?數據集擁有自己的世界觀?不,其實還是人的世界觀
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
伴隨深度學習的不斷日常化,數據集中的偏見(bias)和公正性(fairness)已經成為一個熱門研究方向。
偏見在AI領域是一個很棘手的話題:有些偏見是有益的,例如噪聲數據可以增加模型的魯棒性,有些偏見是有害的,例如傾向對有色人種識別錯誤。
而且,當我們得到一個不完美的模型的時候,其中的數據集到底存在什么偏見?這些偏見是如何產生的?
谷歌的PAIR (People + AI Research)團隊最近發表了一篇博文,用一個很簡單有趣的例子討論了這些問題。

原文鏈接:https://pair.withgoogle. com/explorables/dataset-worldviews/
1 有偏見的分類
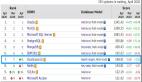
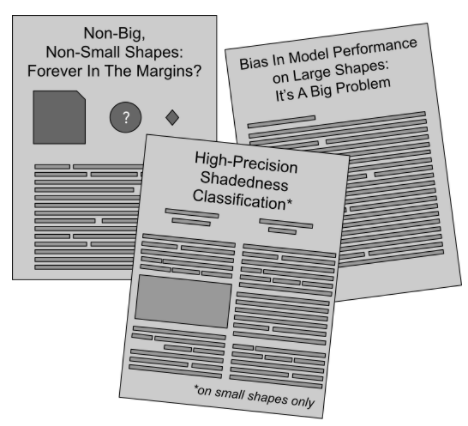
假設我們擁有如下所示的不同形狀的數據集,它們對應的標簽是有無陰影,如下圖。

利用頁面上的交互式分類器,可以分類出如下的結果,并得出相應的準確性。
模型并不完美,為了對結果進行糾正,你可能想知道模型正在犯什么錯誤,或者,數據存在哪種類型的偏見?
2 公正性分析
