













JavaScript 是怎么運行起來的?

JavaScript 的運行原理,是面試的時候經常會問到的問題,但是根據過往的面試結果來看,這部分能理解的很清楚的不足 20%,大多數同學熱衷于去學習一些 Vue、React 這樣的框架,以及一些新的 API,卻忽視了語言的根本,這是個非常不好的現象。
今天就帶大家來一起回顧一下,JavaScript 的真正的工作原理,里面不涉及深入的源碼解析,只是希望能夠用最簡單的描述讓大家弄明白整個過程,主要分為下面幾個部分:
- 解釋型和編譯型語言
- JavaScript 引擎
- EcmaScript 和 JavaScript 引擎的關系
- 運行時環境
- 為啥是單線程
- 調用堆棧的執行過程
- JavaScript 語言的解析過程
解釋型和編譯型語言
大家可能之前都聽說過,JavaScript 是一種解釋型的編程語言,那么啥叫解釋型語言呢?
編程語言是用來寫代碼的,代碼是給人看的。計算機只看得懂機器代碼(01010101),看不懂語言代碼。將我們能看得懂的代碼轉換為計算機可讀的機器代碼有兩種方式:解釋和編譯。
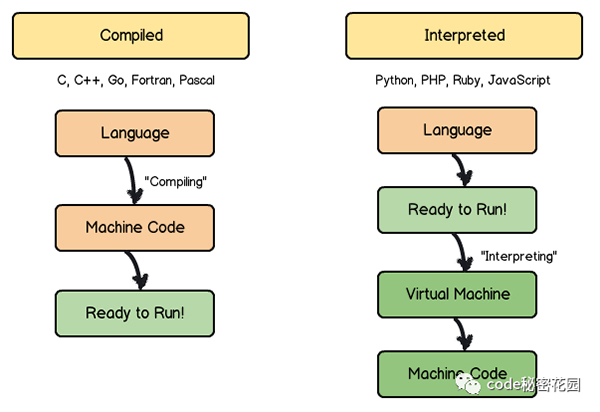
編譯型語言
編譯型語言直接可以轉換為計算機處理器可以執行的機器代碼,運行編譯型語言需要一個 “構建” 的步驟,每次更新了代碼你也要重新 “構建” 。
它們會比解釋語言更快更高效地執行。也可以更好的控制硬件,例如內存管理和 CPU 使用率。但是,在完成整個編譯的步驟需要花費額外的時間,生成的二進制代碼對平臺有一定的依賴性。
常見的編譯型語言有 C、C ++、Erlang、Haskell、Rust 和 Go。
解釋型語言
解釋型語言 是通過一個解釋器逐行解釋并執行程序的每個命令。
因為在運行時翻譯代碼的過程增加了開銷,解釋型語言曾經比編譯型語言慢很多。但是,隨著即時編譯的發展,這種差距正在縮小。
但是,解釋型語言更靈活一點,并且一般都能動態植入,程序也比較小。另外,因為是通過解釋器自己執行源程序代碼的,所以代碼本身相對于平臺是獨立的。
常見的解釋型語言有 PHP、Ruby、Python 和 JavaScript。
最后再來看看,誰來編譯?誰來解釋?誰來執行?
- 編譯型:編譯器來編譯,系統執行。
- 解釋型:解釋器解釋并執行。
JavaScript 引擎
JavaScript 是一種解釋型的編程語言,所以源代碼在執行之前沒有被編譯成二進制代碼。那么計算機是怎么理解和執行純文本腳本的呢?
