治噩夢(mèng)級(jí)摳圖 魏茨曼聯(lián)合英偉達(dá)發(fā)布Text2LIVE,用自然語(yǔ)言就能PS
使用Photoshop類(lèi)的軟件算是創(chuàng)造性工作還是重復(fù)性工作?
對(duì)于用PS的人來(lái)說(shuō),重復(fù)性工作如摳圖可能是一大噩夢(mèng),尤其是頭發(fā)絲、不規(guī)則的圖形、與背景顏色貼近的,更是難上加難。

如果有AI模型能幫你摳圖,還能幫你做一些如替換紋理、添加素材等工作,那豈不是能節(jié)省大把時(shí)間用來(lái)創(chuàng)作?
一些專(zhuān)注于視覺(jué)效果(VFX)的從業(yè)者對(duì)圖像和視頻合成方面的新工作和創(chuàng)新很感興趣,但他們同時(shí)也會(huì)感覺(jué)到威脅,擔(dān)心AI的快速發(fā)展是否會(huì)替代他們,畢竟現(xiàn)在AI從繪畫(huà)到生成視頻,簡(jiǎn)直無(wú)所不能。
比如讓一個(gè)新手生成一個(gè)偽造視頻需要大量的學(xué)習(xí)和操作時(shí)間,如果使用deepfake的話則不需要什么門(mén)檻,而且效率也高得多。
不過(guò)好消息是,AI目前并非全知全能,一個(gè)模型只能做軟件內(nèi)的一點(diǎn)點(diǎn)工作;如果要把多個(gè)模型組裝成一個(gè)Pipeline,那還得需要人來(lái)操作才行;對(duì)于更復(fù)雜的任務(wù),那還需要人類(lèi)的創(chuàng)造力。
魏茨曼科學(xué)研究學(xué)院和英偉達(dá)的研究人員就提出了一個(gè)模型Text2Live,用戶只需要輸入自然語(yǔ)言文本作為命令,就能對(duì)給定的圖片和視頻進(jìn)行處理。模型的目標(biāo)是編輯現(xiàn)有物體的外觀(如物體的紋理)或以語(yǔ)義的方式增加場(chǎng)景的視覺(jué)效果(如煙、火等)。

論文鏈接:https://arxiv.org/pdf/2204.02491.pdf
Text2Live能夠用復(fù)雜的半透明效果增強(qiáng)輸入場(chǎng)景,而不改變圖像中的無(wú)關(guān)內(nèi)容。
比如對(duì)模型念出咒語(yǔ)「煙」或者「火」,就可以給圖片合成上相應(yīng)的效果,十分真實(shí);

對(duì)著面包圖片說(shuō)「冰」,就可以變成一個(gè)冰面包,甚至「奧利奧蛋糕」也不在話下;

或是對(duì)著視頻說(shuō)「給長(zhǎng)頸鹿戴個(gè)圍脖」,它也能精確識(shí)別出來(lái)長(zhǎng)頸鹿的脖子,并在每一幀都給它戴上一個(gè)圍脖,還能換各種不同的效果。

用自然語(yǔ)言P圖
受視覺(jué)語(yǔ)言模型(Vision-Language models)強(qiáng)大的語(yǔ)義表達(dá)能力啟發(fā),研究人員想到,為什么我們不能用自然語(yǔ)言命令來(lái)P圖呢?這樣用戶就可以輕松而直觀地指定目標(biāo)外觀和要編輯的對(duì)象和區(qū)域,而開(kāi)發(fā)出的模型需要具備識(shí)別出給定文本提示的局部、語(yǔ)義編輯的能力。
多模態(tài)的話,在4億個(gè)文本-圖像對(duì)上學(xué)習(xí)過(guò)的CLIP模型就是現(xiàn)成的,并且其內(nèi)包含巨大的視覺(jué)和文本空間豐富性已經(jīng)被各種圖像編輯方法所證明了!

但還有一個(gè)困難,就是在所有真實(shí)世界的圖像中想用CLIP達(dá)到完美性能還是不容易的。
大多數(shù)現(xiàn)有方法都是將預(yù)訓(xùn)練好的生成器(例如GAN或Diffusion模型)與CLIP結(jié)合起來(lái)。但用GANs的話,圖像的域是受限制的,需要將輸入圖像反轉(zhuǎn)到GAN的潛空間,本身就是一個(gè)具有挑戰(zhàn)性的任務(wù)。而擴(kuò)散模型雖然克服了這些障礙,但在滿足目標(biāo)編輯和保持對(duì)原始內(nèi)容的高保真度之間面臨著權(quán)衡。但將這些方法擴(kuò)展到視頻中也并不簡(jiǎn)單。
Text2LIVE采取了一條不同的路線,提出從單一的輸入(圖像或視頻和文本提示)中學(xué)習(xí)一個(gè)生成器。

新問(wèn)題來(lái)了:如果不使用外部生成式的先驗(yàn),該如何引導(dǎo)生成器走向有意義的、高質(zhì)量的圖像編輯操作?
Text2LIVE主要設(shè)計(jì)了兩個(gè)關(guān)鍵部分來(lái)實(shí)現(xiàn)這一目標(biāo):
1. 模型中包含一種新穎的文字引導(dǎo)的分層編輯(layered editing),也就是說(shuō),模型不是直接生成編輯過(guò)的圖像,而是通過(guò)在輸入的圖層上合成RGBA層(顏色和不透明度)來(lái)表示編輯。
這也使得模型可以通過(guò)一個(gè)新的目標(biāo)函數(shù)來(lái)指導(dǎo)生成的編輯內(nèi)容和定位,包括直接應(yīng)用于編輯層的文本驅(qū)動(dòng)的損失。
比如前面的例子中使用文本提示「煙」,不僅輸出最終的編輯圖像,還表達(dá)了編輯層所代表的目標(biāo)效果。
2. 模型通過(guò)對(duì)輸入的圖像和文本進(jìn)行各種數(shù)據(jù)增強(qiáng),在一個(gè)由不同的圖像-文本訓(xùn)練實(shí)例組成的「內(nèi)部數(shù)據(jù)集」上訓(xùn)練生成器。實(shí)驗(yàn)結(jié)果也表明,這種「內(nèi)部學(xué)習(xí)方法」可以作為一個(gè)強(qiáng)大的regularization,能夠高質(zhì)量地生成復(fù)雜的紋理和半透明的效果。
文本增強(qiáng)主要使用預(yù)定義的14個(gè)模板提示符,能夠提供CLIP向量的多樣性。

