Apache Flink 在蔚來汽車的應(yīng)用
本文整理自蔚來汽車大數(shù)據(jù)專家,架構(gòu)師吳江在 Flink Forward Asia 2021 行業(yè)實(shí)踐專場(chǎng)的演講。主要內(nèi)容包括:
- 實(shí)時(shí)計(jì)算在蔚來的發(fā)展歷程
- 實(shí)時(shí)計(jì)算平臺(tái)
- 實(shí)時(shí)看板
- CDP
- 實(shí)時(shí)數(shù)倉(cāng)
- 其他應(yīng)用場(chǎng)景
一、 實(shí)時(shí)計(jì)算在蔚來的發(fā)展歷程
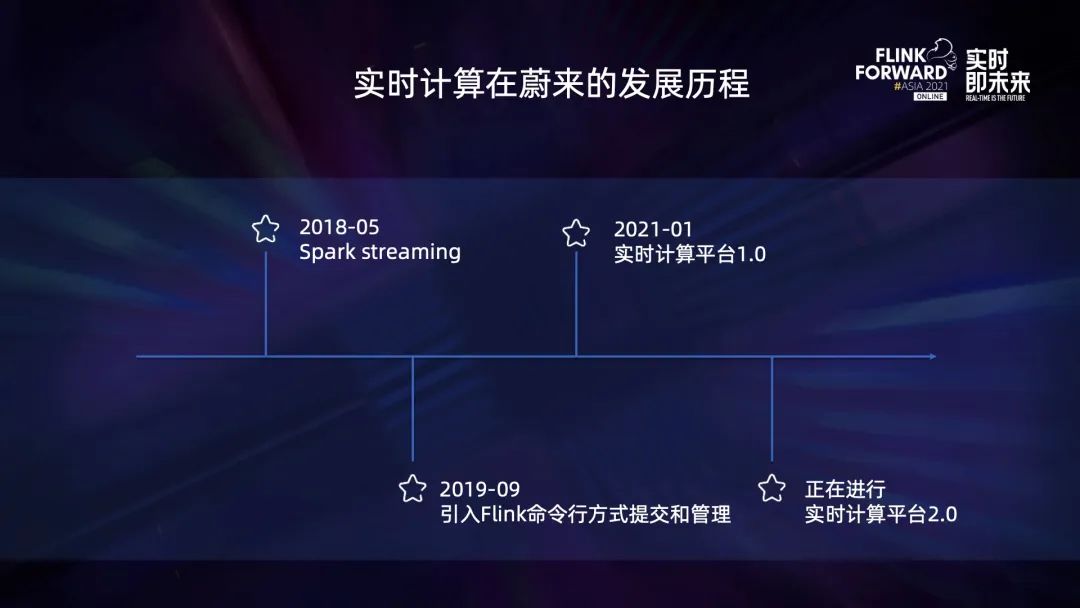
18 年 5 月份左右,我們開始接觸實(shí)時(shí)計(jì)算的概念,最初是用 Spark Streaming 做一些簡(jiǎn)單的流式計(jì)算數(shù)據(jù)的處理;
19 年 9 月份我們引入了 Flink,通過命令行的方式進(jìn)行提交,包括管理整個(gè)作業(yè)的生命周期;
到了 21 年 1 月份,我們上線了實(shí)時(shí)計(jì)算平臺(tái) 1.0,目前正在進(jìn)行 2.0 版本的開發(fā)。
二、實(shí)時(shí)計(jì)算平臺(tái)
在實(shí)時(shí)計(jì)算平臺(tái) 1.0,我們是通過將代碼進(jìn)行編譯,然后上傳 jar 包到一個(gè)服務(wù)器上,以命令行的方式進(jìn)行提交。這個(gè)過程中存在很多問題:
- 首先,所有流程都是手動(dòng)的,非常繁瑣而且容易出錯(cuò);
- 其次,缺乏監(jiān)控,F(xiàn)link 本身內(nèi)置了很多監(jiān)控,但是沒有一個(gè)自動(dòng)的方式將它們加上去,還是需要手動(dòng)地去做配置;
- 此外,任務(wù)的維護(hù)也非常麻煩,一些不太熟悉的開發(fā)人員進(jìn)行操作很容易出現(xiàn)問題,而且出現(xiàn)問題之后也難以排查。

實(shí)時(shí)計(jì)算平臺(tái) 1.0 的生命周期如上圖。任務(wù)寫完之后打成 jar 包進(jìn)行上傳提交,后續(xù)的開啟任務(wù)、停止、恢復(fù)和監(jiān)控都能夠自動(dòng)進(jìn)行。
作業(yè)管理主要負(fù)責(zé)作業(yè)的創(chuàng)建、運(yùn)行、停止、恢復(fù)和更新。日志主要記錄 Flink 任務(wù)提交時(shí)的一些日志,如果是運(yùn)行時(shí)的日志還是要通過 Yarn 集群里的 log 來查看,稍微有點(diǎn)麻煩。關(guān)于監(jiān)控和告警模塊,首先 metrics 監(jiān)控主要是利用 Flink 內(nèi)置的指標(biāo)上傳到 Prometheus,然后配置各種監(jiān)控的界面,告警也是利用 Prometheus 的一些指標(biāo)進(jìn)行規(guī)則的設(shè)置,然后進(jìn)行告警的設(shè)置。Yarn 負(fù)責(zé)整體集群資源的管理。
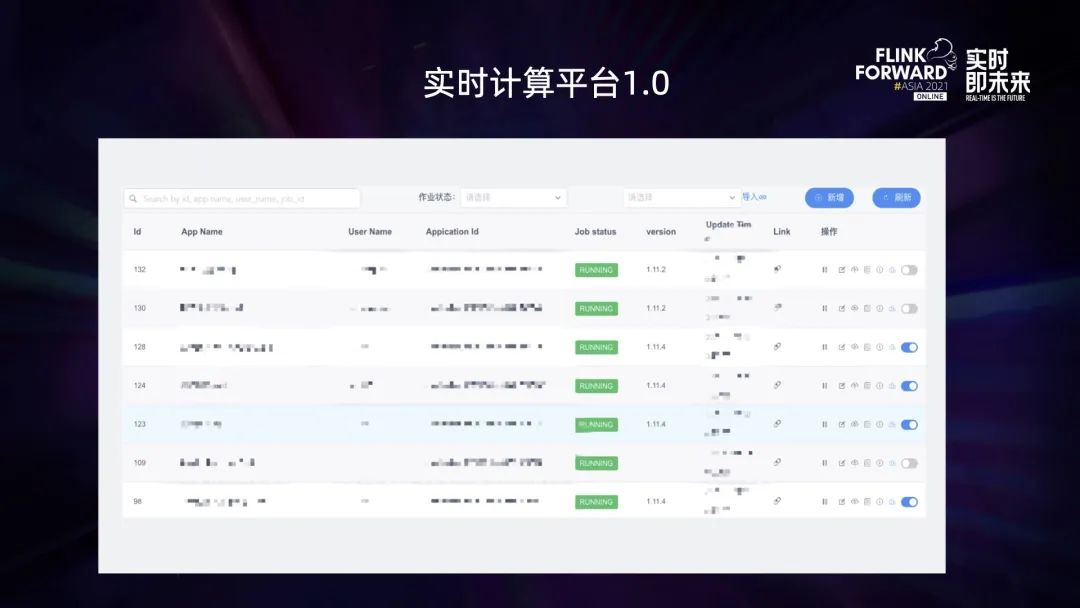
上圖是實(shí)時(shí)計(jì)算平臺(tái) 1.0 的界面,整體功能比較簡(jiǎn)單。
