













實時數(shù)倉方案五花八門,實際落地如何選型和構(gòu)建
01為何需要實時數(shù)倉架構(gòu)
最初企業(yè)存儲數(shù)據(jù)都在數(shù)倉中存儲,但是隨著數(shù)據(jù)量的增大,傳統(tǒng)數(shù)據(jù)的方案在時效性上和數(shù)據(jù)維護上變得越來越困難。實時數(shù)倉架構(gòu)應(yīng)運而生。
然而問題并不是這么簡單,在具體方案落地上實時數(shù)倉有很多方案可以選擇,那么面對不同的業(yè)務(wù)和應(yīng)用場景我們到底應(yīng)該選擇哪種技術(shù)方案呢?這是困擾好多大數(shù)據(jù)架構(gòu)師的問題。

圖1
02數(shù)倉如何分層&各層用途
介紹實時數(shù)倉前,我們先回顧下離線數(shù)倉的分層架構(gòu),這將對我們后面理解實時數(shù)倉架構(gòu)設(shè)計具有很大幫助。
數(shù)倉一般分為:ODS層、DWD層、DWS層和ADS層。這里我會分別展開說一下。這部分內(nèi)容大家了解數(shù)倉中每層數(shù)據(jù)的特點即可,具體研發(fā)中同學(xué)們可以根據(jù)項目再做深入體會。
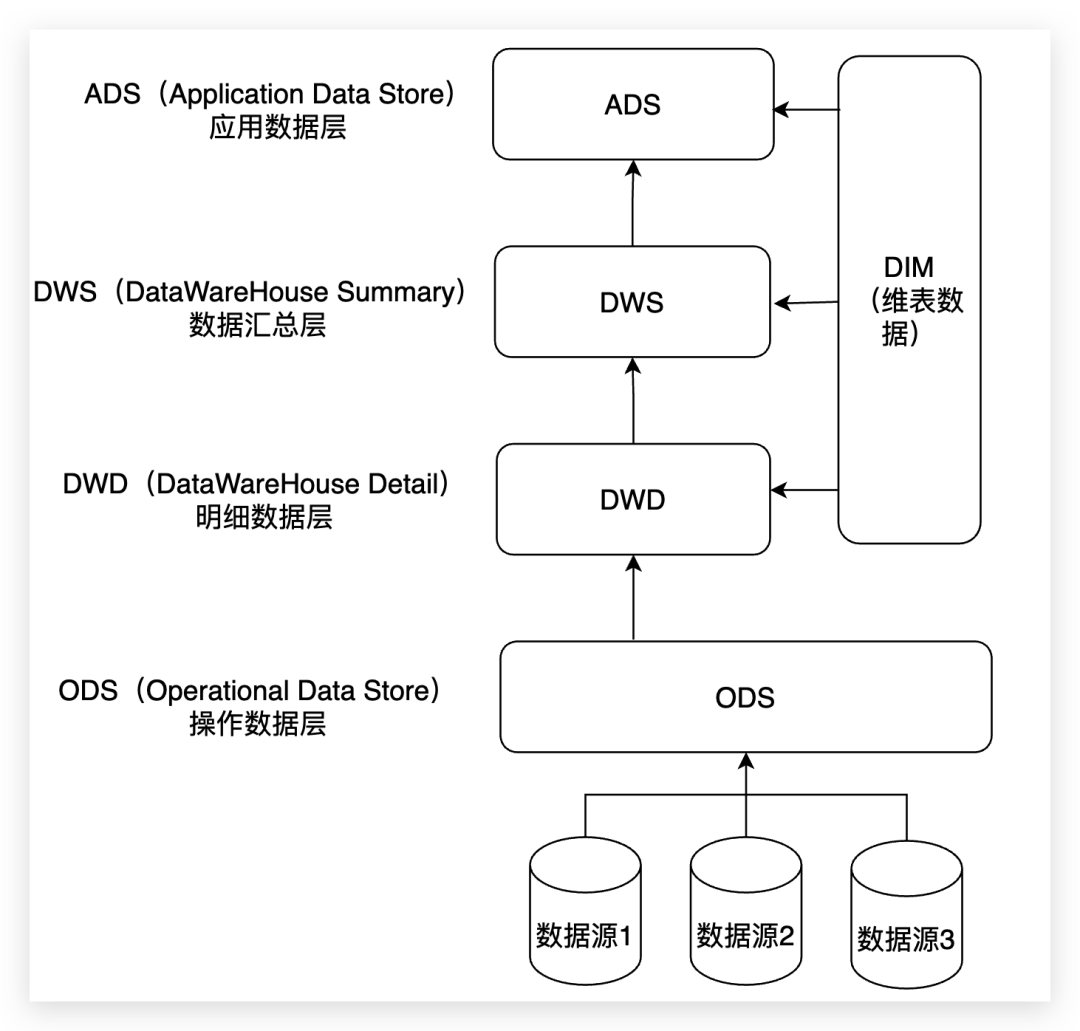
圖2
1)ODS層:ODS是數(shù)據(jù)接入層,所有進入數(shù)據(jù)的數(shù)據(jù)首先會接入ODS層。一般來說ODS層的數(shù)據(jù)是多復(fù)雜多樣的。從數(shù)據(jù)粒度上看ODS層是粒度最細的數(shù)據(jù)層。
2)DWD層:為數(shù)據(jù)倉庫層,數(shù)據(jù)明細層的數(shù)據(jù)應(yīng)是經(jīng)過ODS清洗,轉(zhuǎn)后的一致的、準確的、干凈的數(shù)據(jù)。DWD層數(shù)據(jù)粒度通常和ODS的粒度相同,不同的是該層的數(shù)據(jù)質(zhì)量更高,字段更全面等。在數(shù)據(jù)明細層會保存BI系統(tǒng)中所有的歷史數(shù)據(jù),例如保存近10年來的數(shù)據(jù)。
3)DWS層:數(shù)據(jù)集市層,該層數(shù)據(jù)是面向主題來組織數(shù)據(jù)的,通常是星形或雪花結(jié)構(gòu)的數(shù)據(jù)。從數(shù)據(jù)粒度來說,這層的數(shù)據(jù)是輕度匯總級的數(shù)據(jù),已經(jīng)不存在明細數(shù)據(jù)了。
