













VR絲滑全景指日可待?谷歌這個360° NeRF讓人看到未來
前段時間,CVPR 2022 公布了今年的論文接收結果,同時也意味著投稿的論文終于熬過了靜默期。不少作者都感嘆:終于可以在社交媒體上聊聊我們的論文了!
今天要介紹的論文來自谷歌研究院和哈佛大學。谷歌研究科學家、論文一作 Jon Barron 表示,他們開發了一種名為 Mip-NeRF 360 的模型,該模型能夠生成無界場景的逼真渲染,給我們帶來了 360° 的逼真效果和漂亮的深度圖。
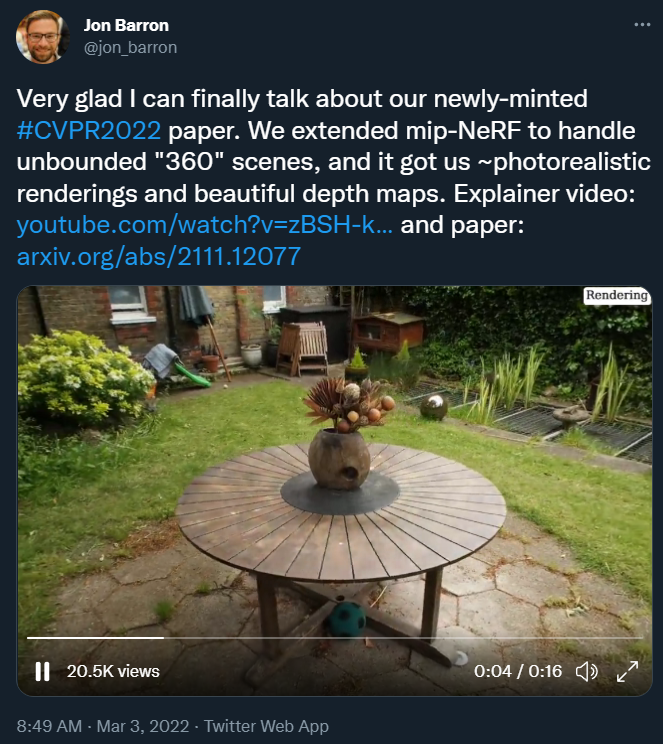
下面是幾張效果圖:


這么好的效果什么時候能讓 VR 頭盔用上
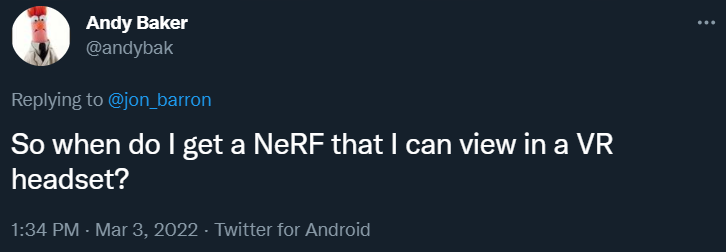
作者回答說,「我們已經可以在瀏覽器 (http://nerf.live) 或桌面 GPU (https://nvlabs.github.io/instant-ngp/) 上實時渲染 NeRF,所以把它放到 VR 頭盔上應該是可行的。」
論文概覽
神經輻射場 (NeRF) 通過在基于坐標的多層感知器 (MLP) 的權重內編碼場景的體積密度和顏色,來合成高度逼真的場景渲染。這種方法在逼真的視圖合成方面取得了重大進展 [30]。然而,NeRF 使用 3D 點對 MLP 的輸入進行建模,這在渲染不同分辨率的視圖時會導致混疊。