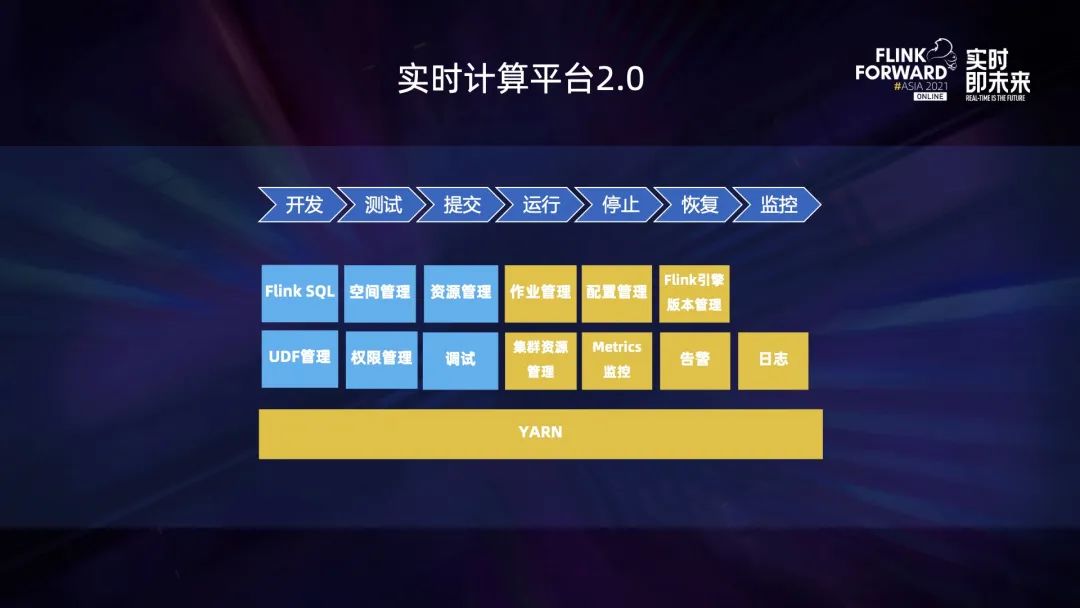
上圖是實(shí)時(shí)計(jì)算平臺(tái) 2.0。相對(duì)于 1.0,最大的區(qū)別是藍(lán)色的部分。對(duì)于實(shí)時(shí)計(jì)算平臺(tái)的形態(tài),可能并沒有一個(gè)統(tǒng)一的標(biāo)準(zhǔn),它與每個(gè)公司本身的情況息息相關(guān),比如公司本身的體量和規(guī)模、公司對(duì)實(shí)時(shí)計(jì)算平臺(tái)的資源投入等,最終還是應(yīng)該以適用于公司本身的現(xiàn)狀為最佳標(biāo)準(zhǔn)。
2.0 版本我們?cè)黾訌拈_發(fā)到測(cè)試兩個(gè)階段功能的支持。簡(jiǎn)單介紹一下它們的具體功能:
FlinkSQL:它是很多公司的實(shí)時(shí)計(jì)算平臺(tái)都支持的功能,它的優(yōu)點(diǎn)在于可以降低使用成本,也比較簡(jiǎn)單易用。
空間管理:不同的部門和不同的組可以在自己的空間里進(jìn)行作業(yè)的創(chuàng)建、管理。有了空間的概念之后,我們可以利用它做一些權(quán)限的控制,比如只能在自己有權(quán)限的空間里進(jìn)行一些操作。
UDF 管理:使用了 FlinkSQL 的前提下,就可以基于 SQL 的語義用 UDF 的方式擴(kuò)充功能。此外,UDF 還能用于 Java 和 Schema 任務(wù),可以把一些公用的功能包裝成 UDF,降低開發(fā)成本。它還有一個(gè)很重要的功能就是調(diào)試,可以簡(jiǎn)化原有的調(diào)試流程,做到用戶無感知。
實(shí)時(shí)計(jì)算平臺(tái) 2.0 的實(shí)現(xiàn),帶給我們最大的影響就是減輕了數(shù)據(jù)團(tuán)隊(duì)的負(fù)擔(dān)。在我們?cè)鹊拈_發(fā)流程里,經(jīng)常需要數(shù)據(jù)團(tuán)隊(duì)的介入,但實(shí)際上其中的很大一部分工作都是比較簡(jiǎn)單的,比如數(shù)據(jù)同步或數(shù)據(jù)的簡(jiǎn)單處理,這類工作并不一定需要數(shù)據(jù)團(tuán)隊(duì)去介入。
我們只需要把實(shí)時(shí)計(jì)算平臺(tái)做得更完善、易用和簡(jiǎn)單,其他的團(tuán)隊(duì)就可以使用 FlinkSQL 去做上述簡(jiǎn)單的工作,理想的情況下他們甚至不需要知道 Flink 的相關(guān)概念就可以做一些 Flink 的開發(fā)。比如后臺(tái)人員做業(yè)務(wù)側(cè)開發(fā)的時(shí)候,對(duì)于一些比較簡(jiǎn)單的場(chǎng)景就不需要依賴數(shù)據(jù)團(tuán)隊(duì),大大降低溝通成本,進(jìn)度會(huì)更快。這樣在部門內(nèi)有一個(gè)閉環(huán)會(huì)更好一點(diǎn)。而且以這樣的方式,各個(gè)角色其實(shí)都會(huì)覺得比較開心。產(chǎn)品經(jīng)理的工作也會(huì)變得更輕松,在需求的階段不需要引入太多的團(tuán)隊(duì),工作量也會(huì)變少。
