一文梳理推薦系統中的特征交互排序模型
引言
工業推薦系統一般包含兩個部分:召回和排序。召回階段根據用戶的興趣和歷史行為,從海量的物品庫里,快速找回小部分用戶潛在感興趣的物品。排序模型需要融入各種特征(例如用戶端的特征、物品端的特征等),使用較為復雜的模型,對召回階段輸出的物品集合進行排序,為用戶做精準的個性化推薦。排序模型融入特征不僅需要考慮單獨每一個特征,更需要考慮特征之間的交互。特征交互也叫特征組合,通過將兩個或多個特征組合起來,進行一系列操作,來實現對樣本空間的非線性變換,增加模型的非線性能力,以達到對于不同的特征組合都能進行有效預測的目標。
那么如何建模特征交互?最容易想到的方法是對所有特征的組合都枚舉一遍。但是,這種顯式地特征交互有一定的局限性:(1)非線性建模能力有限(2)更高階的特征交互計算量大,難以實現(3)數據稀疏性大時,出現次數少的特征難以訓練(4)不能自動化實現特征交互,人工代價大。隨著深度學習時代的到來,特征交叉方案變得更加豐富,很多工作利用深度神經網絡(DNN)來隱式地建模特征交互的高階關系,來解決顯式特征交互帶來的問題。一些典型的工作例如PNN,Wide&Deep,NFM,DeepFM,xDeepFM,DIN等。
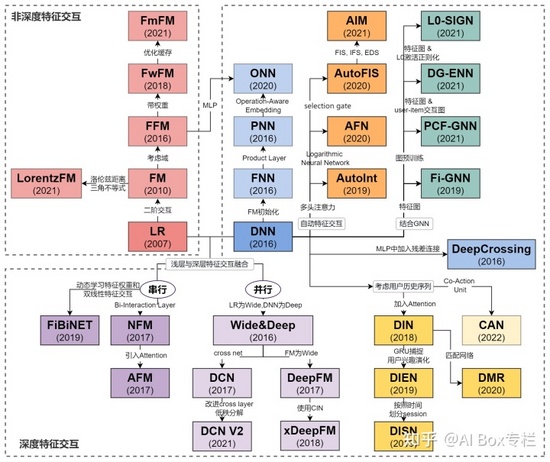
本文梳理了從LR到CAN,推薦系統發展過程中比較知名的32個特征交互排序模型。文章一共包含5個部分:
- 非深度特征交互 :LR, FM, FFM, FwFM, LorentzFM, FM^2
- 深度特征交互 : DNN(FNN), DeepCrossing, Wide&Deep, PNN, NFM, AFM, DeepFM, DCN, xDeepFM, FiBiNET, ONN. DCN V2
- 自動特征交互 : AutoInt, AFN, AutoFIS, AIM
- 基于圖的特征交互 : Fi-GNN, L0-SIGN, PCF-GNN, DG-ENN
- 基于序列的特征交互 : DIN, DIEN, DSIN, DMR, CAN
其中,嚴格來說3、4、5三個部分也屬于深度特征交互這一類,但因為其各自有明顯的特點,因此將它們單獨歸類。讀者可以選擇自己不熟悉的方向進行閱讀。
下圖是本文涉及到的排序模型的發展歷程,讓脈絡更加清晰。
特征交互排序模型發展歷程
1 非深度特征交互
LR
Predicting Clicks Estimating the Click-Through Rate for New Ads, WWW 2007
LR模型沒有使用特征交互的線性函數,對于每一個特征使用一個參數w作為權重。它可以處理大規模的離散化特征,并且易于并行化、可解釋性強。同時LR有很多變種,例如支持在線實時模型訓練(FTRL)。
FM
Factorization Machines, ICDM 2010
LR模型假設特征之間是相互獨立的,忽略了特征之間的交互,而FM則是針對這一點進行改進。FM模型融入了二階特征交互,對于每兩個特征x_i和x_j的交互組合,用一個參數w_ij來作為權重。

為了解決了特征交互稀疏的問題,作者對參數w_ij進行了分解,分解為了兩個向量的點積:


FFM
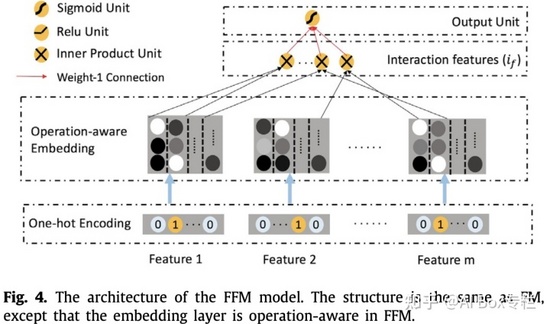
Field-aware Factorization Machines for CTR Prediction, RecSys 2016
在FM中,每一個特征只學習一個隱向量,這篇文章的作者一些特征應當屬于不同的特征域,因此應該分別建模。具體來講,FFM針對每個特征都會學習f個隱向量,f表示field的數量。假設樣本的 n 個特征屬于 f 個field,那么FFM的二次項有 nf個隱向量,而在FM模型只有有n個隱向量。
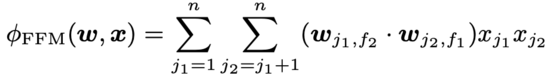
FwFM
Field-weighted Factorization Machines for Click-Through Rate Prediction in Display Advertising, WWW 2018
FFM對不同的交互方式可以精確的建模,取得很好的效果。但是,FFM中的參數個數跟特征數和域數的乘積同階,在實際應用中開銷較大。FwFM提出帶權重的FFM,對不同域中不同的特征交互建模時更加高效。
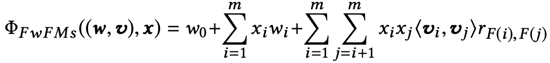
LorentzFM
Learning Feature Interactions with Lorentzian Factorization Machine, AAAI 2020
洛倫茲因子分解機模型沒有使用深度模型的結構,但可以達到深度模型的準確率,而且降低了深度模型的參數量和訓練時間。具體來講,LorentzFM建模特征交互時,利用了雙曲空間中兩個特征之間距離是否違背三角不等式來構造特征交互,同時雙曲三角形特殊的幾何特性可以替換掉現在普遍使用的MLP層,達到了減少參數量的目標。
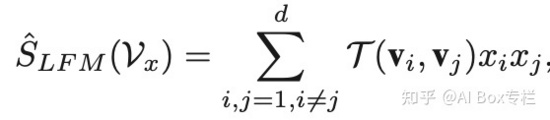


FM^2
FM^2: Field-matrixed Factorization Machines for CTR Prediction, WWW 2021
FmFM(FM^2)可以看做FwFM的升級版,并且FM、FwFM等模型都可以統一到FmFM框架下,并通過embedding向量維度和中間向量緩存優化,在模型效果持平的前提下,提升計算效率。具體來講,特征 F(i) 與特征 F(j) 交叉時,引入矩陣M,特征 F(i) 對應向量先與矩陣相乘得到中間向量,再與特征 F(j) 對應向量點積。FM和FwFM可以統一到該框架下。FM在進行二階特征交互時,特征對應向量直接進行點積,等價于把FmFM中的M矩陣設置為單元矩陣(對角線全為1)。FwFM進行特征交互時,每對特征引入權重 ,等價于把FmFM中的轉化矩陣設置對角線全為 r 的矩陣(非對角線為0),矩陣參數可學習,對角線元素相同。
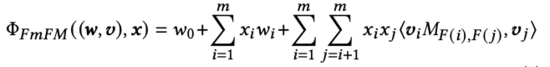
2 深度特征交互
DNN(FNN)
Deep Learning over Multi-field Categorical Data, ECIR 2016
DNN模型通常由Embedding層+MLP層組成。通過Embedding層,將高維離散特征轉換為固定長度的連續特征,然后通過多個全連接層,最后通過一個激活函數得到點擊的概率。這種方法的優點在于通過神經網絡擬合高階特征交互的非線性關系,同時減少了人工特征的工作量。這篇論文中提到的FNN則是用訓練好的FM作為初始化參數,再接DNN。

