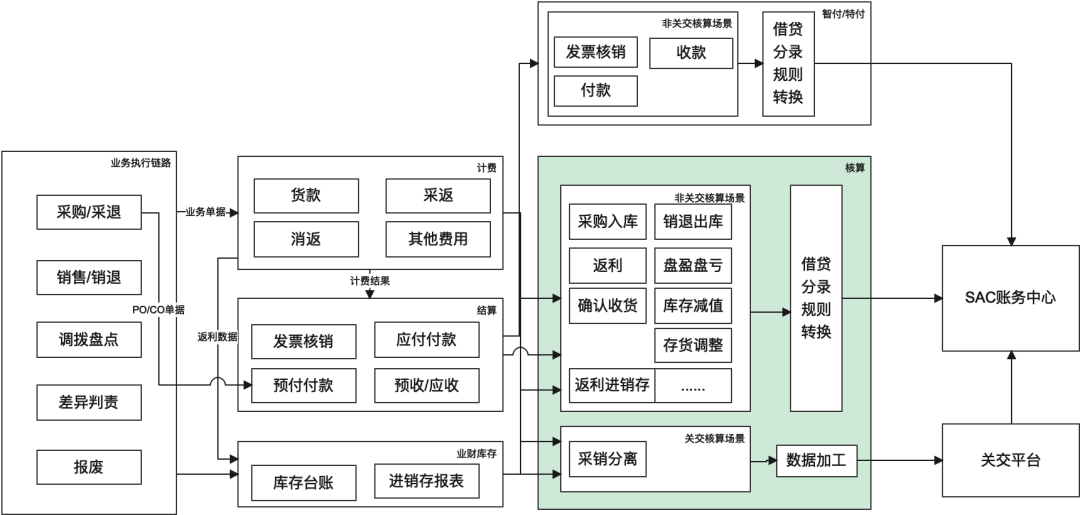
從上圖可以看到供應鏈核算一腳在業務(計費/結算可以理解為財務視角的業務),一腳在財務,職責上既要滿足核算團隊月結出賬的訴求,又要提供業財對賬的能力,基于此我們將數據處理統一為如下流程:

二、離線 SQL 模式存在的問題
從第1章節圖2可以看到,核算的流程就是ETL的過程,在早期的方案中通過離線+在線的實現方式,其中離線完成原始憑證的加工,業務接入的邏輯通過SQL實現,在線系統完成記賬+拋賬,同時由于在線系統處理能力有限,在原始憑證加工中進行了業務單據的聚合,此種實現方式主要存在以下問題。
1.對賬問題定位困難,核算小二主要通過下載分錄及對應的業務單據匯總數據進行對賬,如果某一分錄和業務數據有出入,只能逐一業務要素分析,由于缺乏通過分錄精確追溯到關聯業務單據的下鉆能力,問題定位耗時較長,造成這一問題的主要原因在于通過離線SQL實現的原始加工邏輯無法精確的建立業務單據和原始憑證的關聯關系。
2.日常運維困難,隨著業務的不斷發展,業務接入離線任務在不斷的膨脹,最終成為一個橫跨4個項目空間,150+離線任務、100+離線表的工程,任一節點的錯誤都會造成月結數據出錯。
3.行業實施效率較低,每次新接入行業都需要開發小二新建一套離線表+離線任務,相應的也造成運維問題的持續惡化。
三、為什么選擇Spark
1.核心訴求
在核算主版本的建設中,我們希望能夠通過打造穩定可復用的產品能力最大程度的解決上述問題,核心訴求如下:
1)核算規則(業務接入/記賬/拋賬)可配、可視,不存在黑盒的加工邏輯,加工流程對核算小二全透明(提升實施+對賬效率)
2)建立整個核算鏈路單據維度的關聯關系(業務單據<->原始憑證<->記賬憑證<->拋賬憑證),具備雙向的單據追溯能力(提升對賬效率)
基于以上訴求,我們抽象了標準的規則模型,滿足用戶多場景下各個鏈路(業務接入、記賬、拋賬)的加工邏輯配置(規則相關設計方案不再此文展開),與之配套的會計引擎完成基于核算規則的數據處理,另外在主版本的設計中,原始憑證需要1V1還原業務單據,每月原始憑證數據量達到了10億級別,為了滿足月結時效性的要求,我們需要采用高性能、支持大數據量、且編程友好(便于建立單據關系)的計算引擎。
2.Spark VS MapReduce
基于上述訴求,我們重點調研了Spark和MapReduce兩款計算引擎,差異如下所示:
引擎 | MapReduce | Spark |
編程友好 | 一般,支持Map/Reduce兩種算子 | 較好,支持的算子豐富(map/filter/reduce/aggregate等) |
性能 | 一般,中間態數據需要落盤,計算邏輯相對復雜時,MapReduce會涉及到多MapReduce任務執行(多次shuffle),每次shuffle也會涉及到大量的磁盤IO | 較好,基于內存計算,基于DAG可以構建RDD的血緣關系,在調度過程中可以避免大量無效的磁盤IO,另外rdd共享機制可以降低網絡IO的開銷 |
集團生態 | 較好,odps提供MapReduce計算框架支持,可以通過LogView查看日志 | 較好,odps提供Spark計算引擎支持,可以通過LogView查看日志,目前提供了stand-alone、集群及client三種模式的支持 |
比較形象的對比(并不是說spark不會落盤,在基于DAG圖拆分stage時,也會涉及到shuffle,但整體的磁盤IO消耗比MapReduce要低)。
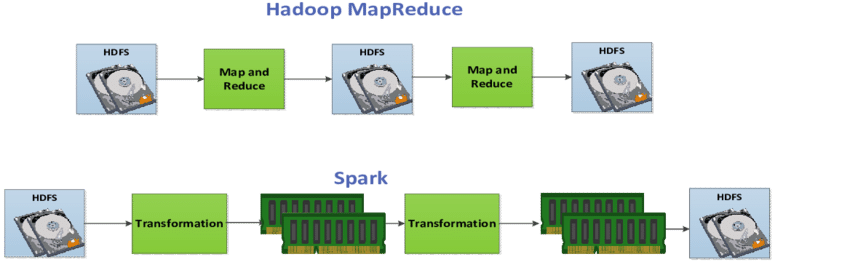
3.編程模式優勢: RDD + DataFrame 的編程模式
如上面和MapReduce的比較中看到 Spark 在編程友好性上比MapReduce好一些,比較適合后端開發人員。
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
// Create an RDD
val peopleRDD = spark.sparkContext.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// Generate the schema based on the string of schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Convert records of the RDD (people) to Rows
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Apply the schema to the RDD