基于這個問題,Mip-NeRF 擴展了 NeRF ,不再對沿錐體的體積截頭體進行推理 [3]。盡管這樣做提高了質量,但 NeRF 和 mipNeRF 在處理無界場景時會遇到挑戰,無界場景中的相機可能面向任何方向并且場景內容可能位于任何位置。
在這篇論文中,研究者提出了對 mip-NeRF 的擴展 ——mip-NeRF 360,它能夠生成這些無界場景的逼真渲染(圖 1)。

將類似 NeRF 的模型應用于大型無界場景會引發三個關鍵問題:
- 參數化問題。mip-NeRF 要求將 3D 場景坐標映射到有界域,所以無界的 360 度的場景會占據無窮大的歐式空間區域。
- 效率問題。巨大且細節化的場景需要巨大的網絡容量,所以在訓練期間,頻繁地沿每條射線去查詢巨大的 MLP 網絡會產生巨大的消耗 。
- 歧義問題。無界 360 度場景的背景區域明顯比中心區域的光線稀疏。這種現象加劇了從 2D 圖像重建 3D 內容的固有模糊性。
基于上述問題,研究者提出了 mip-NeRF 的擴展模型,它使用非線性場景參數化、在線蒸餾和新穎的基于失真的正則化器來克服無界場景帶來的挑戰。