圖像數(shù)據(jù)的Pipeline由一個(gè)在單一輸入圖像上訓(xùn)練的生成器和目標(biāo)文本提示組成。

左側(cè)就是生成內(nèi)部數(shù)據(jù)集的過(guò)程,即由不同訓(xùn)練實(shí)例組成的內(nèi)部(圖像,文本)對(duì)和數(shù)據(jù)增強(qiáng)后得到的數(shù)據(jù)集。
右測(cè)是生成器將圖像作為輸入,并輸出一個(gè)RGBA的可編輯層(顏色+透明度),在輸入的基礎(chǔ)上進(jìn)行合成,從而形成最終的編輯過(guò)的圖像。
生成器的的優(yōu)化函數(shù)為多個(gè)損失項(xiàng)之和,每個(gè)損失項(xiàng)都是在CLIP空間中定義,包括主要的目標(biāo)Composition loss,能夠反映圖像和目標(biāo)文本提示之間的匹配程度;Screen loss,應(yīng)用于生成的編輯層中,主要技術(shù)是在純綠色背景上合成一個(gè)噪音背景圖像,判斷摳圖準(zhǔn)確度;Structure loss,保證替換的紋理和顯示效果能夠保持原始目標(biāo)的空間分布和形狀。

除了圖像外,研究人員還將Text2LIVE擴(kuò)展到了文本指導(dǎo)的視頻編輯領(lǐng)域。
現(xiàn)實(shí)世界的視頻通常由復(fù)雜的物體和攝像機(jī)運(yùn)動(dòng)組成,包括了關(guān)于場(chǎng)景的豐富信息。然而,想實(shí)現(xiàn)一致的視頻編輯是很困難的,不能只是簡(jiǎn)單地對(duì)圖片的每一幀都使用相同操作。
因此,研究人員提出將視頻分解為一組二維圖集(atlases)。每個(gè)圖集可以被視為一個(gè)統(tǒng)一的二維圖像,代表了整個(gè)視頻中的一個(gè)前景物體或背景。這種表示方法大大簡(jiǎn)化了視頻編輯的任務(wù)。應(yīng)用于單個(gè)二維圖集的編輯會(huì)以一種一致的方式映射到整個(gè)視頻中。
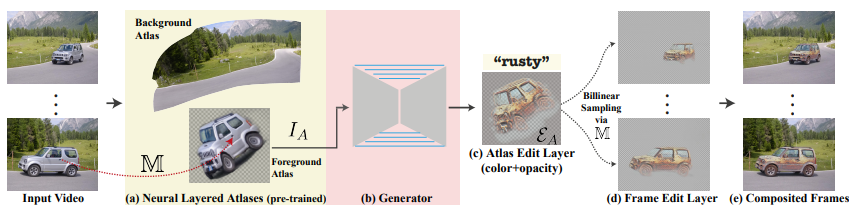
視頻的訓(xùn)練Pipeline包括(a)一個(gè)預(yù)訓(xùn)練的固定分層神經(jīng)圖集模型,可以用作「視頻渲染器」,包括了一組二維圖集、從像素到圖集的映射函數(shù),以及每個(gè)像素的前景/背景透明值;(b)框架訓(xùn)練一個(gè)生成器,將選定的離散圖集IA作為輸入,并輸出;(c)一個(gè)圖集編輯層EA;(d)使用預(yù)訓(xùn)練映射網(wǎng)絡(luò)M把編輯過(guò)的圖集渲染回每一幀;(e)在原始視頻上進(jìn)行合成。
在實(shí)驗(yàn)的量化評(píng)估中,研究人員選擇人類(lèi)感知評(píng)估的方式,參與者會(huì)看到一個(gè)參考圖像和一個(gè)目標(biāo)編輯提示,以及兩個(gè)備選方案。
參與者必須選擇「哪張圖片能更好地根據(jù)文本提示來(lái)編輯參考圖像」?
實(shí)驗(yàn)數(shù)據(jù)包括了82個(gè)(圖像,文本)對(duì),收集了12450個(gè)用戶對(duì)圖像編輯方法的判斷,投票結(jié)果可以看到Text2LIVE在很大程度上超過(guò)了所有的基線模型。

在視頻的實(shí)驗(yàn)中,參與者需要選擇「質(zhì)量更好、更能體現(xiàn)文本的視頻」,實(shí)驗(yàn)數(shù)據(jù)包含19個(gè)(視頻,文本)對(duì)和2400個(gè)用戶的判斷結(jié)果。結(jié)果可以看到,F(xiàn)rames基線模型產(chǎn)生了時(shí)間線不一致的結(jié)果,而Atlas基線的結(jié)果更一致,但在生成高質(zhì)量紋理方面表現(xiàn)不佳,經(jīng)常產(chǎn)生模糊的結(jié)果。
?
級(jí)摳圖 魏茨曼聯(lián)合英偉達(dá)發(fā)布Text2LIVE,用自然語(yǔ)言就能PS") ?
?