













作者 | 家宏 順輝 國梁等
在深度學習時代,算力的需求和消耗日益增長,如何降低算力成本,提高算力效率,逐漸成為一個重要的新課題。智能算力旨在對流量算力進行精細化和個性化分配,從而實現系統算力約束下的業務收益最大化。
1 業務背景
隨著美團外賣業務的飛速發展,外賣廣告系統壓力變得越來越大,算力開始成為新的瓶頸。2021年上半年,外賣廣告的數條業務線開始出現算力資源不足的情況,算力分配效率亟待提升。在外賣場景下,流量呈現明顯的雙峰結構,廣告系統在高峰時段面臨較大的性能壓力,非高峰時段存在大量算力冗余。智能算力旨在對流量算力進行精細化和個性化分配,從而實現系統算力約束下的業務收益最大化。
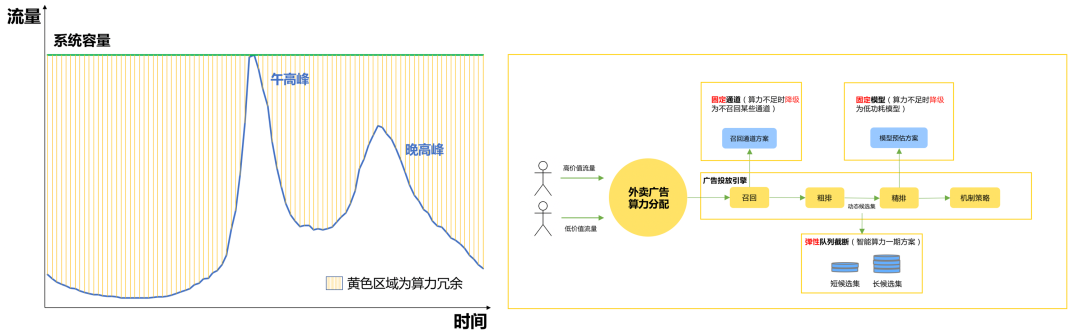
本文是廣告智能算力系列文章的第二篇,在第一篇《美團外賣廣告智能算力的探索與實踐》中[1],我們對阿里DCAF[2]線性規劃求解方案進行了外賣場景下的優化,落地了彈性隊列局部最優算力分配方案(以下簡稱“第一期”)。如上圖所示,外賣展示廣告鏈路中,召回通道和模型決策均使用固定策略,在算力不足時會丟失部分優質流量帶來的收益。
在本文中,我們提出了基于進化算法的多動作算力決策方法ES-MACA(Evolutionary Strategies based Multi-Action Computation Allocation)。在外賣廣告鏈路上,同時決策彈性通道、彈性隊列和彈性模型三個動作。在后置動作決策中,我們考慮前置模塊的決策引起的狀態變化,同時使用多任務模型聯合建模實現系統仿真模擬(離線仿真+收益預估,實現不同決策動作下的收益評估功能),實現全鏈路最優算力分配。相對第一期內容,ES-MACA在外賣展示廣告業務線上取得CPM+1.x%、收入+1.x%的效果。
2 整體思路
為了應對極大的在線流量壓力和龐大的候選集,外賣廣告投放系統將整個檢索過程設計成候選集依次遞減的漏斗型級聯架構,主要包含召回、粗排、精排、機制等模塊。在第一期中,我們把算力分配的手段定義為彈性動作,并結合外賣場景歸納了彈性隊列、彈性模型、彈性通道和彈性鏈路等四種動作,具體動作的定義如下:
- 彈性隊列:線上檢索是一個漏斗的過程,不同價值流量可以在級聯漏斗的各模塊中分配不同候選隊列長度。
- 彈性模型:在模型預估服務中,對于不同價值流量可以選擇不同大小模型,大模型相對小模型預估效果更好的同時,消耗的算力也更多。
- 彈性通道:在召回場景中,不同價值流量可以選擇不同復雜度的召回通道和召回通道的路數。
- 彈性鏈路:在檢索鏈路上,不同價值流量可以選擇不同復雜度的檢索鏈路。
2.1 算力分配問題形式化描述
在一個包含M個算力決策模塊的鏈路中,全鏈路最優的智能算力的目標可通用的描述為:通過智能化決策M個模塊的算力檔位,在整體算力滿足約束的條件下,使得整體流量收益最大化。該問題的一般形式化描述為: 以上是多個算力決策模塊的場景,在外賣展示廣告中,對算力和收益較為敏感的決策模塊為廣告召回策略、精排隊列長度和精排預估模型,分別對應彈性通道、彈性隊列和彈性模型三個動作。在本期中,我們同時考慮彈性通道、彈性隊列和彈性模型三個模塊的算力聯合決策。
以上是多個算力決策模塊的場景,在外賣展示廣告中,對算力和收益較為敏感的決策模塊為廣告召回策略、精排隊列長度和精排預估模型,分別對應彈性通道、彈性隊列和彈性模型三個動作。在本期中,我們同時考慮彈性通道、彈性隊列和彈性模型三個模塊的算力聯合決策。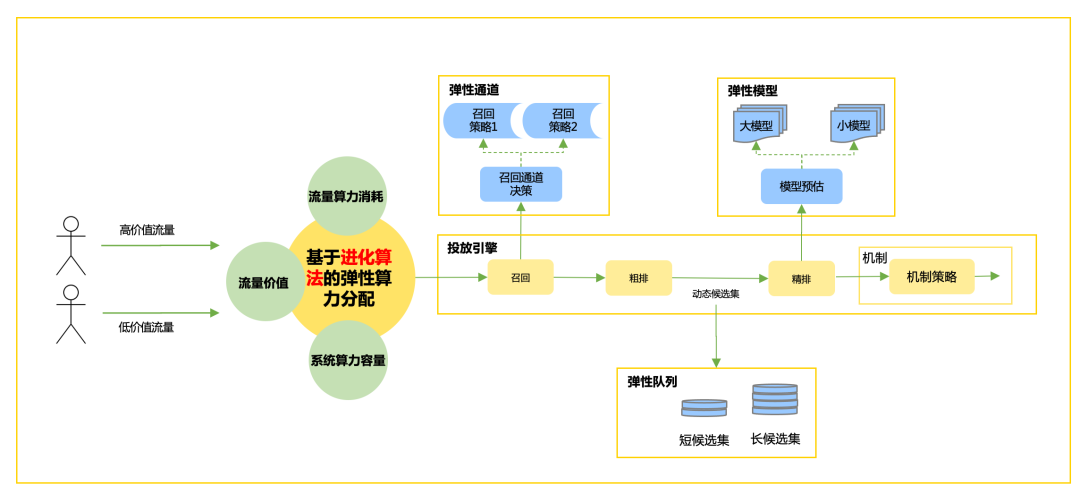 在多個模塊聯合決策時,同一個請求的不同模塊動作之間互相會產生影響。如下圖所示,彈性通道決策結果決定了真實召回隊列(包括候選隊列的長度和廣告類型等信息),直接影響了彈性隊列的輸入狀態。同理,彈性隊列的決策結果影響了彈性模型的輸入狀態。因此,在多動作聯合建模中,我們增加了請求“狀態”特征,讓決策動作與系統產生交互,更好地擬合系統狀態的過程。