新模型被稱為「mip-NeRF 360」,因為該研究針對的是相機圍繞一個點旋轉 360 度的場景,與 mip-NeRF 相比,均方誤差降低了 54%,并且能夠生成逼真的合成視圖和詳細的深度用于高度復雜、無界的現實世界場景的地圖。

- 論文鏈接:https://arxiv.org/pdf/2111.12077.pdf
- 視頻解讀:https://www.youtube.com/watch?v=zBSH-k9GbV4
技術細節
讓 mip-NeRF 在無界場景中正常工作存在三個主要問題,而本文的三個主要貢獻旨在解決這些問題。接下來,讓我們結合作者給出的解讀視頻來了解一下。
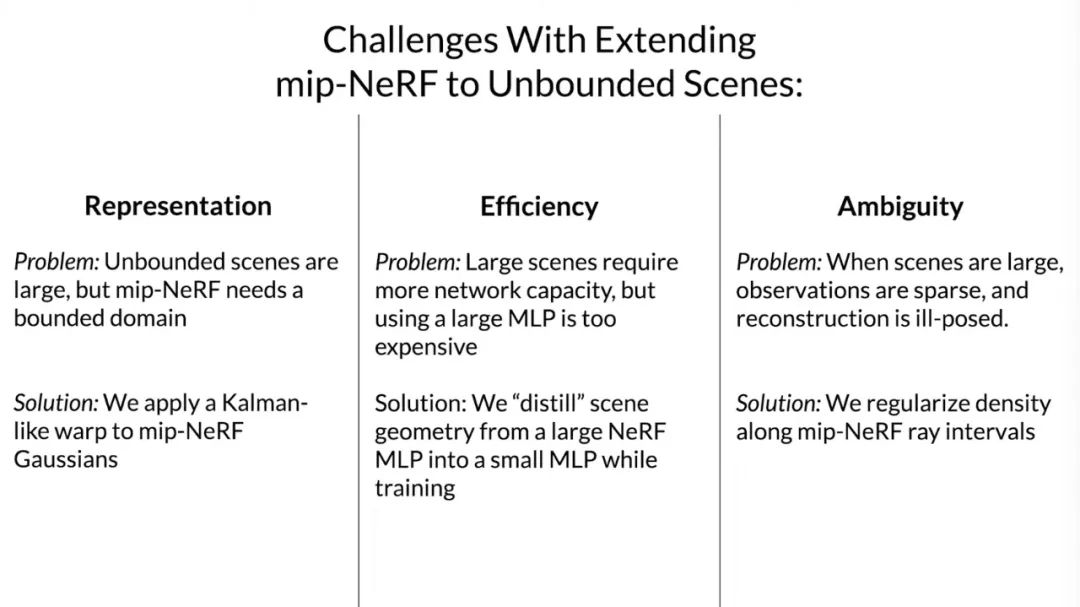
第一個問題是在表示方面,mip-NeRF 適用于有界坐標空間中,而非無界場景,研究者使用一種看起來很像是一種擴展版的卡爾曼濾波器將 mip-NeRF 的高斯函數扭曲到非歐式空間中。
第二個問題是,場景通常是細節化的,如果想將 mip-NeRF 用于無界場景,可以將網絡變得更大,但是這樣會讓訓練速度變慢。所以,在優化階段,研究者提出訓練一個較小的 MLP 來限制空間大小,這可以讓訓練速度變快三倍。
第三個問題是,在更大的場景下,3D 重建的結果會變得較為模糊,產生偽影。為了解決這個問題,研究者引入了一種新型正則化器,專門用于 mip-NeRF 中的射線間隔。