val peopleDF = spark.createDataFrame(rowRDD, schema)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL can be run over a temporary view created using DataFrames
val results = spark.sql("SELECT name FROM people")
上面是一個官方的例子,在schema控制,可編程性和 sql 操作等能較好的結合,邏輯比較類同后端開發。
基于上述spark特點及優勢,我們最終選擇spark實現會計引擎邏輯。
四、spark基礎介紹
1.基礎概念
- Rdd(Resilient distributed dataset):不可變的彈性分布式數據集(不可變性似于docker中的只讀鏡像層),只能通過其他的transformation算子創建新的RDD。
- Operations:算子,spark包括兩類算子,transformation(轉換算子,通過對前置rdd的處理生成新的rdd)/action(觸發spark job的拆分及執行,負責將rdd輸出)。
- Task:執行器執行的任務單元,一般基于當前rdd的分區數量拆分。
- Job:包含多個task的集合,基于Action算子拆分。
- Stage:基于當前rdd處理邏輯的寬窄依賴拆分,spark中非常重要的概念,stage的切換會涉及到IO。
- Narrow/Wide dependencies:參考下圖,區分的重要依據在于父節點是否會被多個子節點使用。

2.Spark on MaxCompute(ODPS)
我們在實踐中,主要基于spark on odps提供的client模式實現,client模式的詳細介紹可以參考相關文檔。
- Spark 有很多的后端的 Runtime,例如其商業化公司的Databricks Runtime, 彈內我們使用的是 AliSpark,是集團的適配MaxComputer,同時在離線交互是使用了 Cupid-SDK 的 Client模式,這個模式不是獨立集群的模式,類Serveless模式,整體的成本上比獨立集群要低,當然資源保障上沒有獨立集群好。
Client模式原理參考相關文檔,比調度模式有更好的應用交互性。