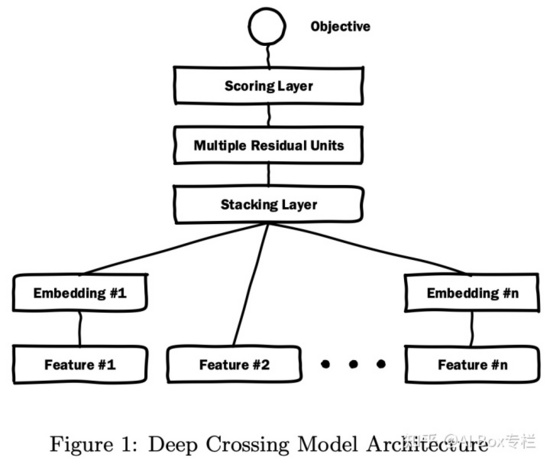
DeepCrossing
Deep Crossing: Web-Scale Modeling without Manually Crafted Combinatorial Features , SIGKDD 2016
微軟于2016年提出的Deep Crossing可以說是深度學習CTR模型的基礎性模型,旨在解決特征工程中特征組合的難題,降低人工特征組合的工作量。它的整體結構與DNN類似,不同的地方在于Deep Crossing采用的MLP是由殘差網絡組成的(文中提到這是第一次殘差單元被用于圖像識別之外)。通過多個殘差單元,對特征向量各個維度進行交叉組合,使模型獲得了更多的非線性特征和組合特征信息,從而提高了模型的表達能力。
Wide&Deep
Wide & Deep Learning for Recommender Systems, RecSys 2016
Wide&Deep 是由Google于2016年提出的,是推薦領域取得較大成功的最早深度模型。模型包括Wide和Deep兩個部分,Wide 部分為 LR,這部分對樣本中的特征與目標有較為明顯的關聯進行記憶性學習,即對于樣本中出現過的高頻低階特征能夠用少量參數學習,缺點是泛化能力差;Deep部分為DNN,旨在學習到樣本中多個特征與目標之間的隱式關聯,對于少量出現過的樣本甚至沒有出現過的樣本能做出預測。在Wide&Deep的框架下,一個優勢是Wide部分可以沿用之前非深度特征交互的成果,尤其是特征工程部分。這一點也促進了之后DeepFM等工作的誕生。

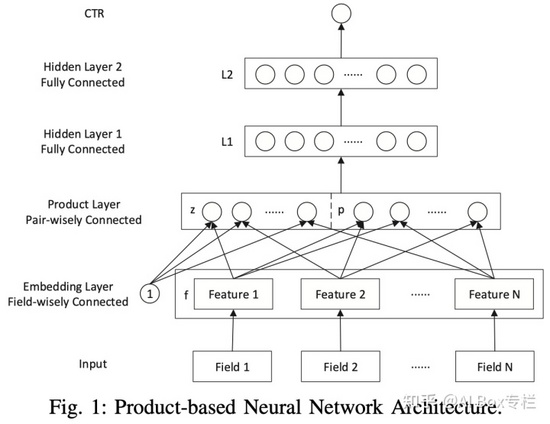
PNN
Product-based Neural Networks for User Response Prediction, ICDM 2016
傳統Embedding+MLP的方式并不能很好對高階交叉特征進行獲取,同時FNN用FM初始化參數接DNN的方式也并不完美,針對這些缺點PNN進行了改進,通過引入特征交互層 Product Layer,顯式的對特征進行交互,以提升模型的表達能力。Product層利用內積(Inner PNN)和外積(Outer PNN)兩種方式實現對特征的交叉組合。其中,IPNN本質上利用共享參數來減少參數量,采用一階矩陣分解來近似矩陣結果。OPNN的時空復雜度比IPNN更高,作者使用了Sum Pooling的方式來降低復雜度,但也造成了精度的損失。 實際使用更多的是IPNN。
NFM
Neural Factorization Machines for Sparse Predictive Analytics, SIGIR 2017
NFM將FM得到的交互特征用于DNN層的輸入,并使用Bi-interaction Pooling操作對二階交叉特征進行處理,解決傳統FM作為線性模型表達有限的問題和對高階交叉特征學習不充分的問題,公式如下:

Bi-interaction Pooling與FM相比,沒有引入額外的參數,且具有線性復雜度。

AFM
Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks, IJCAI 2017
與NFM類似,AFM首先利用FM解決稀疏特征問題及淺層交互特征,同時利用深度注意力網絡獲取深層交互特征。模型的核心是注意力層(Attention-based Pooling Layer)通過關注不同的交叉特征和目標之間的關系,得到不同程度的貢獻分數,然后加權求和。同時利用MLP進一步處理訓練數據中未出現樣本的的評估問題,從而達到泛化模型的目的。

DeepFM
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction, IJCAI 2017
將Wide&Deep模型的LR替換為FM。解決FM只能獲取二階特征,無法獲取高階特征的問題;解決傳統DNN的隱式交叉方式在高稀疏特征無法很好獲取表征的問題。DeepFM是一個端到端的深度學習模型,模型FM和DNN部分共享Embedding層。

