難道沒有完美的存儲引擎?
存儲引擎是數據庫的核心組件,存儲引擎的一些特性決定了數據庫的一些基本性能特性。存儲引擎的選擇也是數據庫開發人員十分謹慎的一個方面。以前我也在一些文章里介紹了一些常見的存儲引擎,也對這些存儲引擎的優缺點做了概括。不過如果沒有真實的去使用,去匹配應用負載,僅僅是紙上談兵,是完全不夠的。
目前數據庫中使用最為廣泛的存儲引擎不外乎兩個系列三種引擎,分布式數據庫喜歡采用的LSM-TREE存儲,以及普通通用型數據庫常用的BTREE/HEAP存儲。BTREE和HEAP存儲是兩種十分相近的存儲引擎結構,Oracle,PostgreSQL,MySQL等數據庫都使用BTREE/HEAP結構。BTREE是一個泛稱,實際上數據結構是一棵增強的B+TREE。

這是一張來自網上的兩大陣營的一些數據庫產品的清單,我們可以看出傳統數據庫使用B-TREE結構的比較多,而一些新興的數據庫系統往往使用LSM-TREE。LSM-TREE是Log-Structured Merge Tree的簡稱,是一種典型的不可變結構的存儲引擎,其目的是為了降低可變結構存儲引擎中寫入數據需要先找到已經存在的PAGE,然后再進行修改的成本,從而實現更高并發的寫入。因此LSM-TREE引擎的數據庫天生對高并發寫入/修改操作十分友好。不過LSM-TREE結構也不是完美的,在讀性能上需要在多個副本之間做協同,因此讀性能會受到一定的影響。
HEAP/BTREE結構的存儲引擎雖然從結構上來說比較接近,不過依然存在一定的差異。在我們常見的數據庫中,Oracle、PostgreSQL等是采用HEAP結構的,這種結構的頁和不同的BTREE頁不同,采用slotted page。Mysql、達夢等數據庫使用的是傳統的BTREE存儲結構。
實際上這么說也不是很準確,只能說這些數據庫的默認存儲引擎是使用這種數據組織方式的。實際上Oracle中有heap表,有簇表,有混合列壓縮的表。其中簇表是BREE結構的。達夢的存儲引擎有多種數據組織方式:B樹數據、堆表數據、列存數據、位圖索引,其中B樹數據是普通的達夢表的默認組織方式。
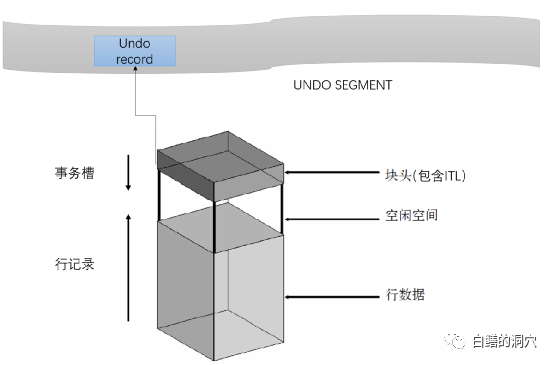
Oracle的數據塊結構是一種典型的SLOTTED PAGE的結構,塊頭從上往下增長,而數據從尾部向塊頭生長。中間是一個可變長的slot指示器。
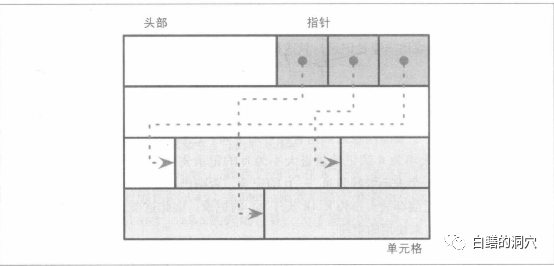
如上圖所示,通過一個定長數組指示器結構,指出每一行行頭的位置,這主要是為了解決不定長記錄的存儲問題,從而使空間利用率達到最高。

Oracle數據塊使用一個kdbt的結構來指出某個block中有多少條記錄,并且kdbpri這個指示器與塊頭的偏移量。kdbpri就是這個slot數組。
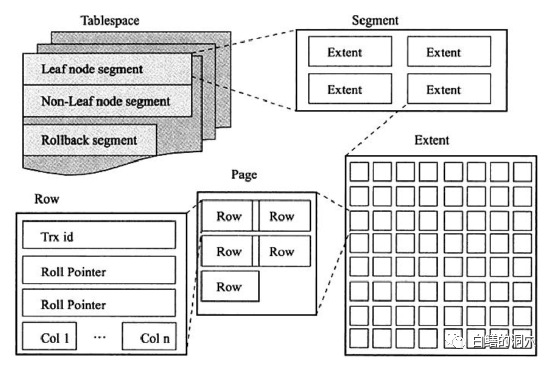
上面是MySQL innodb存儲引擎的一個邏輯示意圖,這是一種典型的BTREE結構存儲引擎。BTREE結構的存儲引擎也不是完全相同的。主要的區別是leaf node segment是否和數據存儲在一個段里。達夢明顯是分開的。實際上BTREE結構的存儲結構,所有的數據存儲都是按照主鍵的順序存儲的。
表空間是一個邏輯結構,可以被認為是innodb的頂層邏輯結構,所有的數據都必須屬于某個表空間。默認的innodb引擎有一個ibdata1表空間,默認的數據都存儲在這個表空格鍵中。如果設置了innodb_file_per_table參數,每張表都會創建獨立的文件。不過只有表的數據、索引等會存儲在每張表自己的文件中,UNDO數據、事務控制信息、INSERT BUFFER等仍然會存儲在系統共享的表空間中。在Innodb存儲引擎中,一張表會分為兩個段,其中一個段是葉節點段,存儲實際的數據,另外一個段是索引段,存儲索引的指針信息。而表中DML的UNDO信息會存儲在rollback segment中。