在多個模塊聯合決策時,同一個請求的不同模塊動作之間互相會產生影響。如下圖所示,彈性通道決策結果決定了真實召回隊列(包括候選隊列的長度和廣告類型等信息),直接影響了彈性隊列的輸入狀態。同理,彈性隊列的決策結果影響了彈性模型的輸入狀態。因此,在多動作聯合建模中,我們增加了請求“狀態”特征,讓決策動作與系統產生交互,更好地擬合系統狀態的過程。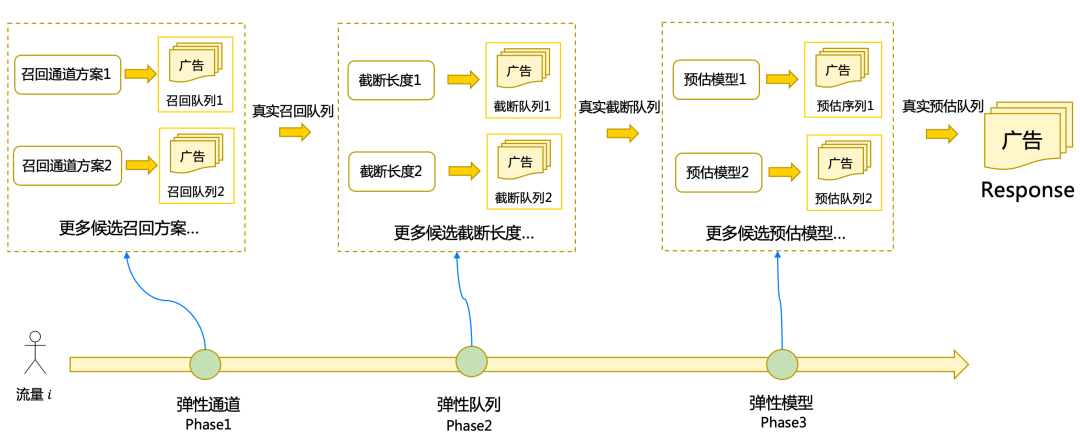
2.2 挑戰分析
外賣智能算力第一期中,我們針對外賣廣告場景,在DCAF方案的基礎上進行了一系列探索和改進,并初次進行了模型彈性分配的嘗試,取得了不錯的收益。近年,阿里CRAS[3]方案給出了一種應用于預排、粗排和精排隊列聯合優化的聯合最優算力分配線性規劃方案。從彈性動作的分類來看,該方案以一種優雅的方式解決了三個彈性隊列的聯合優化問題,CRAS通過一些數據分析和合理假設,將原始問題拆解為三個互相獨立且相似子問題,然后分別對三個子問題進行求解。
但是已有方案是基于線性規劃方案的,且僅關注一個或多個彈性隊列優化問題,在面對非彈性隊列動作組合,如彈性通道和彈性模型時,方案無法直接遷移。特別地,在約束條件或優化目標發生變化時,線性規劃方案需要重新對特定業務問題進行建模和求解,需消耗大量的人力;此外,目前已有線性規劃方案的問題建模和求解過程中往往包含一些業務數據相關的強假設,這些假設在新的業務上可能難以滿足,這進一步使得已有方案難以拓展遷移到新的業務問題上。
由于外賣場景的LBS限制,外賣廣告的候選隊列相對非LBS電商場景較短,不需要經過復雜的預排-粗排-精排的過程。在全鏈路上,我們更關注召回通道、精排隊列長度、精排預估模型等模塊的算力分配,這些模塊其實對算力更加敏感。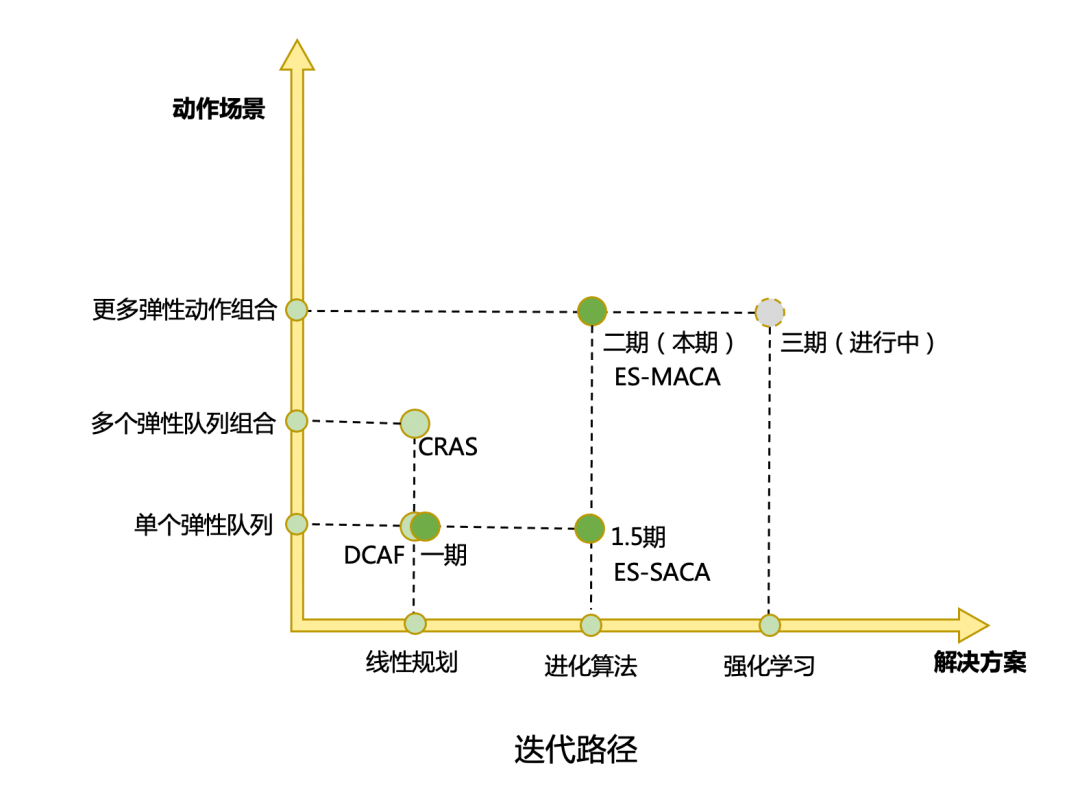 整體來看,美團外賣廣告場景全鏈路最優算力分配的挑戰主要包括以下兩個方面。通用化問題
整體來看,美團外賣廣告場景全鏈路最優算力分配的挑戰主要包括以下兩個方面。通用化問題
- 挑戰點:已有方案與業務耦合過重,一方面,在約束條件或優化目標發生變化時,線性規劃方案需要重新對特定業務問題進行建模;另一方面,對特定的業務線,往往需要根據業務數據特性增加一些強假設。外賣廣告目前包括十余條業務線,每條業務線中又存在多個算力決策場景,若對每條業務線的每個場景都單獨建模,人力成本巨大。
- 應對思路:采用通用解決方案并沉淀為基礎通用能力,為廣告業務的不同算力決策場景賦能,降本增效。
序列決策問題
- 挑戰點:在全鏈路算力分配時,多個決策模塊之間互相耦合,共同對影響當前流量的最終算力和收益。如下圖所示,前置動作決策后,需要跟真實環境交互才能獲取動作決策后的交互結果,模塊之間涉及到系統狀態轉移,需要在最后一個決策模塊完成決策后才能獲得流量收益,這使得我們難以通過常規方式建模。
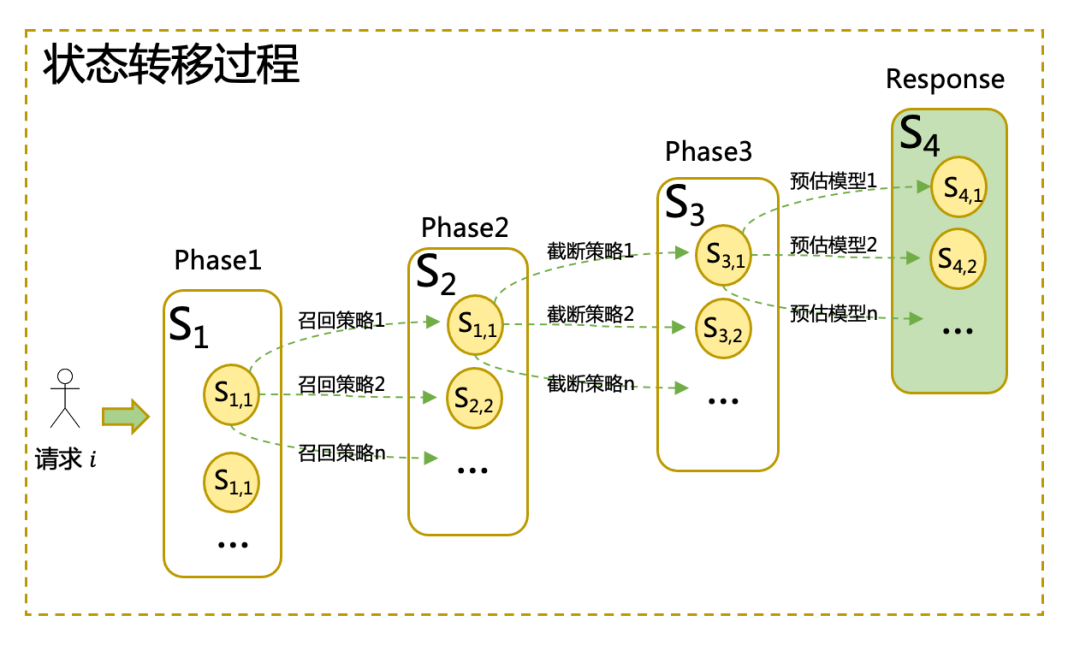
- 應對思路:在全鏈路最優算力分配問題建模過程中,增加系統在各鏈路上的“狀態”轉移過程,后置模塊根據前置模塊的決策結果和請求狀態進行決策。