DCN
Deep & Cross Network for Ad Click Predictions, ADKDD 2017
DCN對Wide&Deep中的Wide部分進行了替換,提出CrossNetwork用于特征交叉。它的設計理念是通過參數共享的方式減少向量壓縮變換時產生參數量過多的情況,從而減少模型的過擬合,增強模型的泛化能力。同時Cross Network的方式會將模型復雜度降為層級線性增長。

xDeepFM
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems, SIGKDD 2018
使用CIN交叉網絡和DNN的雙路結構,同時以顯式和隱式的方式學習高階特征。其中模型的核心部分是交叉網絡CIN部分,由交互和壓縮兩步,通過vector-wise角度學習高階交叉特征,CIN與DNN兩個部分同時共享Embedding層。
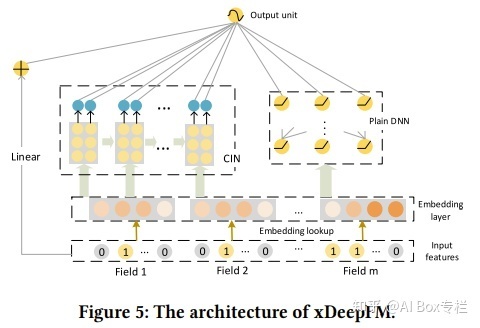
FiBiNET
FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction, RecSys 2019
結合特征重要性和雙線性特征交互進行CTR預估。主要通過動態學習不同特征的特征重要性權重,解決CTR預估中對不同場景下不同特征的權重reweight的問題;雙線性的使用解決稀疏數據在特征交叉建模時的有效性問題。核心結構包括SENET Layer和Bilinear-Interaction Layer。其中 SENET Layer會對每個field用pooling操作和FC層計算特征重要性權重的Excitation;對原始每個field利用Excitation得到的特征重要性權重重新賦權。而 Bilinear-Interaction Layer 提出一種結合Inner Product和Hadamard Product方式,學習交互特征。
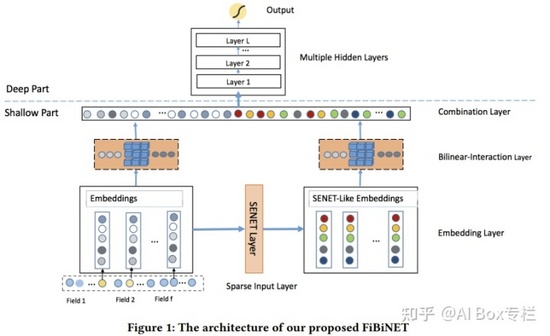
ONN
Operation-aware Neural Networks for user response prediction , NN 2020
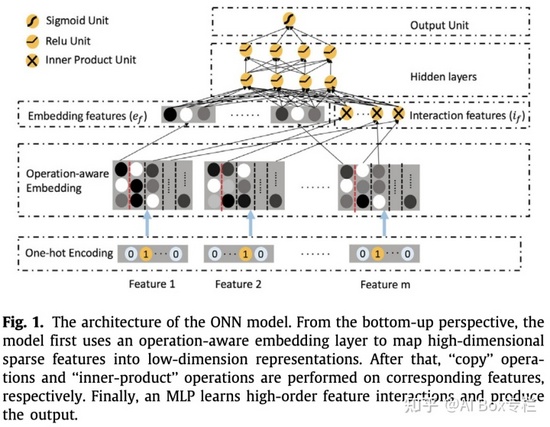
目前大多數模型對于一個特征在進行不同的操作時都使用相同的表示。但對于不同的操作,一個特征的最好的表示不總是相同的。ONN解決該問題的一個思路是在基本的通用的Embedding+MLP結構下,將PNN與FFM結合起來,實現了在embedding層的每一個特征對于不同操作(內積或者外積)有不同的表示,這對于之后進入MLP學習高階特征交互時有更好的幫助。與PNN相比,ONN實現了operation-aware的embedding layer,即一個特征有多種embedding,對于不同操作可以選擇不同的特征表示。和FFM模型最大的區別在于ONN加入了MLP,深度神經網絡能夠更好的挖掘特征深層次的依賴,學習到復雜的特征交互關系。
DCN V2
DCN V2: Improved Deep & Cross Network and Practical Lessons for Web-scale Learning to Rank Systems, WWW 2021
DCN V2是DCN的作者提出的一個改進版本。核心的改進在于cross network。
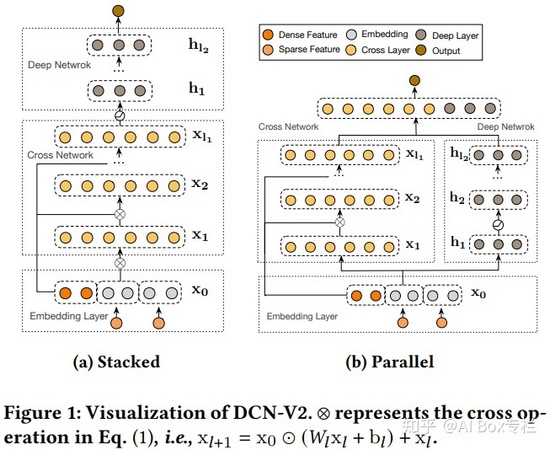
這是DCN的cross layer