4)ADS層:數(shù)據(jù)應(yīng)用層,它是完全為了滿足具體的分析需求而構(gòu)建的數(shù)據(jù),也是星形或雪花結(jié)構(gòu)的數(shù)據(jù)。從數(shù)據(jù)粒度來說是高度匯總的數(shù)據(jù)。其匯總的目標主要是按照應(yīng)用需求進行的。
03數(shù)倉分層的必要性
那么數(shù)倉為什么要分層,數(shù)倉分層后有哪些好處呢?數(shù)倉分層是一個比較麻煩且耗費工作成本的一個事情,只有理解了數(shù)倉分層到底有哪些好處,我們才能理解數(shù)倉分層的必要性。
數(shù)倉分層的總體思路是用空間換時間,其目的是通過數(shù)倉分層,使得數(shù)倉能夠更好地應(yīng)對需求的變更,和提高數(shù)據(jù)的穩(wěn)定性。
1)用空間換時間:通過大量的預(yù)處理來提升應(yīng)用系統(tǒng)的用戶體驗(效率),因此數(shù)據(jù)倉庫會存在大量冗余的數(shù)據(jù)。
2)能更好地應(yīng)對需求的變更:如果不分層的話,如果源業(yè)務(wù)系統(tǒng)的業(yè)務(wù)規(guī)則發(fā)生變化,將會影響整個數(shù)據(jù)清洗過程,工作量巨大。
3)提高數(shù)據(jù)處理過程的穩(wěn)定性:通過數(shù)據(jù)分層管理可以簡化數(shù)據(jù)清洗的過程,因為把原來一步的工作分到了多個步驟去完成,相當于把一個復(fù)雜的工作拆成了多個簡單的工作,每一層的處理邏輯都相對簡單和容易理解。
這樣我們比較容易保證每一個步驟的正確性,當數(shù)據(jù)發(fā)生錯誤的時候,往往我們只需要局部調(diào)整某個步驟即可。

圖3
前面介紹了數(shù)倉分層的一些基本理論,這將對我們后面理解實時數(shù)倉的各種架構(gòu)打下一些理論知識基礎(chǔ)。下面為大家梳理下市場上常見的實時數(shù)倉方案和對應(yīng)的應(yīng)用場景。
04從Lambda架構(gòu)說起
大部分實時數(shù)倉,其實是從Lambda架構(gòu)演化而來的,因此在介紹實時數(shù)倉方案前我們先回顧下Lambda架構(gòu)。
Lambda架構(gòu)將數(shù)據(jù)分為實時數(shù)據(jù)和離線數(shù)據(jù)。
針對實時數(shù)據(jù)使用流式計算引擎進行計算(例如Flink),針對離線數(shù)據(jù)使用批量計算引擎(例如Spark)計算。然后分別將計算結(jié)果存儲在不同的存儲引擎上對外提供數(shù)據(jù)服務(wù)。

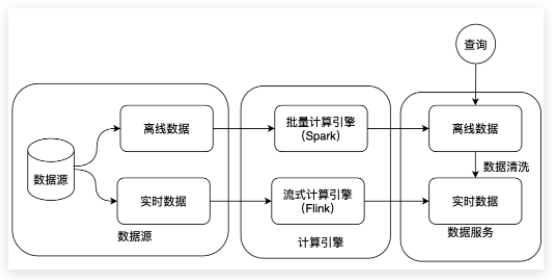
圖4
這種架構(gòu)的優(yōu)點是離線數(shù)據(jù)和實時數(shù)據(jù)各自計算,既能保障實時為業(yè)務(wù)提供服務(wù),又能保障歷史數(shù)據(jù)的快速分析。它分別結(jié)合了離線計算引擎與流式計算引擎二者的優(yōu)勢。