這就是 JavaScript 引擎的工作,也就是我們上面提到的解釋器。
JavaScript 引擎是一個執行 JavaScript 代碼的計算機程序。基本上所有現代瀏覽器都內置了 JavaScript 引擎。當我們的瀏覽器中加載到 JavaScript 文件時,JavaScript 引擎會從上到下解析(將其轉換為機器碼)并執行文件的每一行。
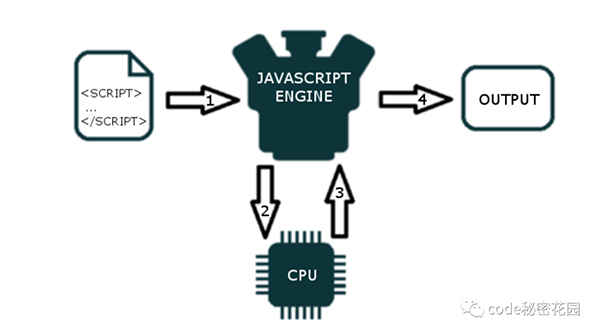
每個瀏覽器都有自己的 JavaScript 引擎,其中最著名的引擎是 Google 的 V8。
Google Chrome 和 Node.js 的 JavaScript 引擎都是 V8。下面還有一些其他的常見引擎:
- SpiderMonkey:由 Firefox 開發,第一款 JavaScript 引擎,用于Firefox。
- Chakra:由微軟開發,用于 Microsoft Edge。
- JavaScriptCore:由蘋果開發,用于 webkit 型瀏覽器,比如 Safari
所有的 JavaScript 引擎都會包含一個調用棧和一個堆:
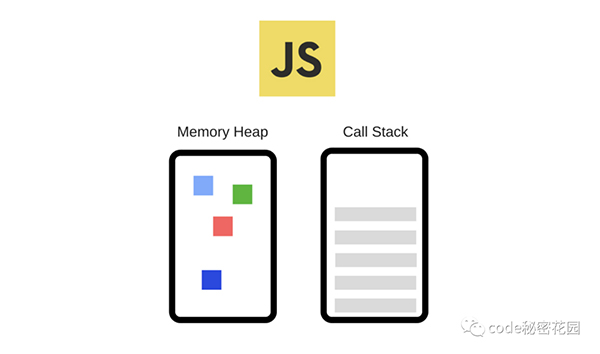
- 內存堆 - 這是內存分配發生的地方,是一個非結構化的內存池,它存儲我們應用程序需要的所有對象。
- 調用堆棧 - 是我們的代碼實際執行的地方
EcmaScript 和 JavaScript 引擎的關系
ECMAScript 指的是 JavaScript 的語言標準及語言版本,比如 ES6 表示語言(標準)的第 6 版。它由一個推動 JavaScript 發展的委員會制定,這個委員會指的是技術委員會( Technical Committee )第 39 號,我們一般簡稱 TC39,由各個主流瀏覽器廠商的代表以及一些互聯網大廠構成。
JavaScript 引擎的核心就是實現 ECMAScript 標準,此外還提供一些額外的機制(例如 V8 提供的垃圾回收器)。
一些最新的 ECMAScript 提案,到達 stage3 或 stage4 后,就會被 JavaScript 引擎實現,例如 v8 會把它的一些對語言標準的實現更新在它的博客上:https://v8.dev/
運行時環境
JavaScript 引擎并不能孤立運行,它需要一個好的運行時環境才能發揮更大的作用,例如 Node.js 就是一個 JavaScript 運行時環境,各種瀏覽器也是 JavaScript 的運行時環境。
這些運行時環境往往會提供諸如:事件處理、網絡請求 API、回調隊列或消息隊列、事件循環 這樣的附加能力。
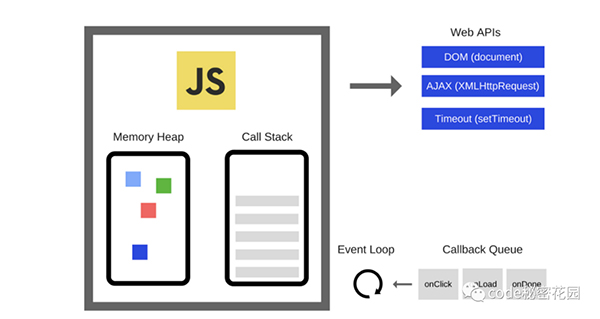
那么 JavaScript 引擎怎么配合這些能力在運行時環境中發揮作用呢?我們拿 Chrome 來舉個例子。
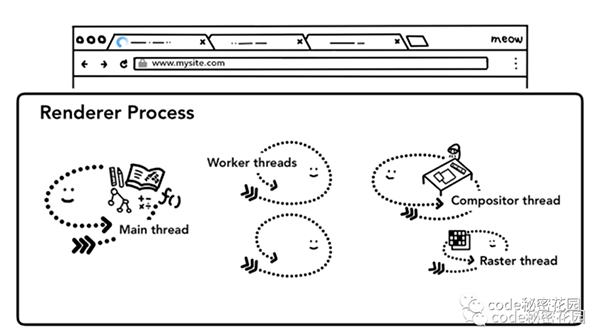
Chrome 是一個多進程的架構,我們打開一個瀏覽器時會啟動多個不同的進程協助瀏覽器將頁面為我們呈現出來:
- 瀏覽器進程:瀏覽器最核心的進程,負責管理各個標簽頁的創建和銷毀、頁面顯示和功能(前進,后退,收藏等)、網絡資源的管理,下載等。
- 插件進程:負責每個第三方插件的使用,每個第三方插件使用時候都會創建一個對應的進程、這可以避免第三方插件crash影響整個瀏覽器、也方便使用沙盒模型隔離插件進程,提高瀏覽器穩定性。
- GPU進程:負責3D繪制和硬件加速
- 渲染進程:瀏覽器會為每個窗口分配一個渲染進程、也就是我們常說的瀏覽器內核,這可以避免單個 page crash 影響整個瀏覽器。