首先來談第一個問題,以一個有著三個攝像頭的平地場景為例,在 mip-NeRF 中,這些相機將高斯函數投射到場景中。在一個大的場景,這導致高斯函數逐漸遠離原點并且被拉長。這是因為 mip-NeRF 需要基于有界的坐標空間并且高斯函數在某種程度上是各向同性的。
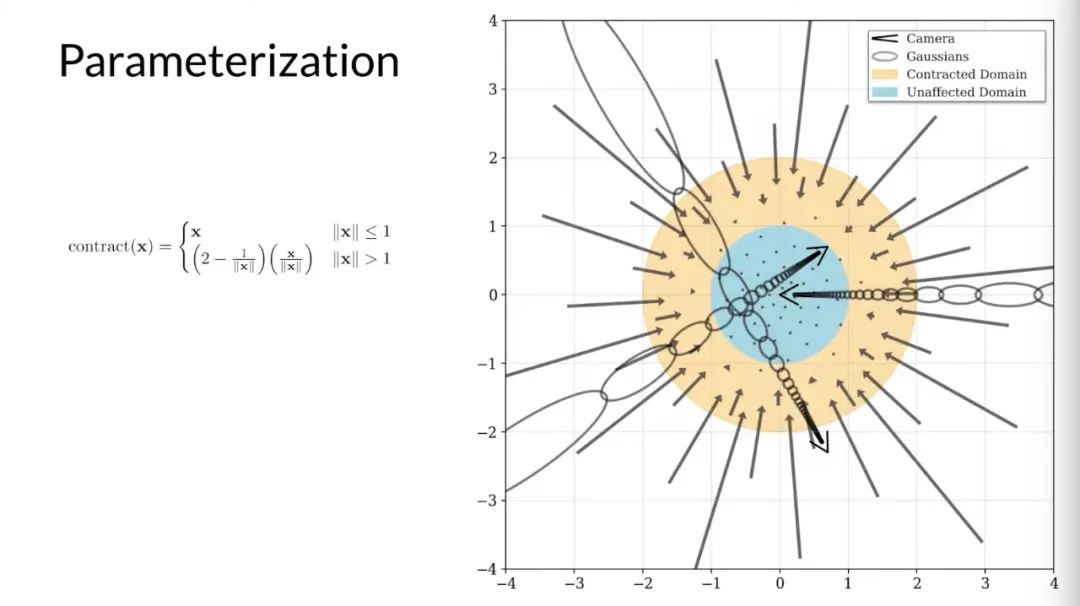
為了解決這個問題,研究者定義了一個扭曲函數,來平滑地將藍色圓(Unaffected Domain)外部的坐標映射到橙色圓(Contracted Domain)內。扭曲函數旨在消除 mip-NeRF 中的高斯非線性間距的影響。
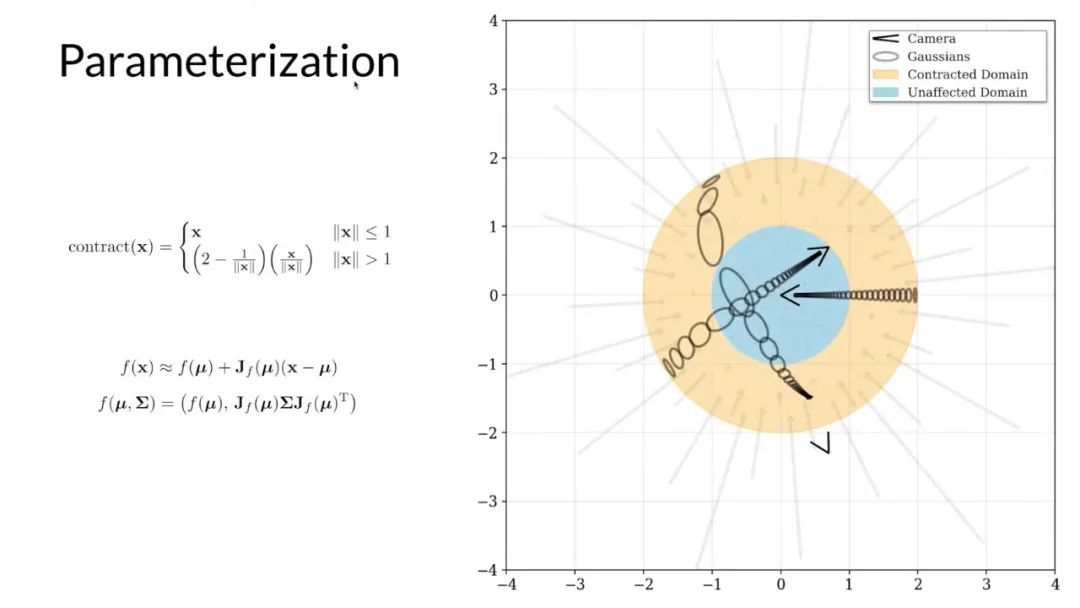
為了將這種扭曲應用于 mip-NeRF 中的高斯函數,研究者使用了一個擴展版的卡爾曼濾波器,這樣一來,沒有邊界的場景就可以被約束到橙色圓內,橙色圓內是一個非歐式空間,其中的坐標就是 MLP 的輸入。
為了能理解論文中的在線蒸餾模型,我們首先需要介紹 mip-NeRF 是如何訓練以及采樣的。在 mip-NeRF 中,首先需要定義一組大致均勻分布的區間,可以理解為直方圖中的端點。如圖所示,每個間隔的高斯都被送入 mlp,并且得到直方圖權重 w^c 和顏色 c^c。然后將這些顏色加權后得到像素點的顏色 C^c。之后這些權重被重采樣,并得到一組新的區間,并且在場景中有內容的地方,端點就會較為聚集。
