大數據轉型方案:首推數據湖!
作者:談數據
作為大數據的變革新生力量,數據湖技術一經問世,便深受大廠青睞,紛紛推出自己的數據湖解決方案和相關產品,并已在廣告數據分析、游戲行業等領域落地實行,效果顯著。
數倉技術應對關系型結構化數據游刃有余,但對于多元異構數據,卻愛莫能助。最近行業大佬都在聊怎么部署數據湖,這波操作未來走向如何?

數據湖技術能夠實現全量數據的單一存儲,通常存儲原始格式的對象塊或者文件。
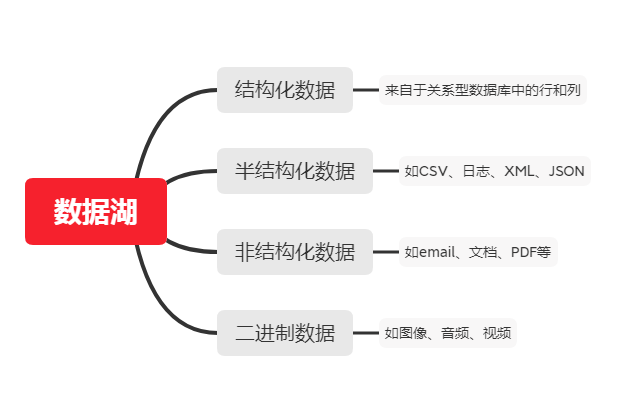
不管是傳統數倉承載的結構化數據還是半結構化數據、非結構化數據、二進制數據等任意類型的數據,數據湖都可以輕松實現采集、存儲和分析。
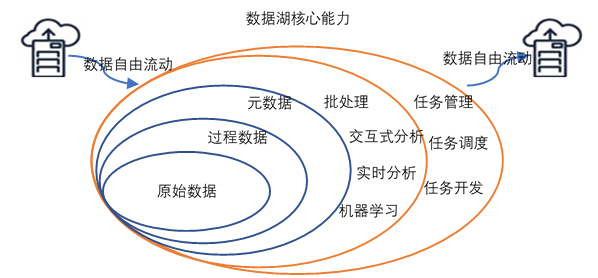
更為人性化的是,數據湖可根據企業的業務需求提供可大可小的彈性擴充,數據可在治理規則下自由流動,采用統一的存儲引擎,支持多模式計算引擎,可以運行從控制面板和可視化到大數據處理、實時分析和機器學習等不同類型的分析,深度挖掘數據價值進行預測分析,并保證了數據一致性、可治理和安全性的實現。
同時,數據湖無需任何預處理即可對數據進行采集、存儲和分析,還能消除數據采集和存儲的復雜性,加速應用數據,賦能廣大研發者、數據科學家、分析師實現對跨平臺、跨語言、跨領域的所有數據進行高效分析和處理,并且可與企業業務數據庫和數據倉庫無縫集成,擴展現有數據應用,進一步助力企業大數據中臺實現優化升級。
作為大數據的變革新生力量,數據湖技術一經問世,便深受大廠青睞:AWS、阿里云、華為、谷歌、騰訊等紛紛推出自己的數據湖解決方案和相關產品,并已在廣告數據分析、游戲行業等領域落地實行,效果顯著:
- 企業無需先期購買服務器、存儲等硬件設備,也無需一次性購買大量的云服務,完全契合了業務潮汐帶來了資源波動,滿足彈性分析需求,極大地降低了運維成本使用成本,大大提高了資金利用率。
- 能夠實現與企業現有技術的深度融合,支持數據多元集成和遷移,大幅帶動提升了企業原有分析和治理系統的性能優化。由此,眾多規模企業紛紛摩拳擦掌想要打造一套自己的數據湖技術體系。
責任編輯:趙寧寧
來源:
ITPUB