這是DCN V2的cross layer
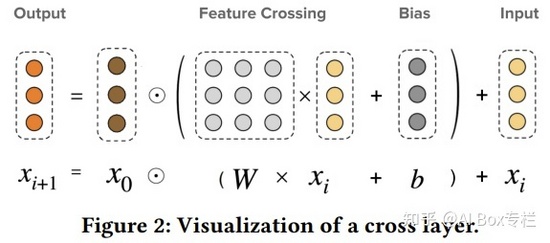
從兩幅圖的公式可以對比看出,模型最大的變化是將原來的向量w變成了矩陣W。矩陣相比向量來說,擁有更多的參數來保留高階交叉信息,提高模型的表達能力。但是引入矩陣會增加計算量,為了減少開銷,作者提出了對W矩陣進行低秩分解,即用兩個低秩子矩陣代替原來的矩陣,實驗證明這種方式精度損失很低。另外,文章對deep層和cross層還嘗試了stacked(串行,cross層的輸出作為deep層的輸入)和 parallel(并行,cross層和deep層同時進行,最后將兩部分的輸出拼接)兩種不同的組合方式,實驗表明兩種組合方式在不同的數據集上的表現效果不同,沒有優劣之分。
3 自動特征交互
現有的特征交互的工作通常分為二階交互和高階交互,而且需要指定一個交互階數,迭代出所有的交互特征。這樣做一方面計算量容易變得很大,不利于實際應用;另一方面可能會潛在引入噪聲,即不重要的特征交互組合。自動特征交互這一類工作的目標是希望模型可以自動學出應該保留哪些交互的特征以及應該進行幾階交互。
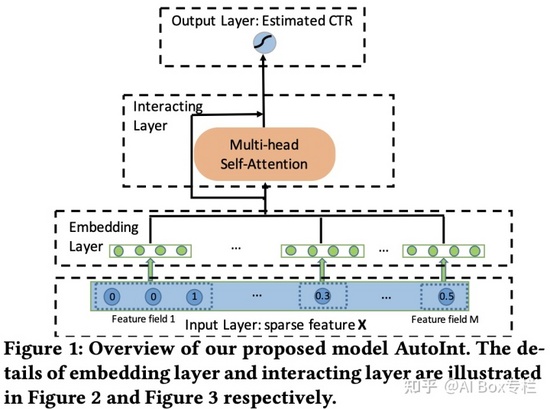
AutoInt
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks, CIKM 2019
受Transformer的啟發,模型利用帶殘差連接的多頭自注意力機制顯式的進行交互特征的獲取,能夠自動學習高階特征交叉。核心部分是Interacting Layer,將輸入的embedding轉換為Query、Key、Value,通過自注意力的方式計算每個特征與其他特征的相似度,加權求和得到新特征。模型也包含多個注意力層以構造更高階的組合特征。
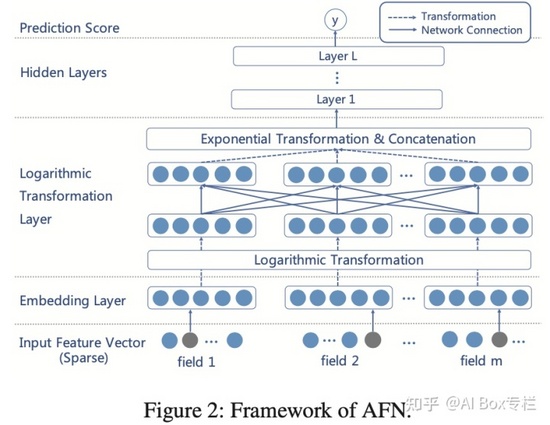
AFN
Adaptive Factorization Network: Learning Adaptive-Order Feature Interactions, AAAI 2020
現有的特征交互的工作通常指定一個交互階數,迭代出所有的交互特征,這樣做一方面計算量很大,另一方面會引入噪聲的特征組合。AFN本文借鑒了Logarithmic Neural Network (LNN)的思想,模型中的Logarithmic Transformation Layer可以自動學習保留出應該交互的特征以及應該進行幾階交互。其核心思想是引入對數mic變換,將特征對數化,再去做交叉運算。這樣能將特征交互中每個特征的冪轉換為帶系數的乘法。
AutoFIS
AutoFIS: Automatic Feature Interaction Selection in Factorization Models for Click-Through Rate Prediction, SIGKDD 2020
