阿里二面:RocketMQ 消息積壓了,增加消費者有用嗎?
大家好,我是君哥。今天分享一道有意思的面試題。
面試官:RocketMQ 消息積壓了,增加消費者有用嗎?
我:這個要看具體的場景,不同的場景下情況是不一樣的。
面試官:可以詳細說一下嗎?
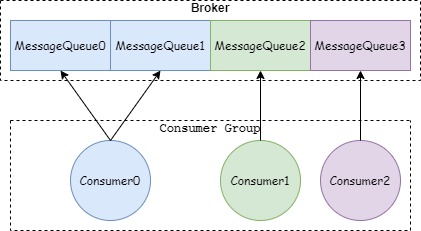
我:如果消費者的數量小于 MessageQueue 的數量,增加消費者可以加快消息消費速度,減少消息積壓。比如一個 Topic 有 4 個 MessageQueue,2 個消費者進行消費,如果增加一個消費者,明細可以加快拉取消息的頻率。如下圖:
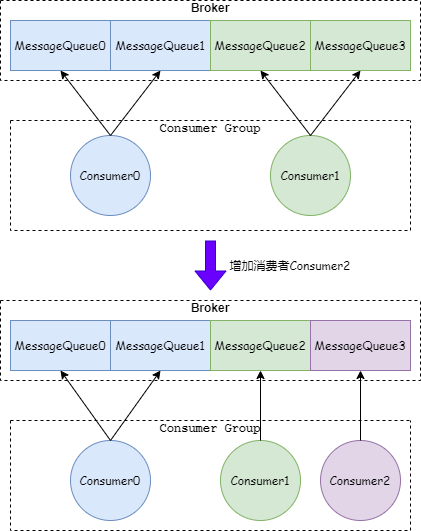
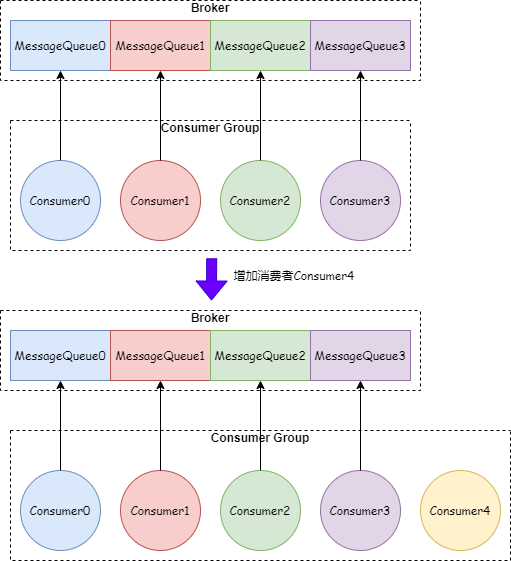
如果消費者的數量大于等于 MessageQueue 的數量,增加消費者是沒有用的。比如一個 Topic 有 4 個 MessageQueue,并且有 4 個消費者進行消費。如下圖:
面試官:你說的第一種情況,增加消費者一定能加快消息消費的速度嗎?
我:這...,一般情況下是可以的。
面試官:有特殊的情況嗎?
我:當然有。消費者消息拉取的速度也取決于本地消息的消費速度,如果本地消息消費的慢,就會延遲一段時間后再去拉取。
面試官:在什么情況下消費者會延遲一段時間后后再去拉取呢?
我:消費者拉取的消息存在 ProcessQueue,消費者是有流量控制的,如果出現下面三種情況,就不會主動去拉取:
ProcessQueue 保存的消息數量超過閾值(默認 1000,可以配置);
ProcessQueue 保存的消息大小超過閾值(默認 100M,可以配置);
對于非順序消費的場景,ProcessQueue 中保存的最后一條和第一條消息偏移量之差超過閾值(默認 2000,可以配置)。
這部分源碼請參考類:org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl。
面試官:還有其他情況嗎?
我:對于順序消費的場景,ProcessQueue 加鎖失敗,也會延遲拉取,這個延遲時間是 3s。
面試官:消費者延遲拉取消息,一般可能是什么原因導致的呢?
我:其實延遲拉取的本質就是消費者消費慢,導致下次去拉取的時候 ProcessQueue 中積壓的消息超過閾值。以下面這張架構圖為例:
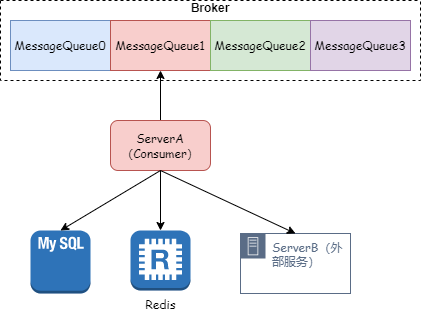
消費者消費慢,可是能下面的原因:
消費者處理的業務邏輯復雜,耗時很長;
消費者有慢查詢,或者數據庫負載高導致響應慢;
緩存等中間件響應慢,比如 Redis 響應慢;
調用外部服務接口響應慢。
面試官:對于外部接口響應慢的情況,有什么應對措施嗎?
