遷移學習前沿探究探討:低資源、領域泛化與安全遷移
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
遷移學習是機器學習的一個重要研究分支,側重于將已經學習過的知識遷移應用于新的問題中,以增強解決新問題的能力、提高解決新問題的速度。
4月8日,在AI TIME青年科學家——AI 2000學者專場論壇上,微軟亞洲研究院研究員王晉東做了《遷移學習前沿探究探討:低資源、領域泛化與安全遷移》的報告,他提到,目前遷移學習雖然在領域自適應方向有大量研究,相對比較成熟。但低資源學習、安全遷移以及領域泛化還有很多待解決的問題。
針對這三方面的工作,王晉東提供了三個簡單的、新的擴展思路,以下是演講全文,AI科技評論做了不改變原意的整理。
所有內容可以在作者整理維護的Github上最流行的遷移學習倉庫:transferlearning.xyz 上找到相關材料
今天介紹遷移學習三個方向的工作:低資源、領域泛化與安全遷移。遷移學習英文名稱:Transfer learning,基本范式是通過微調“重用”預訓練模型。縱觀機器學習的絕大多數應用,都會采用這種預訓練+微調的范式,節省成本。
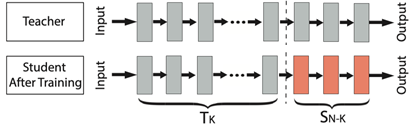
上圖遷移學習范式示例,在Teacher網絡模型中,經過輸入、輸出一整套流程訓練,已經獲得比較好的性能。Student模型想要訓練,則可以固定或者借用Teacher網絡的Tk層,然后單獨根據任務微調模型,如此可以獲得更好的性能。
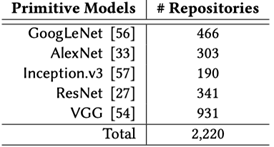
目前,在CV領域,已經存在ResNet;在NLP領域已經有BERT、RoBERT等模型可供使用。如上圖,2016年GitHub上有個統計,關于遷移學習的Repository總計有2220個,當前可能會更多。

上圖展示了,過去五年,遷移學習領域在頂級會議上取得的進展。最早是吳恩達在NIPS16上表示遷移學習在未來非常重要;然后,CVPR2018上有一篇最佳論文是關于遷移學習的;同年,IJCAI18上,有團隊用遷移學習的手法贏得ADs競賽;2019年,ACL會議上,有學者強調遷移學習的范式在NLP領域非常重要,一年后,一篇遷移學習論文拿到了該會議的最佳論文提名。