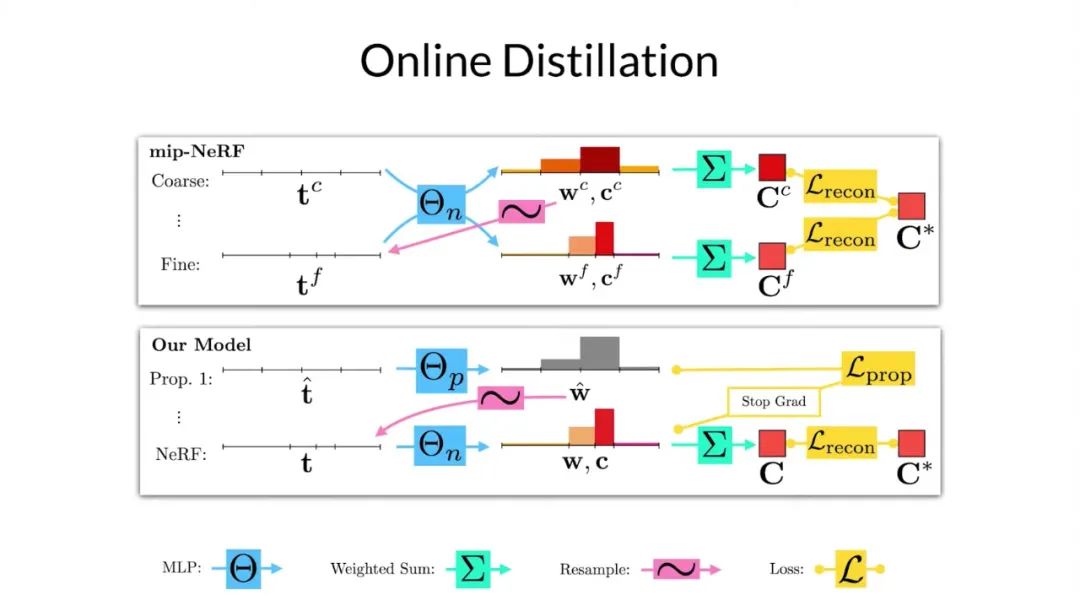
這個重采樣可以多次進行,但為了方便在這里只顯示一個。這個新的區間中的數據被送入同一 MLP 來得到一組新的權重和顏色,然后再通過加權得到像素點的顏色 C^f。mip-NeRF 只是最小化所有渲染像素值和輸入圖像真實像素值之間的重構損失。只有精細的顏色被用來渲染最終的圖像是非常浪費的。
粗略渲染需要有監督學習來完成的唯一原因是幫助指導精細直方圖的采樣,這一觀察激發了文中模型的訓練和采樣過程。研究者從一組均勻分布的直方圖開始,將它們送入提出的 MLP 以產生一組權重,但不產生顏色。
這些權重會被重新采樣,同樣這個過程可以重復多次,但他們在視頻中只展示了一個重采用過程。他們提出的 mlp 產生的最后一組區間被送入另一個 mlp,該 mlp 的行為與 mip-NeRF 中的完全相同,他們將其稱為 NeRF mlp。NeRF mlp 為他們提供了一組可以用于渲染像素顏色的權重和顏色。