綜合考慮以上兩個問題,我們將外賣廣告全鏈路最優算力分配問題建模為多階段決策問題(每個決策模塊對應一個決策階段),按時間順序依次決策召回方案、截斷隊列和預估模型。每個階段中,由Agent與環境交互和決策,Agent參數可使用進化算法或強化學習求解。
全鏈路算力分配過程可建模為馬爾科夫決策過程(Markov Decision Process, MDP)或部分可觀測馬爾科夫決策過程(Partially Observable Markov Decision Process,POMDP)。如上圖所示,狀態轉移發生在相鄰的兩個階段之間,各階段分別有不同的候選動作(如召回策略,截斷長度和預估模型編號等),Reward則在最后一個階段動作執行后通過系統反饋獲得。
我們可以收集在線日志數據,使用離線強化學習(Offline RL)求解Agent;在不擔心線上收益受損的情況下,也可以使用在線強化學習(Online RL)求解Agent。但由于業務場景復雜,各階段算力約束難以統一,不管是離線強化學習還是在線強化學習,都面臨多階段強約束難以建模和求解的問題。
而進化算法作為一種應用廣泛、魯棒性強的全局優化方法,有以下優點:
- 避免局部最優:進化算法參數搜索過程具有一定的隨機性,不易陷入局部最優;
- 可并行化:進化算法參數搜索過程可并行,可緩解評估過程耗時問題;
- 應用廣泛:進化算法可以能夠處理不連續、不可微和非凸優化問題,且不需要過多先驗知識;
- 簡單易用:一些進化算法,比如交叉熵方法(Cross-Entropy Method,CEM)可以優雅地解決各種約束問題,不需要直接求解約束問題。
進化算法能很好地解決外賣廣告場景中的問題,既容易擴展到其他業務線,又能非常方便地建模各種決策問題。因此,本期我們選擇進化算法來求解外賣場景全鏈路最優算力分配問題。在后續工作中,我們會嘗試使用強化學習方案求解。如本節迭代路徑(圖)所示,我們在1.5期中嘗試了基于進化算法的單動作算力決策方法ES-SACA(Evolutionary Strategies based Single-Action Computation Allocation),驗證了進化算法在算力分配場景的有效性。接下來,本文主要介紹基于進化算法的多動作算力決策方法ES-MACA。
3 方案設計
為了實現廣告系統全鏈路上的最優算力分配,我們設計了如下決策方案:
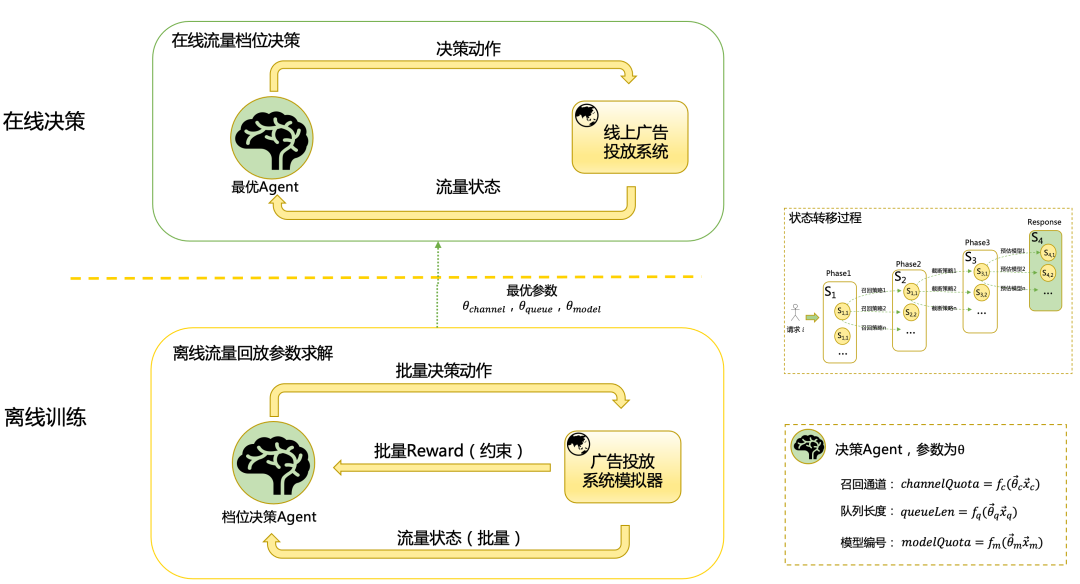
離線訓練:隨機選擇決策Agent參數,批量回放歷史流量,Agent與廣告投放模擬系統進行交互,完成狀態轉移過程。根據系統返回的Reward優化決策Agent參數,最終輸出離線最優Agent參數,并同步到線上。
在線決策:對于線上單條請求,使用離線最優Agent與線上系統進行交互和決策。
在本期中,我們使用進化算法求解Agent參數。進化算法參數尋優的核心是組合動作價值評估,由于涉及到狀態轉移過程,組合動作價值評估不再是一個簡單的監督學習問題,Agent需要依次與系統交互并執行決策動作,直到最后一個階段的動作完成時才能從系統中取得收益。一種簡單的方案是讓Agent在線學習,與系統交互的同時優化自身參數,但在線學習會影響業務收益,這對我們來說是不可接受的。為了解決這個問題,我們通過構造廣告投放模擬器,模擬線上廣告系統環境,由該模擬器與Agent進行交互,并反饋收益(Reward)。
3.1 全鏈路最優算力決策
3.1.1 問題建模
根據外賣廣告的投放場景,我們基于進化算法對整個問題建模如下:
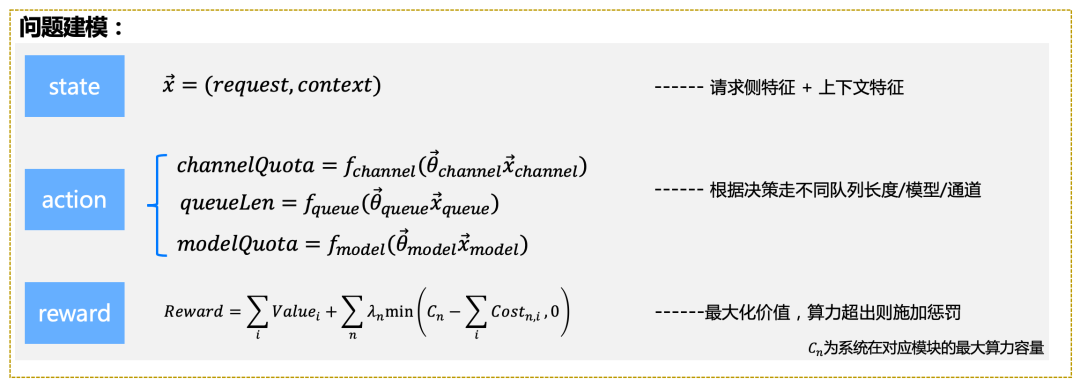
(1)彈性通道:召回動作,一維向量 , 表示是否該通道是否召回。
(2)彈性隊列:截斷長度,整數值。