一直到去年,深度學習三巨頭表示,現實的世界中,數據分布不穩定,有必要開發快速適應小數據集變化的遷移模型。
事實上,隨著我們認知越來越多,會逐漸認識到遷移學習有很多問題待解決,需要不斷開發新的方法。
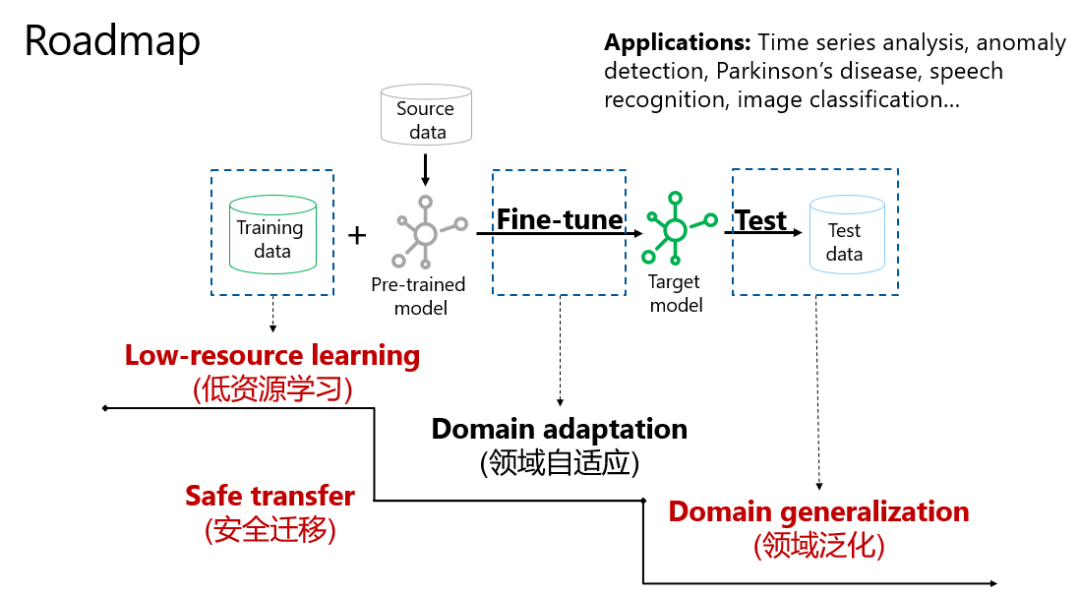
在移學習范式中,如果訓練數據和預訓練模型剛好匹配,則能開發出性能優越的應用;如果有較大差異,則可以借助“外援數據”進行修正,然后獲得目標模型,進而在測試(未知)數據上獲得較好表現。
從訓練數據到測試數據,整套流程中,其實存在很多問題,例如:
- 低資源學習,即如何在小數據情況下,如何設置遷移模型;
- 領域自適應,即如何解決當訓練集和測試集的數據分布存在偏差;
- 領域泛化,如何從若干個具有不同數據分布的數據集(領域)中學習一個泛化能力強的模型;
- 同時,整個過程還需要時刻注重安全遷移,確保隱私不泄露,模型不“中毒”等等。
目前,領域自適應方面已經有大量研究成果、該領域相對較成熟。但低資源學習、安全遷移以及領域泛化等方面還有很多待解決的問題。
1 低資源學習
低資源學習的本質是,依賴少量的有標簽的樣本去學習泛化能力強的模型,期望其在未知的數據上表現良好。但問題在于,在各種場景下如何確保小數據中的標簽仍然含有知識、且這些知識能被遷移到大量的無標簽數據上。
經典的工作來自于NeurIPS 2020,當時谷歌在論文中提出FixMatch算法,通過一致性正則和基于閾值的置信度來簡化半監督學習,設置固定閾值調整遷移學習的知識。
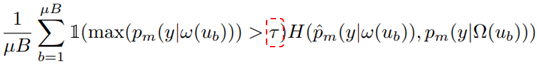
公式如上,模型學習的置信度要根據閾值來判定,如果大于一定的域值,就使用這些數據進行訓練和預測;否則這些數據則不參與下次訓練。
那么,對于半監督學習而言,預訓練模型僅考慮閾值就足夠了嗎?谷歌在論文中,將閾值設置為0.95,顯然這個數字是由谷歌的實驗得出,其實我們在真實世界中,永遠無法得知的取值是多少。
基于此,需要學習一個更真實的閾值,也即開發一種自適應學習,讓模型根據數據靈活決定值。為了驗證這一想法,我們先回答“選擇固定閾值還是靈活閾值”。
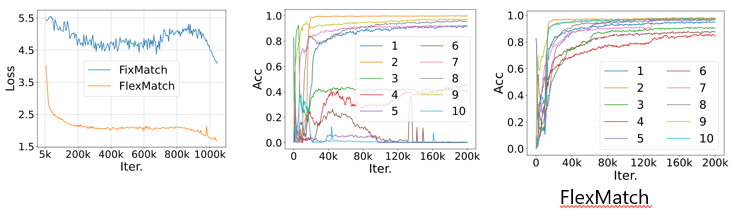