- 集團client模式將spark session作為服務提供,可以方便地與在線系統交互,包括任務的提交、關閉、實例的關閉等;
- 在使用集團提供的spark能力時,比較麻煩的在于如何方便的查看日志,從我們的實踐看主要有以下2個路徑。
申請odps對應項目空間的logview權限,可以直接在https://logview.alibaba-inc.com/中基于sparkInstanceId定位到具體的日志;
借助odps client+提交spark任務時返回的實例ID獲取log地址,代碼參考如下:
//instanceIdd對應odps client中的lookupName
Account account = new AliyunAccount(sparkSessionConfig.getAccessId(), sparkSessionConfig.getAccessKey());
Odps odps = new Odps(account);
odps.setEndpoint(sparkSessionConfig.getEndPoint());
odps.setDefaultProject(sparkSessionConfig.getNamespace());
//日志地址目前設定有效期為7*24小時
try {
return odps.logview().generateLogView(odps.instances().get(sparkInstanceId), 7 * 24L);
} catch (OdpsException e) {
LOGGER.error("生成logView地址失敗,config:{},instanceId:{},e:{}", sparkSessionConfig, sparkInstanceId, e);
}
五、技術方案
1.整體方案
spark作為大數據處理引擎,在實例數量較少的情況下采用odps任務目前的運維方式來管理的話成本并不高,但是在供應鏈核算的場景下,需要支持每天將近600+(行業*核算場景)數量的實例運行,且需滿足核算完整性、準確性、及時性的要求,另外由于目前我們的spark任務(cupid)與odps任務共享項目空間資源,意味著我們需要在有限的資源下支持核算的業務,基于以上背景及訴求,供應鏈核算整體的應用架構設計如下:
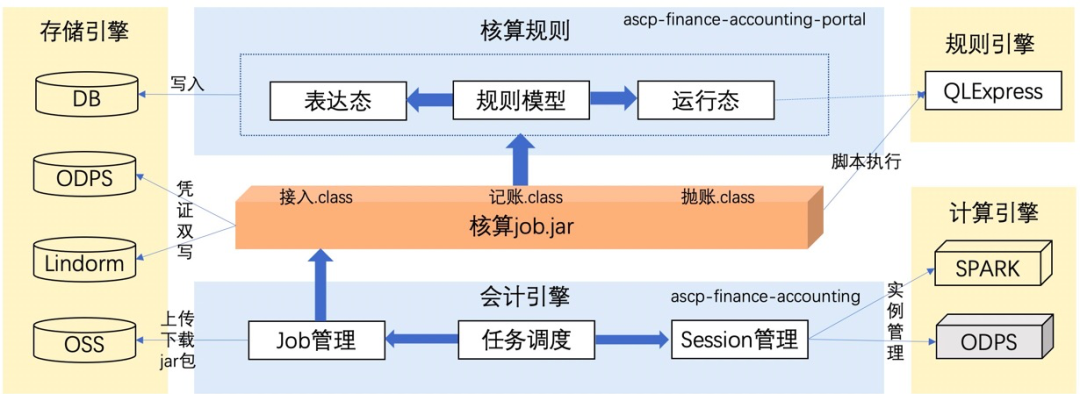
