













圖文并茂!推薦算法架構——粗排
一、總體架構
粗排是介于召回和精排之間的一個模塊 。它從召回獲取上萬的候選item,輸出幾百上千的item給精排,是典型的精度與性能之間trade-off的產物。對于推薦池不大的場景,粗排是非必選的。粗排 整體架構 如下:
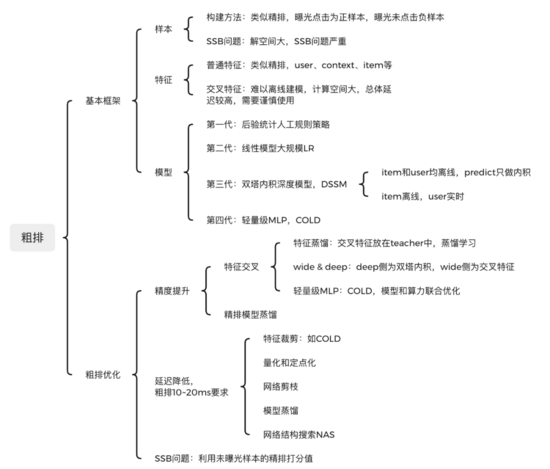
二、粗排基本框架:樣本、特征、模型
目前粗排一般模型化了,基本框架也是包括數據樣本、特征工程、深度模型三部分。
1.數據樣本
目前粗排一般也都模型化了,其訓練樣本類似于精排,選取曝光點擊為正樣本,曝光未點擊為負樣本。但由于粗排一般面向上萬的候選集,而精排只有幾百上千,其解空間大很多。只使用曝光樣本作為訓練,但卻要對曝光和非曝光同時預測,存在嚴重的樣本選擇偏差(SSB問題),導致訓練與預測不一致。相比精排,顯然粗排的SSB問題更嚴重。
2.特征工程
粗排的特征也可以類似于精排,由于其計算延遲要求高,只有10ms~20ms,故一般可以粗分為兩類:
- 普通特征:類似精排,user、context、item三部分。有哪些特征,以及特征如何處理,可以參看精排的特征工程部分。
- 交叉特征:user和item之間的交叉特征,對提升模型精度很有幫助。但由于交叉特征枚舉過多,難以離線計算和存儲。實時打分時又不像user特征只用計算一次,延遲較高。故對于交叉特征要謹慎使用。
3.深度模型
粗排目前已經基本模型化,其發展歷程主要分為四個階段:
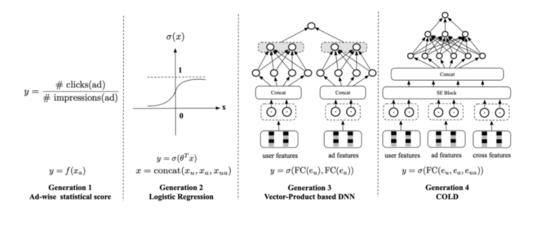
第一代 :人工規則策略,可以基于后驗統計,構建一個人工規則。比如融合item的歷史CTR、CVR、類目價格檔、銷量等比較核心的因子。人工規則準確率低,也沒有個性化,也不可能實時更新。
第二代 :LR線性模型,有一定的個性化和實時性能力,但模型過于簡單,表達能力偏弱。
第三代 :DSSM雙塔內積深度模型。它將user和item進行解耦合,分別通過兩個Tower獨立構建。從而可以實現item向量離線存儲,降低線上predict延遲。主要有兩種范式:
- item和user均離線存儲。 這個方案只需要計算user和item的內積即可,計算延遲低。 由于user是離線存儲的,故可以使用復雜的模型,提升表達能力。 但user側的實時性較差,對于用戶行為不能實時捕捉。
- item離線,user實時。 item相對user,實時性要求沒那么高。 由于一次打分是針對同一個用戶的,故user側只需要實時計算一次即可,速度也很快。 目前這個方案使用較多。
第四代 :item和user隔離,導致二者沒有特征交叉能力,模型表達能力弱。故又提出了以COLD為代表的第四代模型,輕量級MLP粗排模型。它通過SE block實現特征裁剪,并配合網絡剪枝和工程優化,可以實現精度和性能之間的trade-off。
三、粗排優化
粗排的幾個主要問題:
- 精度和特征交叉問題:經典的DSSM模型優點很多,目前在粗排上廣泛應用,其最核心的缺點就是缺乏特征交叉能力。正所謂成也蕭何敗蕭何,正是由于user和item分離,使得DSSM性能很高。但反過來也是由于二者缺乏交叉,導致模型表達能力不足,精度下降。典型的精度和性能之間的trade-off。
- 低延遲要求:粗排延遲要求高,一般只有10ms~20ms,遠低于精排的要求。
- SSB 問題: 粗排解空間比精排大很多,和精排一樣只使用曝光樣本,導致嚴重的樣本選擇偏差問題。
1.精度提升
精度提升的方案主要有精排蒸餾和特征交叉,主要還是要優化特征交叉問題。
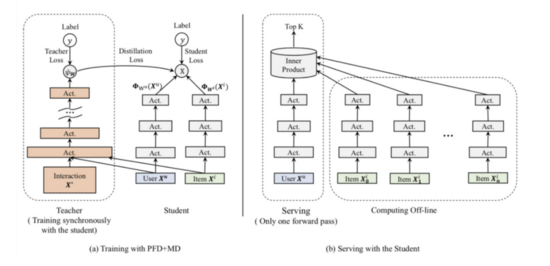
- 精排蒸餾
精排模型作為teacher,對粗排模型進行蒸餾學習,從而提升粗排效果,這已經成為了目前粗排訓練基本范式
- 特征交叉
特征交叉可以在特征層面,也可以在模型層面實現。特征層面就是手工構造交叉特征,作為模型底層輸入,仍然可以在獨立的Tower中。模型層面則使用FM或者MLP等實現自動交叉。主要方法有:
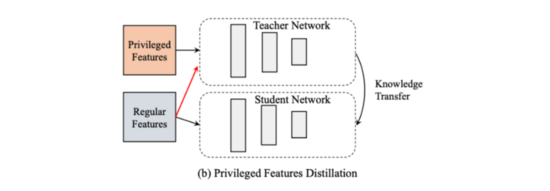
特征蒸餾 :teacher和student使用相同的網絡結構,teacher模型使用普通特征和交叉特征,student則只使用普通特征。student從teacher中可以學到交叉特征的高階信息。
加入交叉特征 :特征層面構建手工交叉特征,獨立的Tower中使用。由于交叉特征難以離線存儲,實時計算空間也很大,故這個獨立的Tower不能過于復雜。那我們第一時間就想到了wide&deep模型。deep部分仍然使用DSSM雙塔,wide部分則為交叉特征。
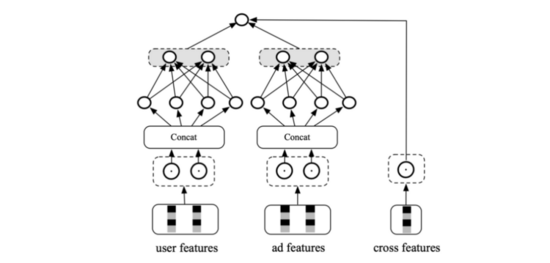
輕量級MLP :模型層面實現特征交叉,不進行獨立分塔。比如COLD,通過特征裁剪、網絡剪枝、工程優化等方式降低時延,而不是靠獨立分塔。
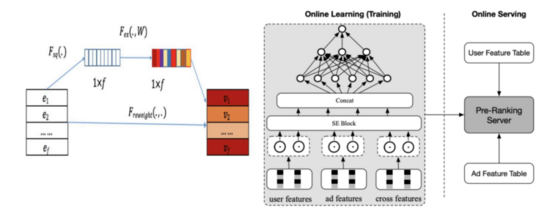
2.延遲降低
精度和性能一直以來都是一個trade-off,很多方案都是在二者之間尋找平衡。粗排的性能要求更高,其延遲必須控制在10ms~20ms以內。性能優化 有很多常見方法 。
主要有以下方法:
- 特征裁剪:如COLD,不重要的特征先濾掉,自然就降低了整體延遲。這一層可以做在模型內,從而可以個性化和實時更新。
- 量化和定點化:比如32bit降低為8bit,可以提升計算和存儲性能。
- 網絡剪枝:network pruning,包括突觸剪枝、神經元剪枝、權重矩陣剪枝等方法,不展開了。
- 模型蒸餾:model distillation,上文已經提到了,不展開了。
網絡結構搜索NAS:使用更輕量級,效果更好的模型。可以嘗試網絡結構搜索NAS。
3.SSB問題
粗排解空間比精排大很多,和精排一樣只使用曝光樣本,導致嚴重的樣本選擇偏差問題。可以把未曝光樣本的精排打分給利用起來,緩解SSB問題。
作者簡介

謝楊易
騰訊應用算法研究員
騰訊應用算法研究員,畢業于中國科學院,目前在騰訊負責視頻推薦算法工作,有豐富的自然語言處理和搜索推薦算法經驗。














