深度好文! 圖解Kafka Producer 內存池架構設計
在閱讀本文之前, 希望你可以思考一下下面幾個問題, 帶著問題去閱讀文章會獲得更好的效果。
- 發送消息的時候, 當Broker掛掉了,消息體還能寫入到消息緩存中嗎?
- 當消息還存儲在緩存中的時候, 假如Producer客戶端掛掉了,消息是不是就丟失了?
- 當最新的ProducerBatch還有空余的內存,但是接下來的一條消息很大,不足以加上上一個Batch中,會怎么辦呢?
- 那么創建ProducerBatch的時候,應該分配多少的內存呢?
什么是消息累加器RecordAccumulator
kafka為了提高Producer客戶端的發送吞吐量和提高性能,選擇了將消息暫時緩存起來,等到滿足一定的條件, 再進行批量發送, 這樣可以減少網絡請求,提高吞吐量。
而緩存這個消息的就是RecordAccumulator類.
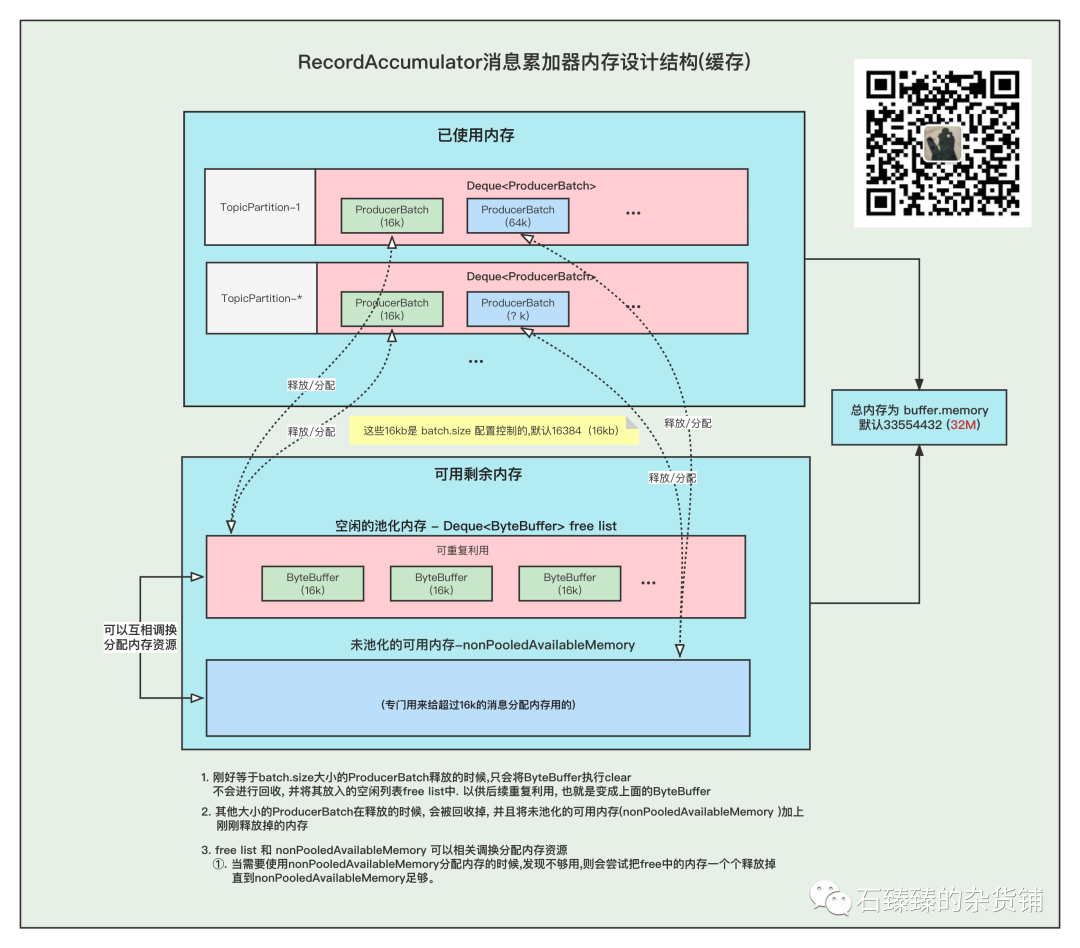
上圖就是整個消息存放的緩存模型,我們接下來一個個來講解。
消息緩存模型
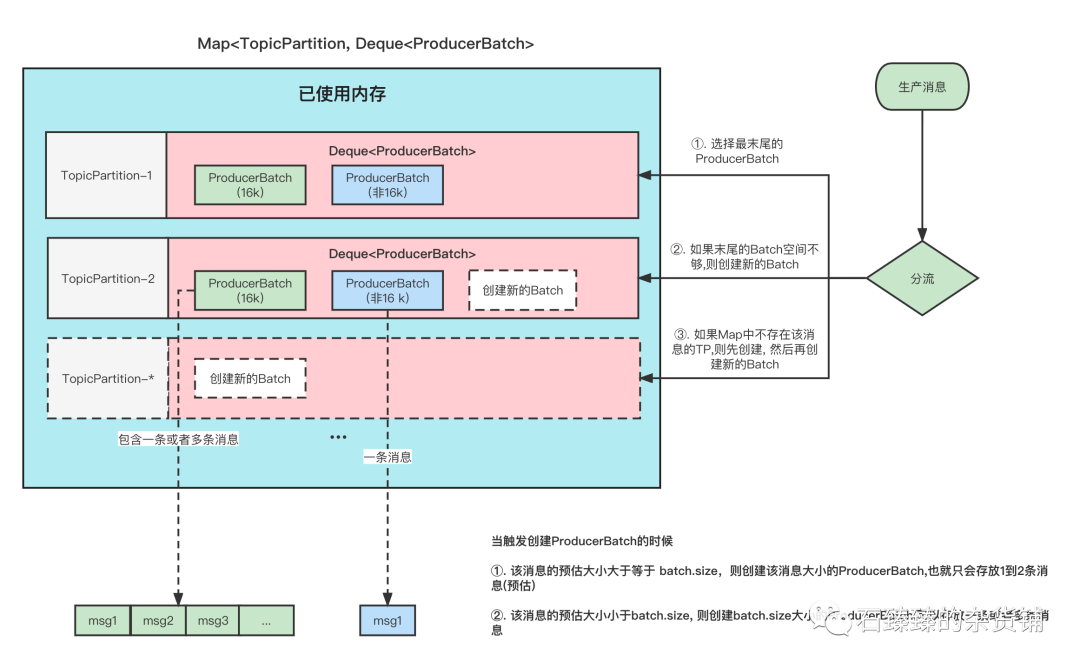
上圖表示的就是 消息緩存的模型, 生產的消息就是暫時存放在這個里面。
- 每條消息,我們按照TopicPartition維度,把他們放在不同的Deque<ProducerBatch> 隊列里面。TopicPartition相同,會在相同Deque<ProducerBatch> 的里面。
- ProducerBatch : 表示同一個批次的消息, 消息真正發送到Broker端的時候都是按照批次來發送的, 這個批次可能包含一條或者多條消息。
- 如果沒有找到消息對應的ProducerBatch隊列, 則創建一個隊列。
- 找到ProducerBatch隊列隊尾的Batch,發現Batch還可以塞下這條消息,則將消息直接塞到這個Batch中
- 找到ProducerBatch隊列隊尾的Batch,發現Batch中剩余內存,不夠塞下這條消息,則會創建新的Batch
- 當消息發送成功之后, Batch會被釋放掉。
ProducerBatch的內存大小
那么創建ProducerBatch的時候,應該分配多少的內存呢?
先說結論: 當消息預估內存大于batch.size的時候,則按照消息預估內存創建, 否則按照batch.size的大小創建(默認16k).
