













牛津大學最新調(diào)研:AI面臨基準危機,NLP集中“攻關”推理測試

人工智能(AI)基準為模型提供了衡量和比較的路徑,超越基準,達到SOTA,經(jīng)常成為頂會論文的標配。同時,有些基準確實推動了AI的發(fā)展,例如ImageNet 基準測試對近幾年的熱潮功不可沒。
如今,ImageNet 基準仍然在研究中發(fā)揮核心作用,一些新模型,例如谷歌的Vision Transformer在論文中仍然與ImageNet方法進行比較。
但,如果某一基準的分數(shù)一直占據(jù)榜首,后續(xù)沒有高質(zhì)量基準引入,那么這種依靠基準推動發(fā)展的“路子”就有問題。

近日,維也納醫(yī)科大學和牛津大學的研究人員對AI基準圖譜進行了調(diào)查,共統(tǒng)計了2013年以來CV和NLP領域的406項任務的1688項基準。發(fā)現(xiàn):很大一部分基準迅速趨于接近飽和,還有一部分基準被擱置;同時,在NLP領域,從2020年開始,新基準的建立減少,方向轉向推理或推理相關的高級任務上。
在文中,作者呼吁,未來的工作應該著重于大規(guī)模的社區(qū)合作,以及將基準性能與現(xiàn)實世界效用和影響相聯(lián)系。
1.33%的AI基準被“擱置”
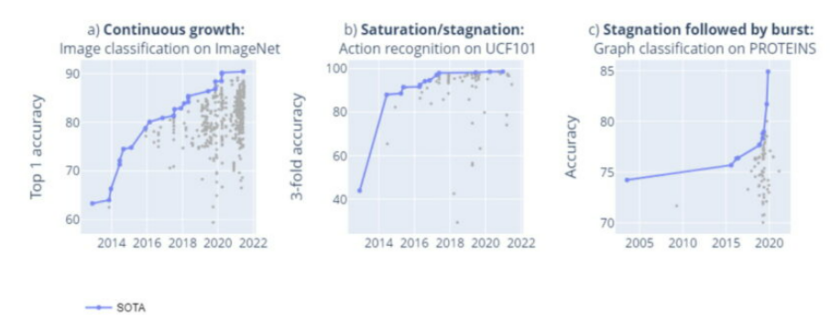
從單個基準出發(fā),如上圖可以看出基準上的SOTA有三種狀態(tài):穩(wěn)定增長,停滯或飽和,以及停滯后的飛躍。其中,穩(wěn)定增長代表技術穩(wěn)定;停滯背后代表缺乏技術進步的能力;而爆發(fā)是指技術出現(xiàn)突破。
事實上,近年來,關鍵領域,如NLP,有相當一部分新基準迅速趨于飽和,或者設計針對特定基準特征過度優(yōu)化的模型,而這些模型往往無法泛化到其他數(shù)據(jù)中。
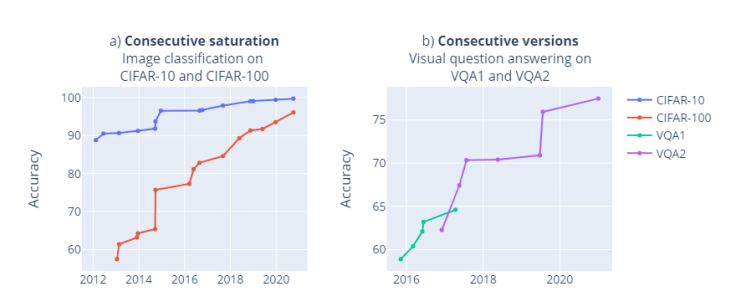
目前,這些現(xiàn)象已經(jīng)蔓延到相同領域的不同基準中,例如上圖,CIFAR-10和CIFAR-100的狀態(tài)。
同時,數(shù)量方面也出現(xiàn)了尷尬的局面,例如《2021年的人工智能指數(shù)報告》指出,CV基準數(shù)量或許能滿足日益增長的任務需求;而NLP模型的增長速度正在超過現(xiàn)有的問答和自然語言理解基準。
Martínez-Plumed等學者分析了 CIFAR-100 和 SQuAD1.1 等 25 個流行 AI 基準背后“故事”,他們發(fā)現(xiàn)“SOTA 前沿”由某些長期協(xié)作的社區(qū)主導,例如美國或亞洲大學與科技公司共同合作的組織。