其中ascp-finance-accounting負責任務調度,組件交互如下:
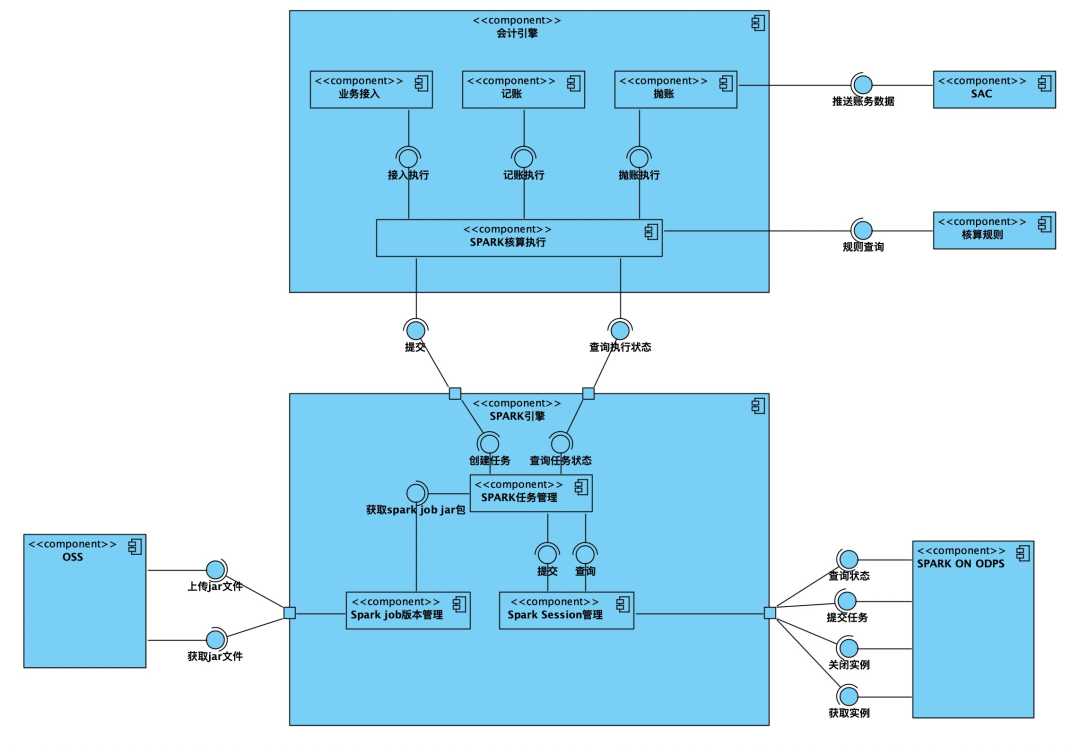
- spark任務管理:負責spark任務相關生命周期的管理,承接核算任務和spark session之間的交互;
- spark session管理:負責spark實例的創建、銷毀、job提交等,另外針對不同類型的session,支持自定義所需資源,包括實例worker數量、分區大小等,主要與spark on odps交互;
- 核算任務管理:負責業務接入、記賬、拋賬等核算任務的生命周期管理;
- spark job版本管理:spark任務所需jar包會不斷的迭代,針對不同的核算場景可以定制所需的job版本。
ascp-finance-accounting-spark負責spark job的開發維護,spark on odps client模式下需要基于服務上傳jar包,若jar包較大,性能較差,所以基于client模式下提供的resource管理能力,我們將項目module拆分如下:
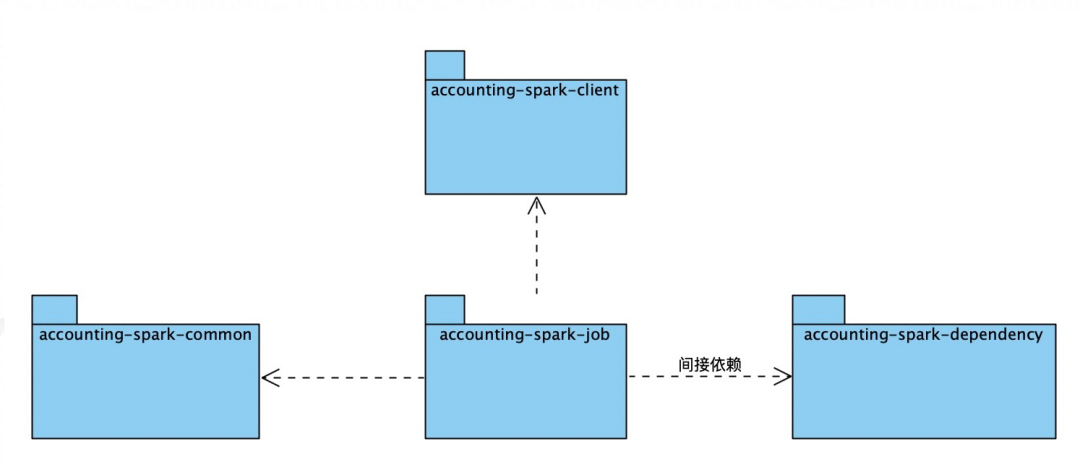
包名 | 作用 |
accounting-spark-client | 對外提供spark任務的啟動、查詢及終止服務 |
accounting-spark-common | 公共包,包括常量、工具類等 |
accounting-spark-job | spark任務包,封裝了任務接入和記賬兩個任務的實現 |
accounting-spark-dependency | spark任務包依賴的二方包,client模式下若job包過大,會造成上傳失敗的問題,所以部分job依賴的二方包可以放在dependency中,單獨打包,手工在datawork中上傳,通過resources傳遞參數 |
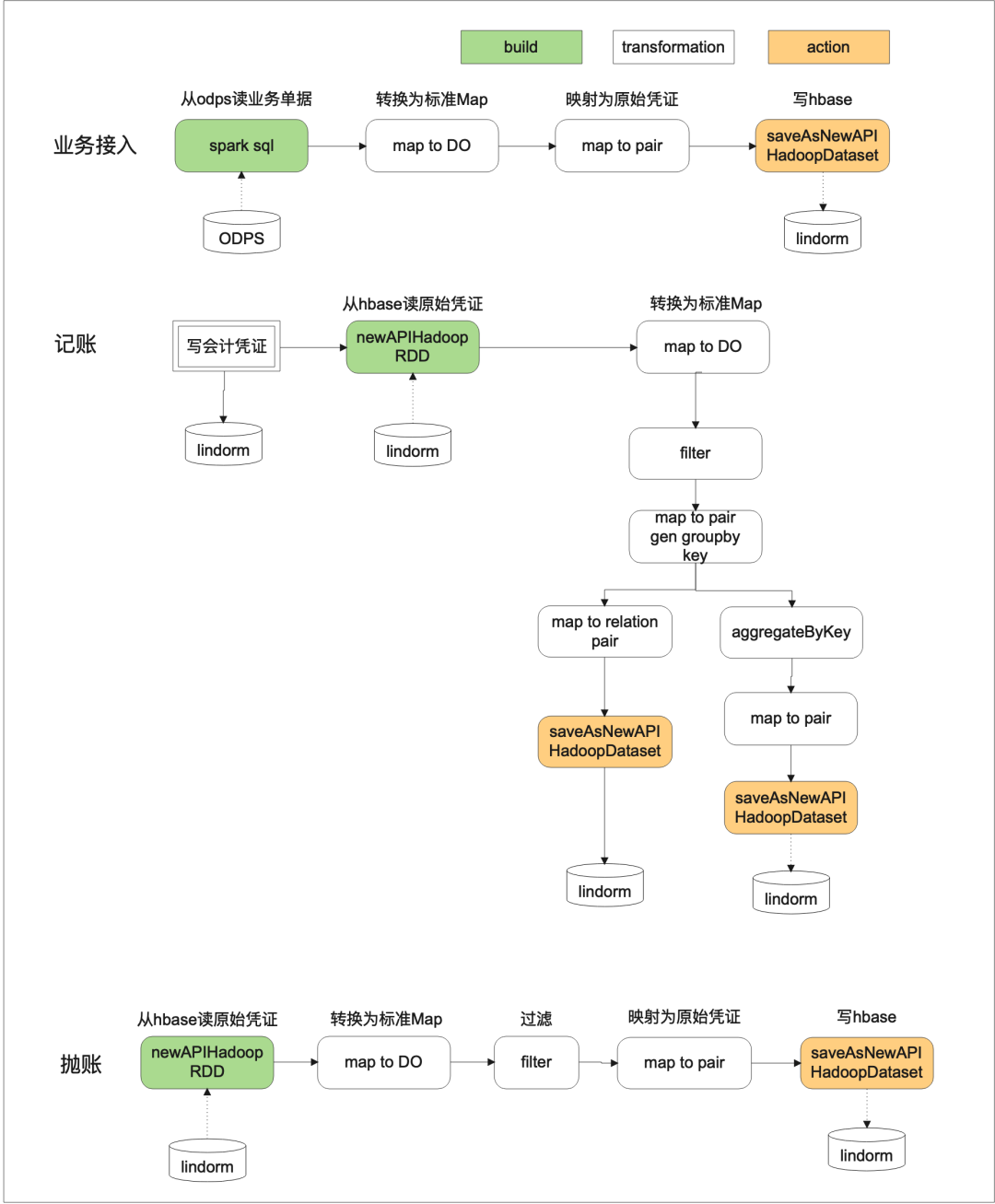
2.數據處理流程
核算接入、記賬、拋賬等主流程的spark處理邏輯如下所示:
六、運維及調優
基于spark的特性,完成數據處理邏輯的編寫對我們來說并不困難,問題主要集中在如何用盡可能低的成本滿足業務需求,特別是在目前控制成本的背景下,在供應鏈核算的落地過程中,我們主要采用了以下優化方式。
1.數據量評估