(3)彈性模型:模型編號,整數值。
- 狀態:上下文特征,請求隊列特征等(后置決策模塊的狀態依賴前置模塊的決策,比如彈性通道的決策直接影響了彈性隊列時隊列長度)。
- 動作:在不同階段定義不同。
- Reward:收益目標為業務收益,為了保證求解參數符合算力約束條件,在Reward中添加算力約束條件。對于越嚴格的約束條件,算力系數 越大。
3.1.2 離線參數求解
 離線參數求解主要分為進化算法參數尋優和Reward評估兩個模塊。
離線參數求解主要分為進化算法參數尋優和Reward評估兩個模塊。
- 參數尋優模塊:實現通用的進化算法尋參流程,負責參數初始化、參數評估(依賴Reward評估模塊)、參數采樣和參數進化等過程,并最終輸出最優參數。
- Reward評估模塊:根據指定Agent的具體參數,批量回放線上流量,讓Agent與環境進行交互(離線仿真),最后根據交互結果預估當前參數對應的收益。
3.1.2.1 參數尋優
參數尋優模塊使用進化算法求解參數。本文以CEM為例,對參數求解過程進行詳細講解:
- 參數初始化:初始化參數均值和方差,根據指定的均值和方差隨機采樣N組參數。
- Reward評估
- 離線仿真:回放流量,讓當前參數對應的Agent與離線模擬器交互,完成狀態轉移過程,在所有模塊決策完成后,離線仿真模塊輸出回放流量交互結果。
- 收益預估:根據回放流量交互結果,預估當前交互結果下的期望收益。
- 參數挑選:按照參數合并流量期望收益,挑選使得所有流量整體收益最高的Top-K組參數。
- 參數進化:根據Top-K參數,計算新的參數均值和方差。
- 參數采樣:根據新的均值和方差,重新采樣N組參數,并跳轉到第二步,直到參數均值和方差收斂。
Tips:NES方案在本場景中效果不如CEM,原因是NES對帶約束問題(特別是多約束問題)Reward設計要求過高,在真實場景中難以求解到嚴格滿足約束的參數。3.1.2.2 Reward評估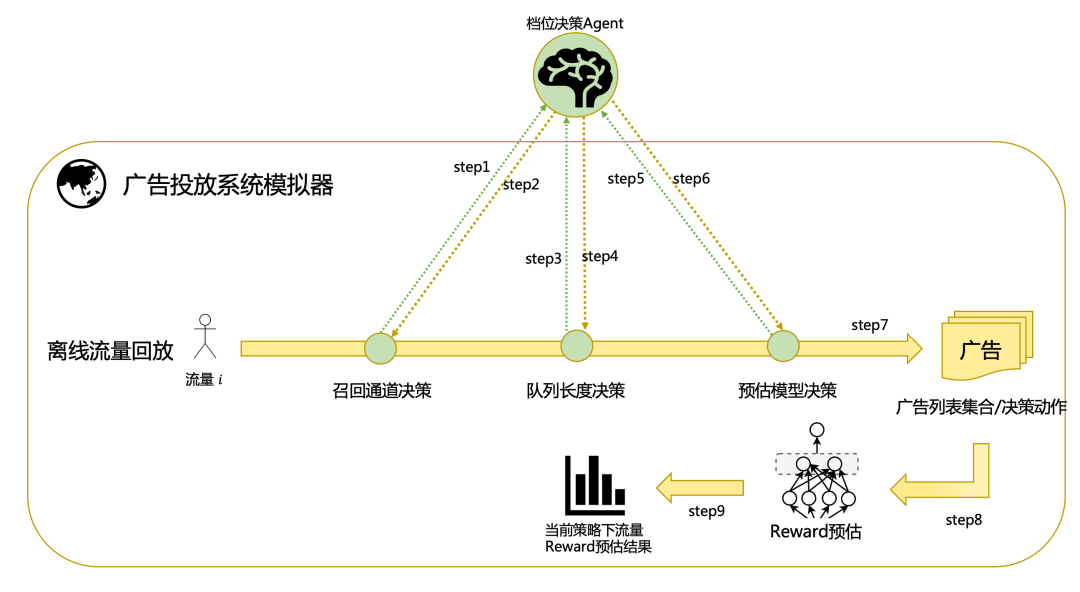 離線Reward評估流程:在離線訓練時,對于選定的Agent和歷史流量。
離線Reward評估流程:在離線訓練時,對于選定的Agent和歷史流量。
- Step1:模擬器構造流量初始狀態特征,并反饋給Agent。
- Step2:Agent根據模擬器給出的流量狀態特征進行召回通道檔位決策。
- Step3:模擬器按照Agent給出的召回決策結果進行隊列召回,并將召回結果反饋給Agent。
- Step4:Agent根據召回結果及初始流量狀態進行隊列長度決策。
- Step5:模擬器按照Agent給出的隊列長度決策結果模擬截斷操作,反饋截斷后的隊列狀態給Agent。
- Step6:Agent根據截斷隊列進行預估模型編號決策。
- Step7:模擬器根據模型編號決策給出廣告列表集合以及決策相關特征。
- Step8:將離線模擬的廣告列表結果輸入收益預估模型,預估每條請求對應的離線收益。
- Step9:統計整體流量的Reward,作為當前Agent策略的評估結果。
3.1.2.2.1 離線仿真
在線環境交互面臨的困境(離線仿真的必要性):理論上,決策Agent與在線環境交互能獲得最真實Reward(收益)反饋,但直接利用在線流量探索會導致以下問題:
- 在線收益損失:在線探索Agent收益的過程是有損的,特別是在策略學前期,策略決策幾乎是隨機的,線上算力約束和收益都無法得到保障。
- 流量利用率低:Agent學習往往需要幾十甚至上百輪的訓練,每輪訓練中又包含多組可行參數,為了積累置信的流量數據,每組參數的流量不能太少,總體來說訓練時間和效率將是難以接受的。