所以,這是一個(gè)以技術(shù)的方式來優(yōu)化組織流程的很好的例子。
三、實(shí)時(shí)看板

實(shí)時(shí)看板是一個(gè)比較常見的功能,在我們的具體實(shí)現(xiàn)中,主要發(fā)現(xiàn)了以下幾個(gè)難點(diǎn):
第一,數(shù)據(jù)延遲上報(bào)。比如業(yè)務(wù)數(shù)據(jù)庫(kù)發(fā)生問題后,進(jìn)行 CDC 接入的時(shí)候就需要中斷,包括后續(xù)寫到 Kafka,如果 Kafka 集群負(fù)載很高或 Kafka 發(fā)生問題,也會(huì)中斷一段時(shí)間,這些都會(huì)造成數(shù)據(jù)的延遲。上述延遲在理論上可以避免,但實(shí)際上很難完全避免。此外還有一些理論上就不能完全避免的延遲,比如用戶的流量或信號(hào)有問題導(dǎo)致操作日志無法實(shí)時(shí)上傳。
第二,流批一體。主要在于歷史數(shù)據(jù)和實(shí)時(shí)數(shù)據(jù)能否統(tǒng)一。
第三,維度的實(shí)時(shí)選擇。實(shí)時(shí)看板可能需要靈活選擇多個(gè)維度值,比如想先看北京的活躍用戶數(shù),再看上海的活躍用戶數(shù),最后看北京 + 上海的活躍用戶數(shù),這個(gè)維度是根據(jù)需要可以靈活選擇的。
第四,指標(biāo)的驗(yàn)證。指標(biāo)的驗(yàn)證在離線的情況下,相對(duì)來說比較簡(jiǎn)單一些,比如說可以做一些數(shù)據(jù)分布,看看每個(gè)分布的大概情況,也可以通過 ODS 層數(shù)據(jù)的計(jì)算與中間表進(jìn)行比對(duì),做交叉驗(yàn)證。但是在實(shí)時(shí)的情況下就比較麻煩,因?yàn)閷?shí)時(shí)處理是一直在進(jìn)行的,有些情況很難去復(fù)現(xiàn),此外也很難進(jìn)行指標(biāo)范圍或分布的驗(yàn)證。
實(shí)時(shí)看板一般存在兩個(gè)方面的需求:
- 首先是時(shí)延方面,不同的場(chǎng)景對(duì)時(shí)延的要求是不同的,比如有些場(chǎng)景下能夠接受數(shù)據(jù)延遲 1-2 分鐘到達(dá),但有的場(chǎng)景下只允許延遲幾秒鐘。不同場(chǎng)景下實(shí)踐的技術(shù)方案復(fù)雜度不一樣。
- 其次,需要兼顧實(shí)時(shí)與歷史看板的功能。有些場(chǎng)景下,除了需要看實(shí)時(shí)的數(shù)據(jù)變化,還需要對(duì)比著歷史數(shù)據(jù)來一起分析。
實(shí)時(shí)與歷史數(shù)據(jù)應(yīng)該進(jìn)行統(tǒng)一的存儲(chǔ),否則可能會(huì)存在很多問題。首先,實(shí)現(xiàn)的時(shí)候表結(jié)構(gòu)比較復(fù)雜,查詢的時(shí)候可能需要判斷哪段時(shí)間是歷史數(shù)據(jù),哪段時(shí)間是實(shí)時(shí)數(shù)據(jù),然后對(duì)它們進(jìn)行拼接,會(huì)導(dǎo)致查詢的實(shí)現(xiàn)成本過高。其次,在歷史數(shù)據(jù)進(jìn)行切換的時(shí)候也很容易出現(xiàn)問題,比如每天凌晨定時(shí)刷新歷史數(shù)據(jù),此時(shí)如果歷史任務(wù)發(fā)生延遲或錯(cuò)誤,很容易導(dǎo)致查出來的數(shù)據(jù)是錯(cuò)誤的。