由于各個圖形的主要區別在于形狀,一個可能的偏見存在于形狀的差別。通過觀察你可能認為三個最主要的形狀主要是圓、三角形和矩形。為了證實這個假設,你要確信你的模型在面對圓、三角形和矩形的時候模型的表現能力的一樣的。接下來我們來做公正性分析(fairness analysis)。
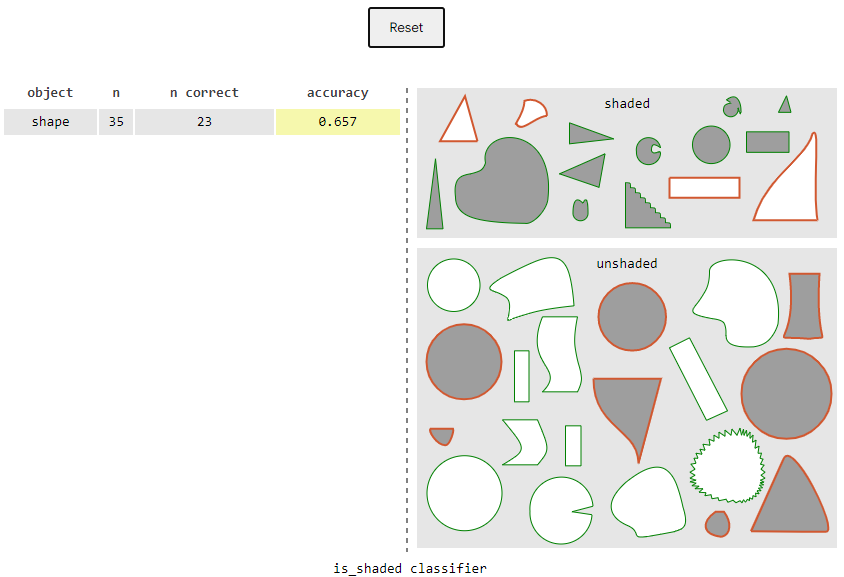
首先我們需要對每個的形狀進行標注,但是一個問題是,有些形狀并不能很肯定地確定是什么形狀,這時候有兩種策略,一是把這種形狀判斷為最有可能是圓、三角形和矩形(with their best guess);一種是給出一個選項:上述三種形狀都不是(as "other")。之后我們分析模型對于每一類形狀的分類準確率。該交互式頁面給了兩種策略的結果:
策略一:尋找最有可能的形狀:
第一種策略表明分類器對于矩形分類的結果最好,圓次之,三角形最差。不過這可以表明模型對三角形存在偏見嗎?我們在頁面上切換第二種策略。
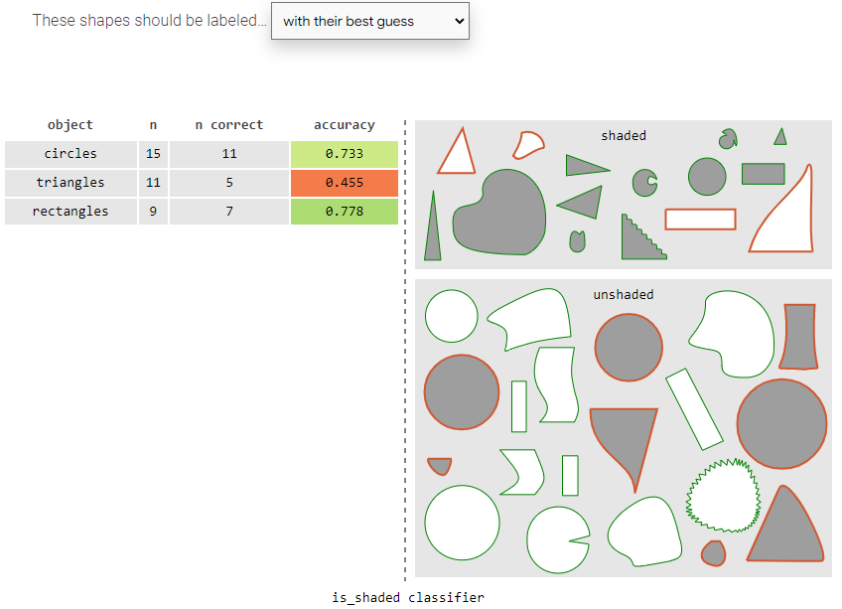
策略二:上述都不是:
結果發生了變化!第二種策略則表明分類器對于三角形和矩形分類結果都最好,圓卻最差。我們對于偏見的理解因為我們制定分類的策略不同而不同,換言之,每一種分類方式代表著采取不同的角度看待哪些是重要的分類特征。而決定數據集和最終模型決策的是你——制定策略的人。也就是每個數據集都代表一種“世界觀”,其收集背后莫不代表著人的意志。
所以,再回過頭來想想,還有哪些策略或者規則的指定可能會影響我們的對于公正性的判斷?
