作者 | 曲檀 旭陽等
在LBS(Location Based Services, 基于位置的服務)距離約束下,候選較少制約了整個到店廣告排序系統的潛力空間。本文介紹了我們從候選類型角度進行候選擴展,通過高性能的異構混排網絡來應對性能的挑戰,從而提升本地生活場景排序系統的潛能上限。希望能給從事相關方向的同學以啟發。
1 背景與簡介
1.1 背景
美團到店廣告負責美團搜索流量的商業變現,服務于到店餐飲、休娛親子、麗人醫美、酒店旅游等眾多本地生活服務商家。質量預估團隊負責廣告系統中CTR/CVR以及客單價/交易額等質量分預估,在過去幾年中,我們通過位次上下文建模[1]、時空超長序列建模[2]等創新技術,在CTR預估問題中的用戶、上下文等方向都取得了一些突破[3],并整理成論文發表在SIGIR、ICDE、CIKM等國際會議上。不過以上論文重在模型精度,而模型精度與廣告候選共同決定著排序系統的質量。但在廣告候選角度,相比于傳統電商的候選集合,美團搜索廣告因LBS(Location Based Services, 基于位置的服務)的限制,所以在某些類目上門店候選較少,而候選較少又嚴重制約了整個排序系統的潛力空間。當用傳統方式來增加候選數量的方法無法取得收益時,我們考慮將廣告候選進行擴展與優化,以期提升本地生活場景排序系統的潛能上限。
1.2 場景介紹
單一的門店廣告不足以滿足用戶找商品、找服務的細粒度意圖訴求。部分場景將商品廣告作為門店廣告的候選補充,兩者以競爭方式來確定展示廣告樣式;此外,還有部分場景商品廣告以下掛形式同門店廣告進行組合展示。多種形式的異構廣告展示樣式,給到店廣告技術團隊帶來了機遇與挑戰,我們根據業務場景特點,針對性地對異構廣告進行了混排優化。下文以美團結婚頻道頁和美團首頁搜索為例,分別介紹兩類典型異構混排廣告:競爭關系異構廣告和組合關系異構廣告。
- 競爭關系異構廣告:門店和商品兩種類型廣告競爭混排,通過比較混排模型中pCTR確定廣告展示類型。如下圖1所示,左列首位為門店類型廣告勝出,展示內容為門店圖片、門店標題和門店星級評論數;右列首位為商品類型廣告勝出,展示內容為商品圖片、商品標題和對應門店。廣告系統決定廣告的排列順序和展示類型,當商品類型廣告獲勝時,系統確定展示的具體商品。
 圖1 競爭關系異構廣告在結婚頻道頁場景
圖1 競爭關系異構廣告在結婚頻道頁場景
- 組合關系異構廣告:門店廣告和其商品廣告組合為一個展示單元(藍色框體)進行列表排序,商品從屬于門店,兩種類型異構廣告組合混排展示。如下圖2所示,門店廣告展示門店的頭圖、標題價格等信息;兩個商品廣告展示商品價格、標題和銷量等信息。廣告系統確定展示單元的排列順序,并在門店的商品集合中確定展示的Top2商品。
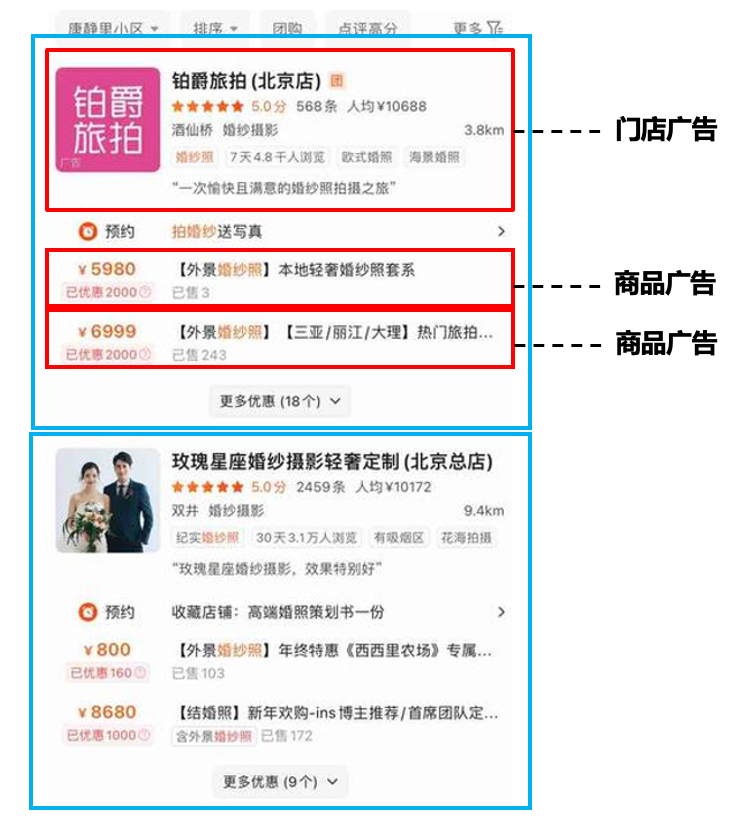
圖2 組合關系異構廣告在首頁搜索場景
1.3 挑戰與做法簡介
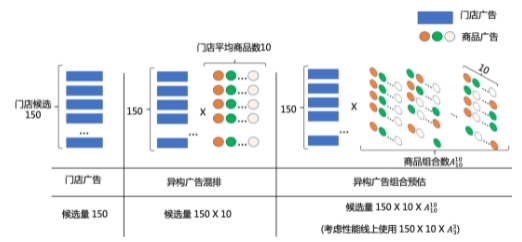
圖3 廣告候選量變化示意圖
目前,搜索廣告模型線上為基于DNN(深度神經網絡)[4-6]的門店粒度排序模型,門店候選數量受限(約150)且缺失商品等更直接且重要的決策信息。因此,我們將商品廣告作為門店的候選補充,通過門店與門店下多商品的混排打開候選空間,候選量可以達到1500+。此外,考慮廣告上下文影響,同時進一步擴展打分候選以提升排序上限,我們將門店粒度升級為異構廣告組合粒度的排序,基于此構建生成式廣告組合預估系統,候選極限達到了1500X(考慮線上性能我們最終選擇1500X)。而在探索過程中,我們遇到了以下三大挑戰:
- 商品粒度預估性能壓力:下沉到商品粒度后增加至少10倍的候選量,造成線上預估服務無法承受的耗時增加。
- 組合間關系建模困難:門店同組合商品的上下文關系使用Pointwise-Loss建模難以刻畫。
- 商品廣告冷啟動問題:僅使用經過模型選擇后曝光的候選,容易形成馬太效應。
針對上述挑戰,技術團隊經過思考與實踐,分別進行如下針對性的優化:
- 高性能異構混排系統:通過bias網絡對門店信息遷移學習,從而實現高性能商品粒度預估。
- 生成式廣告組合預估系統:將商品預估流程升級為列表組合預估,并提出上下文聯合模型,建模商品上下文信息。
- 異構廣告冷啟動優化:基于湯姆森采樣算法進行E&E(Exploit&Explore, 探索與利用)優化,深度探索用戶的興趣。
目前,高性能異構混排和生成式廣告組合預估已經在多個廣告場景落地,視場景業務不同,在衡量廣告營收的千次廣告展示收益(RPM,Revenue Per Mille)指標上提升了4%~15%。異構廣告冷啟動優化在各業務生效,在精度不下降的前提下給予流量10%隨機性。下文將會對我們的具體做法進行詳細的介紹。
2 技術探索與實踐
2.1 高性能異構混排系統
打分粒度從門店下沉為商品后,排序候選量從150增加到1500+,帶來排序潛力提升的同時,如果使用門店模型直接進行商品預估,則會給線上帶來無法承擔的耗時增加。通過分析,我們發現門店下所有商品共享門店基礎特征,占用了80%以上的網絡計算,但對于多個商品只需要計算一次,而商品獨有的、需要獨立計算的商品特征只占用20%的網絡計算。所以基于這個特性,我們參照組合預估[7]的做法,來實現異構混排網絡。主網絡的高復雜性門店表征通過共有表達的遷移學習,實現對門店網絡輸出層的復用,從而避免在進行商品預估時對門店網絡的重復計算。如下圖4所示,整個網絡分為門店網絡和商品網絡。在離線訓練階段,門店網絡(主網絡)以門店特征作為輸入,得到門店的輸出層,計算門店Loss,更新門店網絡;商品網絡(bias網絡)以商品特征為輸入,得到商品輸出層,與門店網絡的輸出層門店向量作CONCAT操作,然后計算最終的商品Loss,并同時更新門店網絡和商品網絡。為了實現線上預估時對門店網絡輸出層的復用,我們將商品以List的方式喂入模型,實現請求一次打分服務,獲得1(門店)+n(商品)個預估值。另外,對于門店的商品數不固定這一問題,我們通過維度動態轉換的方式保證維度對齊。實現保持網絡規模情況下擴大了10倍打分量,同時請求耗時僅增加了1%。圖4 異構混排網絡結構圖通過異構混排網絡,我們在性能約束下得到了門店和各個商品的預估值,但是由于廣告出口仍然以門店作為單元進行計費排序,所以我們需要根據不同業務場景特點進行預估值應用。為了描述方便,下文中用“P門店”代表門店的預估值,“P商品_i”代表第i個商品的預估值。篩選頻道頁的競爭關系異構廣告
- 篩選頻道頁內有門店和商品兩種展示類型進行競爭,獲勝的廣告類型將最終得到展示。訓練階段,每一次曝光為一條樣本,一條樣本為商品和門店其中一種類型。門店樣本只更新門店網絡,商品樣本同時更新門店網絡和商品網絡。
- 預估階段,門店和商品發生點擊概率互斥,我們使用Max算子:通過Max(P門店 ,P商品_1 ,...,P商品_n ),如果門店獲勝,則展示門店信息,門店的預估值用于下游計費排序;如果任一商品獲勝,則展示該商品信息,該商品的預估值用于下游。