我們內(nèi)部對(duì)實(shí)時(shí)看板的延時(shí)性要求比較高,一般要求在秒級(jí)以內(nèi),因?yàn)槲覀兿M笃聊簧系臄?shù)字是時(shí)刻在跳動(dòng)和變化的。傳統(tǒng)的方案一般是采用拉的方式,比如說每秒查一次數(shù)據(jù)庫(kù),實(shí)現(xiàn)的難度比較大,因?yàn)橐粋€(gè)頁面會(huì)包含很多指標(biāo),需要同時(shí)發(fā)送很多接口去查詢數(shù)據(jù),想讓所有數(shù)據(jù)都在一秒鐘之內(nèi)返回是不太可能的。另外,如果很多用戶同時(shí)進(jìn)行查詢,會(huì)導(dǎo)致負(fù)載很高,時(shí)效性更難以保證。
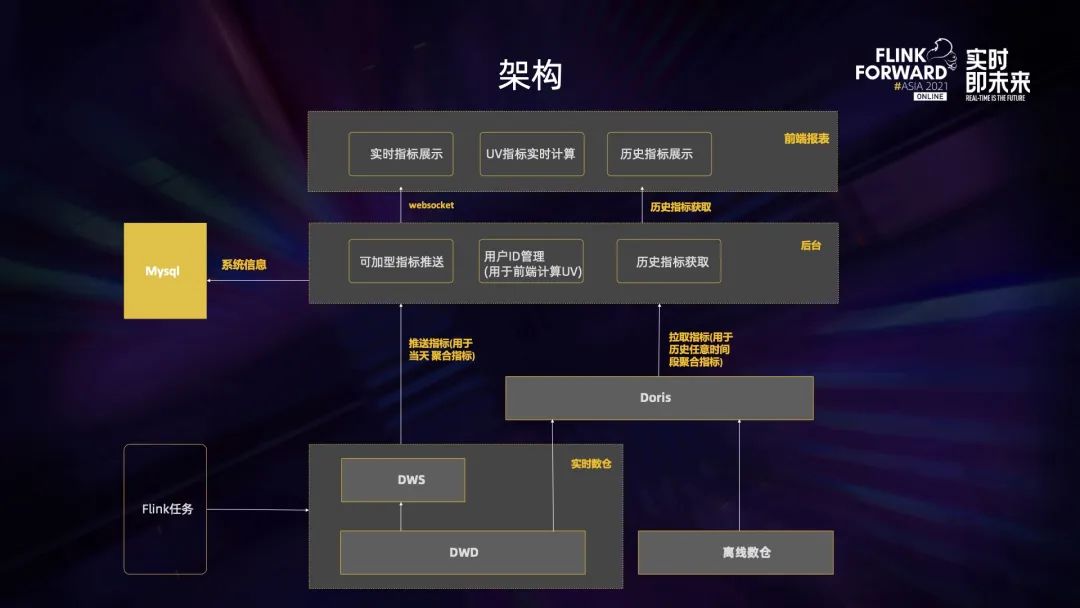
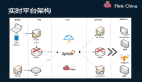
所以我們采取了推的方式,上圖是具體實(shí)現(xiàn)的架構(gòu)圖,主要分為三層。第一層是數(shù)據(jù)層即 Kafka 的實(shí)時(shí)數(shù)倉(cāng),通過 Flink 對(duì)這些數(shù)據(jù)進(jìn)行處理后將它們實(shí)時(shí)地推到后臺(tái),后臺(tái)再實(shí)時(shí)地把它們推到前端。后臺(tái)與前端的交互是通過 web socket 來實(shí)現(xiàn)的,這樣就可以做到所有的數(shù)據(jù)都是實(shí)時(shí)推送。
在這個(gè)需求場(chǎng)景下,有一些功能會(huì)比較復(fù)雜。

舉個(gè)簡(jiǎn)單例子,比如統(tǒng)計(jì)實(shí)時(shí)去重人數(shù) UV,其中一個(gè)維度是城市,一個(gè)用戶可能對(duì)應(yīng)多個(gè)城市,選擇上海和北京兩個(gè)城市的 UV 數(shù),就意味著要把上海和北京的人放到一起進(jìn)行去重,算出來去重的實(shí)時(shí) UV 數(shù)據(jù),這是一件比較麻煩的事情。從離線的角度來看,選多個(gè)維度是非常簡(jiǎn)單的,把維度選好之后直接取出數(shù)據(jù)進(jìn)行聚合即可。但是在實(shí)時(shí)場(chǎng)景下,要在哪些維度進(jìn)行聚合是提前指定好的。

第一個(gè)方案是,在 Flink 狀態(tài)中存儲(chǔ)所有 user ID 和出現(xiàn)過的維度,并直接計(jì)算所有可能的維度組合 UV,然后將更新過的 UV 推送給前端。
但這種方式會(huì)增加很多計(jì)算成本,而且會(huì)導(dǎo)致維度爆炸,從而導(dǎo)致存儲(chǔ)成本也急劇增加。
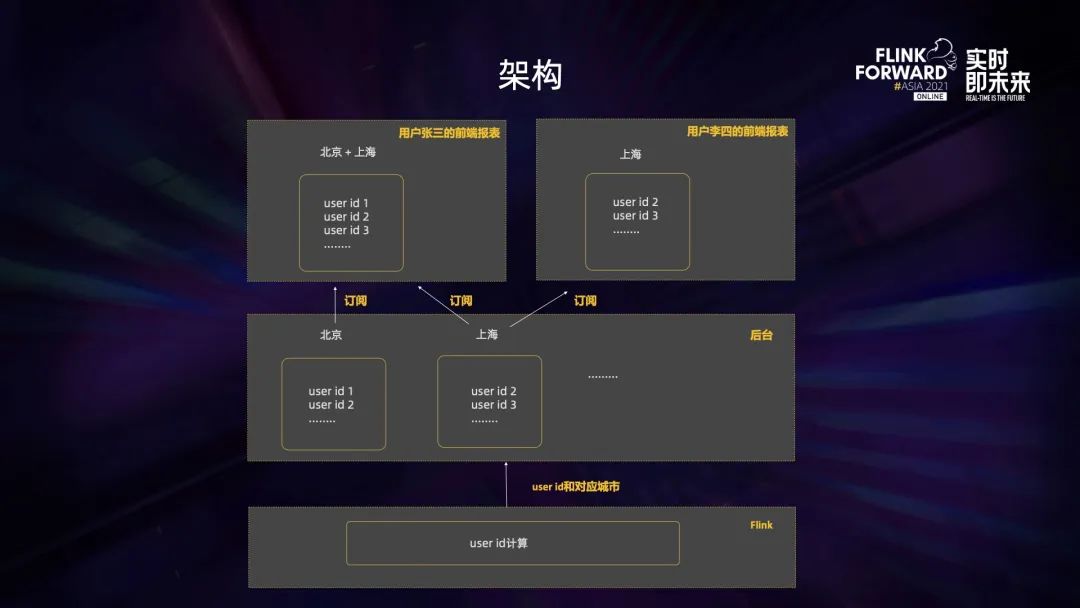
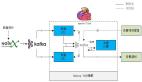