如上圖(左)所示,固定閾值的Loss下降的特別慢。同時,通過對比兩種選擇的ACC指標也能證明,如上圖(中),對于不同的類別,需要設置不同的閾值。
在“動態調整”的思想下,我們在NeurIPS 2021上提出FlexMatch算法,有以下幾個特點:
- 對于不同的類別,能進行不同程度的閾值自適應;
- 對于不同的樣本,設置不同閾值;
- 測試階段,需要對閾值“一視同仁”
- 全程無人工干擾,全自動學習閾值
實驗結果表明,如上圖(右)所示,在同樣的數據集上,該方法呈現正向曲線,效果比較穩定。FlexMatch的設計思想借用了“課程學習”,半監督學習常用給不確定樣本打偽標簽的策略,偽標簽的學習應該是循序漸進的遷移的過程,即由易到難的過程,然后類別的學習也是由易到難的過程。同時,FlexMatch采取了聚類假設:類別和閾值息息相關。
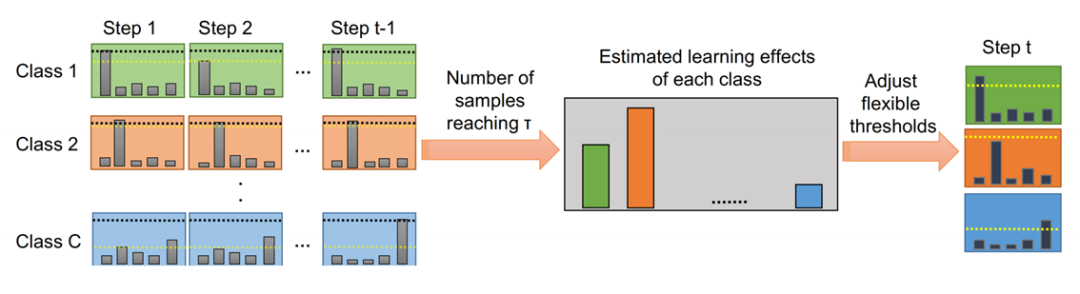
以上是該思想的流程圖,和FixMatch大同小異,不同之處是強調在不同類別上,會預估學習難度,然后自適應調整閾值。
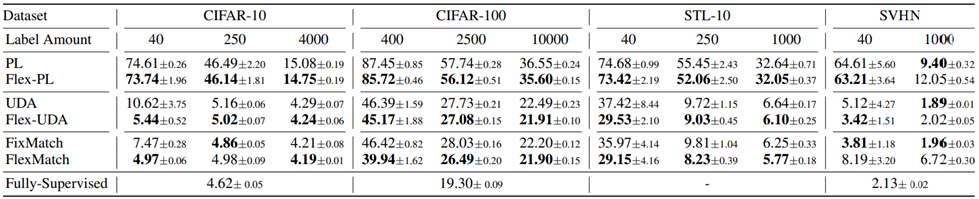
以上是在CIFAR10/100、SVHN、STL-10和ImageNet等常用數據集上進行了實驗,對比了包括FixMatch、UDA、ReMixmatch等最新最強的SSL算法。實驗結果如上表所示,可以發現FlexMatch在標簽有限的情況下能顯著改進。在未引入新的超參數、無額外計算的情況下,對于復雜任務,也有顯著改進,且收斂速度顯著提升。
值得一提的是,針對該領域,我們開源了一個半監督算法庫TorchSSL,目前已支持算法有:Pi-Model,MeanTeacher,Pseudo-Label,VAT,MixMatch,UDA,ReMixMatch,FixMatch。
鏈接:https://github.com/TorchSSL/TorchSSL
2 低資源應用
現實世界中存在大量語言,但有很少的標注數據,世界上有7000種語言,常用的語言也就那么幾十種,剩下絕大大多數都是低資源的語言。需要對小數據進行模型訓練,同時能夠避免模型過擬合。所以,針對低資源語言的自動語音識別(ASR)仍然是端到端(E2E)模型的一個挑戰。
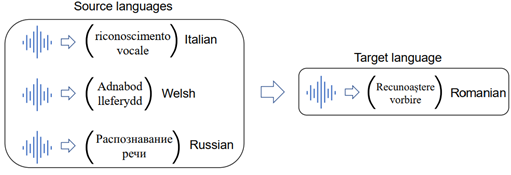