首頁搜索的組合關系異構廣告
- 首頁搜索的排序列表頁中每個展示單元由門店和兩個商品組成,機制模塊對這一個展示單元進行計費排序。訓練階段,每一次曝光為多條樣本:一條門店樣本和多條商品樣本。門店樣本只更新門店網絡,商品樣本同時更新門店網絡和商品網絡。
- 預估階段,由于用戶點擊【更多優惠】前,默認展示Top2商品,所以可以選擇商品預估值最高的Top2作為展示商品,其余商品按預估值排序。我們需要預估pCTR(門店|商品1|商品2) 。從數學角度分析,我們在預估門店或商品1或商品2被點擊的概率,因此我們使用概率加法法則算子:pCTR(門店|商品1|商品2) = 1 - (1-P門店 ) * (1-P商品_1 ) * (1-P商品_2)。所以在得到門店和商品預估值之后,首先要對商品按預估值進行排序,得到商品商品的展示順序,并選擇Top2的商品預估值和門店預估值進行概率加法法則計算,得到展示單元的預估值用于門店排序計費。
雖然系統整體架構相似,但是因使用場景不同,樣本生成方式也不同,模型最終輸出的P商品有著不同的物理含義。在競爭關系廣告中,P商品作為和門店并列的另一種展示類型;組合關系廣告中,P商品則為門店廣告展示信息的補充,因此也有著不同預估值的應用方式。最終高性能異構混排系統在多個廣告場景落地,視場景業務不同,RPM提升范圍在2%~15%之間。
2.2 生成式廣告組合預估系統
在商品列表中,商品的點擊率除了受到其本身質量的影響外,還會受到其上下展示商品的影響。例如,當商品的上下文質量更高時,用戶更傾向于點擊商品的上下文,而當商品上下文質量較低時,用戶則傾向于點擊該商品,這種決策差異會累積到訓練數據中,從而形成上下文偏置。而消除訓練數據中存在的上下文偏置,有利于更好地定位用戶意圖以及維護廣告系統的生態,因此我們參照列表排序的思路[8-9],構建生成式商品排序系統,建模商品上下文信息。獲取上下文信號可以通過預估商品列表的全排列,但是全排列的打分量極大(商品候選數10的全排列打分數為10!=21,772,800)。為了在耗時允許的情況下獲取上下文信號,我們采用二次預估的方式對全排列結果進行剪枝。首次預估時采用Base模型打分,僅取Top N商品進行排列,二次預估時再利用上下文模型對排列的所有結果進行打分。將全排列的打分量從10!減少到N!(在線上,我們選擇的N為3)。但是二次預估會給服務帶來無法承受的RPC耗時,為了在性能的約束下上線,我們在TensorFlow內部實現了二次預估模塊。如下圖5所示,我們最終實現了基于剪枝的高性能組合預估系統,整體耗時和基線持平。圖5 基于剪枝的高性能組合預估系統通過剪枝和TF算子,任一商品輸入可以感知其上下文信號。為了建模上下文信息,我們提出基于Transformer的上下文自適應感知模型。模型結構如圖6所示:
- 我們首先將門店特征及商品特征分別過Embedding層得到門店Emb及商品Emb,再通過全鏈接層得到無位次商品向量和無位次的預估值;
- 將無位次商品向量與商品位次信號進行拼接,通過Transformer建模商品的上下文信息,得到包含上下文信息的商品Emb;
- 將包含上下文信息的商品Emb與位次信號再次拼接,通過DNN非線性交叉,得到包含上下文信息及位次信息的最終輸出商品預估值。通過強化商品間的交叉,達到建模商品上下文的目的,最終生成式廣告組合預估在首頁搜索取得了RPM+2%的效果提升。
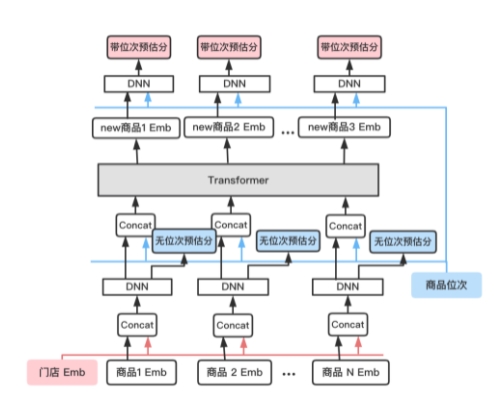