第二種方案的架構(gòu)圖如上。我們把 sink 作為一個(gè)流式的核心,把端到端整體作為一個(gè)流式應(yīng)用,比如把數(shù)據(jù)的接入、在 Flink 中數(shù)據(jù)的處理計(jì)算、再到后臺(tái)、通過 web socket 推給前端這一整體作為一個(gè)應(yīng)用來考慮。
我們會(huì)在 Flink 里面存儲(chǔ)每個(gè)用戶所有的維度值,后臺(tái)的 Flink 推送的用戶具體情況也會(huì)存在每個(gè)城市下 user ID 的 list 里。Flink 擁有一個(gè)很關(guān)鍵的排除功能,如果用戶已經(jīng)出現(xiàn)過,那么在 Flink 階段就不會(huì)把變更推送到前端和后臺(tái);如果用戶沒出現(xiàn)過,或者用戶出現(xiàn)過但城市沒出現(xiàn)過,那就會(huì)把用戶與城市的組合推送給后臺(tái),保證后臺(tái)可以拿到每個(gè)城市下用戶 ID 去重的 list。
前端選擇維度之后,可以對(duì)后臺(tái)不同維度的 user ID 進(jìn)行增量的訂閱。這里有兩個(gè)點(diǎn)需要注意:
第一是在前端剛打開在選擇緯度的時(shí)候,有一個(gè)初始化的過程,它會(huì)從后臺(tái)讀取所選維度的全量用戶 ID 來做一個(gè)合集,然后計(jì)算 UV 人數(shù)。
在第二個(gè)階段新的用戶 ID 到達(dá)之后,會(huì)通過 Flink 推送給后臺(tái),而后臺(tái)只會(huì)推送增量 ID 給前端,然后前端因?yàn)橐呀?jīng)保存了之前的合集,對(duì)于增量的 ID,它就可以直接用 O(1) 的時(shí)間去算出新的合集,并且計(jì)算出它的 UV 人數(shù)。

可能有人會(huì)問,在這個(gè)方案下,用戶太多怎么辦?前端會(huì)不會(huì)占用太多的資源?
首先,從目前我們的實(shí)際使用場(chǎng)景來看,這個(gè)方案是夠用的,如果以后 ID 數(shù)激增,用 bitmap 也是一種選擇,但只用 bitmap 也不足以解決問題。因?yàn)椴煌居脩?ID 的生成規(guī)則不一樣,有些是自增 ID,有些是非自增 ID 或者甚至都不是一個(gè)數(shù)值,那就需要做映射,如果是一個(gè)離散的數(shù)值也需要額外做一些處理。
第一種方案把 ID 從 1 開始重新編碼,使它變得比較小且連續(xù)。目前大部分場(chǎng)景下大家可能都是用 RoaringBitMap,它的特點(diǎn)是如果 ID 非常稀疏,它在實(shí)際存儲(chǔ)的時(shí)候會(huì)使用一個(gè) list 來存,而不是用 bitmap 來存,也就無法達(dá)到減少占用內(nèi)存的目的。所以要盡量讓 ID 的空間變小,讓 ID 的值比較連續(xù)。
但這樣還不夠,如果 ID 是之前沒出現(xiàn)過的,就需要給它重新分配一個(gè) ID,但是處理這些數(shù)據(jù)的時(shí)候,F(xiàn)link task 的并行度可能大于 1,這個(gè)時(shí)候多個(gè)節(jié)點(diǎn)同時(shí)消費(fèi)數(shù)據(jù)的話,它們可能都會(huì)遇到同樣的新 ID,如何給這個(gè) ID 分配對(duì)應(yīng)的新的映射的小 ID?