但是有一個缺點是離線數(shù)據(jù)和實時數(shù)據(jù)的一致性比較難保障,一般在離線數(shù)據(jù)產(chǎn)生后會使用離線數(shù)據(jù)清洗實時數(shù)據(jù)來保障數(shù)據(jù)的強一致性。
05Kappa架構(gòu)解決哪些問題
接下來要講的這種架構(gòu),它是基于Lambda架構(gòu)上的優(yōu)化版本,Kappa架構(gòu)。這種架構(gòu)將數(shù)據(jù)源的數(shù)據(jù)全部轉(zhuǎn)換為流式數(shù)據(jù),并將計算統(tǒng)一到流式計算引擎上。
這種方式的特點使架構(gòu)變得更加簡單,但是不足之處是需要保障數(shù)據(jù)都是實時的數(shù)據(jù),如果數(shù)據(jù)是離線的話也需要轉(zhuǎn)化為流式數(shù)據(jù)的架構(gòu)進行數(shù)據(jù)處理,具體架構(gòu)可結(jié)合這張圖來看。
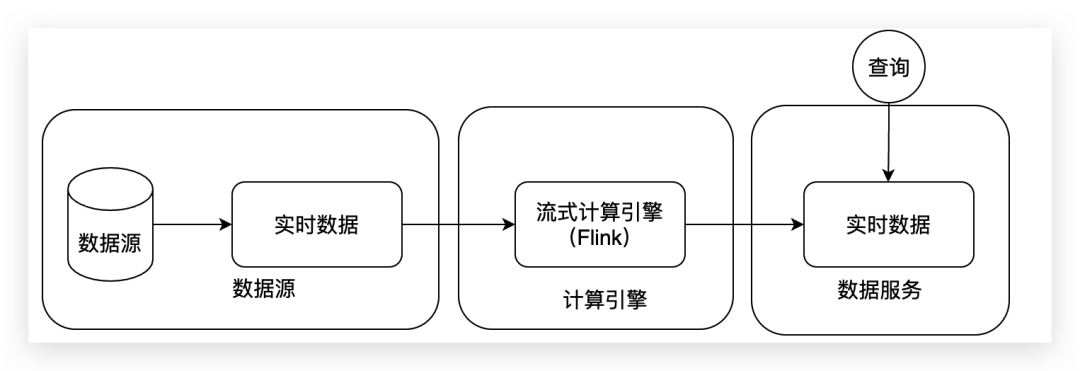
圖5
06深入實時數(shù)倉架構(gòu)
實時數(shù)倉的查詢需求
在正式討論實時數(shù)倉前,我們先看下行業(yè)對實時數(shù)倉的主要需求,這有助于我們理解實時數(shù)倉各種方案設(shè)計的初衷,了解它是基于哪些需求應(yīng)運而生的。
這也將幫助我們從更多維度上思考需求、條件、落地難點等等一些關(guān)鍵要素之間如何評估和權(quán)衡,最終實現(xiàn)是基于現(xiàn)有條件下的功能如何將其價值最大化。
傳統(tǒng)意義上我們通常將數(shù)據(jù)處理分為離線的和實時的。對于實時處理場景,我們一般又可以分為兩類:
一類諸如監(jiān)控報警類、大屏展示類場景要求秒級甚至毫秒級;另一類諸如大部分實時報表的需求通常沒有非常高的時效性要求,一般分鐘級別,比如10分鐘甚至30分鐘以內(nèi)都可接受。

圖6
基于以上查詢需求,業(yè)界常見的實時數(shù)倉方案有這幾種。
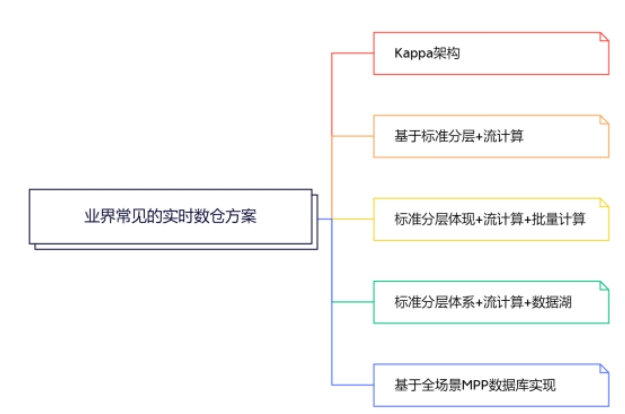
 圖7
圖7
目前老的項目大部分還在使用的標準分層體現(xiàn)+流計算+批量計算的方案。未來大家可能都會遷移到標準分層體系+流計算+數(shù)據(jù)湖,和基于全場景MPP數(shù)據(jù)庫實現(xiàn)的方案上,我也會重點介紹這兩個方案,也希望大家能夠多花點時間加以理解。
方案 1:Kappa 架構(gòu)
首先咱們看下Kappa架構(gòu),Kappa架構(gòu)將多源數(shù)據(jù)(用戶日志,系統(tǒng)日志,BinLog日志)實時地發(fā)送到Kafka。