AutoFIS的目標是自動識別出有效的特征交互組合,避免引入噪聲特征交互。模型整體分為兩個階段: 搜索階段(檢測有效特征交互)和重訓練階段(去除冗余的特征交互,并重新訓練模型)。模型會為每個特征交互引入門控單元來控制是否選擇它。搜索階段門控打開,正常學習每個特征交互的權重;重訓練階段,關閉不重要特征交互的門控,即在訓練時丟掉這個特征交互。
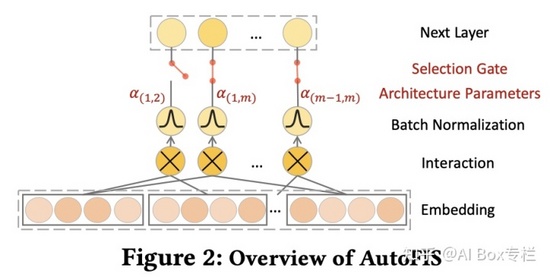
AIM
AIM: Automatic Interaction Machine for Click-Through Rate Prediction, TKDE 2021
AIM是AutoFIS的擴展版,包含三個核心組件:特征交互搜索(FIS)、交互函數搜索(IFS)和嵌入維數搜索(EDS)。其中IFS以及FIS負責特征交互搜索,EDS負責特征表示搜索。FIS負責搜索特征交互的組合,可以看到FIS的結構與AutoFIS一致,但基本的FIS結構只能探索特征間的二階交互,這里作者設計了 P 階特征交互的搜索算法。IFS為每個特征交互組合設計了不同的運算選擇,具體而言,本文設計了inner,outer與kernel product三種運算。在搜索階段,IFS與FIS同時進行搜索,因為不同特征組合與組合間的運算是緊密聯系的。特征交互搜索在自底向上的搜索過程中同時完成了特征組合搜索與特征組合間的運算搜索。EDS結構,它為特征embedding的每個值分配一個剪枝搜索權重,用來修改重參化后的embedding。最后根據搜索非0權重位置構建embedding table的稀疏表示。
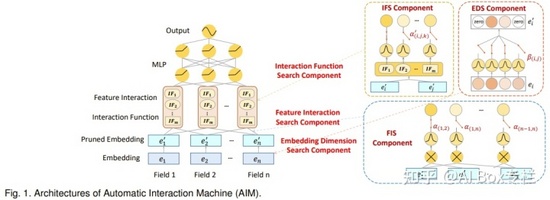
4 基于圖的特征交互
這部分主要介紹了近三年來應用圖神經網絡到CTR模型中,來建模特征交互的工作。
Fi-GNN
Fi-GNN: Modeling Feature Interactions via Graph Neural Networks for CTR Prediction, CIKM 2019
Fi-GNN首次嘗試將GNN用于建模特征之間的復雜交互,屬于開創性的工作。基本思想是構建特征圖,將特征作為圖的節點,兩兩節點之間都存在一條邊,邊上的權重代表特征交互的重要程度,以此將特征之間的復雜交互轉化為特征圖的節點之間的交互。在Embedding層中,模型使用了多頭注意力網絡層得到新的field embedding,蘊含了該field和其它特征field的高階特征交互。輸出為一個特征圖,作為后面Fi-GNN模型的輸入。Fi-GNN由多步組成。每一步會對節點做更新:使用注意力網絡聚合鄰居節點的信息,然后使用一個GRU單元對節點N進行狀態更新。在Fi-GNN中,每個節點通過和鄰居節點交換狀態信息,以循環的方式更新自身的狀態,圖網絡上更新的步數相當于特征交互的階數。