舉個(gè)例子,一個(gè)節(jié)點(diǎn)查詢之后需要生成一個(gè)新 ID,同時(shí)又要保證其他節(jié)點(diǎn)不會(huì)再生成相同的 ID,可以通過在新 ID 上做唯一索引來保證,把索引創(chuàng)建成功就生成了新 ID,失敗的節(jié)點(diǎn)可以進(jìn)行重試操作,去取現(xiàn)在的 ID mapping,因?yàn)閯偛乓呀?jīng)有其他節(jié)點(diǎn)生成這個(gè) ID 了,所以它在重試取 mapping 階段一定會(huì)成功。
除此之外,還需要考慮一種場(chǎng)景,比如用戶注冊(cè)完成后,馬上產(chǎn)生一些行為,而用戶注冊(cè)與一些業(yè)務(wù)模塊的行為表可能是由不同業(yè)務(wù)部門開發(fā),也可能會(huì)存在不同的數(shù)據(jù)庫(kù)、不同的表里面,甚至是不同類型的數(shù)據(jù)庫(kù),上述情況的接入方式也會(huì)不一樣,可能會(huì)導(dǎo)致雖然是先注冊(cè),但是注冊(cè)數(shù)據(jù)流可能會(huì)稍微晚于行為數(shù)據(jù)流到達(dá),這會(huì)不會(huì)導(dǎo)致出現(xiàn)什么問題?
目前看來是不會(huì)的,只需要行為數(shù)據(jù)流與新用戶注冊(cè)數(shù)據(jù)流共享一個(gè) ID mapping 即可。
綜上,一個(gè)好的架構(gòu),即使面對(duì)數(shù)據(jù)量激增的情況,也是不需要在架構(gòu)層面進(jìn)行大改的,只需要在細(xì)節(jié)上進(jìn)行重新設(shè)計(jì)。
第二個(gè)問題是前端會(huì)不會(huì)有很大的計(jì)算負(fù)載?
答案是:不會(huì)。雖然人數(shù)的去重是由前端來做,但只有前端第一次加載的時(shí)候才需要將用戶全量拉取,之后的增量 user ID 都會(huì)直接用 O(1) 的方式加入到目前的集合里,所以前端的計(jì)算負(fù)擔(dān)是很低的,整個(gè)過程完全是流式的。
第三個(gè)問題是實(shí)時(shí)報(bào)表同時(shí)訪問的用戶數(shù)很多怎么辦?
從目前的架構(gòu)上來看,對(duì) Flink 和后臺(tái)側(cè)基本沒有影響,唯一的影響就是如果有很多用戶同時(shí)訪問,他們的頁面需要同時(shí)與后臺(tái)建立 web socket 連接。但是因?yàn)閷?shí)時(shí)報(bào)表主要還是內(nèi)部使用,不會(huì)對(duì)外,所以同時(shí)的訪問量不會(huì)太多。
而且我們把數(shù)據(jù) ID 去重的一部分職責(zé)放在前端,即使有多個(gè)用戶同時(shí)訪問,計(jì)算職責(zé)也會(huì)分?jǐn)偟讲煌挠脩魹g覽器里面去,實(shí)際上也不會(huì)有過多負(fù)載。
四、CDP
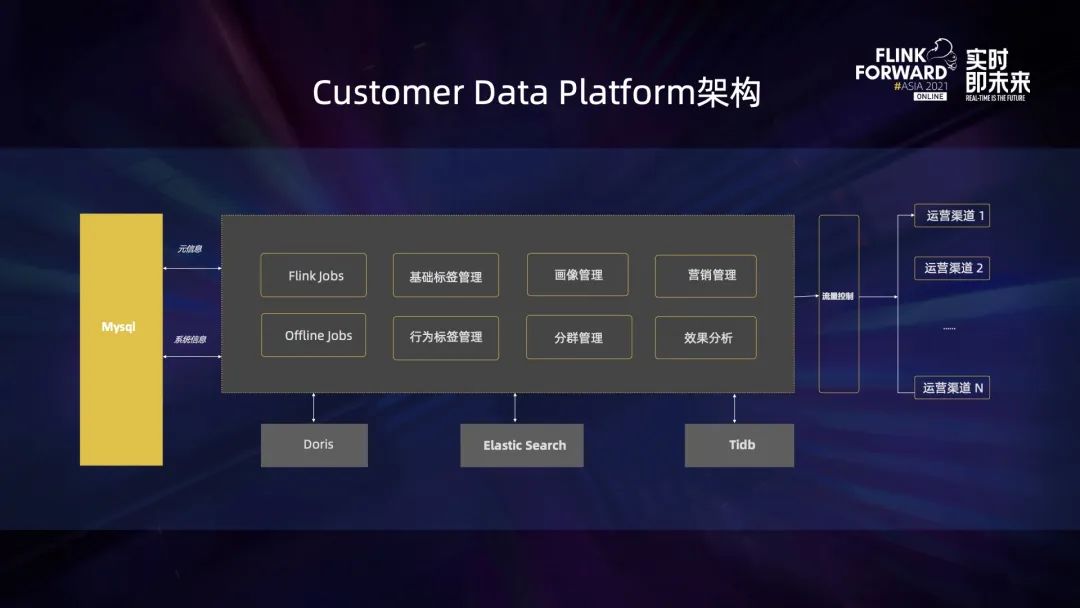
CDP 是一個(gè)運(yùn)營(yíng)平臺(tái),負(fù)責(zé)偏后臺(tái)的工作。我們的 CDP 需要存儲(chǔ)一些數(shù)據(jù),比如屬性的數(shù)據(jù)存在 ES 里、行為的明細(xì)數(shù)據(jù)包括統(tǒng)計(jì)數(shù)據(jù)存在 Doris 里、任務(wù)執(zhí)行情況存在 TiDB。也存在一些實(shí)時(shí)場(chǎng)景的應(yīng)用。
