網絡編程 | 徹底搞懂網絡 IO 模型

令人頭大的 IO
說起網絡 IO 相關的開發(fā),很多人都頭大,包括我自己,寫了幾年的代碼,對 IO 相關的術語說起來也是頭頭是道,什么 NIO、IO 多路復用等術語一個接一個。但是也就自己知道,這些概念一團亂,網上各種各樣的文章也沒一個權威易懂的,并且很多文章說起 IO 就扯上 Java 的 NIO 包,專注的大多是如何使用(術)而不是 IO 的本質(道)。所以寫這篇文章來從 socket 編程的痛點,轉到 NIO 的解決方案,再到多路復用器的發(fā)展來一起梳理網絡IO 模型。
從 Socket 編程說起
做業(yè)務開發(fā)的同學,常常面對的是 Spring Boot 這些框架幫我們搭建好的 Server 框架,但是如果往下去看框架幫我們實現(xiàn)的代碼最終會看到 Socket 相關的源碼, Socket 相關的代碼實際上就是 TCP 網絡編程。
目前主流的 HTTP 框架,比如 Golang 原生的 HTTP net/http,都是基于 TCP 編程實現(xiàn)的,按照 HTTP 協(xié)議約定,解析 TCP 傳輸流過來的數據,最終將傳輸數據轉換為一個 Http Request Model 交給我們業(yè)務的 Handler 邏輯處理。
例如,Golang 的 原生 Http 框架 net/http 為例就有這么些代碼片段:
l, err = sl.listenTCP(ctx, la) // 監(jiān)聽連接請求
rw, e := l.Accept() // 創(chuàng)建連接
go c.serve(connCtx) // 調用新的協(xié)程處理請求邏輯
w, err := c.readRequest(ctx) // 讀取請求
serverHandler{c.server}.ServeHTTP(w, w.req) // 執(zhí)行業(yè)務邏輯,并返回結果
Socket 編程的過程
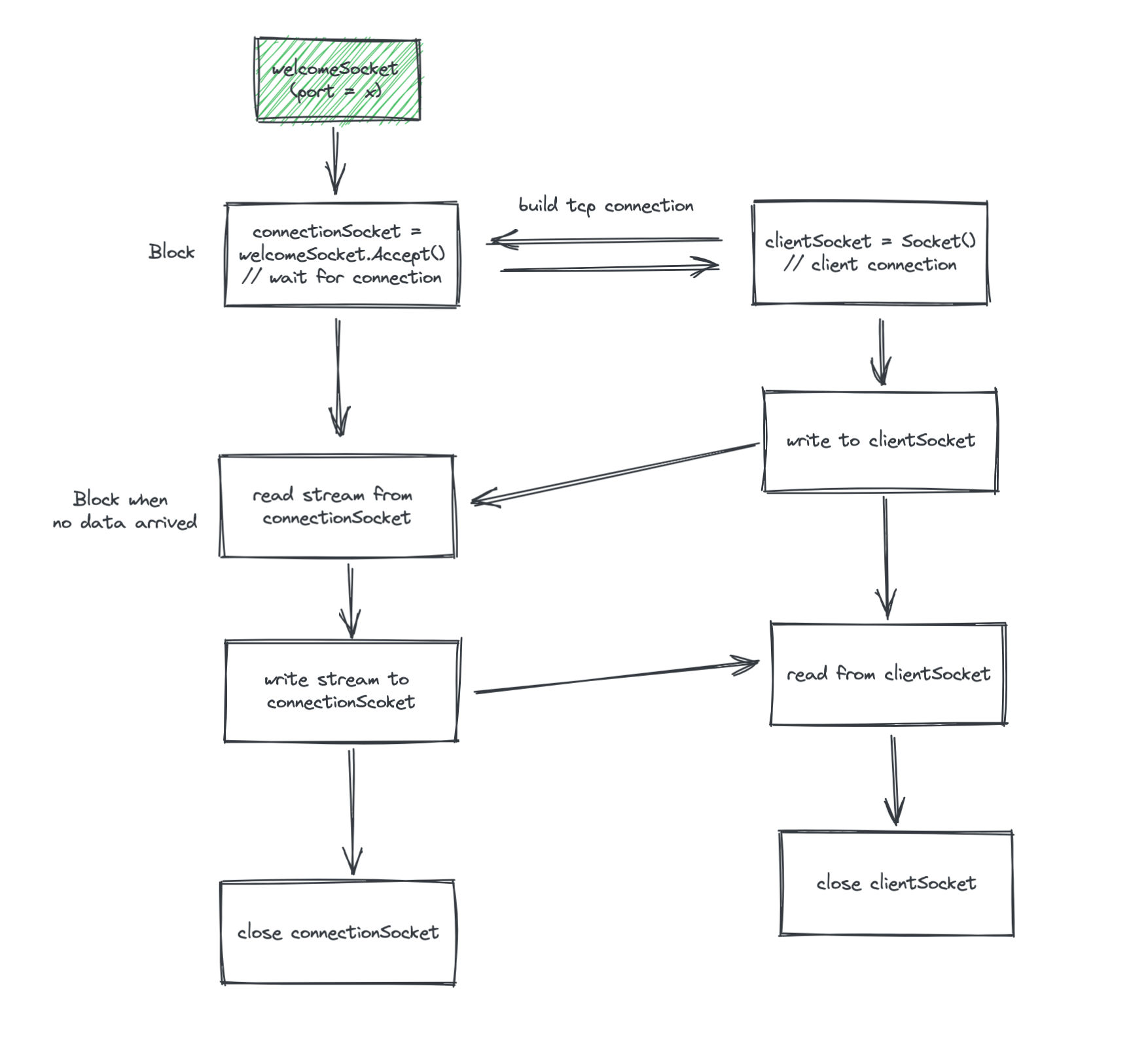
- 服務端需要先綁定(Bind)并監(jiān)聽(Listen)一個端口,這個時候會有一個歡迎套接字(welcomeSocket)
- welcomeSocket 調用 Accept 方法,接受客戶端的請求,如果沒有請求那么會阻塞住