L0-SIGN
Detecting Beneficial Feature Interactions for Recommender System, AAAI 2021
特征交互對于在推薦系統中實現高精度推薦至關重要。然而,一些特征交互可能與推薦結果無關,可能會引入噪聲并降低推薦精度。處理組合問題一個很好的數據結構就是圖。為了充分利用特征交互,L0-SIGN構造了特征圖,所有的特征當成圖的頂點,圖中有沒有邊來表示兩個節點之間有沒有交互,邊的權重表示特征交互的重要性。同時文章提出了一種帶有L0激活正則化的邊預測模型,來自動檢測那些在推薦準確性方面有益的特征交互,從而過濾掉帶來噪聲的特征交互。

PCF-GNN
Explicit Semantic Cross Feature Learning via Pre-trained Graph Neural Networks for CTR Prediction, SIGIR 2021
和Fi-GNN用端到端建模不一樣,PCF-GNN是一個兩階段的模型。第一階段是GNN的預訓練:通過構建一種基于特征共現關系的GNN,節點表示每一個特征,邊的權重為特征共現度,顯式地建模特征共現目標。進行相應的預訓練(沒有像Fi-GNN一樣用多頭注意力機制學習節點初始表示),顯式地預測和輸出特征的交互關系,對于沒有出現過的新的交互,也可泛化預測。第二階段是下游的應用:GNN可以固定參數,作為交互特征提取器,在應用的階段首先推斷出交互特征的值,然后和其余特征拼接在一起作為后面DNN的輸入;也可以做預訓練的范式,在下游CTR模型訓練過程中微調GNN,更新每個特征的表示。
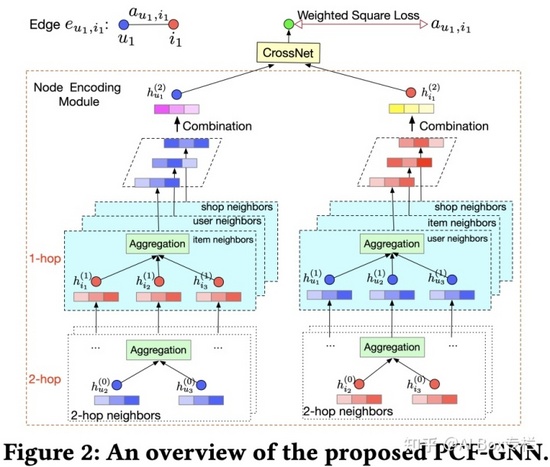
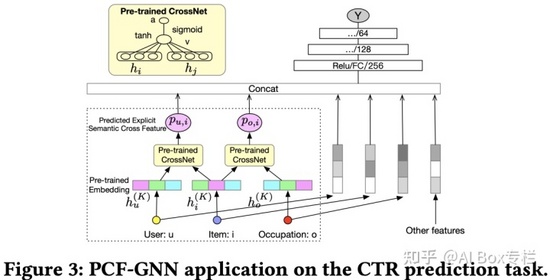
DG-ENN
Dual Graph enhanced Embedding Neural Network for CTR Prediction, SIGKDD 2021
現有工作存在兩個主要的問題:特征稀疏性,特征交互依賴于特征之間的共現信息,稀疏特征在訓練集很少出現,因此很難訓練充分;行為稀疏性,用戶行為呈長尾分布,大部分用戶的交互行為比較稀少。
針對特征稀疏性,參考前面兩篇工作,引入特征圖來自動建模特征交互,high-degree的特征能夠輔助鄰近的low-degree稀疏特征的表示學習,緩解特征共現帶來的偏差和不置信。針對行為稀疏性,可以構建user-item的交互圖,這樣能夠利用其它用戶行為中蘊含的協同信息來解決目標用戶行為稀疏的問題。最終模型把增強的用戶表示、物品表示、屬性表示、上下文表示做調整,輸入到DNN中。

5 基于序列的特征交互
DIN
Deep Interest Network for Click-Through Rate Prediction, SIGKDD 2018
在傳統的特征交互模型中,不同維度的Embedding在拼接后輸入到MLP中以擬合高階非線性關系,但這種框架下用戶的Embedding是不變的,很難獲取用戶的多興趣。本文的動機是模型上如何建模用戶的多峰興趣。DIN創新性地加入了Attention機制,把target item作為query在動態聚合user的歷史行為,這樣在不同場景中,用戶不同的瀏覽歷史會構建出不同的用戶表示。另外,這篇文章還有一些其他重大的創新,例如dice激活函數,group_auc指標等。

