為什么要合并HTTP請求?

思考路徑:
為什么要實現batch call? -> 減少網絡中的傳輸損耗 -> 如何減少的? -> 通過合并HTTP請求 -> 合并HTTP請求是如何減少網絡損耗的?
本文將解決這個問題。一起看看單個請求攜載大量信息和多個請求攜載小量信息對于整個時間的影響。
Client發出請求
1 HTTP 1.1
可以保持長連接,但是每個不同的請求之間,client要向server發一個請求頭
請求無法并行執行的,在一個連接里面
假設如果不合并的話需要建立N個連接,那么合并就可以省去(N-1)*RTT的時間,RTT指網絡延遲(在傳輸介質中傳輸所用的時間,即從報文開始進入網絡到它開始離開網絡之間的時間)。
2 TCP丟包問題
慢啟動,擁塞控制窗口
TCP報文亂序到達,合并后的文件可以允許隊首丟包以后在隊中補上來,但是分開資源的時候,前一個資源未加載完成后面的資源是不能加載的,會有更嚴重的隊首阻塞問題,丟包率會嚴重影響Keep alive情況下多個文件的傳輸速率。
3 瀏覽器線程數限制
多為2-6個線程,會在每個連接上串行發送若干個請求。TCP連接太多,會給服務器造成很大的壓力的。
4 DNS緩存問題
每次請求都需要找DNS緩存,多個請求就需要查找多次,而且緩存有可能被無故清空
服務器處理請求
每個請求需要使用一個連接,建立一個線程,分配一部分CPU, 對于CPU而言,是種負擔,尤其是一般來說建立了連接以后,哪怕發回了請求,這個連接還會保持一段時間才會timeout。這種時候,維持連接是對服務器資源的一種巨大的浪費。
HTTP 2.0
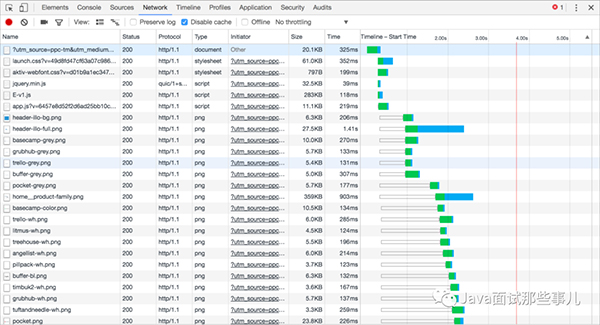
上面描述的所有都是基于HTTP/1.1的一些特性,或者說弊端,有長連接但是無法并行處理請求,TCP的慢啟動和擁塞控制,隊首阻塞問題都給整個性能帶來很多弊端,因此我們有了HTTP2.0來做針對性的改進。很有意思的東西,直接看圖:
HTTP/1.1 network的請求圖
HTTP/2 network的請求圖
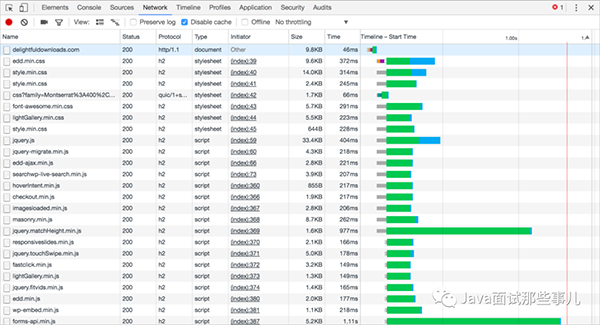
就是這么酷炫,HTTP/2多了很多特性來解決HTTP/1.1的很多問題
1 Fully multiplexed
解決了隊首阻塞的問題。對于同一個TCP連接,現在可以發送多個請求,接收多個回應了!在HTTP/1.1里面,如果在一個連接里上一個請求發生了丟包,那么后面的所有請求都必須等第一個請求補上包,收到回應以后才能繼續執行。而在HTTP/2里面,可以直接并行處理。
2 Header Compression
所有的HTTP request和response都有header,但是header里很可能包含緩存信息,導致他的大小會迅速增大的。但是在一個連接里大部分請求的請求頭其實攜帶的信息都很類似,所以HTTP/2使用了索引表,存儲了第一次出現的請求的請求頭,然后后面的類似的請求只需要攜帶這個索引的數字就好了。頭部壓縮平均減少了30%的頭部大小,加快了整體的網絡中傳輸的速度。
這兩點是和本文關系最大的,有了這兩點,實質上合并HTTP請求的好處在HTTP/2的協議下,已經基本上消失了。合并不合并請求,更多的是看業務上的需求,后端的一些配置。
總結
It's a trade-off. 其實最重要的是看你傳輸什么東西,因為合并HTTP請求實質上是減少了網絡延時,但是如果你在服務器上處理的時間遠遠大于網絡延時的時間的時候,那么合并HTTP請求并不會給你帶來很多性能上的提升。而且大數據量的傳輸一定會降低瀏覽器的cache hit rate,對于緩存的利用率會降低很多。但是對于HTTP請求攜帶的數據量比較少的情況,合并請求帶來的性能提升會是顯而易見的。