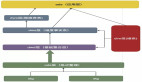
實時數(shù)倉|架構設計與技術選型
前言
當我們做一個項目時往往都需要選擇該用什么技術。這一部分不是我們普通員工想的,而是架構師會根據(jù)客戶的需求選擇出合適的技術。當選擇合適的技術會讓我們的開發(fā)事半功倍。下面我就來講解下我做的項目(實時數(shù)倉)是如何進行選型的。
一、技術選型
當我們在選擇技術時需要根據(jù)客戶的需求來進行選擇。比如:實時統(tǒng)計交易金額(要求延遲不能超過一秒),這時我們在選擇技術時就不能用那些批處理的技術比如Hive,MapRducer 等,因為MapRducer 啟動有可能就能超過了一秒鐘,所以根本就不能滿足這些需求。這時我們可以考慮用一些實時計算的技術如 Flink,SparkStreaming等。接下來我們就來講解下如何選擇。
目前市場是有很多實時計算的技術如:Spark streaming、Struct streaming、Storm 、JStorm(阿里) 、Kafka Streaming 、Flink 等眾多的技術棧我們該如何選擇那?
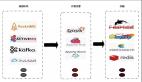
當我們在選擇技術時需要全面考慮,并不是你喜歡這個技術就要用這個技術,這不是明智的選擇。企業(yè)一般根據(jù) 公司員工的技術基礎、流行 、技術復用、場景等眾多的因素來進行選擇。附上一張技術圖

根據(jù)上述圖片就可以清晰的分析出該用什么技術。我在這里也推薦一下僅供參考
如果對延遲要求不高的情況下,可以使用 Spark Streaming,它擁有豐富的高級 API,使用簡單,并且 Spark 生態(tài)也比較成熟,吞吐量大,部署簡單,社區(qū)活躍度較高,從 GitHub 的 star 數(shù)量也可以看得出來現(xiàn)在公司用 Spark 還是居多的,并且在新版本還引入了 Structured Streaming,這也會讓 Spark 的體系更加完善。
如果對延遲性要求非常高的話,可以使用當下最火的流處理框架 Flink,采用原生的流處理系統(tǒng),保證了低延遲性,在 API 和容錯性方面做的也比較完善,使用和部署相對來說也是比較簡單的,加上國內阿里貢獻的 Blink,相信接下來 Flink 的功能將會更加完善,發(fā)展也會更加好,社區(qū)問題的響應速度也是非常快的,另外還有專門的釘釘大群和中文列表供大家提問,每周還會有專家進行直播講解和答疑。
本項目:使用Flink來搭建實時計算平臺
二、需求分析
目前需求有最后通過報表實時展示:
統(tǒng)計用戶日活對比分析(PV、UV、游客數(shù))分別使用柱狀圖顯示

2. 漏斗展示(付款數(shù)、下單數(shù)、加入購物車數(shù)、瀏覽數(shù))

3. 統(tǒng)計一周銷售額,使用曲線圖顯示
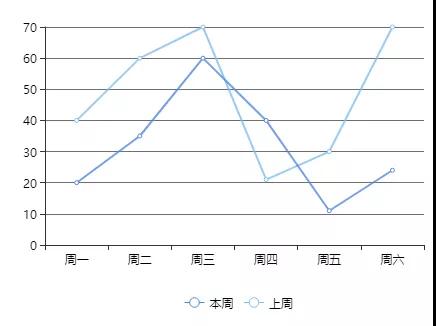
4. 24小時銷售曲線圖顯示

5. 訂單狀態(tài)占比

6. 訂單完成狀態(tài)分析

7. TopN地區(qū)排行

數(shù)據(jù)來源PV/UV數(shù)據(jù)來源
- 來自于頁面埋點數(shù)據(jù),將用戶訪問數(shù)據(jù)發(fā)送到web服務器
- web服務器直接將該部分數(shù)據(jù)寫入到kafka的click_log topic 中
銷售金額與訂單量數(shù)據(jù)來源
- 訂單數(shù)據(jù)來源于mysql
- 訂單數(shù)據(jù)來自binlog日志,通過canal 實時將數(shù)據(jù)寫入到kafka的order的topic中
購物車數(shù)據(jù)和評論數(shù)據(jù)
- 購物車數(shù)據(jù)一般不會直接操作mysql,通過客戶端程序寫入到kafka(消息隊列)中
- 評論數(shù)據(jù)也是通過客戶端程序寫入kafka(消息隊列)中
三、架構設計
根據(jù)分析需求我們可以這樣設計我們架構。

在線架構圖:https://gitmind.cn/app/flowchart/43aa8334090bdd1e1074271f08328e25
小結
本篇文章主要講解了如何選擇一合適技術棧,以及后面分享的技術實時數(shù)倉的架構圖。我們在離線數(shù)倉使用的是hive我們可以在Hive中進行一個層,而要做實時數(shù)倉的話需要使用消息隊列來做分層,本次項目使用Kafka來分層。我在這里為大家提供大數(shù)據(jù)的資源需要的朋友可以去下面GitHub去下載,信自己,努力和汗水總會能得到回報的。我是大數(shù)據(jù)老哥,我們下期見~~~
本文轉載自微信公眾號「大數(shù)據(jù)老哥」,可以通過以下二維碼關注。轉載本文請聯(lián)系大數(shù)據(jù)老哥公眾號。