基于Flink構建全場景實時數倉
本文轉載自微信公眾號「五分鐘學大數據」,作者園陌。轉載本文請聯系五分鐘學大數據公眾號。
本文目錄:
一. 實時計算初期
二. 實時數倉建設
三. Lambda架構的實時數倉
四. Kappa架構的實時數倉
五. 流批結合的實時數倉
實時計算初期
雖然實時計算在最近幾年才火起來,但是在早期也有不少公司有實時計算的需求,但數據量不成規模,所以在實時方面形成不了完整的體系,基本所有的開發都是具體問題具體分析,來一個需求做一個,基本不考慮它們之間的關系,開發形式如下:
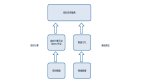
早期實時計算
如上圖所示,拿到數據源后,會經過數據清洗,擴維,通過Flink進行業務邏輯處理,最后直接進行業務輸出。把這個環節拆開來看,數據源端會重復引用相同的數據源,后面進行清洗、過濾、擴維等操作,都要重復做一遍,唯一不同的是業務的代碼邏輯是不一樣的。
隨著產品和業務人員對實時數據需求的不斷增多,這種開發模式出現的問題越來越多:
數據指標越來越多,“煙囪式”的開發導致代碼耦合問題嚴重。
需求越來越多,有的需要明細數據,有的需要 OLAP 分析。單一的開發模式難以應付多種需求。
每個需求都要申請資源,導致資源成本急速膨脹,資源不能集約有效利用。
缺少完善的監控系統,無法在對業務產生影響之前發現并修復問題。
大家看實時數倉的發展和出現的問題,和離線數倉非常類似,后期數據量大了之后產生了各種問題,離線數倉當時是怎么解決的?離線數倉通過分層架構使數據解耦,多個業務可以共用數據,實時數倉是否也可以用分層架構呢?當然是可以的,但是細節上和離線的分層還是有一些不同,稍后會講到。
實時數倉建設
從方法論來講,實時和離線是非常相似的,離線數倉早期的時候也是具體問題具體分析,當數據規模漲到一定量的時候才會考慮如何治理。分層是一種非常有效的數據治理方式,所以在實時數倉如何進行管理的問題上,首先考慮的也是分層的處理邏輯。
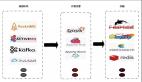
實時數倉的架構如下圖:
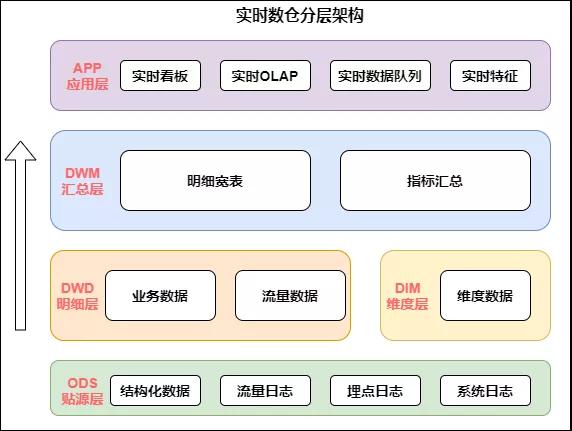
實時數倉架構
從上圖中我們具體分析下每層的作用:
- 數據源:在數據源的層面,離線和實時在數據源是一致的,主要分為日志類和業務類,日志類又包括用戶日志,埋點日志以及服務器日志等。
- 實時明細層:在明細層,為了解決重復建設的問題,要進行統一構建,利用離線數倉的模式,建設統一的基礎明細數據層,按照主題進行管理,明細層的目的是給下游提供直接可用的數據,因此要對基礎層進行統一的加工,比如清洗、過濾、擴維等。