離線仿真的最終目標:復現線上交互邏輯和收益反饋。
- 基本思路:雖然無法完全復現線上的復雜環境,但參照線上環境交互邏輯,可以通過離線廣告系統模擬器在效率和準確性之間做一個取舍。
- 其他模塊:為了達成這個目標,對于特定的廣告隊列信息,我們可以使用有監督學習模型對其流量Reward進行預估。
離線仿真+收益預估解決方案: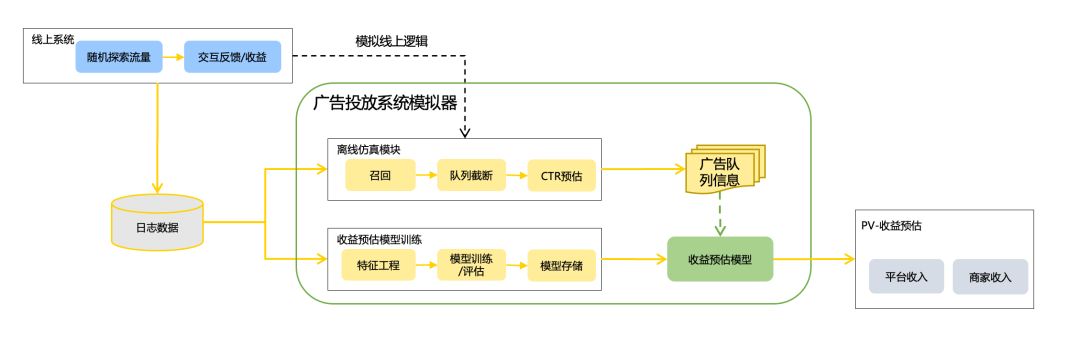
- 線上隨機探索流量:在線留下少量隨機探索流量,隨機決策每個階段的候選動作,同時記錄流量日志和線上系統的交互結果。
- 離線仿真系統:對歷史流量日志,仿照線上邏輯,模擬召回,隊列截斷、粗排CTR預估等邏輯生成離線交互結果。
- 收益預估:作為離線Reward評估的核心模塊,收益預估決定了參數的進化方向,我們將在下一節對收益預估方案進行詳細介紹。
3.1.2.2.2 收益預估
目標和挑戰點
- 數據稀疏問題:由于建模鏈路較長,在用戶轉化數據非常稀疏的情況下,大部分流量都沒有轉化動作發生(意味著商家收益為0)。
- 目標:基于線上空白流量和隨機探索流量,預估請求在不同動作下的期望收益。
- 挑戰點:不同于傳統廣告中“用戶-廣告”粒度的局部鏈路CTR、CVR以及GMV預估任務,本文是請求粒度的全鏈路收益預估,包含了請求曝光、點擊、下單(轉化)的整個過程,問題更加復雜,特別是面臨數據稀疏問題。
模型預估方案
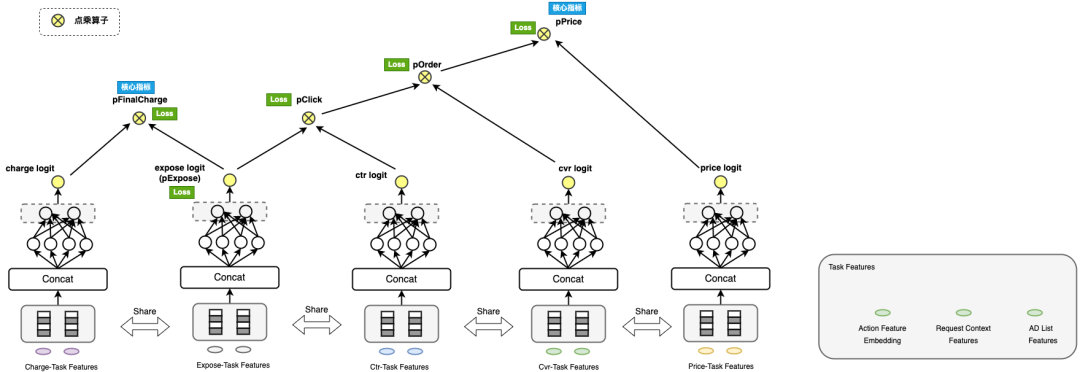
- 考慮到商家收益數據過于稀疏,曝光、點擊數據則較為稠密,同時考慮到曝光(平臺收益)、點擊、下單(商家收益)等行為是強相關的行為,本次預估方案使用多任務模型聯合建模。
- 模型設計
- 特征工程
- 將各階段的特征離散化后通過Embedding加入模型中。
- 根據不同隊列長度下的流量數據分布情況,將隊列長度等特征進行人工分桶再通過Embedding加入模型中。
3.1.3 在線決策
對于線上單條請求,使用離線最優Agent與線上系統進行交互和決策。和離線評估流程一致,依次按照如下流程執行決策過程:
- Step1:系統反饋流量初始狀態至Agent。
- Step2:Agent根據系統流量狀態進行召回通道檔位決策。
- Step3:系統按照Agent給出的召回決策結果進行隊列召回,并將召回結果反饋給Agent。
- Step4:Agent根據召回結果及初始流量狀態進行隊列長度決策。
- Step5:系統按照Agent給出的隊列長度決策結果執行截斷操作,反饋截斷后的隊列狀態給Agent。
- Step6:Agent根據截斷后隊列狀態進行預估模型編號決策。
- Step7:系統按照Agent給出的模型編號調用預估服務。
3.2 系統建設

在智能算力第一期中,我們已經完成了以決策組件為核心,以采集、調控和離線組件為支撐的智能算力系統基本建設。在本期中,我們圍繞著從單動作局部最優決策擴展到多動作組合最優決策的核心需求。在系統建設上,除了多動作組合最優決策的基本能力建設外,更關注的智能算力系統的穩定性和通用性建設,從而支撐智能算力系統在外賣廣告全業務線的全面應用。
3.2.1 決策組件Agent
決策組件Agent作為智能算力系統的客戶端,嵌入到廣告投放系統中各個模塊,負責系統流量算力的分發決策。在本期中,我們主要在決策能力上進行了輕量化、精細化迭代,以及相關能力的標準化建設。
在決策能力上
建設輕量的多動作組合決策能力:我們基于進化算法實現了輕量的多動作組合決策能力,進化算法相關前文已經介紹,這里主要介紹下輕量化。