然后通過Flink集群,按照不同的業(yè)務(wù)構(gòu)建不同的流式計算任務(wù),對數(shù)據(jù)進行數(shù)據(jù)分析和處理,并將計算結(jié)果輸出到MySQL/ElasticSearch/HBase/Druid/KUDU等對應(yīng)的數(shù)據(jù)源中,最終提供應(yīng)用進行數(shù)據(jù)查詢或者多維分析。
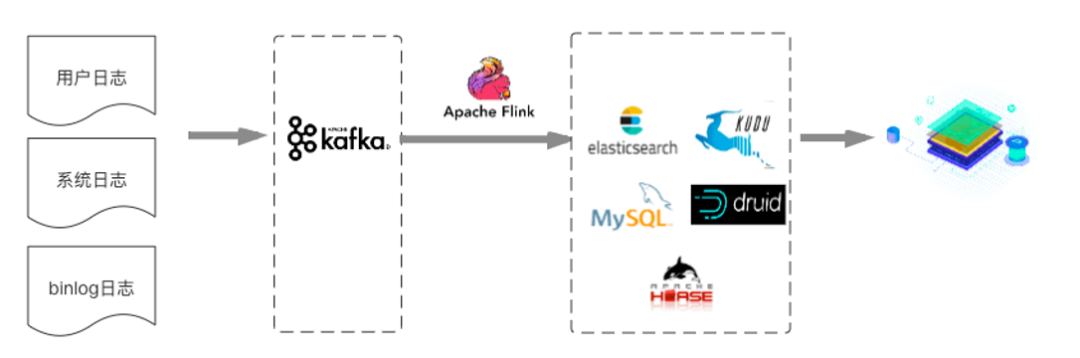
圖8
這種方案的好處有二,方案簡單;數(shù)據(jù)實時。不過有兩個缺點:
一個是用戶每產(chǎn)生一個新的報表需求,都需要開發(fā)一個Flink流式計算任務(wù),數(shù)據(jù)開發(fā)的人力成本和時間成本都較高。
第二個是對于每天需要接入近百億的數(shù)據(jù)平臺,如果要分析近一個月的數(shù)據(jù),則需要的Flink集群規(guī)模要求很大,且需要將很多計算的中間數(shù)據(jù)存儲在內(nèi)存中以便多流Join。
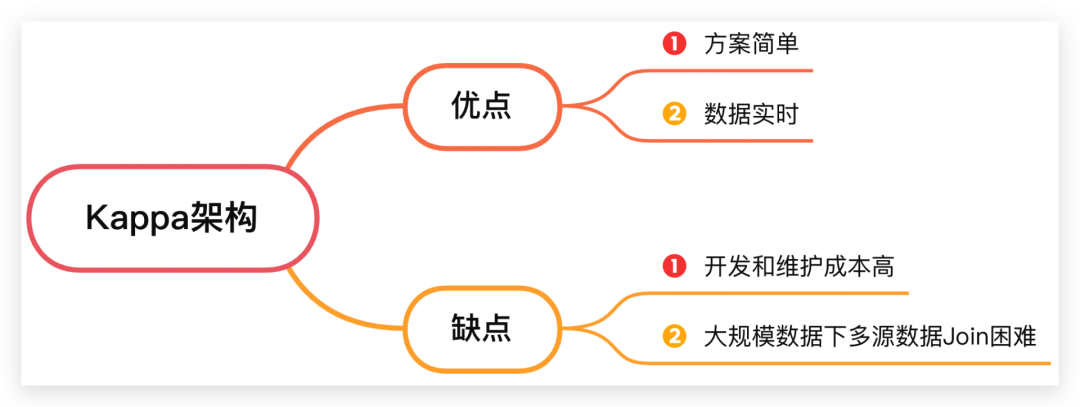
圖9
方案 2:基于標準分層 + 流計算
為了解決方案1中將所有數(shù)據(jù)放在一個層出現(xiàn)的開發(fā)維護成本高等問題,于是出現(xiàn)了基于標準分層+流計算的方案。
接下來咱們看下這種方案,在傳統(tǒng)數(shù)倉的分層標準上構(gòu)建實時數(shù)倉,將數(shù)據(jù)分為ODS、DWD、DWS、ADS層。首先將各種來源的數(shù)據(jù)接入ODS貼源數(shù)據(jù)層,再對ODS層的數(shù)據(jù)使用Flink的實時計算進行過濾、清洗、轉(zhuǎn)化、關(guān)聯(lián)等操作,形成針對不同業(yè)務(wù)主題的DWD數(shù)據(jù)明細層,并將數(shù)據(jù)發(fā)送到Kafka集群。
之后在DWD基礎(chǔ)上,再使用Flink實時計算進行輕度的匯總操作,形成一定程度上方便查詢的DWS輕度匯總層。最后再面向業(yè)務(wù)需求,在DWS層基礎(chǔ)上進一步對數(shù)據(jù)進行組織進入ADS數(shù)據(jù)應(yīng)用層,業(yè)務(wù)在數(shù)據(jù)應(yīng)用層的基礎(chǔ)上支持用戶畫像、用戶報表等業(yè)務(wù)場景。
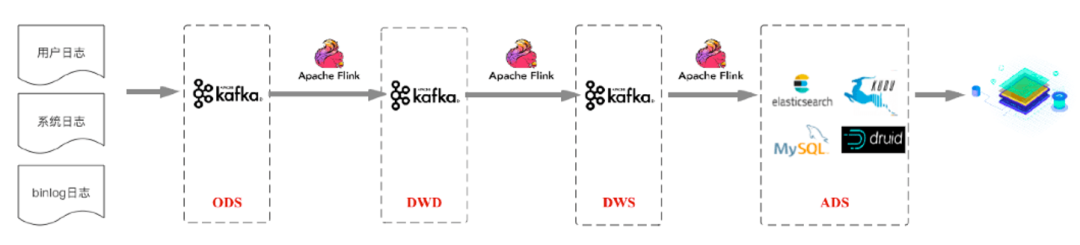
圖10