spark任務的運行效率很大程度上受到分區數量的影響,spark提供了如下手段來進行分區數量的調整(部分為spark on odps能力),供應鏈核算在實現過程中主要用到了odps離線表和lindorm兩種數據源。
1)spark.hadoop.odps.input.split.size:用于設置spark讀取odps離線表的分區大小,默認為256M,在實踐過程中需要結合當前分區的大小進行調整,比如當前分區大小為1GB,那么默認情況下會拆分為4個分區;
2)spark讀寫lindorm(類hbase)的分區數主要受到region數量的影響,在供應鏈核算系統的實踐中,由于初始region數量較少,導致分區數量很少,spark執行效率很差,針對此問題我們實踐了兩種處理策略;
- 進行重分區(repartition算子):針對數據傾斜進行重新分區,但是會拆分stage,觸發shuffle,增加額外的IO成本。
- lindorm進行預分區,比如預分區為128個region,但此種實現方案需要結合rowkey的設計一起使用,會影響到scan的效率。
2.代碼邏輯相關job/stage/task評估
除了六中所述數據量以外,數據處理邏輯的實現方法也會影響到任務的執行效率,spark比mapreduce執行效率高的一個原因就在于spark會先基于處理流程構建DAG,這樣可以有效評估每個stage是否需要落盤(IO成本),在邏輯實現過程中我們在保證數據處理無誤的情況下需要盡可能得降低IO(減少shuffle),比如可以執行以下策略。
- 慎用效率角度的算子,比如groupBy。
- 盡量減少stage數量。
3.計算存儲資源評估
計算存儲資源同樣是spark執行效率優化的關鍵,spark也提供了多種手段來調整資源的使用情況;
- spark.executor.instances executor:設置當前實例的worker數量;
- spark.executor.cores:核數,每個Executor中的可同時運行的task數目;
- spark.executor.memory:executor內存。
4.其他參數
odps.cupid.clientmode.heartbeat.timeout 此配置用來調節cupid(spark on odps) client模式下的心跳超時時間,默認為30分鐘,若任務執行較長,需要進行調整。