- 為什么需要輕量化:在廣告投放系統中,對于線上的時延要求非常嚴苛,在多動作下需要進行序列決策,決策次數理論上等于決策動作的數量,因此智能算力決策必須在效果不降(或微降)下盡可能的輕量化,才能滿足線上RT要求。
- 如何建設:(1) 模型本地化,減少網絡時延,這個也是將決策能力封裝到SDK而不是建設模型決策服務的主要原因。(2) 模型輕量化,通過特征工程工作,盡可能地減少特征數量,減少在線特征處理的性能壓力。(3) 決策并行處理,決策動作盡量和線上已有流程并行處理,減少整體鏈路耗時。
- 輕量化效果:多動作組合決策相對單動作決策,廣告鏈路耗時:TP99+1.8ms、TP999 +2.6ms,滿足線上RT要求。
建設精細化的系統狀態反饋控制能力:我們基于系統狀態的實時收集和PID反饋控制算法,對算力檔位參數進行微調,實現廣告投放系統在動態算力分配過程中的穩定性保障。
- 為什么需要精細化:在廣告投放系統中,穩定性非常重要,從單動作決策到復雜的多動作決策,智能算力決策的參數檔位越來越多,對系統穩定性影響也越來越大,粗粒度的系統狀態反饋控制已經無法保障系統穩定。在第一期彈性隊列方案中也出現過穩定性調控異常的情況,在只依據粗粒度的整體集群系統狀態數據進行穩定性調控時,會偶發單機性能異常引起整體集群狀態變化劇烈,導致算力調控不穩定。
- 如何建設:一方面是系統狀態數據的精細化,數據粒度從集群細化到機房和單機,同時數據指標支持細粒度的自定義擴展。另一方面是系統調控目標和策略的精細化,調控目標從集群的整體穩定細粒度到機房和單機穩定,我們將系統狀態實時反饋控制的最小單位定義為一個調控器,對于每一個調控目標,需要一個或一組調控器支持。另外,為更好地支持單機粒度的反饋控制,我們將系統狀態反饋控制能力從調控組件遷移復用到了決策組件,決策組件可以通過容器信息讀取和攔截的方式,直接采集部分單機粒度的狀態指標,并將調控結果作用到嵌入的機器,形成閉環調控;單機粒度的反饋控制不再強依賴采集組件的鏈路反饋,系統狀態反饋的時延,也從秒級降低到了毫秒級,極大地提高了反饋控制的準確性和效率。
在標準化建設上
在多動作組合決策下對在線決策有了新的要求,一方面需要考慮通用性,做好基礎能力沉淀,另一方面需要和上層業務減少耦合,從而賦能更多動作和業務場景;同時外賣廣告工程架構已經完成了階段性的??平臺化建設??[4],其中標準化是平臺化建設的基礎,因此智能算力決策組件分別從功能、數據、流程上進行了標準化建設。智能算力的標準化建設,對智能算力從單動作決策到多動作組合決策再擴展到各大業務場景(點—>線—>面)的全面建設,具有重要意義。
- 功能標準化
我們將最小不可拆分的功能單元抽象為Action,在智能算力決策鏈路上的Action主要有:實驗、特征拉取、特征計算、詞典處理、參數處理、DCAF決策、ES-MACA決策、系統狀態反饋控制、日志收集、監控等。通過Action的復用和擴展,提高在新動作場景和業務線上的接入效率。
- 數據標準化
在廣告工程平臺化建設中,使用上下文Context描述Action執行的環境依賴,包含輸入依賴、配置依賴、環境參數依賴等。在智能算力在線決策中,我們在廣告基礎Context下擴展了智能算力Context,封裝和維護智能算力的環境依賴,主要包含標準化的輸入輸出、決策特征、決策參數、決策策略等,Action間基于Context實現數據交互。
- 流程標準化
業務的調用流程是完成功能和數據的組合,統一的流程設計模式是業務功能復用和提效的核心手段,我們基于平臺化建設的管理平臺和調度引擎,通過對Action的可視化拖拽,實現了智能算力功能的DAG編排和調度。