圖6 下文組合預估模型
2.3 異構廣告冷啟動優化
為了避免馬太效應,我們也會主動試探用戶新的興趣點,主動推薦新的商品來發掘有潛力的優質商品。我們在模型上線前,通過隨機展示的方式來挖掘用戶感興趣的商品。但是給用戶展示的機會是有限的,展示用戶歷史喜歡的商品,以及探索用戶新興趣都會占用寶貴的展示機會,此外,完全的隨機展示從CTR/PRS等效果上看會有較為明顯的下降,所以我們考慮通過更合理的方式來解決“探索與利用”問題。
相對于傳統隨機展示的E&E算法,我們采用基于湯普森采樣的Exploration算法[10],這樣可以合理地控制精度損失,避免因部分流量進行Exploration分桶的bias問題。湯普森采樣是一種經典啟發式E&E算法,核心思路可以概況為,給歷史曝光數(HI,Historical Impressions)較多的商品較低的隨機性,歷史曝光較少的商品給予較高的隨機性。具體的做法是我們使商品的預估值(pCTR)服從一個beta(a,b)分布,其中:
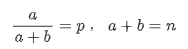
,其中p是以pCTR為自變量的函數,n是以EI為自變量的函數。根據經驗,我們最終使用的函數為:
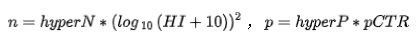
我們通過調節hyperP和hyperN兩個參數來控制最終呈現結果的隨機性。如下圖7所示,action1相比action2分布的均值更高,action3相比另外兩個分布的隨機性更強。較高的隨機性可能會帶來準確性的下降,我們通過參數離線模擬,確定全量版本的超參數。最終上線的模型在精度和效果沒有下降的前提下,展示的商品有10%的隨機性。
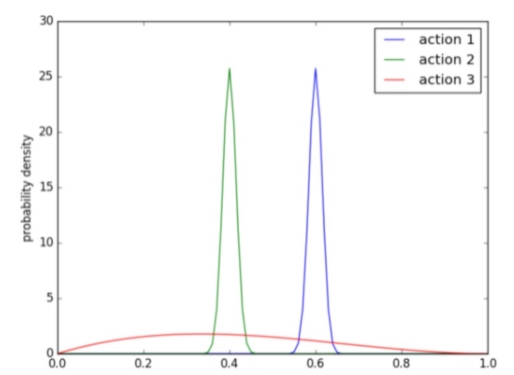
圖7 不同參數下beta分布的分布情況
2.4 業務實踐
異構混排和廣告組合預估有效地解決了LBS限制下門店候選較少的問題。對于前文介紹的兩類典型異構廣告:競爭關系異構廣告和組合關系異構廣告,我們根據其展示樣式和業務特點,將相應的技術探索均進行了落地,并取得了一定的效果。如下圖8所示:
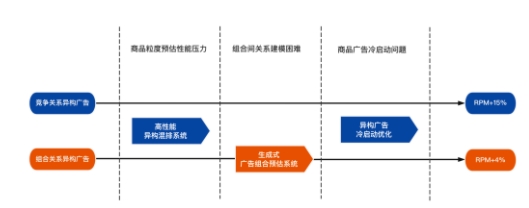
圖8 異構廣告混排技術業務實踐
3 總結
本文介紹了美團到店搜索廣告業務中異構廣告混排的探索與實踐,我們通過高性能的異構混排網絡來應對性能挑戰,并根據業務特點對異構預估進行了應用。為了建模廣告的上下文信息,我們將商品預估流程由單點預估升級為組合預估模式,并提出上下文組合預估模型,建模商品位次及上下文信息,然后,通過基于湯普森算法的E&E策略對商品冷啟動問題進行了優化,在多個場景均取得了一定的成果。近期,已經有越來越多業務場景開始了展示樣式的升級,例如美食類目由門店調整為菜品廣告,酒店類目由門店調整為房型展示,本文提到的方案與技術也在逐步的推廣落地過程中。值得一提的是,相比于美團以門店作為廣告主體,業界的廣告主體以商品和內容為主,本文提到的共有表達遷移和生成式組合預估的技巧,可以應用在商品和創意的組合問題上,更進一步拓展候選規模。廣告異構混排項目也是從業務視角出發,勇于打破原來迭代框架下的一次重要嘗試。我們希望該項目能夠通過技術手段來解決業務問題,然后再通過業務理解反推技術的進步。此外,我們也將在廣告候選問題上進行更多的探索,尋找新的突破點,從而進一步設計更完善的網絡結構,不斷釋放排序系統的潛力空間。
4 參考資料
