













OpenHarmony啃論文成長計劃---Apache Avro與Twister

大家好! 我是深圳技術大學FSR實驗室的同學,在OpenHarmony成長計劃啃論文俱樂部里,與華為、軟通動力、潤和軟件、拓維信息、深開鴻等公司一起,學習和研究序列化相關技術…
【本期看點】
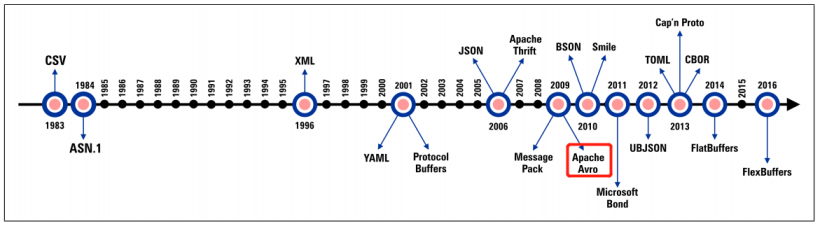
- Apache Avro發展時間及應用。
- 文獻場景概述。
- 與Apache Avro集成后的Twister體系結構。
Apache Avro發展時間及應用
開源地址:apache/avro: Apache Avro is a data serialization system. (github.com)。
今天我們要講的是Apache Avro,其是Hadoop的一個子項目,由Hadoop的創始人Doug Cutting牽頭開發。Avro是一個數據序列化系統,設計用于支持大批量數據交換的應用。它的主要特點有:支持二進制序列化方式,可以便捷,快速地處理大量數據;動態語言友好,Avro提供的機制使動態語言可以方便地處理Avro數據。
其主要應用場景也是在大數據處理方面。


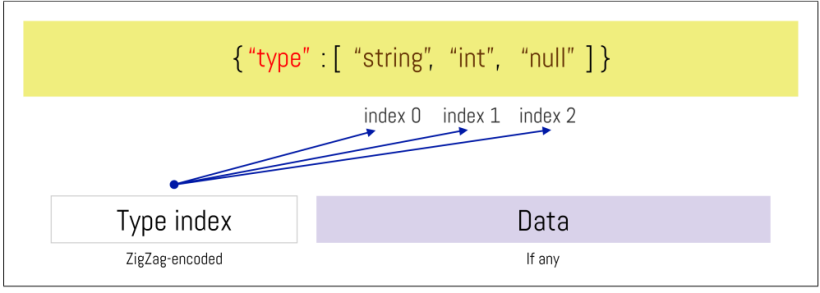
Apache Avro的 schema可以為單個字段聲明潛在類型的有序列表。在這些情況下,Apache Avro二進制編碼會在值的前面加上一個32位 ZigZag編碼的小尾端基數128(LEB128)可變長度有符號整數,該整數對應于有序類型列表的索引。
對于多種類型組成的字段,會被編碼為數據類型索引(Type index)。例如下圖,如果schema定義了一個類型為[“string”、“int”、“null”]的字段,那么如果值是字符串,則該值將以0x00作為前綴,如果值是整數,則以0x02作為前綴,如果值為空,則以0x04作為前綴,然后作為數據段的類型索引(Type index)。
文獻場景概述
這次我分享的文獻是關于Apache Avro在Twister信息傳遞系統的應用,該項目的目標是研究并實現一種用于Twister消息傳遞系統的新方法。
Twister是一個迭代的MapReduce框架,它將MapReduce范式提升到了一個更高的層次,滿足了迭代性質的應用。Twister通過Narada Brokering使用發布/訂閱消息系統,但是由此引發的問題是,與較小的控制消息相比,在交換相對較大的數據消息時,消息傳遞體驗會延遲。
為了研究這個問題,該論文提出了另一種方法實現,就是通過遠程過程調用(RPC),并且選擇Apache Avro作為RPC框架,所有計算節點都可以直接從彼此發送和接收數據,而不是通過代理系統。下面我們來看看Apache Avro和原Narada Brokerin系統的性能差別吧。
與Apache Avro集成后的Twister體系結構
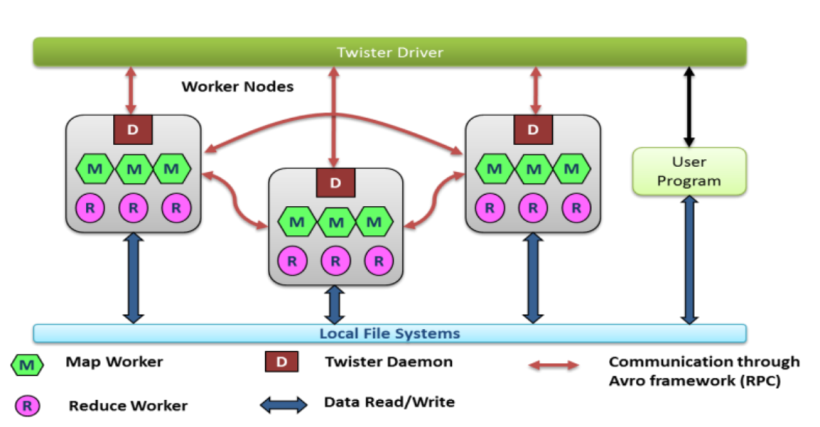

如上圖,ApacheAvro用于Twister驅動程序(Twister Driver)和Twister Daemon之間,以及Twister Daemon之間的通信。每個節點都可以通過RPC和序列化直接相互通信,而不是通過代理系統發送或接收消息。這樣就可以消除了發布/訂閱代理系統與計算節點之間的通信開銷和瓶頸。
測試結果
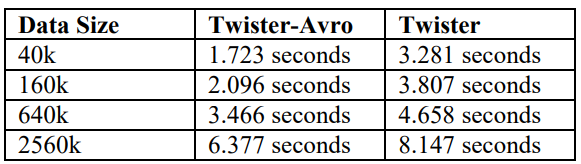

上圖展示了使用我們Apache Avro和原Narada Brokerin系統在不同的數據大小上運行K-means算法的時間性能差別。正如我們所期望的,這個基于Apache Avro的替代方法可以減少通信開銷并提高系統性能。




