3.2.2 采集和調控組件
采集組件負責實時采集廣告投放系統的狀態數據,并進行標準化預處理,調控組件一方面依賴狀態數據實現對整個系廣告投放統狀態的實時感知和系統模塊粒度的算力調控;另一方面作為智能算力系統的中控服務,負責智能算力系統的系統管理,包含業務管理、策略管理、動作管理以及元信息管理等。
我們將系統狀態實時反饋控制的最小單位定義為一個調控器,對于每一個動作決策,會涉及一到多個模塊的算力變化,而每個模塊的算力變化會帶來多個數據指標的變化,因此對于一個動作可能需要配置多個調控器。從單動作決策擴展到多動作,這些調控器的數量會越來越多,如何提高對調控器的管理和接入效率,是一個關鍵問題。這里我們主要進行了異構數據標準化、調控流程通用化建設,基本實現了新調控場景的配置化接入,無需開發和發版。
異構數據標準化采集組件有多個異構數據源,包含來著美團監控系統CAT上報的業務數據、Falcon收集的機器指標數據,還有部分決策組件上報的數據。經過對數據格式和內容的分析,我們首先將數據以系統模塊Appkey進行劃分,Appkey之間數據獨立,同時從數據類型(Type)出發,把數據分為業務指標(Biz)和機器指標(Host);從數據維度(Dimension)出發,把數據分為集群粒度(Cluster)、機房粒度(IDC)、單機粒度(Standalone);具體的指標(Metric)包含QPS、TP99、FailRate、其他擴展指標等。

調控流程通用化
有了異構數據的統一表達,我們就可以設計通用的調控流程,我們以ProductId作為調控業務場景的唯一標識,以ControllerId作為調控器的唯一標識,一個ProductId映射一組ControllerId,每一個調控器Controller包含輸入指標、調控策略、策略參數、輸出結果。
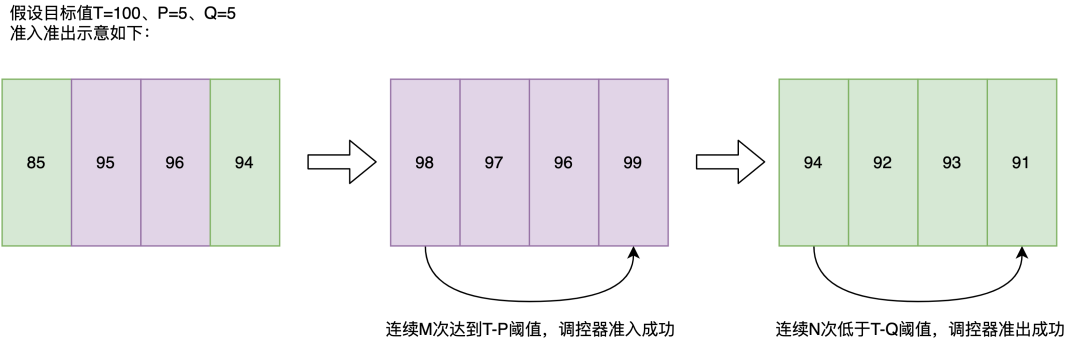
通用的調控過程為:獲取配置的輸入指標、調控策略,基于不同的調控策略選擇不同的策略參數,執行該調控策略得到對應的輸出結果。另外,我們對調控器的調控效率和穩定性進行了優化。在外賣的雙峰流量場景下,在非高峰時段,PID算法的累計誤差容易積累過大,導致到了高峰時段調控周期長,系統狀態反饋調節慢;同時也存在系統抖動或數據毛刺產生的不必要調控的情況。
基于此,我們采用了滑動窗口準入準出的機制,來提高效率和準確性。如下圖所示,我們對于每一個調控器,維護了一個系統指標的滑動統計窗口,當連續M次系統指標達到了PID目標值T-設置的閾值P,該調控器才成功準入,誤差開始累計;同時當連續N次系統指標低于PID目標值T-設置的閾值Q,該調控器成功準出,累計誤差清零。
3.2.3 離線組件
離線組件負責離線模型訓練和參數求解等任務,主要包含樣本收集、模型訓練和參數求解三個部分。
- 樣本收集:在線上流量中,留出少量隨機探索流量,隨機決策召回通道、隊列長度以及不同預估模型,同時將隨機動作以及系統交互數據落表。
- 模型訓練:離線處理隨機流量日志,生成訓練樣本,訓練收益預估的DNN模型。
- 參數求解:在CEM求解過程中,對于給定的策略,模擬線上交互環境生成流量請求信息,然后使用收益預估模型預估當前廣告隊列的收益,從而實現CEM策略評估。
4 實驗
4.1 實驗設置
系統算力容量的選取
算力容量指標選取和第一期一致。一方面,為了保證線上系統能根據實時流量快速調整,仍選擇15min作為最小的調控單元;另一方面,離線模擬選用的系統容量為過去一周的午高峰流量算力。
Baseline選取選取
無智能算力(固定決策)的流量作為對照組。
離線仿真模擬器——流量價值預估