- [1] Huang, Jianqiang, et al. "Deep Position-wise Interaction Network for CTR Prediction." Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2021.
- [2] Qi, Yi, et al. "Trilateral Spatiotemporal Attention Network for User Behavior Modeling in Location-based Search." Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021.
- [3] 胡可,堅強等. 廣告深度預估技術在美團到店場景下的突破與暢想
- [4] Cheng, Heng-Tze, et al. "Wide & deep learning for recommender systems." Proceedings of the 1st workshop on deep learning for recommender systems. 2016.
- [5] Zhou, Guorui, et al. "Deep interest network for click-through rate prediction." Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018.
- [6] Ma, Jiaqi, et al. "Modeling task relationships in multi-task learning with multi-gate mixture-of-experts." Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018.
- [7] Gong, Yu, et al. "Exact-k recommendation via maximal clique optimization." Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019.
- [8] Guo, Huifeng, et al. "PAL: a position-bias aware learning framework for CTR prediction in live recommender systems." Proceedings of the 13th ACM Conference on Recommender Systems. 2019.
- [9] Feng, Yufei, et al. "Revisit Recommender System in the Permutation Prospective." arXiv preprint arXiv:2102.12057 (2021).
- [10] Ikonomovska, Elena, Sina Jafarpour, and Ali Dasdan. "Real-time bid prediction using thompson sampling-based expert selection." Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2015.