- 匯總層:匯總層通過Flink的簡潔算子直接可以算出結果,并且形成匯總指標池,所有的指標都統一在匯總層加工,所有人按照統一的規范管理建設,形成可復用的匯總結果。
我們可以看出,實時數倉和離線數倉的分層非常類似,比如 數據源層,明細層,匯總層,乃至應用層,他們命名的模式可能都是一樣的。但仔細比較不難發現,兩者有很多區別:
- 與離線數倉相比,實時數倉的層次更少一些:
- 從目前建設離線數倉的經驗來看,數倉的數據明細層內容會非常豐富,處理明細數據外一般還會包含輕度匯總層的概念,另外離線數倉中應用層數據在數倉內部,但實時數倉中,app 應用層數據已經落入應用系統的存儲介質中,可以把該層與數倉的表分離。
- 應用層少建設的好處:實時處理數據的時候,每建一個層次,數據必然會產生一定的延遲。
- 匯總層少建的好處:在匯總統計的時候,往往為了容忍一部分數據的延遲,可能會人為的制造一些延遲來保證數據的準確。舉例,在統計跨天相關的訂單事件中的數據時,可能會等到 00:00:05 或者 00:00:10 再統計,確保 00:00 前的數據已經全部接受到位了,再進行統計。所以,匯總層的層次太多的話,就會更大的加重人為造成的數據延遲。
- 與離線數倉相比,實時數倉的數據源存儲不同:
- 在建設離線數倉的時候,基本整個離線數倉都是建立在 Hive 表之上。但是,在建設實時數倉的時候,同一份表,會使用不同的方式進行存儲。比如常見的情況下,明細數據或者匯總數據都會存在 Kafka 里面,但是像城市、渠道等維度信息需要借助 Hbase,MySQL 或者其他 KV 存儲等數據庫來進行存儲。
Lambda架構的實時數倉
Lambda和Kappa架構的概念已在前文中解釋,不了解的小伙伴可點擊鏈接:一文讀懂大數據實時計算
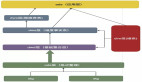
下圖是基于 Flink 和 Kafka 的 Lambda 架構的具體實踐,上層是實時計算,下層是離線計算,橫向是按計算引擎來分,縱向是按實時數倉來區分:
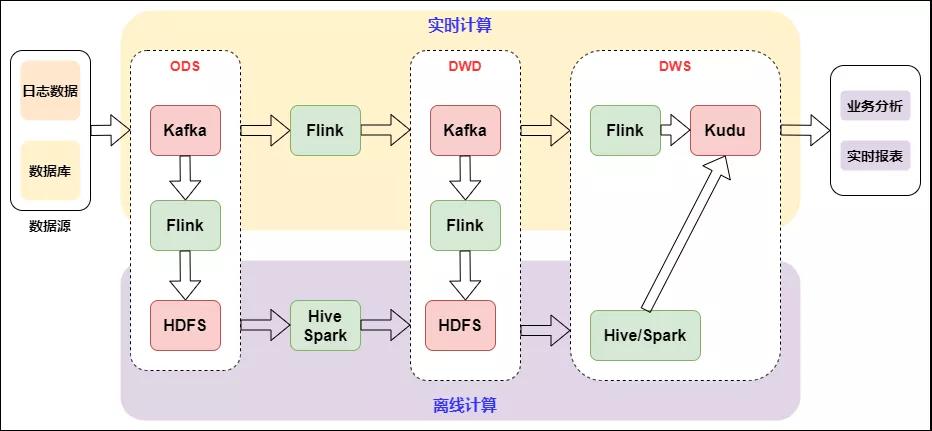
Lambda架構的實時數倉
Lambda架構是比較經典的架構,以前實時的場景不是很多,以離線為主,當附加了實時場景后,由于離線和實時的時效性不同,導致技術生態是不一樣的。Lambda架構相當于附加了一條實時生產鏈路,在應用層面進行一個整合,雙路生產,各自獨立。這在業務應用中也是順理成章采用的一種方式。
雙路生產會存在一些問題,比如加工邏輯double,開發運維也會double,資源同樣會變成兩個資源鏈路。因為存在以上問題,所以又演進了一個Kappa架構。