對,我們當初對于分類的標準是依照形狀,比如圓、三角形或者矩形,這也是我們人為定的標準,如果換成”尖的“或者”圓的“呢?或者“小的”或者“大的”呢?下圖給出了不同評價標準下,正確和錯誤分類的個體:
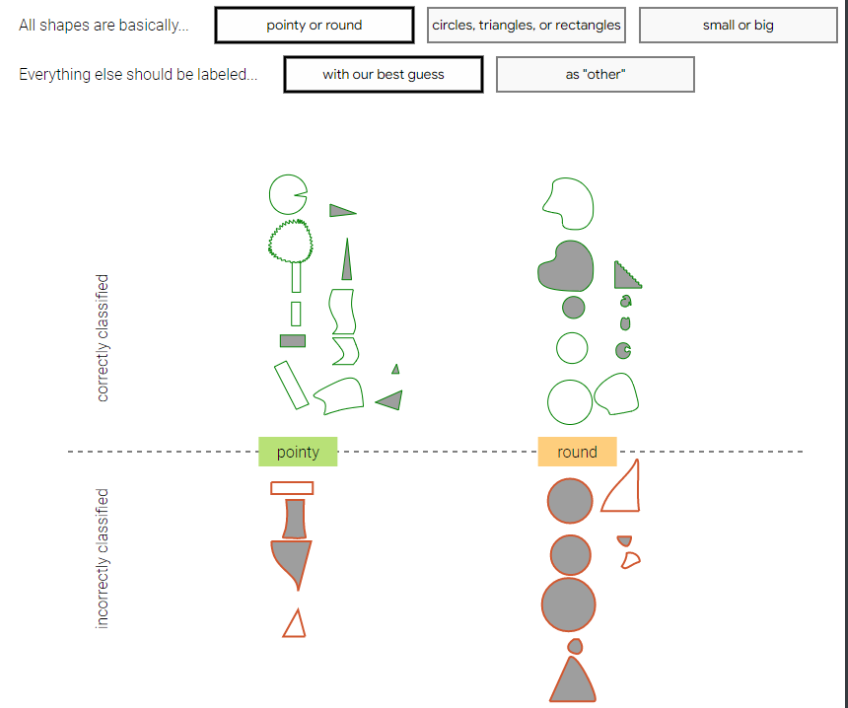
圖注:當類別標準是“尖的”或者“圓的”,以及其它模糊類別是“尋找最有可能的形狀”的時候的分類結果
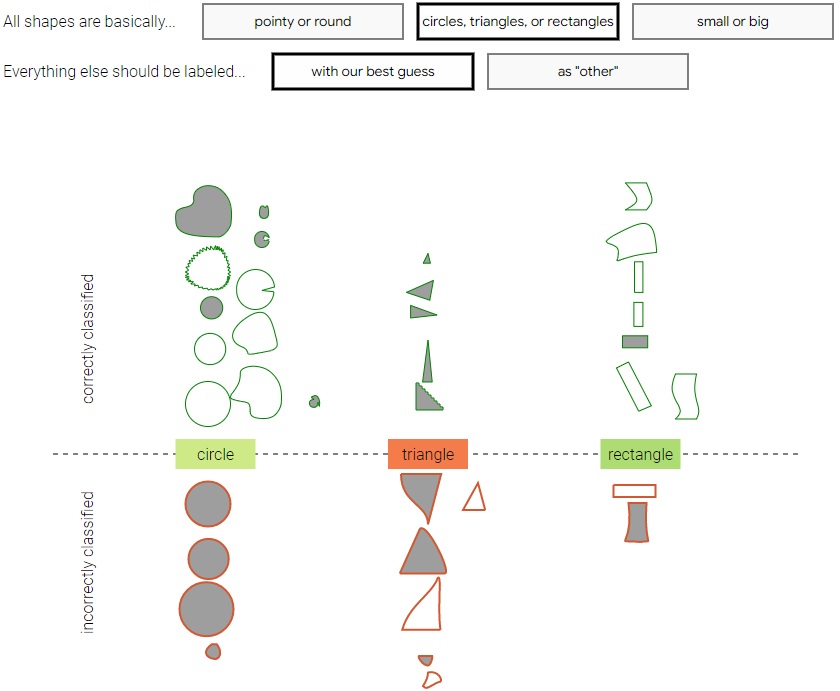
圖注:當類別標準是“小”或者“大的”,以及其它模糊類別是“尋找最有可能的形狀”的時候的分類結果
可以看到,每當選擇一種標準的時候,所得到的錯誤分類的數據分布也都不同,因而每種情況下對于實例的偏見程度或者公正性分析也都會出現偏差——偏見似乎也有了偏見。
3 標簽在講述故事
回顧一下,假設你是收集該數據集的負責成員,剛開始你做出關于與偏見相關的分類類別的決策,所有的形狀實例到底怎么分?你按照“尖的”和“圓的”,也就是下圖:

其它標注者試圖回答下述問題:這個圖形是“尖的”還是“圓的”?
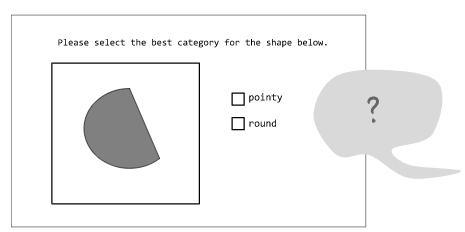
之后,收集完畢,你根據上述錯誤類別分析,你可以得到分類器在尖的形狀表現的好,圓的則表現的差,之后便有了如下的報告:
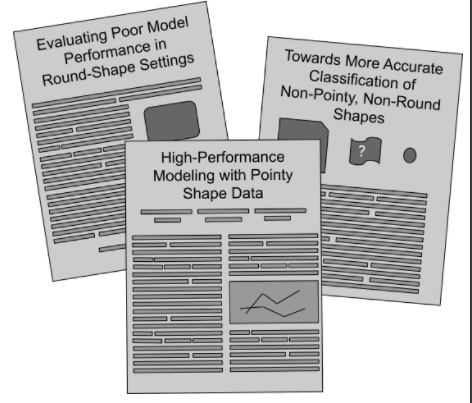
然后,如果一開始的評價標準是“大的”還是“小的”,重復上述步驟,你卻可以得到分類器在小的形狀上分類效果好,于是便有了這樣的故事...