遷移學習的解決方案是,對資源豐富的語言進行預訓練,對資源低的語言進行微調,對資源豐富的語言和資源低的語言進行多任務學習,同時對資源豐富的語言進行元學習,以快速適應資源不足的語言。
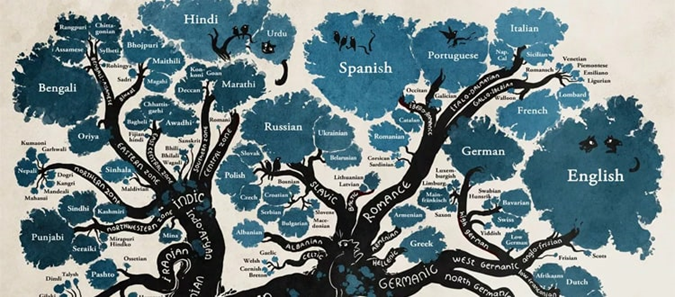
具體而言,要發現語言之間的聯系,例如上圖表明,不同的語言、不同的語系之間會有相似、相關性。這些語言具體怎么分布,有哪些相似性?我們的目標是如何自適應學習這種關系。
當前主要有兩種方法:隱式、顯式。其中,隱式是指不對他們的關系做任何假設,通過網絡直接學習;顯式是指假設語言之間存在線性關系,簡化算法。
基于上述兩點,我們就設計了兩個簡單的算法MetaAdapter和SimAdapter。前者能夠直接學習不同語言之間的關系;后者假設語言之間是線性關系,用注意力機制進行學習。同時,結合MetaAdapter和SimAdapter,我們設計了SimAdapter+,能達到更好的效果。具體模型結構如下所示,只用微調數據里面的參數,就可以去完成網絡的訓練。
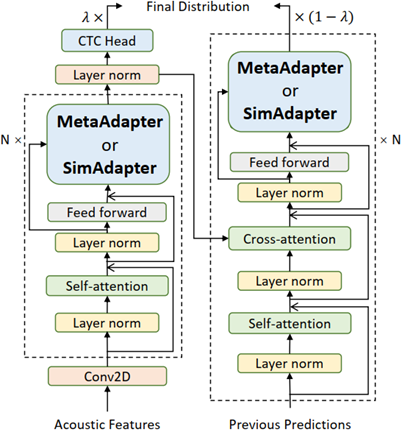
3 領域泛化
領域泛化的目的是利用多個訓練分布來學習未知領域的通用模型。存在數據屬性隨時間動態變化,導致動態分布變化等問題。因此,需要捕捉數據的動態分布變化,例如如何量化時間序列中的數據分布。
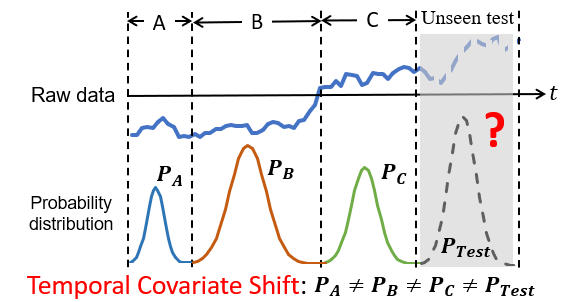
針對上述挑戰,我們提出AdaRNN。首先將時間序列中分布動態改變的現象定義為時序分布漂移 (Temporal Covariate Shift, TCS)問題,如上圖所示將一段時間的數據分為A、B、C以及未知數據,可以看出A、B之間,B、C之間以及A、C之間的數據分布相差比較大,如何解決?分兩步走:先來學習數據最壞情況下的分布,然后匹配最壞分布的差距。
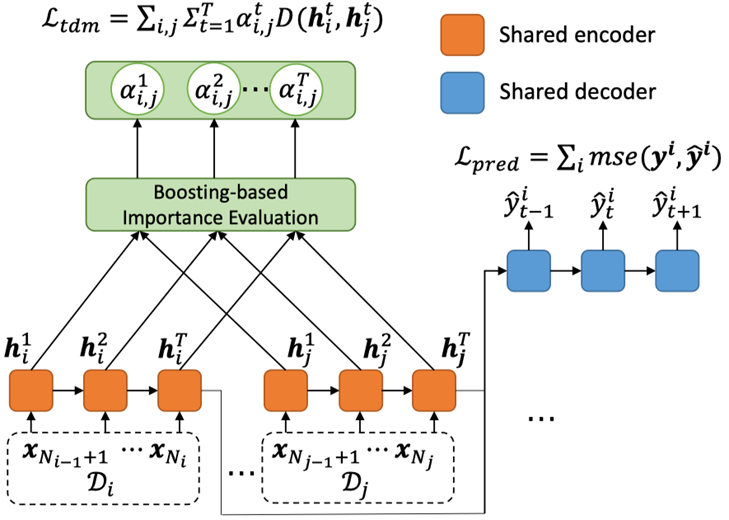
具體而言,采用聚類方法優化問題,然后用貪心算法求解序列分布,將數據分成幾段;最后,設計領域泛化進行匹配分布。
我們在四個真實數據集上測試了算法的效果,包括1個分類任務(行為識別)和3個回歸任務(空氣質量預測、用電量預測和股價預測)。實驗結果表明,模型性能有一定的提升。此外,我們發現不僅在RNN上,Adaptive方法對于Transformer結構也一樣有效。