使用過去14天非實驗組數據作為訓練集,進行兩階段訓練(一階段全流量訓練,二階段隨機探索流量訓練),使用當日隨機探索流量作為測試集。
離線參數求解
外賣場景中,同環比流量變化趨勢基本一致,我們通過重放過去一周流量,離線計算每個時間片內(15分鐘為一個時間片)最優參數并存儲為詞表。
4.2 離線實驗
實驗說明:
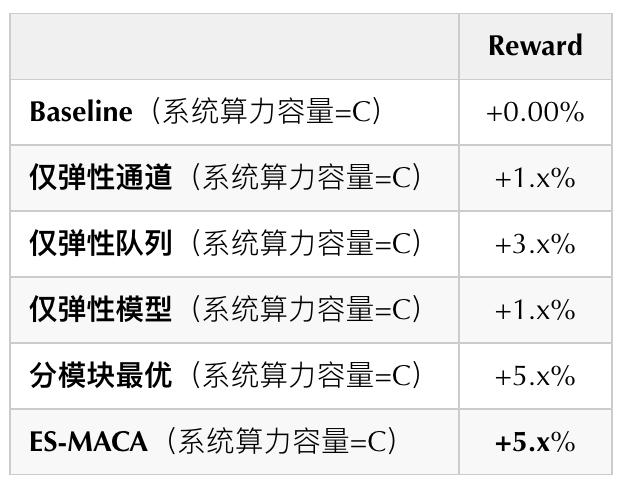
- Baseline:算力C下的固定決策結果。
- 僅彈性通道:在“僅彈性通道”實驗中,隊列決策和模型決策使用Baseline固定方案,“僅彈性隊列”和“僅決策模型”實驗組則與之類似。
- 分模塊最優:依次學習彈性通道、彈性隊列、彈性模型,當前模塊在學習時前置模塊的參數固定為已經學到的最優參數,后置模塊則使用Baseline固定方案。
- ES-MACA(全鏈路最優):彈性通道+彈性隊列+彈性模型同時學習。
從離線實驗的效果來看,我們有以下結論:
- 三個單動作的最優結果整體收益加和大于分模塊最優,也大于ES-MACA,說明三個模塊策略會相互影響,聯合優化時多動作的收益不是簡單的加和關系。
- 分模塊最優方案效果不如ES-MACA方案效果(ES-MACA對比分模塊最優有0.53%的提升),說明后置模塊的策略對前置模塊的決策效果也存在一定影響。
4.3 在線實驗
通過一周的線上ABTest實驗,我們在外賣廣告驗證了本方案的收益如下:
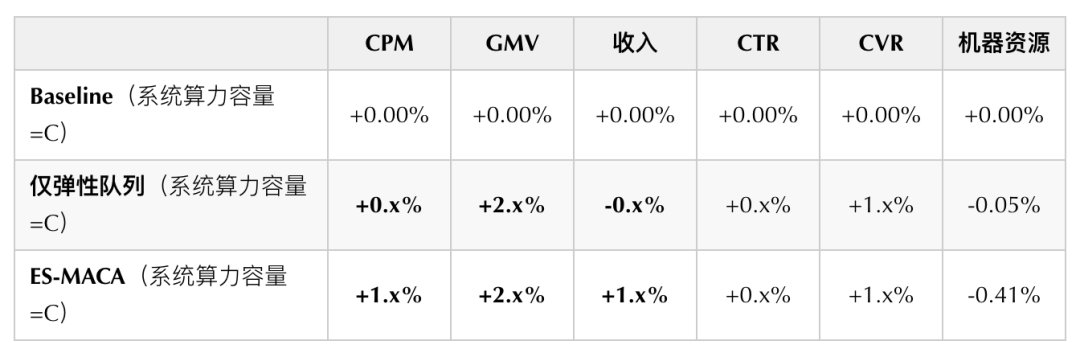
實驗設計說明:
- Baseline:對照組,無任何智能算力決策。
- 僅彈性隊列:實驗組1,僅決策彈性隊列(與一期方案一致)。
- ES-MACA(全鏈路最優):實驗組2,同時決策彈性通道、彈性隊列和彈性模型。
5 總結與展望
這篇文章主要從全鏈路最優算力決策和系統建設兩個方面,介紹了美團外賣廣告智能算力從線性規劃算法到進化算法的技術演進過程,給出了一種基于進化算法的多動作算力分配方案(ES-MACA)。未來,在算法策略上,我們將嘗試強化學習算法,對系統全鏈路組合下的算力最優分配問題進行更精細化的建模和求解;在系統建設上,我們還將嘗試和美團內部基礎架構部門進行合作,從在線系統擴展到在線/近線/離線三層系統,通過智能算力統一決策調度,充分挖掘數據和算力的潛力。
6 參考文獻
- [1] 順輝、家宏、宋偉、國梁、乾龍、樂彬等,美團外賣廣告智能算力的探索與實踐。
- [2] Jiang, B., Zhang, P., Chen, R., Luo, X., Yang, Y., Wang, G., ... & Gai, K. (2020). DCAF: A Dynamic Computation Allocation Framework for Online Serving System. arXiv preprint arXiv:2006.09684.
- [3] Yang, X., Wang, Y., Chen, C., Tan, Q., Yu, C., Xu, J., & Zhu, X. (2021). Computation Resource Allocation Solution in Recommender Systems. arXiv preprint arXiv:2103.02259.
- [4] 樂彬、國梁、玉龍、吳亮、磊興、王焜、劉研、思遠等,??廣告平臺化的探索與實踐 | 美團外賣廣告工程實踐專題連載??。
7 本文作者
家宏、順輝、國梁、乾龍、樂彬等,均來自美團外賣廣告技術團隊。