我們來看一段代碼,這段代碼就是在創建ProducerBatch的時候預估內存的大小
RecordAccumulator#append
/**
* 公眾號: 石臻臻的雜貨鋪
* 微信:szzdzhp001
**/
// 找到 batch.size 和 這條消息在batch中的總內存大小的 最大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 申請內存
buffer = free.allocate(size, maxTimeToBlock);
- 假設當前生產了一條消息為M, 剛好消息M找不到可以存放消息的ProducerBatch(不存在或者滿了),那么這個時候就需要創建一個新的ProducerBatch了
- 預估消息的大小 跟batch.size 默認大小16384(16kb). 對比,取最大值用于申請的內存大小的值。
那么, 這個消息的預估是如何預估的?純粹的是消息體的大小嗎?
DefaultRecordBatch#estimateBatchSizeUpperBound
預估需要的Batch大小,是一個預估值,因為沒有考慮壓縮算法從額外開銷
/**
* 使用給定的鍵和值獲取只有一條記錄的批次大小的上限。
* 這只是一個估計,因為它沒有考慮使用的壓縮算法的額外開銷。
**/
static int estimateBatchSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) {
return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers);
}
- 預估這個消息M的大小 + 一個RECORD_BATCH_OVERHEAD的大小
- RECORD_BATCH_OVERHEAD是一個Batch里面的一些基本元信息,總共占用了 61B