這種方案的優(yōu)點是:各層數(shù)據(jù)職責清晰。缺點是多個Flink集群維護起來復(fù)雜,并且過多的數(shù)據(jù)駐留在Flink集群內(nèi)也會增大集群的負載,不支持upset操作,同時Schema維護麻煩。
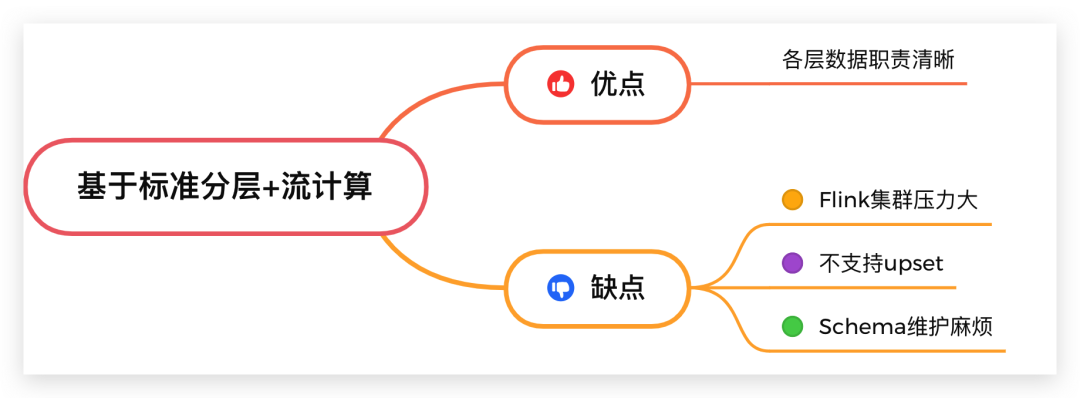
圖11
方案 3:標準分層體現(xiàn) + 流計算 + 批量計算
為了解決方案2不支持upset和schema維護復(fù)雜等問題。我們在方案2的基礎(chǔ)上加入基于HDFS加 Spark離線的方案。也就是離線數(shù)倉和實時數(shù)倉并行流轉(zhuǎn)的方案。
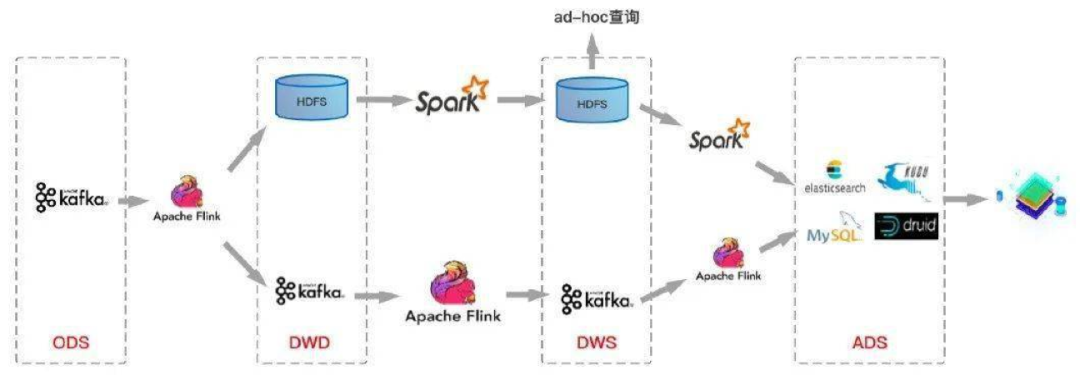
圖12
這種方案帶來的優(yōu)點是:既支持實時的OLAP查詢,也支持離線的大規(guī)模數(shù)據(jù)分析。但是帶來了問題這樣的幾個問題。
數(shù)據(jù)質(zhì)量管理復(fù)雜:需要構(gòu)建一套兼容離線數(shù)據(jù)和實時數(shù)據(jù)血緣關(guān)系的數(shù)據(jù)管理體系,本身就是一個復(fù)雜的工程問題。離線數(shù)據(jù)和實時數(shù)據(jù)Schema統(tǒng)一困難。架構(gòu)不支持upset。
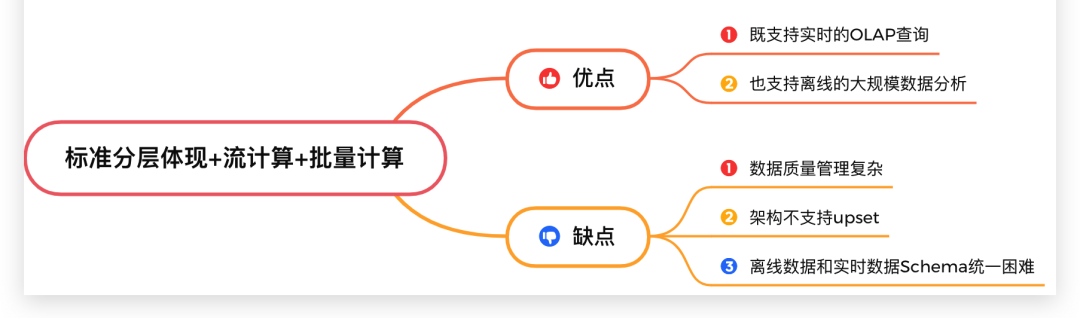
圖13
方案 4:標準分層體系 + 流計算 + 數(shù)據(jù)湖
隨著技術(shù)的發(fā)展,為了解決數(shù)據(jù)質(zhì)量管理和upset 問題。出現(xiàn)了流批一體架構(gòu),這種架構(gòu)基于數(shù)據(jù)湖三劍客 Delta Lake / Hudi / Iceberg 實現(xiàn) + Spark 實現(xiàn)。

圖14
我們以Iceberg為例介紹下這種方案的架構(gòu),從下圖可以看到這方案和前面的方案2很相似,只是在數(shù)據(jù)存儲層將Kafka換為了Iceberg。
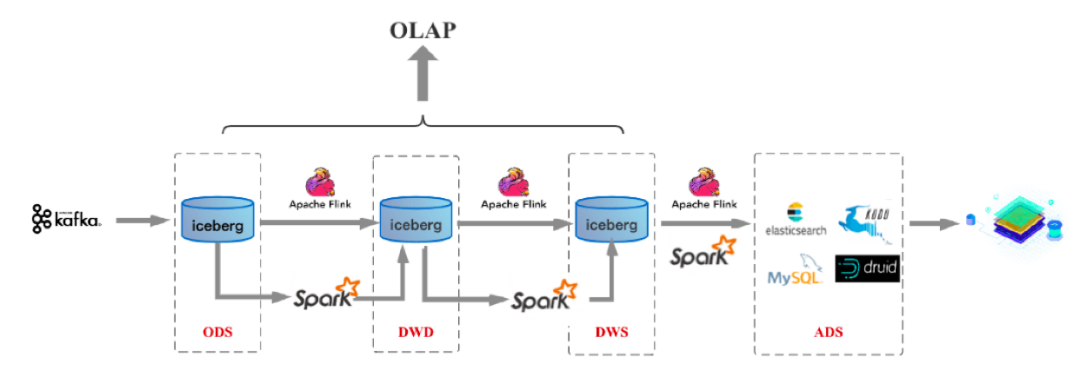
圖15
它有這樣的幾個特點,其中第2、3點,尤為重要,需要特別關(guān)注下,這也是這個方案和其他方案的重要差別。
1、在編程上將流計算和批計算統(tǒng)一到同一個SQL引擎上,基于同一個Flink SQL既可以進行流計算,也可以進行批計算。
2、將流計算和批計算的存儲進行了統(tǒng)一,也就是統(tǒng)一到Iceberg/HDFS上,這樣數(shù)據(jù)的血緣關(guān)系的和數(shù)據(jù)質(zhì)量體系的建立也變得簡單了。
3、由于存儲層統(tǒng)一,數(shù)據(jù)的Schema也自然統(tǒng)一起來了,這樣相對流批單獨兩條計算邏輯來說,處理邏輯和元數(shù)據(jù)管理的邏輯都得到了統(tǒng)一。