研究者將通過監督學習的方式,使得像素渲染得到的顏色接近真實圖片中的顏色。他們讓監督輸出權重與 NeRF mlp 的輸出權重一致,而不是監督文中提出的 mlp 來重建圖像。這種設置意味著只需要經常去訪問一個較小的 mlp,而較大的 NeRF mlp 則不需要太多的訪問次數。
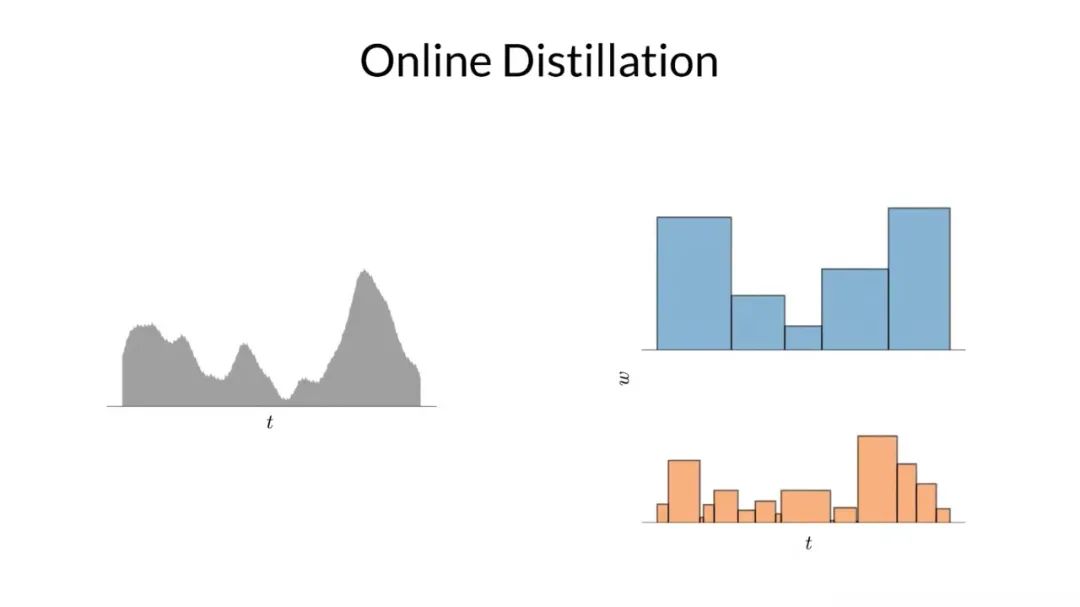
為了使模型起效,他們需要一個損失函數來鼓勵具有不同區間劃分的直方圖彼此一致。為了說明這一點,如上圖所示,他們在左側構建了一個真實的一維分布,在右側的是兩個該真實分布的直方圖。
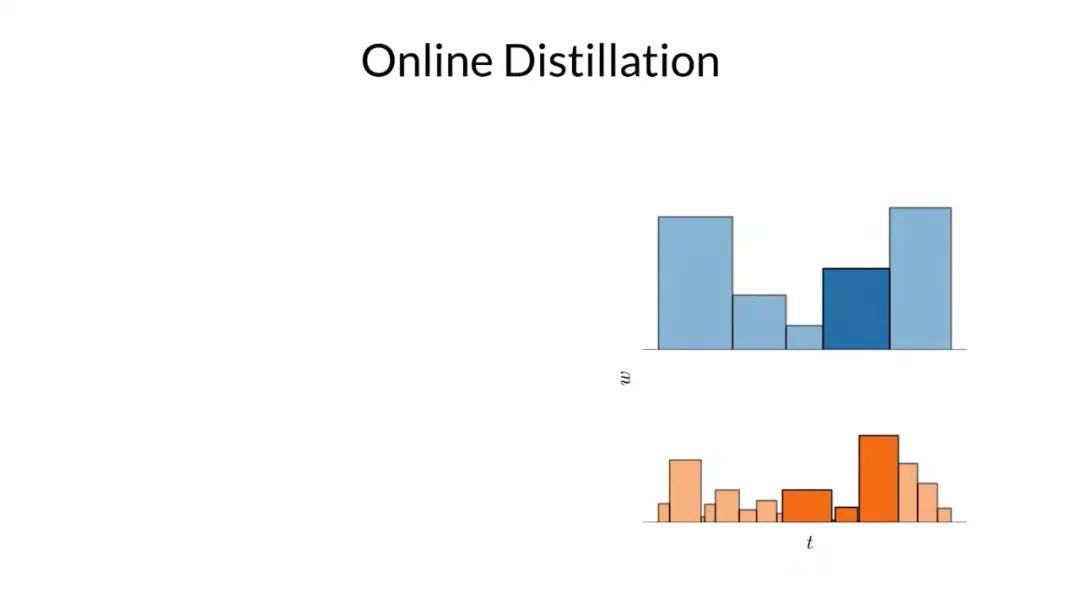
因為這兩個直方圖刻畫同一個分布,研究者可以對它們之間的關系做出一些強有力的斷言,例如上面突出顯示的那個區間的權重一定不會超過在下面的直方圖中與其重疊的區間權重的總和。基于這個事實,他們可以使用一個直方圖的權重來構造另一個直方圖權重的上限。
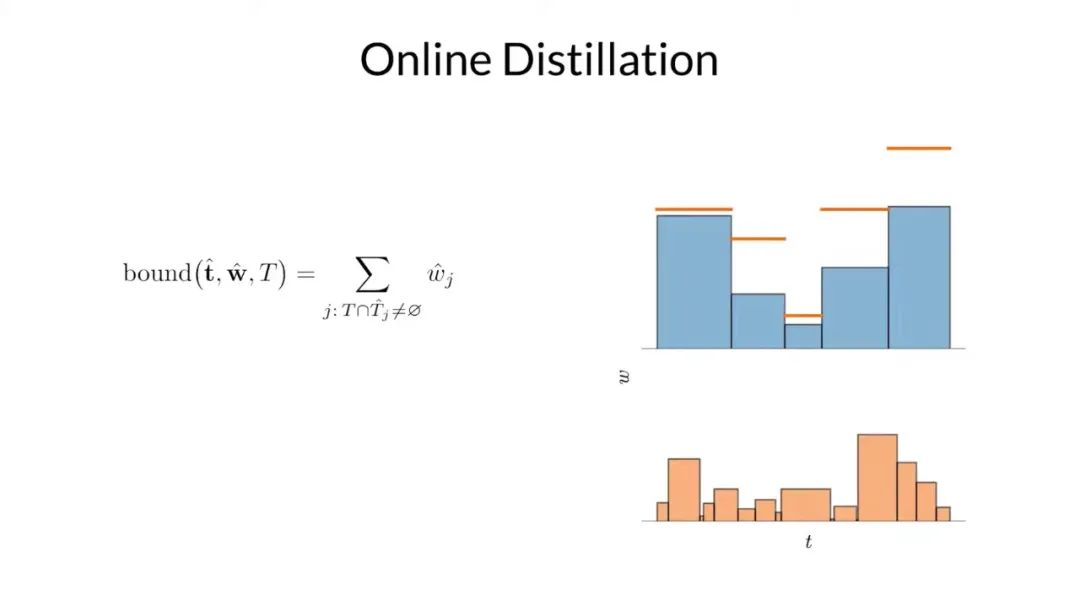
再一次聲明,如果這兩個直方圖同時刻畫相同的真實分布的,上界是必須確定的。
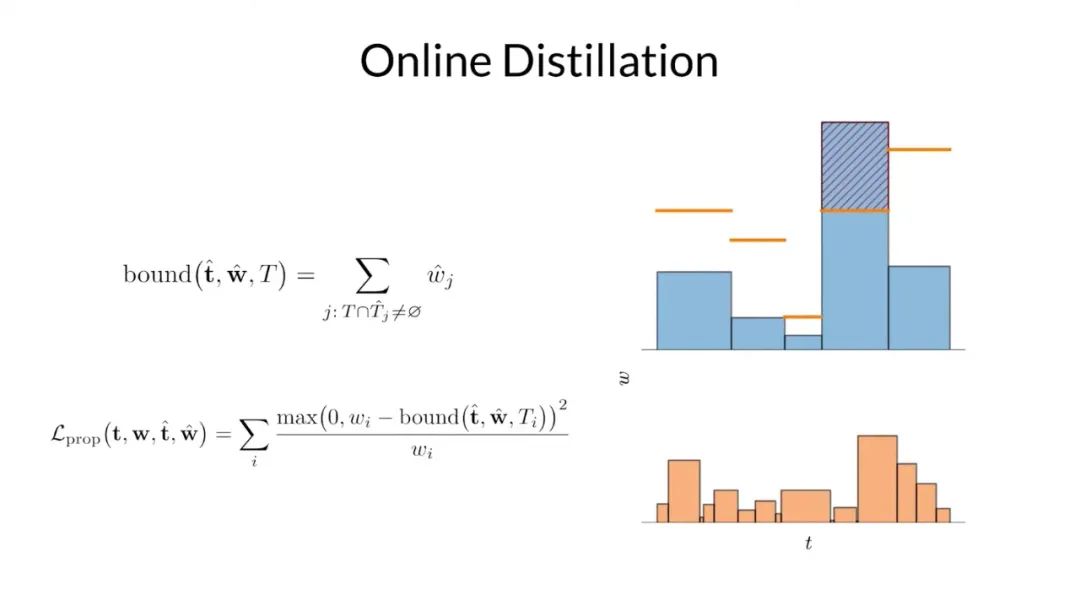
因此,在訓練期間,研究者對他們提出的 mlp 和 NeRF mlp 分別生成的直方圖之間構造了損失,該損失會懲罰任何違反此處以紅色顯示的邊界的多余部分。通過這樣方式,來鼓勵他們提出的 mlp 學習什么是有效的上界。