- 消息M的大小也并不是單單的只有消息體的大小,總大小=(key,value,headers)的大小+MAX_RECORD_OVERHEAD
- MAX_RECORD_OVERHEAD :一條消息頭最大占用空間, 最大值為21B
也就是說創建一個ProducerBatch,最少就要83B .
比如我發送一條消息 " 1 " , 預估得到的大小是 86B, 跟batch.size(默認16384) 相比取最大值。那么申請內存的時候取最大值 16384 。
關于Batch的結構和消息的結構,我們回頭單獨用一篇文章來講解。
內存分配
我們都知道RecordAccumulator里面的緩存大小是一開始定義好的, 由buffer.memory控制, 默認33554432 (32M)
當生產的速度大于發送速度的時候,就可能出現Producer寫入阻塞。
而且頻繁的創建和釋放ProducerBatch,會導致頻繁GC, 所有kafka中有個緩存池的概念,這個緩存池會被重復使用,但是只有固定( batch.size)的大小才能夠使用緩存池。
PS:以下16k指得是 batch.size的默認值.
Batch的創建和釋放
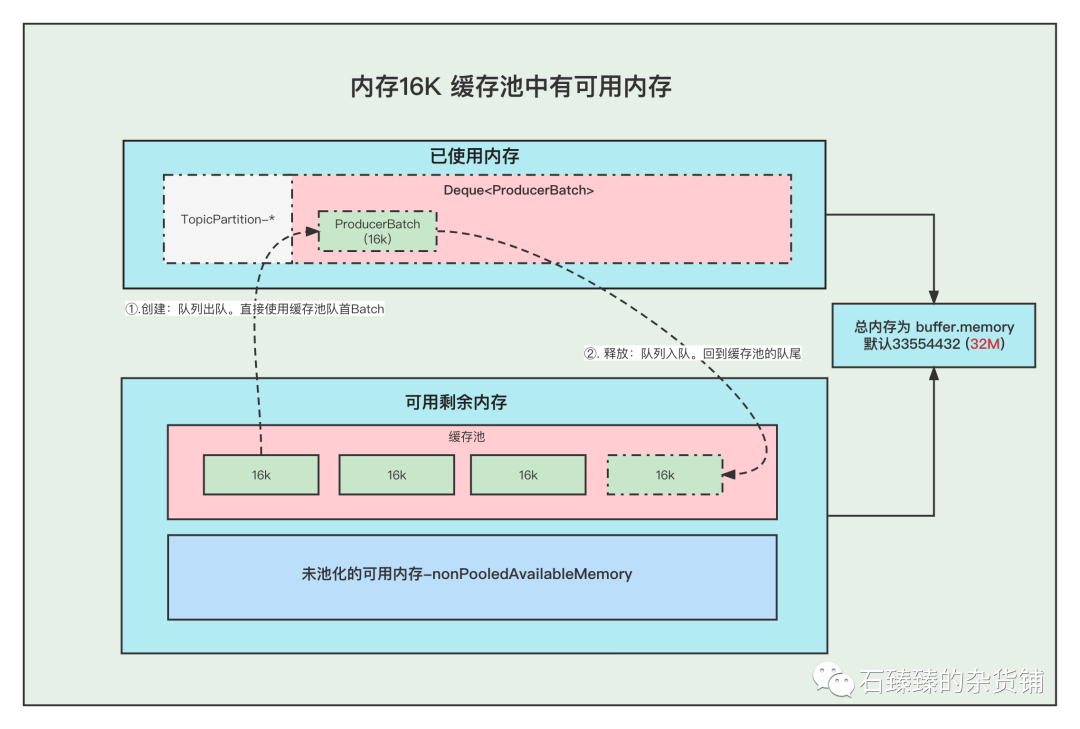
1. 內存16K 緩存池中有可用內存
①. 創建Batch的時候, 會去緩存池中,獲取隊首的一塊內存ByteBuffer 使用。
②. 消息發送完成,釋放Batch, 則會把這個ByteBuffer,放到緩存池的隊尾中,并且調用ByteBuffer.clear 清空數據。以便下次重復使用
2. 內存16K 緩存池中無可用內存