4、數(shù)據(jù)中間的各層(ODS、DWD、DWS、ADS)數(shù)據(jù),都支持OLAP的實時查詢。
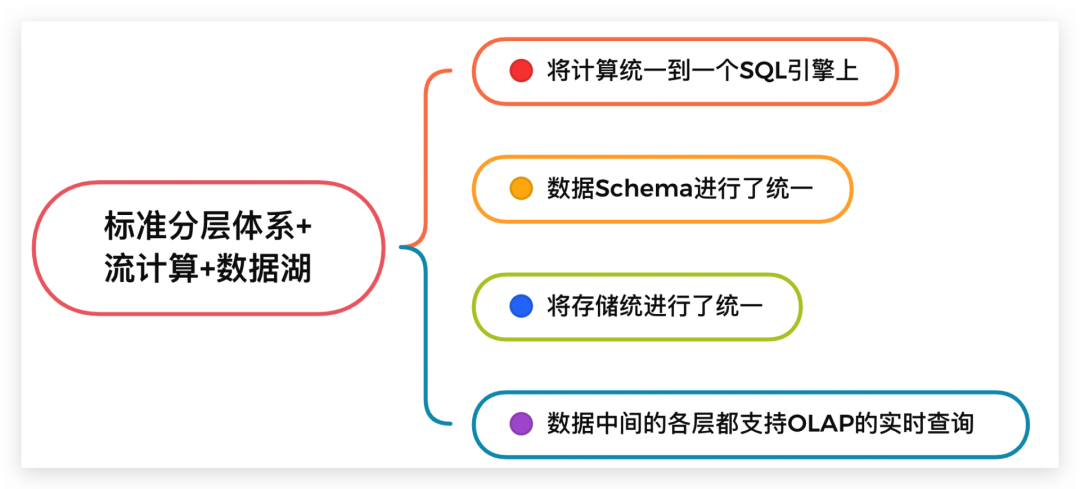
圖16
那么為什么 Iceberg 能承擔起實時數(shù)倉的方案呢,主要原因是它解決了長久以來流批統(tǒng)一時的這些難題:
1、同時支持流式寫入和增量拉取。
2、解決小文件多的問題。數(shù)據(jù)湖實現(xiàn)了相關(guān)合并小文件的接口,Spark / Flink上層引擎可以周期性地調(diào)用接口進行小文件合并。
3、支持批量以及流式的 Upsert(Delete) 功能。批量Upsert / Delete功能主要用于離線數(shù)據(jù)修正。流式upsert場景前面介紹了,主要是流處理場景下經(jīng)過窗口時間聚合之后有延遲數(shù)據(jù)到來的話會有更新的需求。這類需求是需要一個可以支持更新的存儲系統(tǒng)的,而離線數(shù)倉做更新的話需要全量數(shù)據(jù)覆蓋,這也是離線數(shù)倉做不到實時的關(guān)鍵原因之一,數(shù)據(jù)湖是需要解決掉這個問題的。
4、同時 Iceberg 還支持比較完整的OLAP生態(tài)。比如支持Hive / Spark / Presto / Impala 等 OLAP 查詢引擎,提供高效的多維聚合查詢性能。
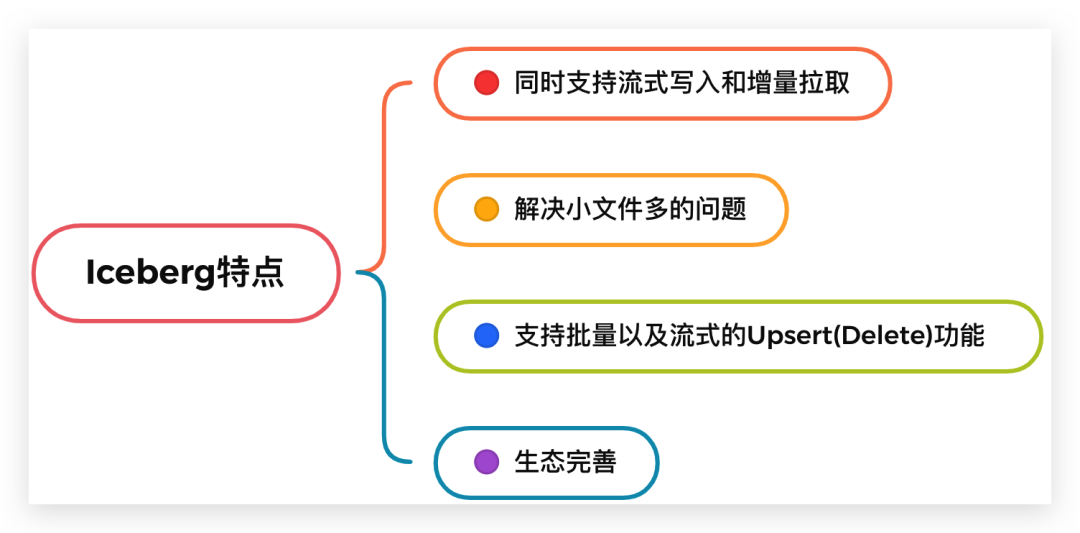
圖17
Iceberg 實戰(zhàn)
上面介紹了基于Iceberg的標準分層體系+流計算+數(shù)據(jù)湖的架構(gòu),下面咱們從實戰(zhàn)角度看下Iceberg如何使用。
iceberg寫入流式數(shù)據(jù)代碼實現(xiàn)如下:
data.writeStream.format("iceberg") .outputMode("append") .trigger(Trigger.ProcessingTime(1, TimeUnit.MINUTES)).option("data_path", tableIdentifier) .option("checkpointLocation", checkpointPath) .start()br
上述代碼會將data_path下的數(shù)據(jù)以流的形式,實時加入到系統(tǒng)中進行計算。
iceberg數(shù)據(jù)過濾代碼實現(xiàn)如下:
Table table = Actions.forTable(table).rewriteDataFiles() .filter(Expressions.equal("date", "2022-03-18")) .targetSizeInBytes(500 * 1024 * 1024) // 500 MB .execute();br
上述代碼過濾出date為2022-03-18的數(shù)據(jù)。
方案 5:基于全場景MPP數(shù)據(jù)庫實現(xiàn)
前面的四種方案,是基于數(shù)倉方案的優(yōu)化。方案仍然屬于比較復(fù)雜的,如果我能提供一個數(shù)據(jù)庫既能滿足海量數(shù)據(jù)的存儲,也能實現(xiàn)快速分析,那豈不是很方便。這時候便出現(xiàn)了以StartRocks和ClickHouse為代表的全場景MPP數(shù)據(jù)庫。
1、基于Darios或者ClickHouse構(gòu)建實時數(shù)倉。來看下具體的實現(xiàn)方式:將數(shù)據(jù)源上的實時數(shù)據(jù)直接寫入消費服務(wù)。
2、對于數(shù)據(jù)源為離線文件的情況有兩種處理方式,一種是將文件轉(zhuǎn)為流式數(shù)據(jù)寫入Kafka,另外一種情況是直接將文件通過SQL導(dǎo)入ClickHouse集群。
3、ClickHouse接入Kafka消息并將數(shù)據(jù)寫入對應(yīng)的原始表,基于原始表可以構(gòu)建物化視圖、Project等實現(xiàn)數(shù)據(jù)聚合和統(tǒng)計分析。
4、應(yīng)用服務(wù)基于ClickHouse數(shù)據(jù)對外提供BI、統(tǒng)計報表、告警規(guī)則等服務(wù)。
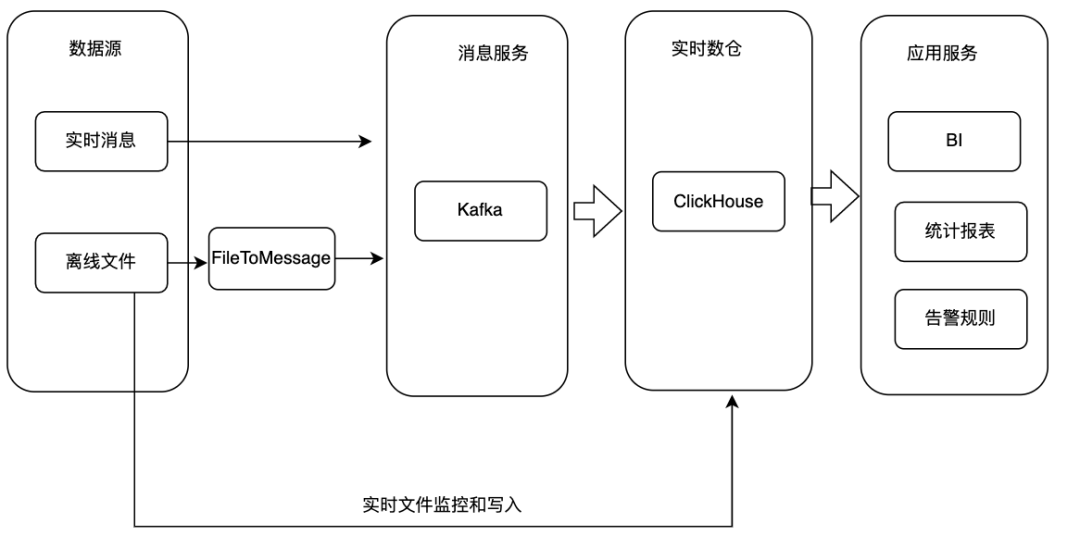
圖18
07具體選型建議
對于這5種方案,在具體選型中,我們要根據(jù)具體業(yè)務(wù)需求、團隊規(guī)模等進行技術(shù)方案選型。
說到這兒,我有這樣的幾點具體建議,希望或多或少可以給你提供一些可供參考、借鑒的新視角或者新思路。
(1)對于業(yè)務(wù)簡單,且以流式數(shù)據(jù)為主數(shù)據(jù)流的大數(shù)據(jù)架構(gòu)可以采用Kappa架構(gòu)。
(2)如果業(yè)務(wù)以流計算為主,對數(shù)據(jù)分層,數(shù)據(jù)權(quán)限,多主題數(shù)據(jù)要求比較高,建議使用方案2的基于標準分層+流計算。
(3)如果業(yè)務(wù)的流數(shù)據(jù)是批數(shù)據(jù)都比較多,且流數(shù)據(jù)和批數(shù)據(jù)直接的關(guān)聯(lián)性不大,建議使用方案3的標準分層體現(xiàn)+流計算+批量計算。這種情況下分別能發(fā)揮流式計算和批量計算各自的優(yōu)勢。