上面這張innodb的邏輯結構圖畫的十分清晰,所有的表的行數據是存儲在extent中的,而每個extent是多個連續的PAGE組成的,每個PAGE中存儲了行數據。實際上這個leaf node segment和Oracle的TABLE SEGMENT是十分類似的,所不同的是多了一個Index segments。相當于在創建表的時候同時又默認創建了一個主鍵索引。Mysql在窗這個主鍵索引的時候,會區分不同的情況。如果要創建的表上沒有設置主鍵索引,那么會選擇表上的一個非空唯一性索引作為主鍵索引,如果不存在這樣的索引,那么Mysql會使用一個六字節的唯一性自增值窗一個主鍵索引。
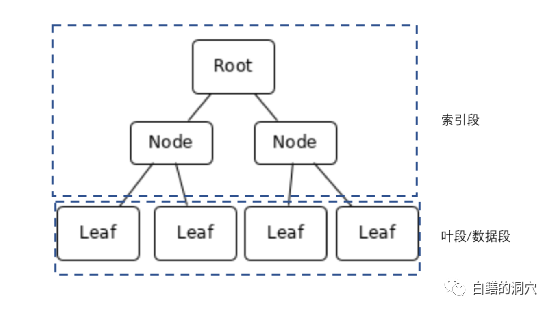
Mysql innodb等采用B樹存儲結構的存儲引擎一般采用上圖的模式,當數據被插入表的時候,會根據主鍵索引或者簇索引的指示插入到某個位置,而不會像Oracle那樣,通過segment的free space bitmap尋找空閑位置插入。
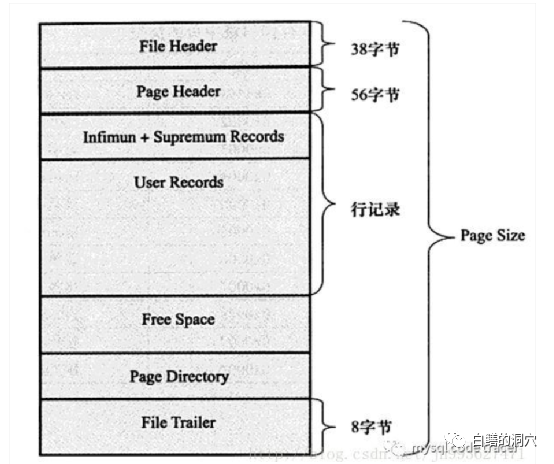
Innodb的PAGE結構與HEAP結構的類似,不過在空閑空間管理上是完全不同的。前面是FILE HEADER/PAGE HEADER,中間是數據記錄,數據記錄也是從低地址往高地址寫,和Oracle相反。這是因為BTREE存儲結構不需要和slotted page一樣,在塊里放一個指示器,其行指示器的功能被BTREE替代了。
Innodb的這種存儲結構,并不存在一個十分友好的類似Oracle的記錄物理地址的ROWID這樣的結構。所以要想定位某條數據記錄,需要使用主鍵或者簇主鍵的方式來實現。主鍵可以定義某條記錄的唯一性地址,因此Mysql的某張表上的其他索引(secondary index)的索引中存儲的鍵值不像Oracle那樣存儲ROWID就可以了,而是存儲的是主鍵中這一行的地址指針。基于一個secondary index的查詢首先找出某些行的主鍵,然后再去掃描一次主鍵索引,才能找到相關行的地址,再找到這條記錄。比起有rowid的Oracle數據庫,這里多了一次主鍵索引的掃描。
可能有些朋友會覺得,是不是heap結構一定優于BTREE結構呢?其實還是回到今天的標題,沒有完美的存儲引擎。針對不同的應用場景,heap和BTREE各有優勢。BTREE結構寫入數據時按主鍵排序的,而且并發寫入時數據并不是按照插入順序寫入數據塊,如果主鍵存在一定的無序性,那么并發寫入的數據可以被打散到多個塊中,從而緩解熱塊沖突的壓力。而二級索引的結構雖然對讀取數據的操作有影響,對于存在多條索引的數據寫入,數據修改,是有優勢的。因為只要主鍵的鍵值不變,行數據的變化,行在數據塊中存儲的變化,不需要變更第二索引。
因此我們可以十分明確的肯定,不同的存儲結構都各有利弊,并不能很直接的說哪種更好。不過在開發高并發,大數據量的系統的時候,了解存儲引擎的一些特點,可以有效的避免一些問題。比如在Mysql、達夢等數據庫中建表,盡可能定義一個顯式的主鍵,從而避免系統自動添加主鍵。另外如果某張表的熱塊沖突特別嚴重的時候,主鍵可以考慮選擇隨機性的數據,而不是單邊增長的數據,就可以有效的進行數據打散,從而降低熱塊沖突的可能性。