













OpenHarmony啃論文成長計劃---淺談序列化規范

大家好! 我是來自深圳技術大學FSR實驗室的同學,標題FFH就是FSRlab For Harmony!并且我也正在參加OpenHarmony成長計劃從論文到開源提交研究,以后我們也會陸續在這個社區記錄學習心得和體會。
引言
在涉及到網絡遠程通信的過程中,序列化傳遞的數據是不可避免的。
序列化(Serialization)其實就是將要傳遞的數據以及數據結構轉化為位字符串(bit-string),而反序列化(Deserialization)就是將為位字符串重新轉換為原始數據以及相應數據結構。
對于序列化其實有規范分類,一種是文本及二進制序列化規范(Textual and Binary Serialization Specififications),還有一種是無模式及模式驅動規范(Schema-less and Schema-driven Serialization Specififications),下面我們簡單了解一下這兩個規范分類。
文本及二進制序列化規范(Textual and Binary Serialization Specififications)
如果序列化規范產生的位字符串對應于文本編碼中的字符序列,如對應ASCII、EBCDIC/CCSID 037或UTF-8,則序列化規范稱為文本序列化規范(Textual Serialization Specififications),否則序列化規范稱為二進制序列化規范(Binary Serialization Specififications)。
下圖是用這兩種規范分別序列化3.1415926535的例子:


文本序列化規范(Textual Serialization Specififications)
我們可以將文本序列化規范視為具備特定文本編碼(如UTF-8)規則內的一組約定。用于操作該文本編碼格式的計算機工具可以方便的處理對應序列化后的位字符串。
比如上圖用兩種規范序列化3.1415926535。
文本表示法將十進制數字編碼為一個 96 bit長的數字字符序列 ,我序列化后的位字符串可以使用對應的文本編輯器(比如這里是UTF-8編碼格式的編輯器)輕松地檢查和處理,可讀性較高。
二進制序列化規范(Binary Serialization Specififications)
還是上圖用二進制規范序列化3.1415926535。
從圖中序列化后的位字符串來看, 二進制序列化表示法根據其符號、指數和尾數對十進制數進行編碼。所得到的位字符串只有 32 bit長。
差異及應用
從序列化后的數據占用的空間來看——二進制序列化規范比文本序列化規范表示法小三倍。然而, 我們無法使用通用的基于文本的工具來處理它,二進制序列化規范需要一個比較詳細的協議來定義被序列化后的二進制流的每個字節的含義是什么。因為這個規范處理的數據空間占用比較小,因此傳輸效率比較高,但是可讀性較低,一般用于需要數據傳輸效率非常高的場景。
JSON,XML以及 BSON,ProtocolBuffers是常用的序列化手段,前面兩個是基于文本序列化規范的,后面兩個是基于二進制序列化規范的。但是,無論是文本格式還是二進制格式,存儲的都是二進制。
模式驅動及無模式序列化規范(Schema-less and Schema-driven Serialization Specififications)
如果序列化規范生成的位字符串可以在事先不了解其原始數據及其數據結構的情況下進行反序列化,則稱這種規范是模式序列化規范的。否則,則稱為模式驅動序列化規范。
下圖是兩種規范分別序列化兩個哈希映射的例子:
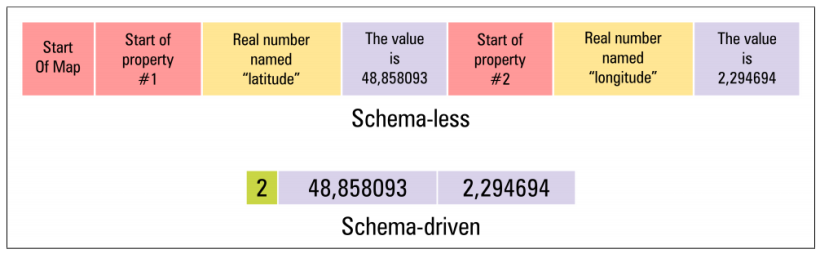

模式驅動序列化規范(Schema-driven Serialization Specififications)
模式驅動序列化規范Schema-driven Serialization Specififications)的特點就是在我們傳遞數據的時候,我們要事先約定傳遞的數據結構信息,并且將結構信息編碼到序列化生成的位字符串中。
比如上圖的例子是序列化兩個映射。
{
"latitude":48858093,
"longitude":2294694
}
模式驅動列化后位字符串的(底部)除了作為整數前綴的映射的長度,省略了大多數自描述性信息。如果沒有提前約定相關的源數據結構信息,接收者無法處理模式驅動下的位字符串,也就是不知道如何轉換為原始數據結構。
無模式序列化規范(Schema-less Serialization Specififications)
還是上圖的例子,無模式序列化規范(頂部)是自描述性的,原始數據結構的信息和原始數據都用不同的屬性區別開來。所以數據接收者不需要提前約定,就可以對序列化后的位字符串進行處理。
差異及應用
從上面的介紹我們可以看到,模式驅動序列化規范序列化后會產生的相對節省很多空間的位字符串。因此,網絡要求高效的系統傾向于采用模式驅動的序列化規范。模式驅動的序列化規范通常與空間效率有關,因此往往是二進制的。然而,也有人提出了一個基于文本JSON兼容的模式驅動序列化規范。
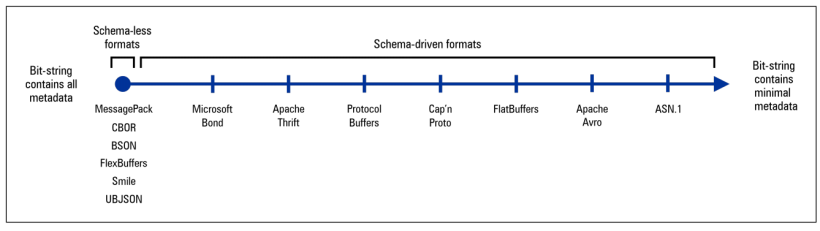
上圖中表示的是用不同的序列化技術,分別序列化相同數據后,對位字符串信息量大小進行排序。(越往右信息量越小)。
我們可以根據上圖直觀地看到序列化后的位字符串包含的信息量,來比較無模式和模式驅動的序列化規范。
最左邊的處理方法序列化后的位字符串的信息量是最大的,都是無模式序列化規范(Schema-less Serialization Specififications),比如BSON,Smile,FlexBuffers等,因為最大地保留了原始數據及其結構的信息描述。最右邊的信息量是最小的,比如ASN.1,因為他們把非常多的結構信息已經在規范中提前約定,因此不需要寫入序列化后的位字符串中。
存在即是合理,這些模式都沒有最好最壞,每種模式都可以在特定的場景發揮對應場景需要的作用。






