- 客戶端請求指定端口,welcomeSocket 從阻塞中返回一個已連接套接字(connectionSocket)用于專門處理這個客戶端請求
- 客戶端往請求套接字寫入數據(Stream)
- 服務端從已連接套接字可以持續(xù)讀到數據,TCP 底層保證數據的順序性
- 服務端可以往已連接套接字寫入數據,客戶端從請求的套接字中可以讀到數據
- 客戶端關閉連接,服務端也可以主動關閉連接
如果用代碼手寫 Socket 服務端,用 Java 實現(xiàn)是這樣的:
public class Server {
public static void main(String[] args) throws Exception {
String clientSentence;
String capitalizedSentence;
ServerSocket welcomeSocket = new ServerSocket(6789);
while (true) {
Socket connectionSocket = welcomeSocket.accept(); // 當沒請求會阻塞住
System.out.println("connection build succ!");
BufferedReader inFromClient = new BufferedReader(new InputStreamReader(connectionSocket.getInputStream()));
DataOutputStream outToClient = new DataOutputStream(connectionSocket.getOutputStream());
clientSentence = inFromClient.readLine(); // 連接上但是客戶端還沒寫入數據會阻塞住
System.out.println("read succ!");
capitalizedSentence = clientSentence.toUpperCase() + '\n';
outToClient.writeBytes(capitalizedSentence);
System.out.println("write succ!");
