













重溫數據結構經典:HashCode及HashMap原理
作者:MicroStone
本篇跟大家一起重溫一下數據結構經典:hashCode及HashMap原理。

一、HashCode為什么使用31作為乘數
1、選擇數字31是因為它是一個奇質數,如果選擇一個偶數會在乘法運算中產生溢出,導致數值信息丟失,因為乘二相當于移位運算。選擇質數的優勢并不是特別的明顯,但這是一個傳統。
2、數字31有一個很好的特性,即乘法運算可以被移位和減法運算取代,來獲取更好的性能:31 * i == (i << 5) - i,現代的 Java 虛擬機可以自動地完成這個優化。
二、數組與鏈表的特點
數組的特點是:尋址容易,插入和刪除困難。
鏈表的特點是:尋址困難,插入和刪除容易。
三、HashMap原理
- 允許null健及null值,null健,值為0。
- HashMap 不保證鍵值對的順序,操作時,鍵值對的順序會發生變化。
- HashMap是非線程安全類,在多線程環境下會發生問題。
- HashMap是JDK 1.2時推出的,底層基于散列算法實現。
- 在JDK 1.8中涉及比較多:1、散列表實現、2、擾動函數、3、初始化容量、4、負載因子、5、擴容元素拆分、6、鏈表樹化、7、紅黑樹、8、插入、9、查找、10、刪除、11、遍歷、12、分段鎖等。
(1) 擾動函數
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
擾動函數就是為了增加隨機性,讓數據元素更加均衡地散列,減少碰撞。
(2) 負載因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
負載因子,可以理解成一輛車可承重重量超過某個閥值時,把貨放到新的車上。在 HashMap 中,負載因子決定了數據量多少了以后進行擴容。
0.75 是一個默認構造值,在創建 HashMap 也可以調整,如何希望用更多的空間換取時間,可以把負載因子調得更小一些,減少碰撞。
(3) 擴容元素拆分
擴容最直接的問題,就是需要把元素拆分到新的數組中,在JDK1.7中,會重新計算哈希值,但在JDK1.8后,進行了優化。
- 擴容時計算出新的newCap、newThr,這是兩個單詞的縮寫,一個是Capacity ,另一個是閥Threshold。
- newCap用于創新的數組桶 new Node[newCap]。
- 隨著擴容后,原來那些因為哈希碰撞,存放成鏈表和紅黑樹的元素,都需要進行拆分存放到新的位置中。
(4) 數據遷移
(5) 數據插入
- 首先進行哈希值的擾動,獲取一個新的哈希值。(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16)。
- 判斷tab是否為空或者長度為0,如果是則進行擴容操作。
- if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length。
- 根據哈希值計算下標,如果對應小標正好沒有存放數據,則直接插入即可否則需要覆蓋。tab[i = (n - 1) & hash])。
- 判斷tab[i]是否為樹節點,否則向鏈表中插入數據,否則向樹中插入節點。
- 如果鏈表中插入節點的時候,鏈表長度大于等于8,則需要把鏈表轉換為紅黑樹。treeifyBin(tab, hash)。
- 最后所有元素處理完成后,判斷是否超過閾值;threshold,超過則擴容。
- treeifyBin,是一個鏈表轉樹的方法,但不是所有的鏈表長度為8后都會轉成樹,還需要判斷存放key值的數組桶長度是否小于64 MIN_TREEIFY_CAPACITY。如果小于則需要擴容,擴容后鏈表上的數據會被拆分散列的相應的桶節點上,也就把鏈表長度縮短了。
(6) 鏈表樹化
- 鏈表樹化的條件有兩點;鏈表長度大于等于8、桶容量大于64,否則只是擴容,不會樹化。
- 鏈表樹化的過程中是先由鏈表轉換為樹節點,此時的樹可能不是一顆平衡樹。同時在樹轉換過程中會記錄鏈表的順序,tl.next = p,這主要方便后續樹轉鏈表和拆分更方便。
- 鏈表轉換成樹完成后,再進行紅黑樹的轉換。先簡單介紹下,紅黑樹的轉換需要染色和旋轉,以及比對大小。在比較元素的大小中,有一個比較有意思的方法,tieBreakOrder加時賽,這主要是因為HashMap沒有像TreeMap那樣本身就有Comparator的實現。