我們常說的瀏覽器內核,比如 webkit 內核,就是瀏覽器的渲染進程,從接收下載文件后再到呈現整個頁面的過程,由瀏覽器渲染進程負責。瀏覽器內核是多線程的,在內核控制下各線程相互配合以保持同步,一個瀏覽器內核通常由以下常駐線程組成:
- GUI 渲染線程:負責渲染瀏覽器界面 HTML 元素,當界面需要重繪(Repaint)或由于某種操作引發回流(reflow)時,該線程就會執行。
- 定時觸發器線程:瀏覽器定時計數器并不是由 JavaScript 引擎計數的, 因為 JavaScript 引擎是單線程的, 如果處于阻塞線程狀態就會影響記計時的準確, 因此通過單獨線程來計時并觸發定時是更為合理的方案。
- 事件觸發線程:當一個事件被觸發時該線程會把事件添加到待處理隊列的隊尾,等待JS引擎的處理。這些事件可以是當前執行的代碼塊如定時任務、也可來自瀏覽器內核的其他線程如鼠標點擊、AJAX 異步請求等,但由于JS的單線程關系所有這些事件都得排隊等待JS引擎處理。
- 異步http請求線程:XMLHttpRequest 在連接后是通過瀏覽器新開一個線程請求, 將檢測到狀態變更時,如果設置有回調函數,異步線程就產生狀態變更事件放到 JavaScript 引擎的處理隊列中等待處理。
- JavaScript 引擎線程:解釋和執行 JavaScript 代碼。
GUI 渲染線程與 JavaScript 引擎為互斥的關系,當 JavaScript 引擎執行時 GUI 線程會被掛起, GUI 更新會被保存在一個隊列中等到引擎線程空閑時立即被執行。
JavaScript 是一種單線程編程語言,所以在瀏覽器內核中只有一個 JavaScript 引擎線程。
但是,在 JavaScript 的一個運行環境中,因為可能有多個渲染進程,所以可能有多個 JavaScript 引擎線程。
詳情可以見這篇文章:瀏覽器是如何調度進程和線程的?
為啥是單線程
那么,為什么 JavaScript 不設計成多個線程呢?這樣不是效率更高?
作為瀏覽器腳本語言, JavaScript 的主要用途是與用戶互動,以及操作 DOM。這決定了它只能是單線程,否則會帶來很復雜的同步問題。比如,假定 JavaScript 同時有兩個線程,一個線程在某個 DOM 節點上添加內容,另一個線程刪除了這個節點,這時瀏覽器應該以哪個線程為準?
所以,為了避免復雜性,從一誕生, JavaScript 就是單線程,這已經成了這門語言的核心特征,將來也不會改變。
那么既然 JavaScript 本身被設計為單線程,為何還會有像 WebWorker 這樣的多線程 API 呢?我們來看一下 WebWorker 的核心特點就明白了:
- 創建 Worker 時, JS 引擎向瀏覽器申請開一個子線程(子線程是瀏覽器開的,完全受主線程控制,而且不能操作 DOM)
- JS 引擎線程與 Worker 線程間通過特定的方式通信(postMessage API,需要通過序列化對象來與線程交互特定的數據)
所以 WebWorker 并不違背 JS引擎是單線程的 這一初衷,其主要用途是用來減輕 cpu 密集型計算類邏輯的負擔。
在單線程上運行代碼非常容易,你不必處理多線程環境中出現的復雜場景 — 例如死鎖。
調用堆棧的執行過程
JavaScript 是一種單線程編程語言,這意味著它有一個調用堆棧,一次只能做一件事。
調用堆棧是一種數據結構,它基本上記錄了我們在程序中的位置。如果我們執行一個函數,它放會放在棧頂。如果我們從一個函數返回,其會從棧頂彈出,這就是調用堆棧的執行過程。下面這個動圖很好的解釋了整個運行過程:

調用堆棧中的每個條目被稱為 堆棧幀。當調用堆棧中的一個 堆棧幀 需要大量時間才能被處理時,就會產生卡頓,因為瀏覽器沒法做其他事情了。
JavaScript 代碼的執行過程
我們從宏觀上看到了 JavaScript 調用堆棧是怎么執行的,那么具體到每段代碼上是怎么解析執行的呢?