}
}
}
我們可以用 Telnet 連接上去嘗試下,但是很快我們會發(fā)現(xiàn)兩個問題:
- Accept 是阻塞的,如果一個客戶端網絡比較差,三次握手時間長整個服務端就卡住了。
- Read 是阻塞的,如果客戶端連接上了,但是遲遲不發(fā)數據(比如我們 telnet 上,但是不寫)整個服務端就卡住了。
優(yōu)化思路:多線程處理,避免 read 阻塞
對于 Read 是阻塞的問題,我們開線程來處理,這樣當一個請求連接上遲遲不寫數據也不會影響到其他連接的處理了。當然這里得考慮到量級,如果量級太大的話需要改成線程池避免線程過多。
public class Server {
public static void main(String[] args) throws Exception {
ServerSocket welcomeSocket = new ServerSocket(6789);
while (true) {
Socket connectionSocket = welcomeSocket.accept(); // 當沒請求會阻塞住
System.out.println("connection build succ!");
new Thread(new Runnable() {
@Override
public void run() {
try {
String clientSentence;
String capitalizedSentence;
BufferedReader inFromClient = new BufferedReader(new InputStreamReader(connectionSocket.getInputStream()));
DataOutputStream outToClient = new DataOutputStream(connectionSocket.getOutputStream());
clientSentence = inFromClient.readLine(); // 連接上但是客戶端還沒寫入數據會阻塞住
System.out.println("read succ!");
capitalizedSentence = clientSentence.toUpperCase() + '\n';