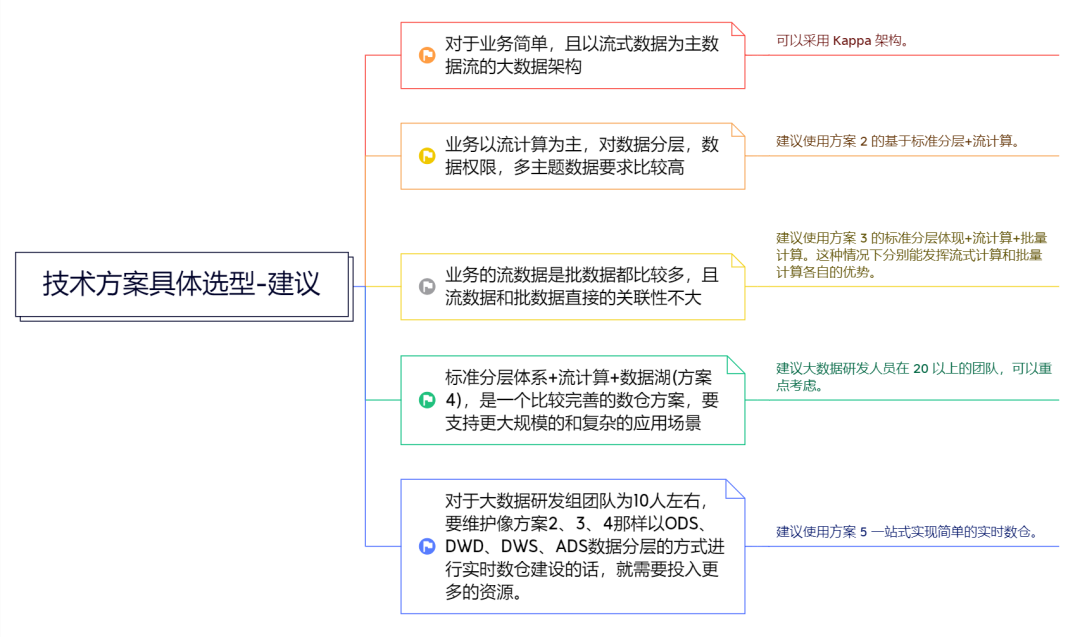
圖19
(4)方案4是一個比較完善的數(shù)倉方案,要支持更大規(guī)模的和復(fù)雜的應(yīng)用場景,建議大數(shù)據(jù)研發(fā)人員在20以上的團隊,可以重點考慮。
(5)對于大數(shù)據(jù)研發(fā)組團隊為10人左右,要維護像方案2、3、4那樣以O(shè)DS、DWD、DWS、ADS數(shù)據(jù)分層的方式進行實時數(shù)倉建設(shè)的話,就需要投入更多的資源。建議使用方案5一站式實現(xiàn)簡單的實時數(shù)倉。
08大廠方案分享
介紹了這么多實時數(shù)倉方案,那么很多小伙伴會問了,大廠到底用的那種方案呢?其實每個大廠根據(jù)自己業(yè)務(wù)特點的不同,也會選擇不同的解決方案。下面為大家簡要分享下OPPO、滴滴和比特大陸的方案,以便大家能夠更好地理解這篇分享中五種架構(gòu)的具體落地。
不過具體架構(gòu)細節(jié)我不會進行過多的介紹,有了前面的內(nèi)容基礎(chǔ),相信大家再通過架構(gòu)圖就能很快了解每個架構(gòu)的特點。這里只是希望大家能夠通過大廠的經(jīng)驗,明白他們架構(gòu)設(shè)計的初衷和要解決的具體問題,同時也給我們的架構(gòu)設(shè)計提供一些思路。
舉例來說,OPPO的實時計算平臺架構(gòu),其方案其實類似于方案2的基于標準分層+流計算。
圖20
滴滴的大數(shù)據(jù)平臺架構(gòu)是這樣的,它的方案其實類似于方案2的基于標準分層+流計算。
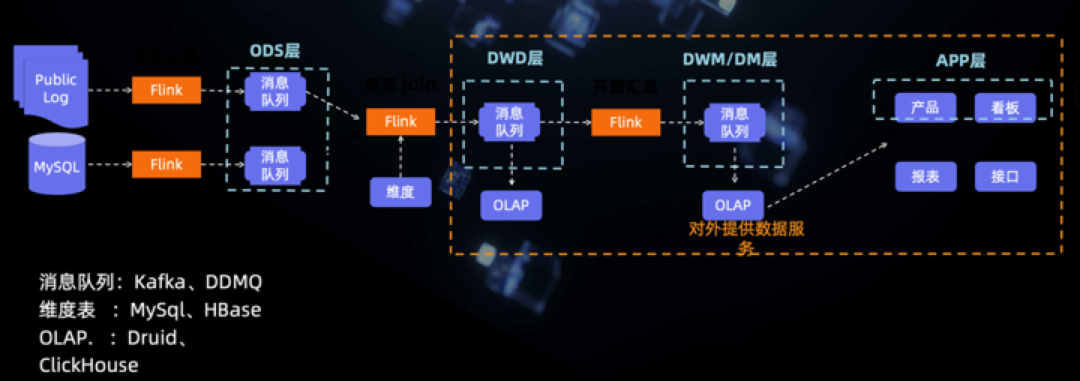
圖21
再結(jié)合比特大陸的方案看下,其方案類型方案3的標準分層體現(xiàn)+流計算+批量計算,同時也引入了ClickHouse,可以看到比特大陸的數(shù)據(jù)方案是很復(fù)雜的。
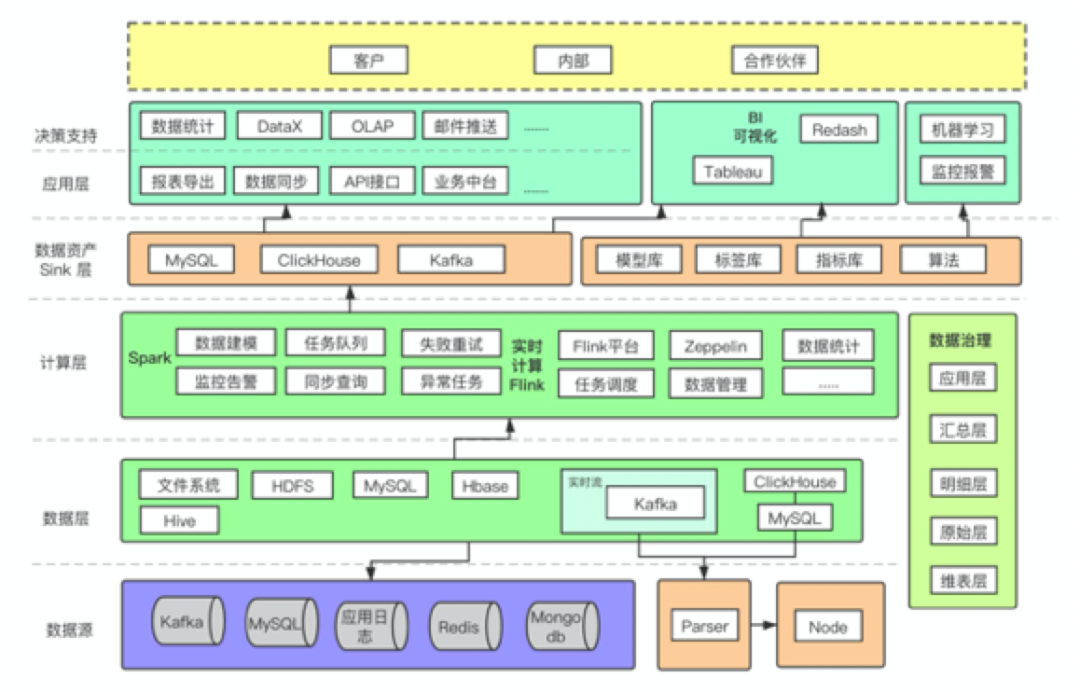
圖22
09結(jié)語&延伸思考
本文介紹了市面上常見實時數(shù)倉方案,并對不同方案的優(yōu)缺點進行了介紹。在使用過程中我們需要根據(jù)自己的業(yè)務(wù)場景選擇合適的架構(gòu)。
另外想說明的是實時數(shù)倉方案并不是“搬過來”,而是根據(jù)業(yè)務(wù)“演化來”的,具體設(shè)計的時候需要根據(jù)自身業(yè)務(wù)情況,找到最適合自己當下的實時數(shù)倉架構(gòu)。
關(guān)于作者,王磊,阿里云 MVP,華院計算技術(shù)總監(jiān)。




