(7) 紅黑樹轉鏈
在轉換樹的過程中,記錄了原有鏈表的順序,紅黑樹轉鏈表時候,直接把TreeNode轉換為Node,因為記錄了鏈表關系,所以替換過程很容易。
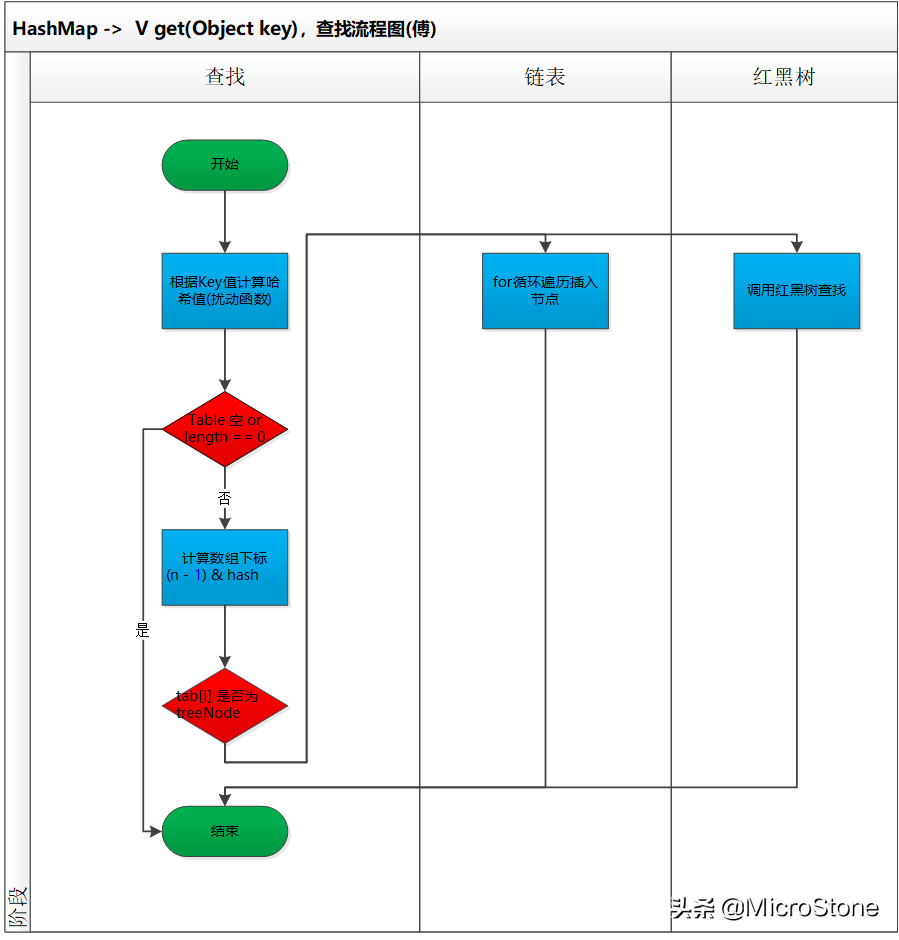
(8) 查找
- 擾動函數的使用,獲取新的哈希值。
- 下標的計算, tab[(n - 1) & hash])。
- 確定了桶數組下標位置,接下來就是對紅黑樹和鏈表進行查找和遍歷操作了。
(9) 刪除
- 刪除的操作也比較簡單,沒有太多的復雜的邏輯。
- 另外紅黑樹的操作因為被包裝了,只看使用上也是很容易。
(10) 遍歷
- 這里我們要設定一個既有紅黑樹又有鏈表結構的數據場景
- 為了可以有這樣的數據結構,我們最好把 HashMap 初始長度設定為 64,避免在
鏈表超過 8 位后擴容,而是直接讓其轉換為紅黑樹。
- 找到 18 個元素,分別放在不同節點(這些數據通過程序計算得來)。
- 桶數組 02 節點:24、46、68。
- 桶數組 07 節點:29。
- 桶數組 12 節點:150、172、194、271、293、370、392、491、590。
測試代碼
public void test_Iterator() {
Map<String, String> map = new HashMap<String, String>(64);
map.put("24", "Idx:2");
map.put("46", "Idx:2");
map.put("68", "Idx:2");
map.put("29", "Idx:7");
map.put("150", "Idx:12");
map.put("172", "Idx:12");
map.put("194", "Idx:12");
map.put("271", "Idx:12");
System.out.println("排序01:");
for (String key : map.keySet()) {
System.out.print(key + " ");
}
map.put("293", "Idx:12");
map.put("370", "Idx:12");
map.put("392", "Idx:12");
map.put("491", "Idx:12");
map.put("590", "Idx:12");
System.out.println("\n\n排序02:");
for (String key : map.keySet()) {
System.out.print(key + " ");
}
map.remove("293");
map.remove("370");
map.remove("392");
map.remove("491");
map.remove("590");
System.out.println("\n\n排序03:");
for (String key : map.keySet()) {
System.out.print(key + " ");
}
}
- 添加元素,在 HashMap 還是只鏈表結構時,輸出測試結果 01。
- 添加元素,在 HashMap 轉換為紅黑樹的時候,輸出測試結果 02。
- 刪除元素,在 HashMap 轉換為鏈表結構時,輸出測試結果 03。
結果如下:
排序01:
24 46 68 29 150 172 194 271
排序02:
24 46 68 29 271 150 172 194 293 370 392 491 590
排序03:
24 46 68 29 172 271 150 194
Process finished with exit code 0
這一篇 API 源碼以及邏輯與上一篇數據結構中擾動函數、負載因子、散列表實現等,內容的結合,算是把 HashMap 基本常用技術點,梳理完成了。但知識絕不止于此,這里還有紅黑樹的相關技術內容,后續會進行詳細。
除了 HashMap 以外還有 TreeMap、ConcurrentHashMap 等,每一個核心類都有一與之相關的核心知識點,每一個都非常值得深入研究。這個燒腦的過程,是學習獲得的知識的最佳方式。
責任編輯:姜華
來源:
今日頭條





