outToClient.writeBytes(capitalizedSentence);
System.out.println("write succ!");
}catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
}
這個時候,我們用 telnet 客戶端連接已經感受不到服務端的瓶頸了。但是從我們上的分析來看,Accept 還是有瓶頸的,就是同時只能對一個請求做連接,而且即使是線程池的模式,如果連接(特別是空閑的)很多,最終也會出現(xiàn)阻塞的情況。
如果你的業(yè)務場景是連接數不多,同時又需要頻繁的交互數據,那么用 BIO 模式無論是對時延還是資源使用都有不錯的效果(相當于 VIP 1v1 服務)。
但是,我們的服務端代碼通常是面對海量的連接的,且很多客戶端連接上,并不會馬上發(fā)送請求,例如聊天室應用,很久用戶才會發(fā)送1條消息。這個時候如果還是這種 1v1 模式,那么有 100w 個用戶,就需要維護 100個連接,顯然是不合適,這太浪費資源了,而且很低效,大部分線程都是在 Block 等待用戶數據。
所以,這個時候 NIO(異步io)橫空出世了。網上有一張比較好的對比圖,可以很好地解釋差異:
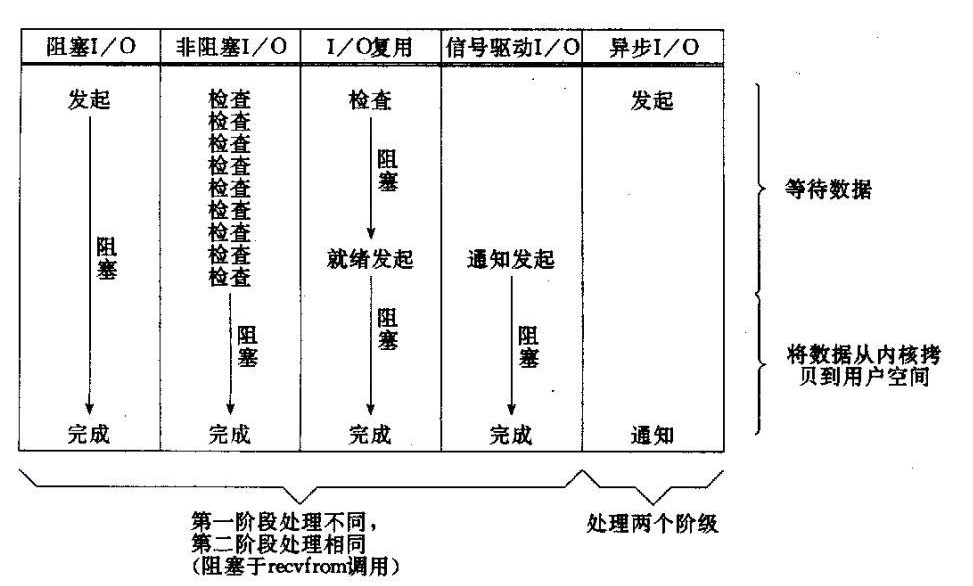
我們上文說的就是 阻塞I/O ,而現(xiàn)在要講的是非阻塞I/O。圖上主要闡述的是 `read()` 方法的過程,主要包括兩部分:
第一階段:等待TCP RecvBuffer 數據就緒,這個在傳統(tǒng)的BIO里如果數據沒就緒,就會阻塞等待,不消耗CPU。
第二階段:將數據從內核拷貝到用戶空間,消耗CPU但是速度非常快,屬于 memory copy。
非阻塞I/O
所以對于 非阻塞I/O 來說,主要要優(yōu)化的是調用 `read()` 方法數據還未就緒導致阻塞問題。這個解決方法很簡單,大部分編程語言都有提供 nio 的方法,只要數據還沒準備就緒不要block,直接返回給調用者就可以了。這樣我們這個線程就可以接著去處理其他連接的數據,這樣就不用每個連接單獨只有一個線程來服務了。
I/O 多路復用