我:這個要分情況討論。
如果調用外部系統只是一個通知,或者調用外部接口的結果并不處理,可以采用異步的方式,異步邏輯里采用重試的方式保證接口調成功。
如果外部接口返回結果必須要處理,可以考慮接口返回的結果是否可以緩存默認值(要考慮業務可行),在調用失敗后采用快速降級的方式,使用默認值替代返回接口返回值。
如果這個接口返回結果必須要處理,并且不能緩存,可以把拉取到的消息存入本地然后給 Broker 直接返回 CONSUME_SUCCESS。等外部系統恢復正常后再從本地取出來進行處理。
面試官:如果消費者數小于 MessageQueue 數量,并且外部系統響應正常,為了快速消費積壓消息而增加消費者,有什么需要考慮的嗎?
我:外部系統雖然響應正常,但是增加多個消費者后,外部系統的接口調用量會突增,如果達到吞吐量上限,外部系統會響應變慢,甚至被打掛。
同時也要考慮本地數據庫、緩存的壓力,如果數據庫響應變慢,處理消息的速度就會變慢,起不到緩解消息積壓的作用。
面試官:新增加了消費者后,怎么給它分配 MessageQueue 呢?
我:Consumer 在拉取消息之前,需要對 MessageQueue 進行負載操作。RocketMQ 使用一個定時器來完成負載操作,默認每間隔 20s 重新負載一次。
面試官:能詳細說一下都有哪些負載策略嗎?
我:RocketMQ 提供了 6 種負載策略,依次來看一下。
平均負載策略:
把消費者進行排序;
計算每個消費者可以平均分配的 MessageQueue 數量;
如果消費者數量大于 MessageQueue 數量,多出的消費者就分不到;
如果不可以平分,就使用 MessageQueue 總數量對消費者數量求余數 mod;
對前 mod 數量消費者,每個消費者加一個,這樣就獲取到了每個消費者分配的 MessageQueue 數量。
比如 4 個 MessageQueue 和 3 個消費者的情況:
源代碼的邏輯非常簡單,如下:
// AllocateMessageQueueAveragely 這個類
// 4 個 MessageQueue 和 3 個消費者的情況,假如第一個,index = 0
int index = cidAll.indexOf(currentCID);
// mod = 1
int mod = mqAll.size() % cidAll.size();
// averageSize = 2
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
// startIndex = 0
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
// range = 2,所以第一個消費者分配到了2個
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
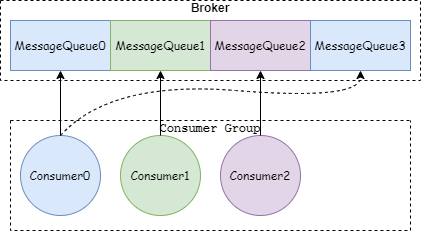
循環分配策略:
這個很容易理解,遍歷消費者,把 MessageQueue 分一個給遍歷到的消費者,如果 MessageQueue 數量比消費者多,需要進行多次遍歷,遍歷次數等于 (MessageQueue 數量/消費者數量),還是以 4 個 MessageQueue 和 3 個消費者的情況,如下圖:
源代碼如下:
//AllocateMessageQueueAveragelyByCircle 這個類
//4 個 MessageQueue 和 3 個消費者的情況,假如第一個,index = 0
int index = cidAll.indexOf(currentCID);
for (int i = index; i < mqAll.size(); i++) {
if (i % cidAll.size() == index) {
//i == 0 或者 i == 3 都會走到這里
result.add(mqAll.get(i));
}
}
自定義分配策略:
這種策略在消費者啟動的時候可以指定消費哪些 MessageQueue。可以參考下面代碼:
AllocateMessageQueueByConfig allocateMessageQueueByConfig = new AllocateMessageQueueByConfig();
//綁定消費 messageQueue1
allocateMessageQueueByConfig.setMessageQueueList(Arrays.asList(new MessageQueue("messageQueue1","broker1",0)));
consumer.setAllocateMessageQueueStrategy(allocateMessageQueueByConfig);