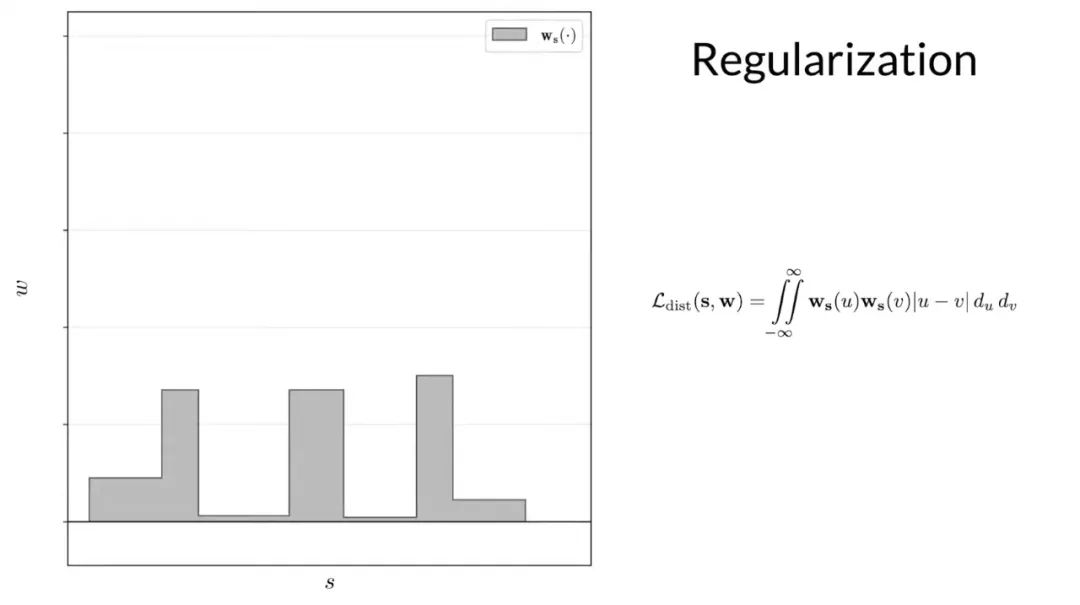
基于 nerf mlp 學習的體積場景密度,新模型中用來解決歧義問題的組件是光線直方圖上的簡單正則化器,他們簡單地最小化沿光線的所有點之間的加權絕對距離,來鼓勵每個直方圖盡可能接近 delta 函數。這里顯示的這個二重積分不容易計算,但可以推導出一個很好的封閉形式,計算起來很簡單。
實驗結果
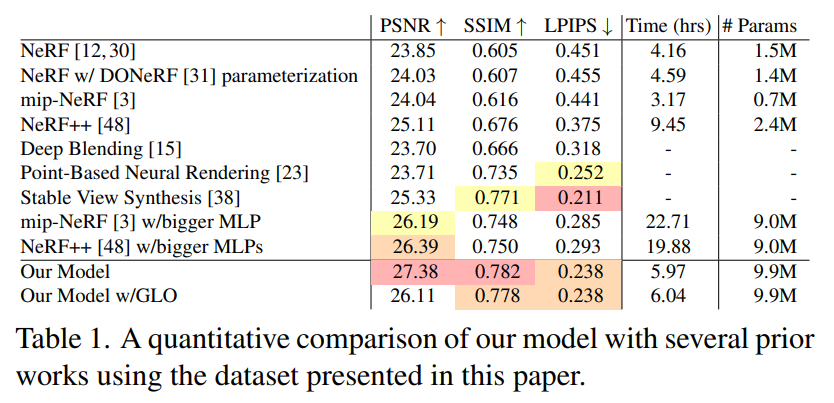
表 1 展示了數據集中測試圖像的平均 PSNR、SSIM [46] 和 LPIPS [49]。從中可以看出,本文提出的模型大大優于所有先前的類似 NeRF 的模型,并且可以看到相對于 mip-NeRF ,均方誤差減少了 54%,而訓練時間僅為 1.92 倍。
在表 2 中,研究者對模型在自行車場景中進行了消融研究,并在此總結了研究結果。
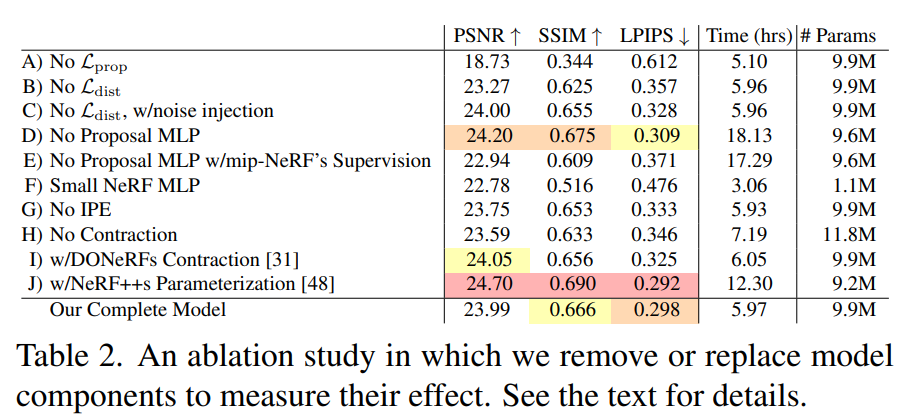
A) 移除 L_prop 會導致災難性的失敗,因為 MLP 完全不受監督。
B) 移除 L_dist 通過引入偽影降低圖像質量(參見圖 5)。