對于非阻塞 I/O 模式,開發(fā)者仍然需要不斷去輪詢事件狀態(tài),如果請求量級很大, 這樣的機制同樣還是會浪費很多資源,同時開發(fā)難度較高。其實想一想,我們作為開發(fā)者的訴求無非就是監(jiān)聽某些事件,比如完成鏈接(accept完成)、數據就緒(可read)等。關于事件的監(jiān)聽其實也無關乎編程語言,在操作系統(tǒng)層面就可以做而且可以做的更高效。操作系統(tǒng)上提供了一系列系統(tǒng)調用,比如 select/poll/epool,這些系統(tǒng)調用后會阻塞,當有對應的事件到來觸發(fā)我們注冊到事件上的Handler邏輯。
所以簡單來說,就是上文說的 非阻塞I/O 用戶自行寫輪詢查看狀態(tài)的邏輯被收斂到操作系統(tǒng)這里提供的 I/O 復用器了,整個程序執(zhí)行起來的邏輯大概變成這樣。
interface ChannelHandler{
void channelReadable(Channel channel);
void channelWritable(Channel channel);
}
class Channel{
Socket socket;
Event event;//讀,寫或者連接
}
//IO線程主循環(huán):
class IoThread extends Thread{
public void run(){
Channel channel;
while(channel=Selector.select()){//選擇就緒的事件和對應的連接
if(channel.event==accept){
registerNewChannelHandler(channel);//如果是新連接,則注冊一個新的讀寫處理器
}
if(channel.event==write){
getChannelHandler(channel).channelWritable(channel);//如果可以寫,則執(zhí)行寫事件
}
if(channel.event==read){
getChannelHandler(channel).channelReadable(channel);//如果可以讀,則執(zhí)行讀事件
}
}
}
Map<Channel,ChannelHandler> handlerMap;//所有channel的對應事件處理器