第一個(gè)是屬性需要實(shí)時(shí)更新,否則可能造成運(yùn)營(yíng)效果不佳。第二個(gè)是行為的聚合數(shù)據(jù)有時(shí)候也需要實(shí)時(shí)更新。
五、實(shí)時(shí)數(shù)倉(cāng)
實(shí)時(shí)數(shù)倉(cāng)重點(diǎn)考量點(diǎn)有以下幾個(gè):

- 元信息管理,包括 Catalog 的管理。
- 分層,如何進(jìn)行合理的分層。
- 建模,實(shí)時(shí)數(shù)倉(cāng)應(yīng)該如何建模,它與離線數(shù)倉(cāng)的建模方式有什么區(qū)別?
- 時(shí)效性,時(shí)延越低越好,鏈路越短越好。
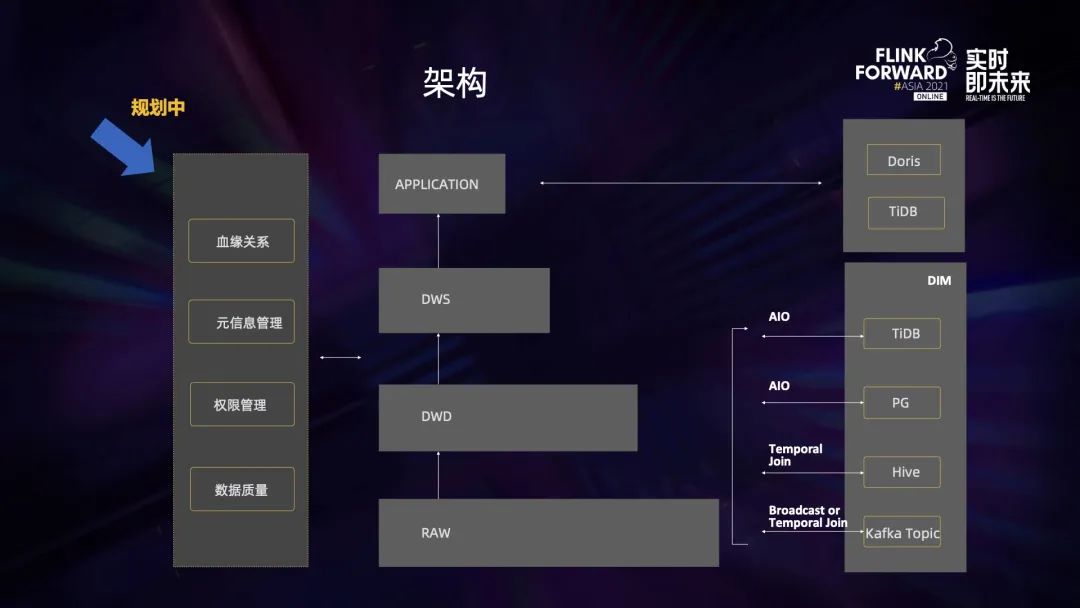
上圖是我們目前的實(shí)時(shí)數(shù)倉(cāng)架構(gòu)圖。它整體上與離線數(shù)倉(cāng)非常相似,也是有一個(gè)原始層、DWD 層、DWS 層和 Application 層。
不同之處在于它有一個(gè)維度層 (DIM 層),里面有很多不同的存儲(chǔ)介質(zhì),維度信息可以放在 TiDB,并通過 AIO 的方式訪問維度表;也可以放在 Hive,用 Temporal Join 的方式去進(jìn)行關(guān)聯(lián);有一些數(shù)據(jù)是一直在變化的,或者需要做一些基于時(shí)間的關(guān)聯(lián),可以把數(shù)據(jù)放到 Kafka 里,然后用 Broadcast 或者 Temporal Join 去進(jìn)行關(guān)聯(lián)。
左側(cè)是我們正在規(guī)劃中的能力。
第一個(gè)是血緣關(guān)系,它對(duì)于問題的溯源,以及對(duì)改動(dòng)的影響的評(píng)估是有幫助的;
第二個(gè)是元信息管理,我們希望把所有數(shù)據(jù)都表化,在進(jìn)行數(shù)據(jù)處理的時(shí)候可以直接用 SQL 搞定;
第三個(gè)是權(quán)限管理,對(duì)于不同的數(shù)據(jù)源、不同的表,都是需要做權(quán)限管理的;
第四個(gè)是數(shù)據(jù)質(zhì)量,如何進(jìn)行數(shù)據(jù)質(zhì)量的保證。
下面是對(duì)這些未來規(guī)劃的具體闡述。

第一,Catalog 管理,這個(gè)功能目前暫未開發(fā)。我們希望為所有數(shù)據(jù)源創(chuàng)建一個(gè)表,不管里面的數(shù)據(jù)是維表還是其他表,是存在 MySQL 還是存在 Kafka,創(chuàng)建表之后都可以將這些細(xì)節(jié)屏蔽,通過 SQL 的方式就能輕松使用它。

第二,合理的分層。分層會(huì)對(duì)實(shí)時(shí)數(shù)倉(cāng)造成多方面的影響。
首先,分層越多,時(shí)延越大。實(shí)時(shí)數(shù)倉(cāng)是否需要這么多分層,值得深思。
其次,實(shí)時(shí)數(shù)據(jù)的質(zhì)量監(jiān)控會(huì)比離線數(shù)據(jù)更復(fù)雜,因?yàn)樗窃诓煌5剡M(jìn)行處理,分層越多,越難以發(fā)現(xiàn)問題、定位問題并進(jìn)行回溯或復(fù)現(xiàn),包括數(shù)據(jù)集成的分布也不易監(jiān)控。
最后,如何進(jìn)行合理的分層。肯定需要盡可能減少層數(shù),并且進(jìn)行合理的業(yè)務(wù)功能垂直劃分,如果不同業(yè)務(wù)之間的交集很少,就盡量在各自業(yè)務(wù)領(lǐng)域內(nèi)建立自己?jiǎn)为?dú)的分層。