①. 創建Batch的時候, 去非緩存池中的內存獲取一部分內存用于創建Batch. 注意:這里說的獲取內存給Batch, 其實就是讓 非緩存池nonPooledAvailableMemory 減少 16K 的內存, 然后Batch正常創建就行了, 不要誤以為好像真的發生了內存的轉移。
②. 消息發送完成,釋放Batch, 則會把這個ByteBuffer,放到緩存池的隊尾中,并且調用ByteBuffer.clear 清空數據, 以便下次重復使用
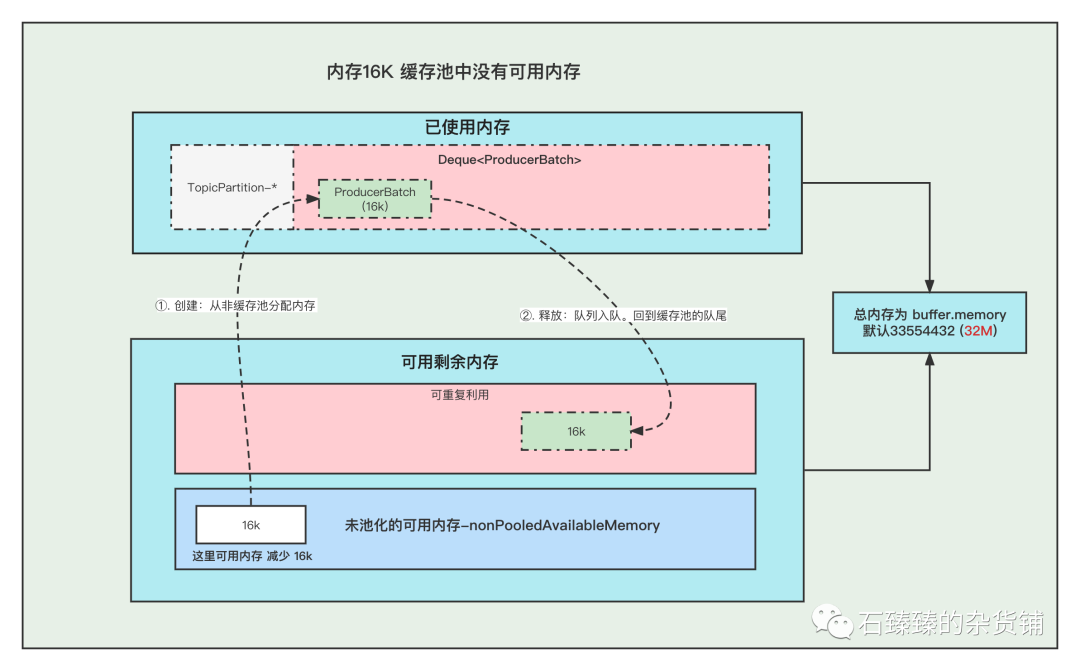
3. 內存非16K 非緩存池中內存夠用
①. 創建Batch的時候, 去非緩存池(nonPooledAvailableMemory)內存獲取一部分內存用于創建Batch. 注意:這里說的獲取內存給Batch, 其實就是讓 非緩存池(nonPooledAvailableMemory) 減少對應的內存, 然后Batch正常創建就行了, 不要誤以為好像真的發生了內存的轉移。
②. 消息發送完成,釋放Batch, 純粹的是在非緩存池(nonPooledAvailableMemory)中加上剛剛釋放的Batch內存大小。當然這個Batch會被GC掉
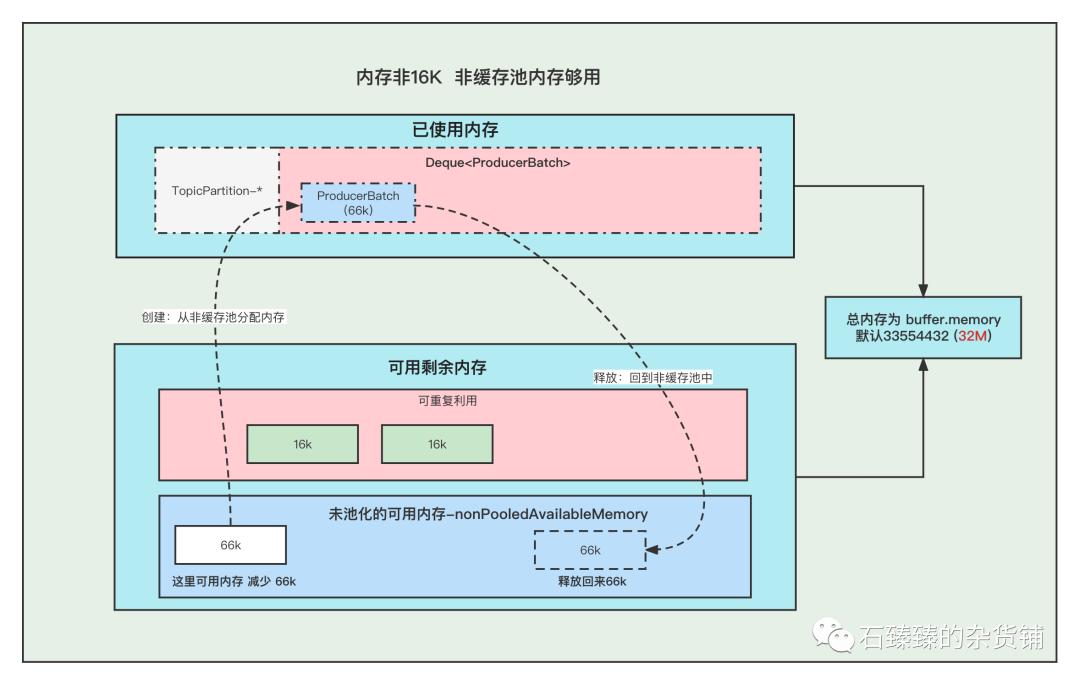
4. 內存非16K 非緩存池內存不夠用
①. 先嘗試將 緩存池中的內存一個一個釋放到 非緩存池中, 直到非緩存池中的內存夠用與創建Batch了
②. 創建Batch的時候, 去非緩存池(nonPooledAvailableMemory)內存獲取一部分內存用于創建Batch. 注意:這里說的獲取內存給Batch, 其實就是讓 非緩存池(nonPooledAvailableMemory) 減少對應的內存, 然后Batch正常創建就行了, 不要誤以為好像真的發生了內存的轉移。
③. 消息發送完成,釋放Batch, 純粹的是在非緩存池(nonPooledAvailableMemory)中加上剛剛釋放的Batch內存大小。當然這個Batch會被GC掉