}
Reactor 模型
目前大多高性能的網絡IO框架主要都是基于IO多路復用 + 池化技術的的 Reactor 模型,Reactor 其實只是一個網絡模型概念并不是具體的某項具體技術。常見的主要有三種,單Reactor + 單進程/單線程、單Reactor + 多線程、多Reactor + 多進程/多線程。
單Reactor + 單進程/單線程
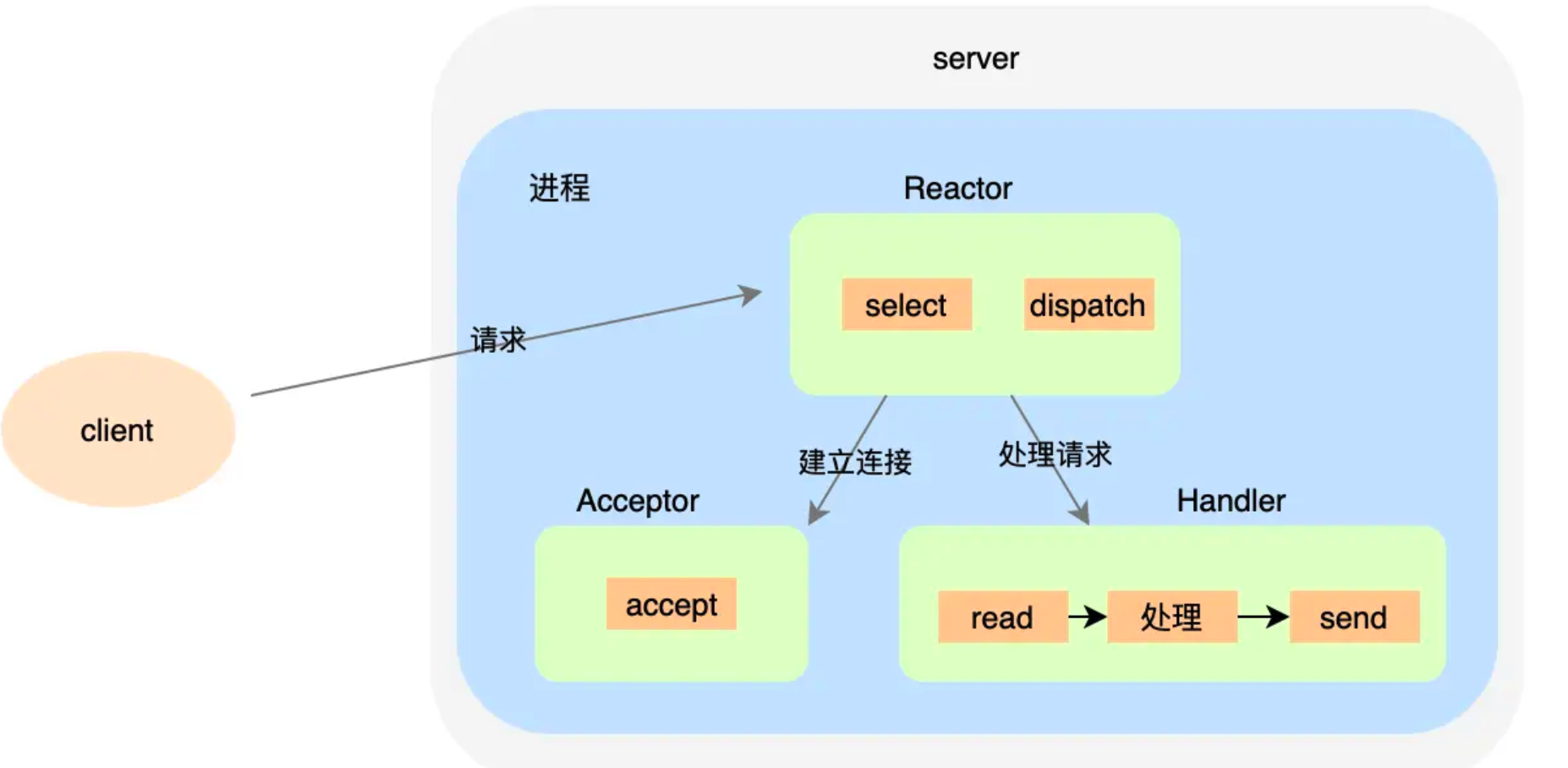
多路復用器 Select 返回結果后,有個 Dispatch 用于分發(fā)結果事件。如果是連接建立事件,Acceptor接受連接并創(chuàng)建對應的Handler來處理后續(xù)事件。如果不是連接事件,直接調用對應的 Handler,Handler 完成數據讀取 read 、process、send 的完整業(yè)務流程。
這種模式優(yōu)點是簡單、不用考慮進程間通信、線程安全、資源競爭等問題,但是也有自身局限性,也就是無法充分利用多核資源,適用于業(yè)務場景處理很快的場景,比如 Redis 就是用這種方案。
單Reactor + 多線程
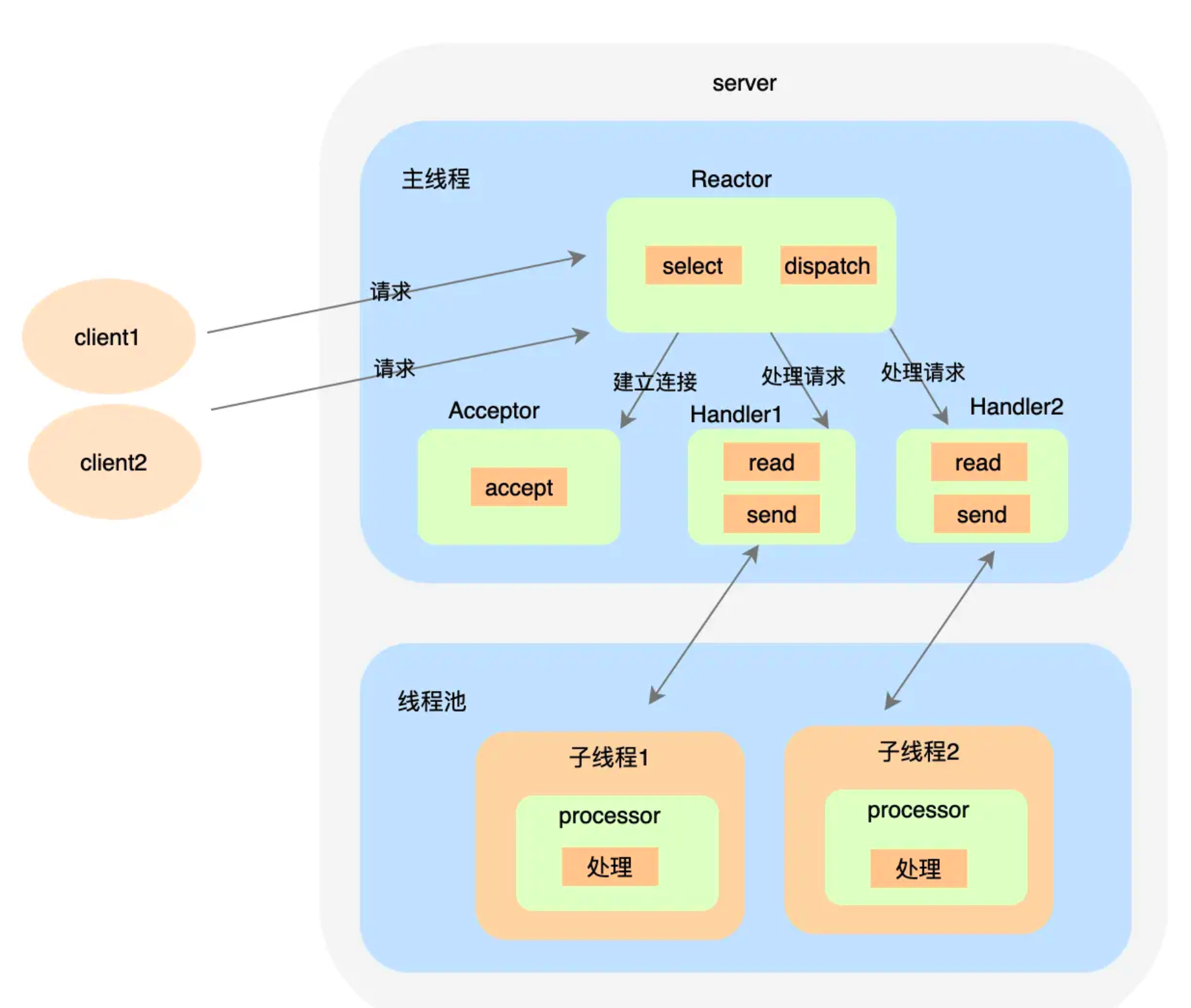
相比于上一種方案,不同的是 Handler 只負責數據讀取不負責處理事件,而是有一個單獨的 Worker 線程池來做具體的事情。之所以 processor 要隔離單獨的線程池是因為 `read` 方法本身是需要消耗 cpu 資源的,通常不適合大于 cpu 核數,而用戶自定義的 processor 邏輯里可能有各種網絡請求,比如 RPC 請求,如果隔離開來,那么 processor 可以設置更大的線程數,提升吞吐量。
這種模式已經可以比較充分利用到多核資源了,但是問題在于主線程承擔了所有的事件監(jiān)聽和響應。瞬間高并發(fā)時可能成為瓶頸,這就需要多 Reactor 的方案了。
多Reactor + 多進程/多線程
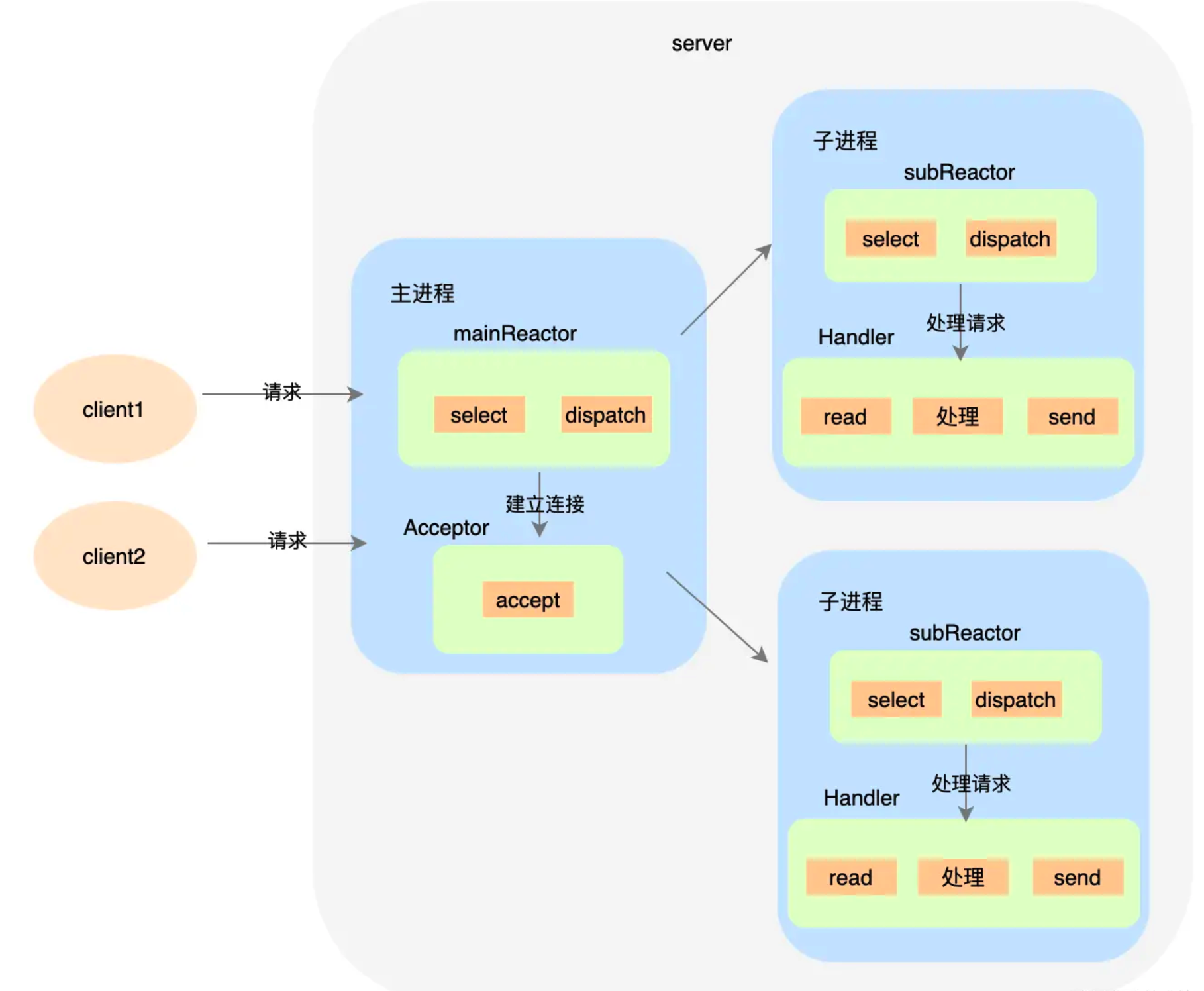
處理步驟:
- 父進程中 mainReactor 對象通過 select 監(jiān)控連接建立事件,收到事件后通過 Acceptor接收,將新的連接分配給某個子進程。