4 安全遷移
安全遷移體現在遷移學習的各個方面,例如如何確保遷移學習模型不會被濫用?如何在保證效果的同時降低遷移模型的復雜性?如何進行安全的遷移學習、避免模型受到惡意攻擊而對用戶造成影響?
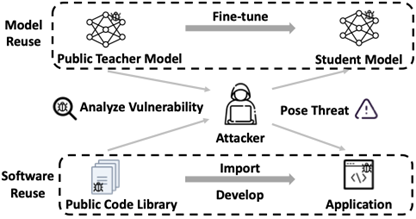
舉個例子,在軟件工程領域,如果軟件有惡意BUG,一旦你在開源社區下載該軟件,不僅會繼承該軟件好的功能,也會繼承它的容易受攻擊的弱點。另外,如果黑客知道用戶的軟件使用了哪段開源代碼,便可以對你的應用軟件發動相應攻擊。
我們統計了一下,在Teacher到student的微調范式中,Student可以從Teacher中繼承那些易受攻擊的弱點的概率為50%~90%。換句話說,最壞的情況是Teacher怎么被攻擊,Student便可以被攻擊。因為Teacher的模型是公開的。
因此,安全遷移研究的目的是如何減少預訓練模型被攻擊的情況,同時還能維護性能。這其中會解決未知攻擊、DNN模型缺乏可解釋性等難題。

我們考慮兩種攻擊:對抗攻擊,例如熊貓圖片中加入某些噪聲,AI會將其識別成長臂猿;后門攻擊,神經網絡結構本身就存在一些可能被利用的東西,例如輸入數字7,然后輸出數字8。
針對安全遷移問題,我們提出ReMoS算法,主要思想是:找出網絡有用權重,剔除無用權重。第一步:需要計算神經元;第二步:評估Teacher模型對Student模型的重要性,計算兩者之差;根據以上兩步,就可以輕松裁減不需要的權重。
實驗結果發現,ReMoS方法幾乎不會顯著增加計算量,其收斂速度與微調模型基本一致,顯著好于從頭開始訓練。
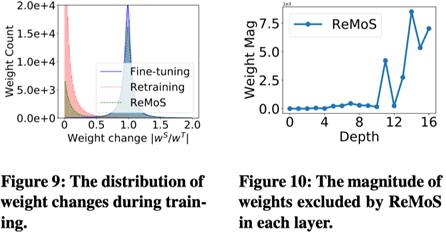
上圖(右)畫出了剪枝之后的權重和網絡層的關系。此結果說明隨著網絡層數據的加深,網絡越來越與學生任務相關,因此,在深層的權重大部分被重新初始化了。這一發現也符合深度網絡可遷移性的結論。
總結一下,今天主要介紹了三方面,低資源學習、領域泛化以及安全遷移。我為這三個方面提供了三個簡單的、新的擴展思路。希望接下來的研究者能夠設計出更好的框架,新的理論,然后在遷移學習的安全性方面去做一些探索。?