例如: 下面我們需要創建 48k的batch, 因為超過了16k,所以需要在非緩存池中分配內存, 但是非緩存池中當前可用內存為0 , 分配不了, 這個時候就會嘗試去 緩存池里面釋放一部分內存到 非緩存池。
釋放第一個ByteBuffer(16k) 不夠,則繼續釋放第二個,直到釋放了3個之后總共48k,發現內存這時候夠了, 再去創建Batch。
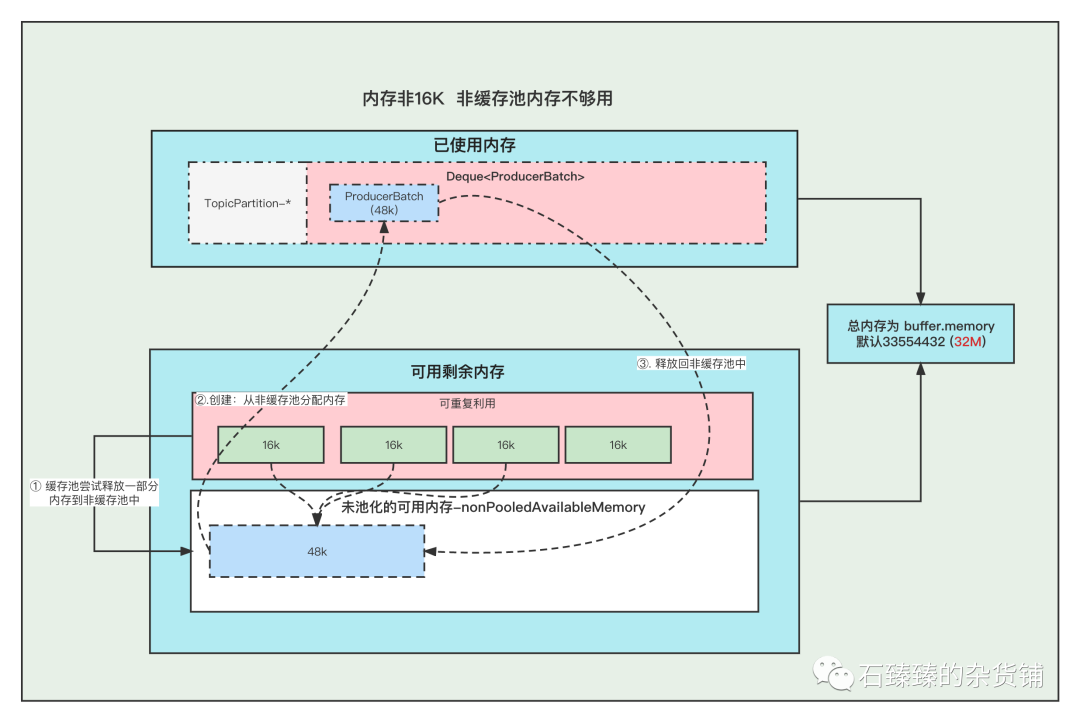
注意:這里我們涉及到的 非緩存池中的內存分配, 僅僅指的的內存數字的增加和減少。
問題和答案
- 發送消息的時候, 當Broker掛掉了,消息體還能寫入到消息緩存中嗎?
當Broker掛掉了,Producer會提示下面的警告??, 但是發送消息過程中
這個消息體還是可以寫入到 消息緩存中的,也僅僅是寫到到緩存中而已。
WARN [Producer clientId=console-producer] Connection to node 0 (/172.23.164.192:9090) could not be established. Broker may not be available

- 當最新的ProducerBatch還有空余的內存,但是接下來的一條消息很大,不足以加上上一個Batch中,會怎么辦呢?
那么會創建新的ProducerBatch。
- 那么創建ProducerBatch的時候,應該分配多少的內存呢?
觸發創建ProducerBatch的那條消息預估大小大于batch.size ,則以預估內存創建。否則,以batch.size創建。
還有一個問題供大家思考:
當消息還存儲在緩存中的時候, 假如Producer客戶端掛掉了,消息是不是就丟失了?