- 子進程的 subReactor 將 mainReactor 分配的連接加入連接隊列進行監(jiān)聽,并創(chuàng)建一個Handler 用于處理連接的各種事件。
- 當有新的事件發(fā)生時,subReactor 會調用連接對應的 Handler 來進行響應。
- Handler 完成 read→處理→send 的完整業(yè)務流程。
目前著名的開源系統(tǒng) Nginx 采用的是多 Reactor 多進程,采用多 Reactor 多線程的實現(xiàn)有Memcache 和 Netty。不過需要注意的是 Nginx 中與上圖中的方案稍有差異,具體表現(xiàn)在主進程中并沒有mainReactor來建立連接,而是由子進程中的subReactor建立。
異步非阻塞 I/O
服務器實現(xiàn)模式為一個有效請求一個線程,客戶端的I/O請求都是由OS先完成了再通知服務器應用去啟動線程進行處理,AIO又稱為NIO2.0,在JDK7才開始支持。但是由于 Linux 上 AIO 的底層實現(xiàn)并不好,所以目前沒有被廣泛使用。比如大名鼎鼎的Netty框架也是使用NIO而非AIO。
總結
這篇文章從 socket 編程出發(fā),你了解到了怎么利用socket編寫服務端代碼,然后在 socket 編程時發(fā)現(xiàn)了痛點,一個在于 accept 建立連接會阻塞線程,另一個在于 read 數據時會阻塞,為了解決阻塞可能導致的低效問題,我們嘗試了用多線程方法來初步解決。
但是在這之后,我們又看到面對海量連接時,BIO 力不從心的現(xiàn)象,所以引入了 NIO 模型。這里闡述了從 NIO 到 多路復用器的進步,相當于是操作系統(tǒng)幫我們做了海量連接事件的監(jiān)聽,這個模式也被稱作 Reactor 模式。最后講到了異步I/O,雖然理想很美好,但是底層基建并不完善,目前這種模式在生產中被使用還比較少。
我寫這篇文章,并沒有描述很多具體的API,因為我希望通過這個文章來幫助大家真正了解IO模型的本質,而不是羅列topic,或者硬性記憶API,因為編程語言很多,而解決方案的思想是統(tǒng)一的。這也是我們學習應該注意的,更多的應該學其道,而不是學其術。