consumer.start();
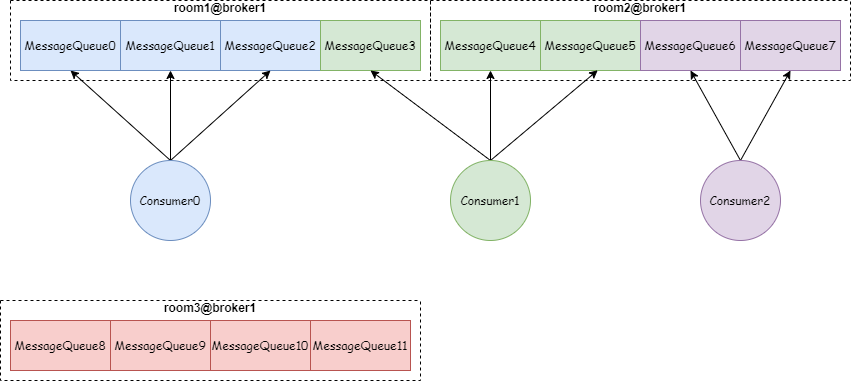
按照機房分配策略:
這種方式 Consumer 只消費指定機房的 MessageQueue,如下圖:Consumer0、Consumer1、Consumer2 綁定 room1 和 room2 這兩個機房,而 room3 這個機房沒有消費者。
Consumer 啟動的時候需要綁定機房名稱。可以參考下面代碼:
AllocateMessageQueueByMachineRoom allocateMessageQueueByMachineRoom = new AllocateMessageQueueByMachineRoom();
//綁定消費 room1 和 room2 這兩個機房
allocateMessageQueueByMachineRoom.setConsumeridcs(new HashSet<>(Arrays.asList("room1","room2")));
consumer.setAllocateMessageQueueStrategy(allocateMessageQueueByMachineRoom);
consumer.start();
這種策略 broker 的命名必須按照格式:機房名@brokerName,因為消費者分配隊列的時候,首先按照機房名稱過濾出所有的 MessageQueue,然后再按照平均分配策略進行分配。
//AllocateMessageQueueByMachineRoom 這個類
List<MessageQueue> premqAll = new ArrayList<MessageQueue>();
for (MessageQueue mq : mqAll) {
String[] temp = mq.getBrokerName().split("@");
if (temp.length == 2 && consumeridcs.contains(temp[0])) {
premqAll.add(mq);
}
}
//上面按照機房名稱過濾出所有的 MessageQueue 放入premqAll,后面就是平均分配策略
按照機房就近分配:
跟按照機房分配原則相比,就近分配的好處是可以對沒有消費者的機房進行分配。如下圖,機房 3 的 MessageQueue 也分配到了消費者:
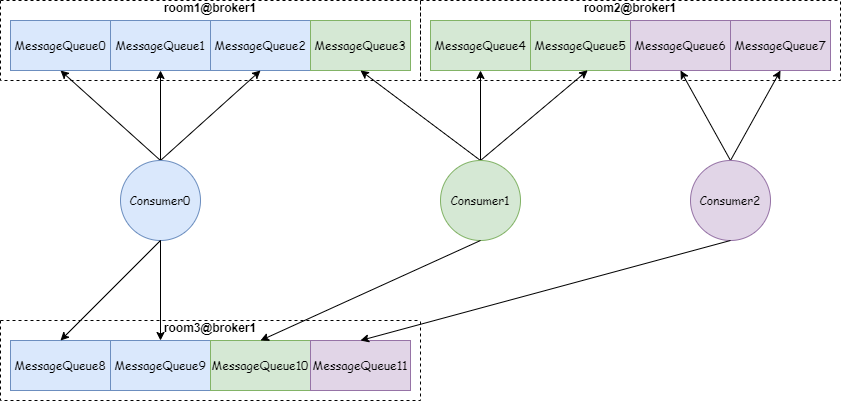
如果一個機房沒有消費者,則會把這個機房的 MessageQueue 分配給集群中所有的消費者。
源碼所在類:AllocateMachineRoomNearby。
一致性 Hash 算法策略:
把所有的消費者經過 Hash 計算分布到 Hash 環上,對所有的 MessageQueue 進行 Hash 計算,找到順時針方向最近的消費者節點進行綁定。如下圖:
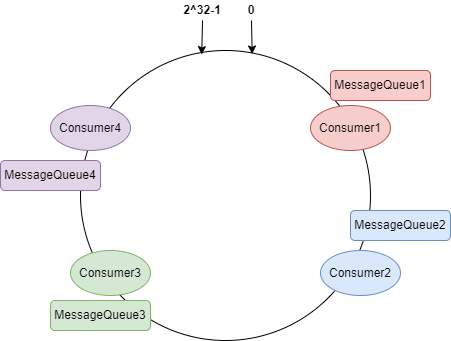
源代碼如下:
//所在類 AllocateMessageQueueConsistentHash
Collection<ClientNode> cidNodes = new ArrayList<ClientNode>();
for (String cid : cidAll) {
cidNodes.add(new ClientNode(cid));
}
//使用消費者構建 Hash 環,把消費者分布在 Hash 環節點上
final ConsistentHashRouter<ClientNode> router; //for building hash ring
if (customHashFunction != null) {
router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt, customHashFunction);
} else {
router = new ConsistentHashRouter<ClientNode>(cidNodes, virtualNodeCnt);
}
//對 MessageQueue 做 Hash 運算,找到環上距離最近的消費者
List<MessageQueue> results = new ArrayList<MessageQueue>();
for (MessageQueue mq : mqAll) {
ClientNode clientNode = router.routeNode(mq.toString());
if (clientNode != null && currentCID.equals(clientNode.getKey())) {
results.add(mq);
}
}
面試官:恭喜你,通過了。