第三,建模。這是離線數(shù)倉(cāng)非常重要的部分,因?yàn)殡x線數(shù)倉(cāng)非常大的一部分用戶是分析師,他們?nèi)粘9ぷ骶褪怯?SQL 進(jìn)行數(shù)據(jù)的查詢和分析,這個(gè)時(shí)候就必須要考慮到易用性,比如大家都喜歡大寬表,所有相關(guān)字段都放到一個(gè)表里。所以在離線數(shù)倉(cāng)建模和設(shè)計(jì)表結(jié)構(gòu)的時(shí)候,就需要盡量把一些可能用到的維度都加上。
而實(shí)時(shí)數(shù)倉(cāng)面對(duì)的更多的是開發(fā)者,所以更強(qiáng)調(diào)實(shí)用性。因?yàn)樵趯?shí)時(shí)數(shù)倉(cāng)的需求下,寬表里每增加一個(gè)字段都會(huì)增加時(shí)延,特別是維度的增加。所以說實(shí)時(shí)數(shù)倉(cāng)的場(chǎng)景維表和建模更適合按實(shí)際需求來做。

第四,時(shí)效性。實(shí)時(shí)數(shù)倉(cāng)本身還是需要有 raw 層,但是時(shí)效性比較高的場(chǎng)景,比如要同步一些線上的數(shù)據(jù),這個(gè)數(shù)據(jù)最后同步快充也是線上的業(yè)務(wù)使用,要盡量減少鏈路,減少時(shí)延。比如可以用一些 Flink CDC 的方式減少中間層,這樣不單減少了整體的鏈路和時(shí)延,鏈路節(jié)點(diǎn)減少也意味著問題發(fā)生的概率變小。對(duì)于時(shí)延要求沒有那么高的內(nèi)部分析場(chǎng)景,盡量選擇使用實(shí)時(shí)數(shù)倉(cāng),可以減少數(shù)據(jù)的冗余。
六、其他應(yīng)用場(chǎng)景
其他的使用場(chǎng)景還包括 CQRS 類應(yīng)用。比如業(yè)務(wù)部門的功能更多的是考慮增刪改查或者是傳統(tǒng)數(shù)據(jù)庫(kù)操作,但后續(xù)還是會(huì)存在數(shù)據(jù)分析的場(chǎng)景,這個(gè)時(shí)候用業(yè)務(wù)庫(kù)去做分析是一個(gè)不太正確的方法,因?yàn)闃I(yè)務(wù)庫(kù)的設(shè)計(jì)本來就沒有考慮分析,更適合使用分析的 OLAP 引擎來做這項(xiàng)工作。這樣也就把業(yè)務(wù)部門要負(fù)責(zé)的工作和數(shù)據(jù)部門負(fù)責(zé)的工作分割開來,大家各司其職。
此外還有指標(biāo)的監(jiān)控和異常檢測(cè)。比如對(duì)各種指標(biāo)通過 Flink 進(jìn)行實(shí)時(shí)的檢測(cè),它會(huì) load 一個(gè)機(jī)器學(xué)習(xí)模型,然后實(shí)時(shí)檢測(cè)指標(biāo)的變化是否符合預(yù)期,和預(yù)期的差距有多大,還可以設(shè)置一個(gè)區(qū)域值來進(jìn)行指標(biāo)的異常檢測(cè)。
實(shí)時(shí)數(shù)據(jù)的場(chǎng)景越來越多,大家對(duì)實(shí)時(shí)數(shù)據(jù)的需求也越來越多,所以未來我們會(huì)繼續(xù)進(jìn)行實(shí)時(shí)數(shù)據(jù)方面的探索。我們?cè)诹髋惑w的實(shí)時(shí)和離線存儲(chǔ)統(tǒng)一上已經(jīng)有了一些產(chǎn)出,我們也會(huì)在這方面投入更多精力,包括 Flink CDC 是否真的可以減少鏈路,提高響應(yīng)效率,也是我們會(huì)去考慮的問題。