C) Mildenhall 等人提出的正則化器 [30] 將高斯噪聲 (σ = 1) 注入密度當中,但效果不如我們的正則化器。
D) 移除研究者提出的 MLP 并使用單個 MLP 對場景和權重進行建模不會降低性能,但會比他們提出的 MLP 增加約為 2 倍的訓練時間。
E) 刪除 MLP 并使用 mip-NeRF 的方法訓練本文提出的模型(在所有粗略尺度上應用 L_recon 而不是 L_prop)會降低速度和準確性,這證明研究者使用的監督策略是合理的。
F) 使用小型 NeRF MLP(256 個隱藏單元而不是 1024 個隱藏單元)加速了訓練,但降低了質量,這展示了大容量 MLP 在建模詳細場景時的價值。
G) 完全移除 IPE 并使用 NeRF 的位置編碼 [30] 會降低性能,顯示了基于 mip-NeRF 而不是 NeRF 的價值。
H) 消除收縮并增加位置編碼頻率來限制場景會降低準確性和速度。
I) 使用 DONeRF [31] 中提出的參數化和對數射線間距會降低精度。
J) 盡管使用 NeRF++ [48] 中提出的雙 MLP 參數化可以優于本文中的技術 —— 但代價是訓練時間加倍,因為 MLP 的驗證時間加倍(為了保持恒定的模型容量,研究者將兩個 MLP 的隱藏單元數除以 √2)。
更多細節請參考原論文。