Kappa架構的實時數倉
Kappa架構相當于去掉了離線計算部分的Lambda架構,具體如下圖所示:
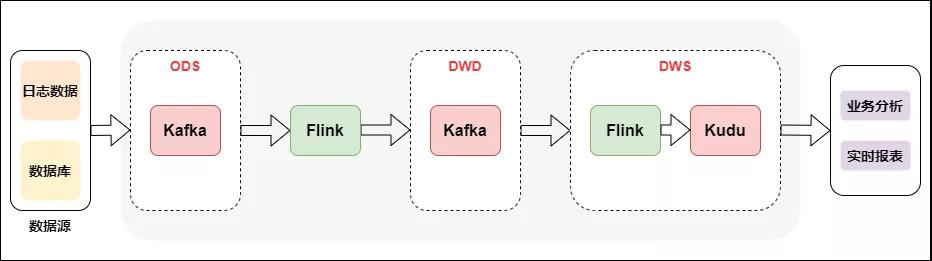
Kappa架構的實時數倉
Kappa架構從架構設計來講比較簡單,生產統一,一套邏輯同時生產離線和實時。但是在實際應用場景有比較大的局限性,因為實時數據的同一份表,會使用不同的方式進行存儲,這就導致關聯時需要跨數據源,操作數據有很大局限性,所以在業內直接用Kappa架構生產落地的案例不多見,且場景比較單一。
關于 Kappa 架構,熟悉實時數倉生產的同學,可能會有一個疑問。因為我們經常會面臨業務變更,所以很多業務邏輯是需要去迭代的。之前產出的一些數據,如果口徑變更了,就需要重算,甚至重刷歷史數據。對于實時數倉來說,怎么去解決數據重算問題?
Kappa 架構在這一塊的思路是:首先要準備好一個能夠存儲歷史數據的消息隊列,比如 Kafka,并且這個消息隊列是可以支持你從某個歷史的節點重新開始消費的。接著需要新起一個任務,從原來比較早的一個時間節點去消費 Kafka 上的數據,然后當這個新的任務運行的進度已經能夠和現在的正在跑的任務齊平的時候,你就可以把現在任務的下游切換到新的任務上面,舊的任務就可以停掉,并且原來產出的結果表也可以被刪掉。
流批結合的實時數倉
隨著實時 OLAP 技術的發展,目前開源的OLAP引擎在性能,易用等方面有了很大的提升,如Doris、Presto等,加上數據湖技術的迅速發展,使得流批結合的方式變得簡單。
如下圖是流批結合的實時數倉:
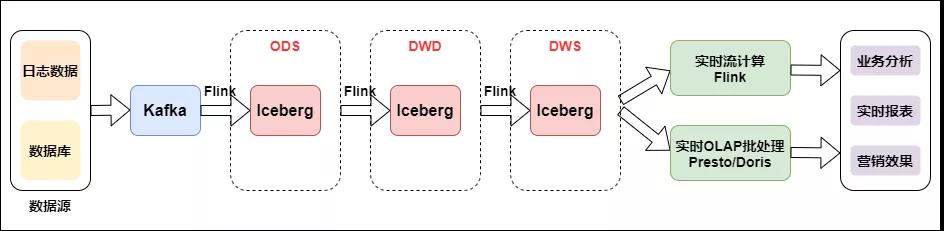
流批結合的實時數倉
數據從日志統一采集到消息隊列,再到實時數倉,作為基礎數據流的建設是統一的。之后對于日志類實時特征,實時大屏類應用走實時流計算。對于Binlog類業務分析走實時OLAP批處理。
我們看到流批結合的方式與上面幾種架構使用的組件發生了變化,多了數據湖 Iceberg 和 OLAP 引擎 Presto。Iceberg是介于上層計算引擎和底層存儲格式之間的一個中間層,我們可以把它定義成一種“數據組織格式”,底層存儲還是HDFS,Iceberg的ACID能力可以簡化整個流水線的設計,降低整個流水線的延遲,并且所具有的修改、刪除能力能夠有效地降低開銷,提升效率。Iceberg可以有效支持批處理的高吞吐數據掃描和流計算按分區粒度并發實時處理。OLAP查詢引擎使用Presto,Presto是一個分布式的采用MPP架構的查詢引擎,本身并不存儲數據,但是可以接入多種數據源,并且支持跨數據源的級聯查詢。擅長對海量數據進行復雜的分析。