此外,其他學者分析了大量 AI 基準測試工作中數(shù)據(jù)集使用和再利用的趨勢,他們發(fā)現(xiàn),很大一部分“知名”數(shù)據(jù)集是由少數(shù)高知名度的組織提出,其中一些數(shù)據(jù)集被越來越多地重新用于新的任務。NLP是個例外,它對新的、特定任務的基準的引入和使用超過了平均水平。
在這項研究中,維也納醫(yī)科大學和牛津大學的研究人員表明:飽和和擱置非常常見。總體看來有以下幾個趨勢:
1.缺乏研究興趣是導致停滯不前的原因之一;
2.所有基準中的大多數(shù)很快就會達到技術停滯或飽和;
3.在某些情況下,會出現(xiàn)持續(xù)增長,例如在 ImageNet 基準測試中;
4.性能改進的動態(tài)變化并不遵循一個清晰可辨的模式:在某些情況下,停滯階段之后是不可預測的飛躍。
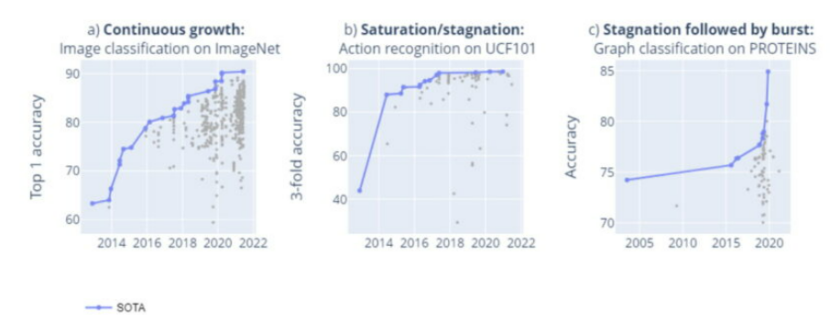
圖注:基準有三種發(fā)展趨勢:穩(wěn)定增長,停滯或飽和,以及停滯后的飛躍。
此外,在1688個基準中,只有66%的基準充分被利用,換言之33%的基準被擱置。同時,基準測試的另一個趨勢是:被某些既定機構和公司的數(shù)據(jù)集主導。
2.NLP基準正面向高難度的任務
過去幾年,CV領域的基準占據(jù)主導地位,但NLP也開始了蓬勃發(fā)展。2020年,新基準的數(shù)量有所下降,越來越多地集中在難度較高的任務上,例如測試推理的任務,例如BIG-bench和NetHack,前者屬于谷歌,后者來自Facebook。
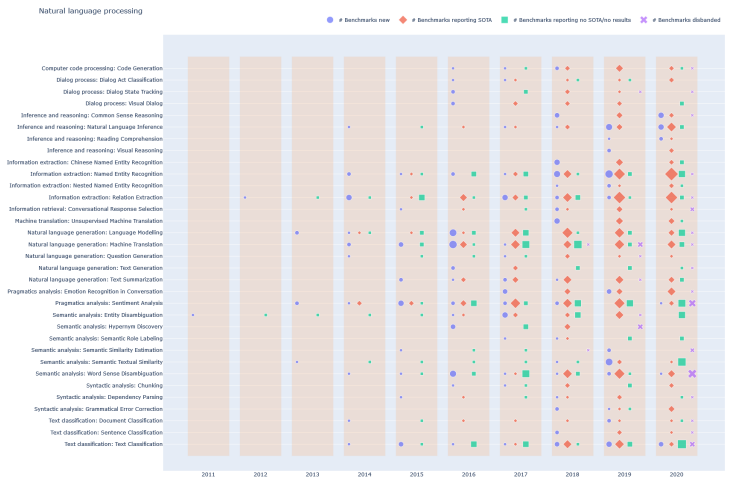
上圖是NLP的基準生命周期展示,可以清晰看出,大多數(shù)任務的幾個主流基準是在2011~2015年間建立的,這期間,也只有少數(shù)幾個SOTA出現(xiàn)。2016年之后,新基準的建立速度大大加快,在翻譯和自然語言建模方面表現(xiàn)最為突出;2018和2019年,分別都針對各種任務建立了大量的基準;2020年是個轉折點,新基準的建立減少,方向轉向推理或推理相關的高級任務上。
整體來說,當前AI基準的趨勢是:來自既定機構(包括工業(yè)界)的基準的趨勢引起了人們對基準的偏見和代表性的關注;許多基準并不能完全將AI性能與現(xiàn)實世界相匹配,因此,開發(fā)少量但有質(zhì)量保證,涵蓋多種AI能力、場景的基準可能是可取的。
最后,研究人員展望,在未來,新的基準應該由來自許多機構、知識領域的大型合作團隊開發(fā),如此才能確保建立高質(zhì)量的基準。
