hbase.client.write.buffer:用來調節lindorm的flush磁盤的buffer大小,lindorm mput數量限制為100(經咨詢為全局限制,無法調整),所以在spark寫lindorm時我們主要采用此配置項調節批量寫入的數量,這點比較坑。
spark.hadoop.odps.cupid.job.priority:用于調節任務資源獲取的優先級。
5.Spark UI
spark 本身的 UI 中有整體的job/stage/task的可視化分析數據,比較方便的查詢到對應的執行過程,如下圖:
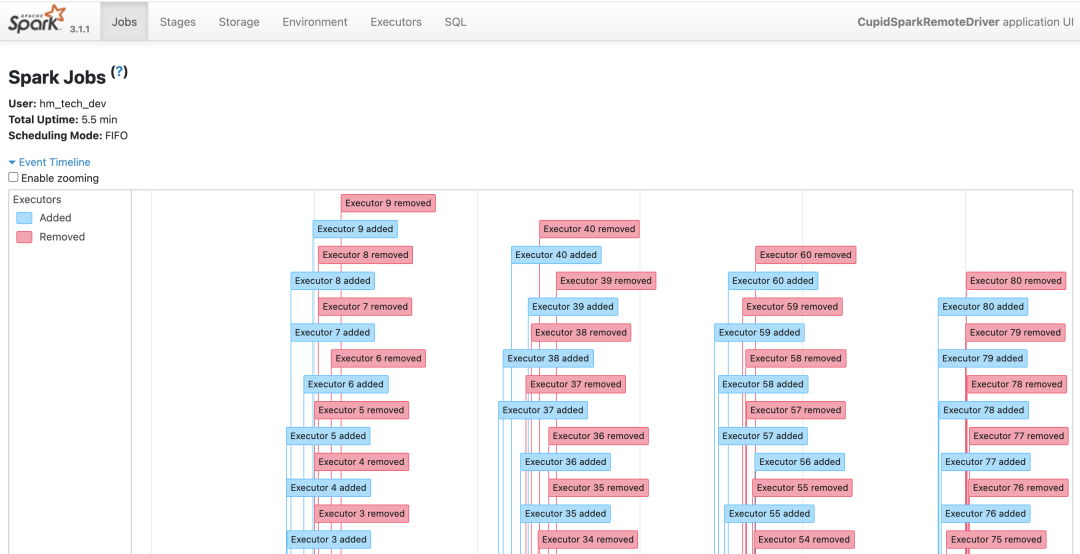
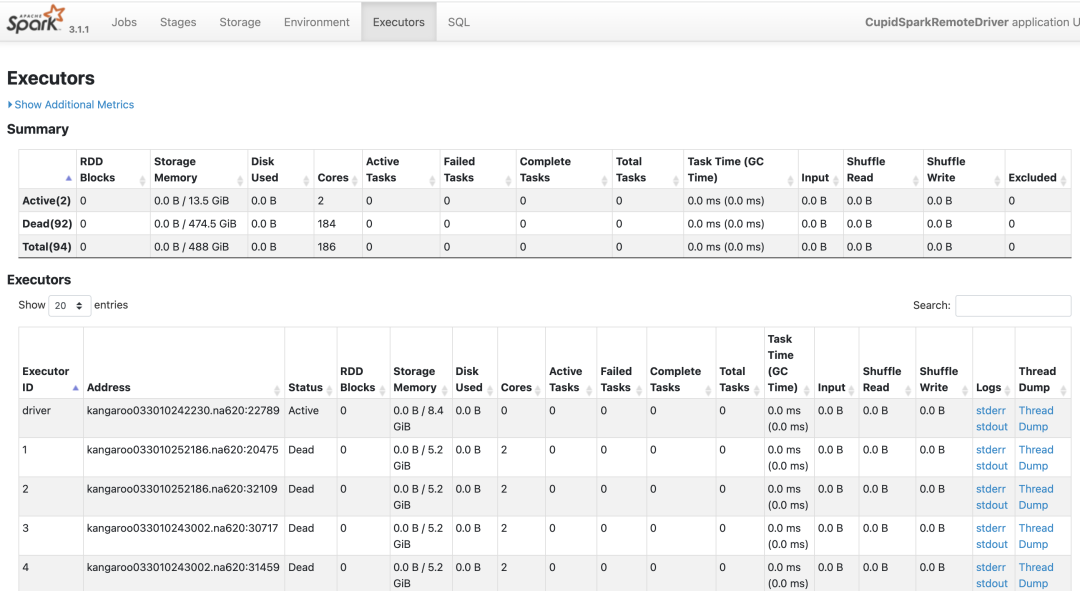
通過SparkUI 可以看到任務的驅動步驟和對應的執行的日志。通過分析可以針對性的優化提升。
6.交互式開發測試
ODPS 有一個非常好的所見所得的 dataworks 平臺,大大提升了開發的效率,spark 當前在dataworks沒有直接的交互的IDE,需要通過 zeppelin 來實現。zeppelin在數據技術棧中的定位如下:
Web-based notebook that enables data-driven,interactive data analytics and collaborative documents with SQL, Scala, Python, R and more.
可以在交互中實現結果的快速反饋。
支持 scala 的 UDF 驗證等,提升了測試驗證效率。
7.效果
經過以上優化,在2500萬數據量60worker數的場景,接入+記賬+拋賬流程由之前的2小時提效至10分鐘,同時在編程模式上更加匹配服務端技術的研發模式,提升了研發效率。
七、總結
核算業務的特征比較偏向數據和規則的處理,大數據引擎的引入有助于整體業務的交付效率提升和成本降低。目前我們對Spark的認知主要在完成數據處理邏輯開發及日常的調優上,隨著運行實例的增多以及業務的不斷發展,當前的技術方案也會不斷的迭代演進。
參考文檔
通過spark訪問lindorm:https://help.aliyun.com/document_detail/174657.html


