想要避免這個問題的一個自然的解決方式是,收集更多的數據和更多的特征:如果我們有足夠多的數據,知道它們足夠多的細節,我們將可以避免做出不同的分類決策,從而產生唯一的偏見的影響因子。
不過,似乎并非這樣。想象一下,當我們描述我們周圍的一件事情的時候,不管是向一個朋友講述一件事情的時候,還是告知計算機關于形狀的事情的時候,我們都會自覺不自覺地選擇自己認為的最重要的部分,或者選擇用什么工具去傳遞它。
不管我們是否這么想,我們無時無刻不在做分類——
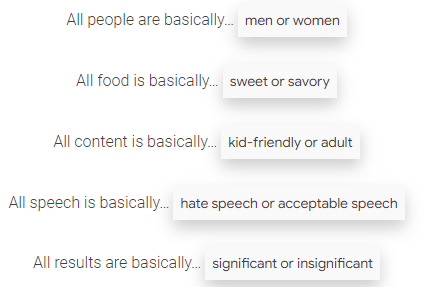
正如我們在形狀的例子中所看到的那樣,所有的選擇都使得某些特征比其它的特征更加重要,使得一些特征的差別是可見的一些卻可被忽略,都使得某些事物變得容易分類有些成為噪聲點。
是分類的標準在講述整個故事。
4 真實的場景
如果我們再回顧真實的機器學習應用,比如監督學習任務中的目標檢測任務。我們想象有下面一幅圖片:

我們想在這樣的數據集上打標注,因而我們想先對其中的目標物體進行標注。其中的一種標注如下:
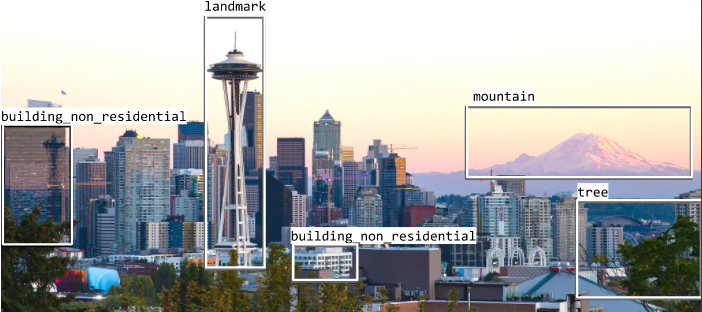
這樣已經看起來很客觀了,對嗎?畢竟山就是山、樹就是樹。可是即使這樣,同一張圖的同一個區域的標簽也可能不一樣,比如這樣:
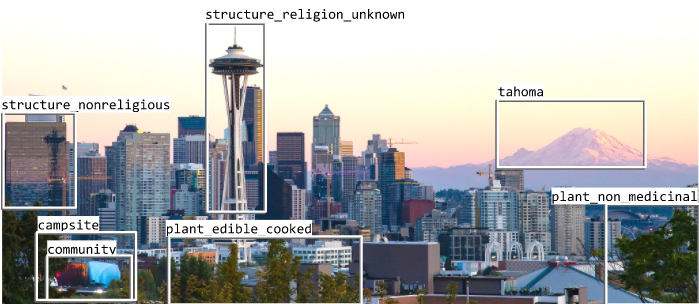
山可以具體化名稱,樹也可以具體化“沒有醫用的植物”。
是的,并沒有一個普遍的方法去對待每一個物體、每一個單詞或者每一張圖片。數據集總是特定時間空間和條件的結果。它們是社會的產物,它們有歷史觀,它們有政治色彩。而忽略這些會帶來非常現實的后果。
那我們應該怎么對待這些信息呢?
一個很好的起點是反思數據所在的上下文,并且始終對數據保持好奇。
很難去判斷一個數據集本身的價值——它們是客觀的,普遍的,中立的嗎——它可能只是反映一種你自己習慣的世界觀。所以理解你自己的世界觀可以告訴你所謂客觀數據的局限性。時刻問自己:你對這個世界做出了什么假設?什么是感覺像是常識?什么有些違背常理?重要的是,對于數據集不應該忘記考慮:誰收集的它?為什么會收集它?誰付錢收集了它?所謂的”真值“標簽來自哪里?
之后,你甚至可能會發現自己在質疑收集數據過程中的某些假設,從而對你的分類任務有更加整體地理解。
如果對你的數據有很多問題,你就已經有很好的開端了。
5 研究團隊介紹
People + AI Research (PAIR) 是 Google 的一個跨學科團隊,通過基礎研究、構建工具、創建設計框架以及與不同社區合作來探索人工智能的人性方面。
團隊的宗旨讓機器學習發揮其積極潛力,因為它需要具有廣泛的參與性,涉及到它影響的社區,并由不同的公民、政策制定者、活動家、藝術家等群體指導。

該團隊開發了很多有趣的可視化交互頁面,探討了很多有趣的AI+公正性或者可解釋性的課題。快去試試吧!?