DIEN
Deep Interest Evolution Network for Click-Through Rate Prediction, AAAI 2019
在推薦場景下,用戶的興趣會隨著時間和空間的變化而發生變化,只通過用戶歷史數據中的興趣因素,而不關注興趣的變化,使得現有的一些模型無法很好的在CTR預估任務中對用戶興趣的變化進行刻畫捕捉。DIEN利用雙層GRU對用戶興趣序列進行刻畫。Behavior Layer將用戶瀏覽過的商品按照瀏覽時間轉換成對應的embedding。Interest Extractor Layer利用GRU提取用戶興趣特征。具體加入一個二分類模型來計算興趣抽取的準確性,用輔助網絡得到預測結果。Interest Evolution Layer中利用Attention(局部關注)配合 GRU(序列學習)的形式,從時序特征中構建與目標物品相關的興趣演化特征。
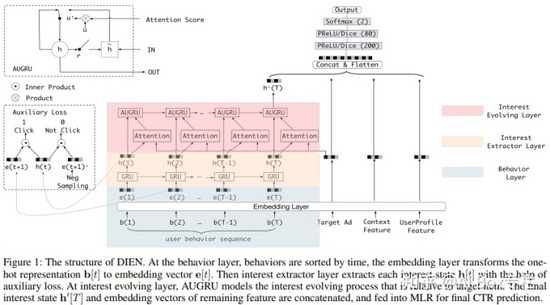
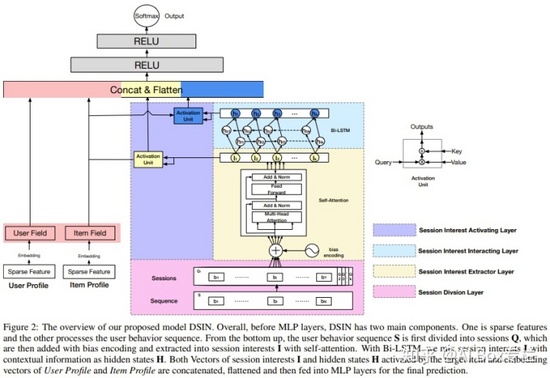
DSIN
Deep Session Interest Network for Click-Through Rate Prediction, IJCAI 2019
DSIN通過將用戶的歷史點擊行為劃分為不同session,然后利用Transformer對每個Session進行學習得到興趣向量后,使用BiLSTM學習用戶在多個Session之間的興趣變化。Session Division Layer完成對用戶歷史點擊行為的劃分,得到多個Sessions;Session Interest Extractor Layer使用Bias Encoding的方式表征不同Session間的順序,同時考慮到用戶興趣可能來自不同因素,利用多頭注意力機制對每個session 建模得到興趣向量表示;Session Interest Interacting Layer在得到用戶的興趣向量表征之后,利用Bi-LSTM學習不同Session之間的由順序帶來的興趣變化;Session Interest Activating Layer利用注意力機制學習不同Session和Item之間的相關性,混合上下文信息的興趣信息之后,對距離較近的Session賦予更大的權重。
DMR
Deep Match to Rank Model for Personalized Click-Through Rate Prediction, AAAI 2020
現有工作主要集中在用戶表示上,很少關注用戶和物品之間的相關性。本文提出了一種深度匹配排名方法(DMR),將協同過濾與匹配的思想相結合,用于CTR預測中的排名任務。模型分為user-to-item網絡和item-to-item網絡兩部分。在user-to-item網絡中,借助協同過濾的思想,通過embedding空間中相應表示的內積直接計算用戶與物品之間的相關性,從用戶行為中提取用戶表示。考慮到最近的行為可以更好地反映用戶的時間興趣,使用注意力機制來自適應地了解每種行為在行為序列中的位置的權重。本文也提出了一個輔助匹配網絡,幫助更好地訓練user-to-item網絡。輔助匹配網絡可看作是一種匹配方法,其任務是根據用戶的歷史行為來預測下一個要點擊的項目,DMR需要同時訓練匹配模型和排名模型。在item-to-item網絡,與DIN類似,通過包含位置信息的注意力機制,計算用戶交互物品與目標物品之間的物品之間相似度,然后進行聚合,以獲得另一種形式的用戶與物品的相關性表示。

CAN
CAN: Feature Co-Action for Click-Through Rate Prediction, WSDM 2022
CAN主要以一種新的方式重新思考高階特征交互。本文首先提出co-action的概念,指出特征交互對最終預測的影響。如果原始特征的co-action信息建模本身有用,那么笛卡爾積就是建模co-action最直接的方式。最直接的使用二維笛卡爾積的方式來顯式做co-action建模會帶讓參數量急劇上升。為了解決這個問題,本文提出了Co-Action Unit使用模型化的方案建模特征之間的交互。具體來講:Co-action Unit的輸入包含兩部分——希望建模交互關系的兩個特征,一端信息作為輸入,另一端信息作為MLP的參數,用MLP的輸出來表達Co-action信息。
對序列做DIN/DIEN類似的聚合,在co-action的視角下可以看做是對原始行為序列的embedding做一個純量的修正,item的表示只有一套。而CAN是用向量來建模的,并且使用的新的embedding和原始序列的embedding完全獨立,因此模型自由度和容量更大。
CAN提供了一種新的特征交互思路,在特征工程上手動特征交叉和模型上自動特征交叉之間做了折衷,也是記憶性和泛化性的互補。可以看作是特征交互的一種新范式。