下面我們就以 V8 為例,來看看一段 JavaScript 代碼的解析執行過程。
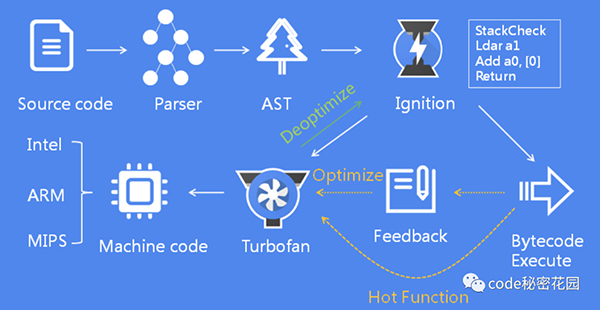
上面的圖展示了 V8 大體的工作流程,畫的很復雜,我們簡化一下,其實核心模塊是下面三個:
- 解析器(Parser):負責將 JavaScript 代碼轉換成 AST 抽象語法樹。
- 解釋器(Ignition):負責將 AST 轉換為字節碼,并收集編譯器需要的優化編譯信息。
- 編譯器(TurboFan):利用解釋器收集到的信息,將字節碼轉換為優化的機器碼。
在執行 JavaScript 代碼時,首先解析器會將源碼解析為 AST 抽象語法樹,解釋器會將 AST 轉換為字節碼,一邊解釋一邊執行。然后編譯器根據解釋器的反饋信息,優化并編譯字節碼,最后生成優化的機器碼,這就是 V8 大體的工作流程。
詞法分析和語法分析
我們常常提到的詞法分析和語法分析的過程就是發生在解析器(Parser)執行階段。
詞法分析就是將字符序列轉換為標記(token)序列的過程。
所謂 token ,就是源文件中不可再進一步分割的一串字符,類似于英語中單詞,或漢語中的詞。
一般來說程序語言中的 token 有:常數(整數、小數、字符、字符串等),操作符(算術操作符、比較操作符、邏輯操作符),分隔符(逗號、分號、括號等),保留字,標識符(變量名、函數名、類名等)等。
比如下面這段代碼:
const 公眾號 = '微信公號名稱';
經過詞法分析后,會被轉換為下面這些 token:
- const(保留字)
- 公眾號(變量名)
- =(賦值操操作算符)
- '微信公號名稱'(字符串常數)
語法分析 將這些 token 根據語法規則轉換為 AST:
{
"type": "Program",
"start": 0,
"end": 23,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 23,
"declarations": [
{
"type": "VariableDeclarator",
"start": 6,
"end": 22,
"id": {
"type": "Identifier",
"start": 6,
"end": 9,
"name": "公眾號"
},
"init": {
"type": "Literal",
"start": 12,
"end": 22,
"value": "微信公號名稱",
"raw": "'微信公號名稱'"
}
}
],
"kind": "const"
}
],
"sourceType": "module"
}
在生成 AST 的同時,還會為代碼生成執行上下文,在解析期間,所有函數體中聲明的變量和函數參數,都被放進作用域中,如果是普通變量,那么默認值是 undefined,如果是函數聲明,那么將指向實際的函數對象。
字節碼和機器碼
有了 AST 和執行上下文,解釋器會將 AST 轉換為字節碼并執行,那么字節碼和機器碼的區別是啥呢?
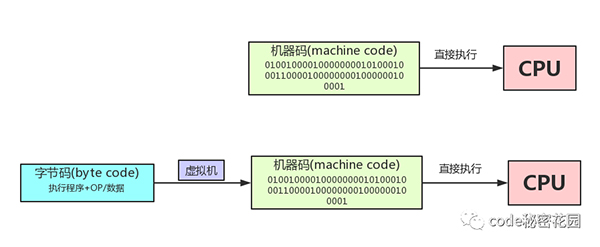
- 機器碼(machine code),學名機器語言指令,有時也被稱為原生碼(Native Code),是電腦的 CPU 可直接解讀的數據(計算機只認識0和1)。
- 字節碼(byte code)是一種包含執行程序、由一序列 OP代碼(操作碼)/數據對 組成的二進制文件。字節碼是一種中間碼,它比機器碼更抽象,需要直譯器轉譯后才能成為機器碼的中間代碼。
相比機器碼,字節碼不僅占用內存少,而且生成字節碼的時間很快,提升了啟動速度。那么機器碼什么時候用到呢?我們在文章開頭提到,隨著即時編譯的發展,解釋型語言和編譯型語言的運行速度的差距正在縮小。
同時采用了解釋執行和編譯執行這兩種方式,這種混合使用的方式就稱為 JIT (即時編譯),V8 采用的就是這種技術。
在解釋器執行字節碼的過程中,如果發現有熱點代碼,比如一段代碼被重復執行多次,這種就稱為熱點代碼,那么后臺的編譯器就會把該段熱點的字節碼編譯為高效的機器碼,然后當再次執行這段被優化的代碼時,只需要執行編譯后的機器碼就可以了,這樣就大大提升了代碼的執行效率。
最后
當然,想要了解更詳細的執行機制,可以去看看 V8 源碼,這篇文章主要帶大家捋清楚各種概念,讓你能夠知道運行一段 JavaScript 背后的工作原理,想要更深入的了解,可以看看下面這些文章:。





















