













區塊鏈和大數據的共同關鍵詞:分布式

大數據和區塊鏈具有一個共同的關鍵詞:分布式。
分布式的思想讓大數據技術實現了分布式計算和分布式協同工作,技術手段也從權威壟斷轉向了去中心化。
而區塊鏈技術作為分布式數據庫的典型代表,也具有分布式的特點。
兩者在這一點上的統一帶來了融合發展的可能。
1.分布式:讓大數據和區塊鏈從技術權威向去中心化轉變
從歷史上的發展來看,IT技術發展呈現出一種集中與分布交替的螺旋式上升的形態
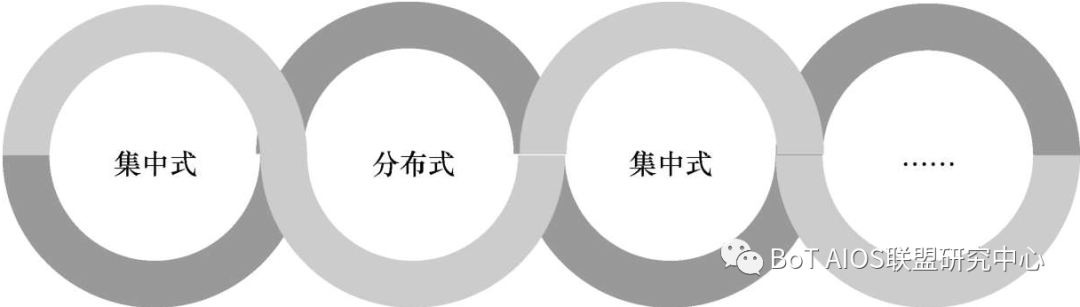
IT技術呈現螺旋化上升
在計算機誕生初期,技術是集中化的,這是因為技術的限制導致了使用模式只能是一對一的。
為了增加計算機的利用率,行業公司很快開始部署新的設計。
IBM公司引入了虛擬化的設計思想,將一臺大型機在為多個客戶服務時分割出多個虛擬的小型主機,這是一種十分復雜的集中式計算。
等進入到小型機和PC時代,雖然使用模式回歸了一對一的模式,但是計算機設備已經分散到了各個地方。
等進入成熟的互聯網時代,客戶端和服務器已經運用了分布式計算的模式,只不過各個服務器之間還是分散的,沒有連成網絡。
進入云計算時代,計算能力又被統一管控起來。
雖然客戶端和服務器依舊以分布式計算為技術基礎,但服務器之間已經形成了分布式協同工作模式。
因為協同的特點,整體上這應該是一種集中式的計算服務。
到了以云計算為基礎設施的大數據時代,IT技術中仍舊蘊含著分布式的核心思想。
以現在最常用的分布式計算技術的代表MapReduce來說,大數據需要MapReduce將任務分解后進行分布式計算,然后將結果合并。
分布式的技術形成了一種去中心化的系統,其中的每個組成部分都是同等重要的。
具有這個特點的區塊鏈技術在這一點上也顯得十分突出。從本質上看,區塊鏈是一種去中心化的分布式賬本。
區塊鏈通過時間順序將持續增長的數據整理成鏈式數據結構,系統中所有節點共同參與數據的記錄。在“分布式”這一理念上,大數據和區塊鏈技術取得了一致。
而分布式概念的出現,代表了一種從技術權威壟斷到去中心化的轉變。
在IT方面中的技術壟斷更加指向具有壟斷性質的大型互聯網公司,假如某家公司掌握了所有互聯網社交軟件的技術,那么它就可以將整個社會輿論控制在手中。
普通民眾因為要使用該公司提供的社交軟件,根本無法順利發出對該公司的質疑。
一家公司獨大,甚至掌控了社會輿論,普通民眾失去了發聲、監管的權利,這顯然是十分不利于社會安定的事情,也違背了互聯網“網絡自由”的初衷,各國政府也在反互聯網技術壟斷上做出了各種努力。
而當“分布式”的概念出現后,從根本上打破了技術權威壟斷的情況,形成了“無中心”的新技術。
在分布式的系統中,所有參與者享有同等的權利。大數據的各個協同工作組件缺一不可,互相協調才能完成工作;
區塊鏈的各個節點共同監督數據,每個節點都有質疑和被質疑的過程。
分布式的核心思想讓區塊鏈和大數據都具有了從技術權威到去中心化的特點。
區塊鏈和大數據在分布式上的共同點有兩個具體的領域:分布式存儲和分布式計算。
2.分布式存儲:HDFS VS區塊
分布式存儲是相對集中式存儲而言的。
在傳統的數據存儲技術中,數據被集中放置在一個特定的數據庫中,就好比用一個籃子裝所有的雞蛋;
而分布式的存儲則利用了多個數據庫,共同存儲數據,“雞蛋”被分散在了各個容器中。
在存儲數據上,區塊鏈和大數據都采用了分布式存儲的技術。
區塊鏈存儲數據的基本單元是區塊,而大數據則是Hadoop分布式文件系統(HDFS)。
如果把區塊鏈看作賬本,區塊鏈中的區塊就是賬本中的賬頁。
在比特幣的區塊鏈中,每一個區塊都記錄了一段時間內比特幣的交易數據。
在中本聰創立比特幣時,構建了第一個區塊——創世區塊。
對于區塊鏈來說,計算機進入區塊鏈中成為一個“區塊”是沒有什么特殊要求的,只要計算能力夠強,就可以成為一個新的區塊。
也就是說,這些區塊的計算機設備可以出現在地球的各個角落。
那么這些原本分散的設備是怎么組合在一起形成“區塊鏈”的呢?
在區塊鏈的區塊中,除了“創世區塊”只有一個ID識別號之外,后續建立的區塊都包含兩個ID識別號,一個是屬于自己的,一個是屬于前一個區塊的。
通過ID號碼之間的指向,區塊就按照時間順序連成了區塊鏈。
由于需要應對海量且在持續快速增長的數據,大數據在數據存儲方面則更加注重性價比,實現存儲容量彈性擴張。
HDFS是大數據應用程序中主要使用的分布式存儲技術,能夠滿足商用硬件的高性價比的要求,因此在眾多分布式技術中脫穎而出。
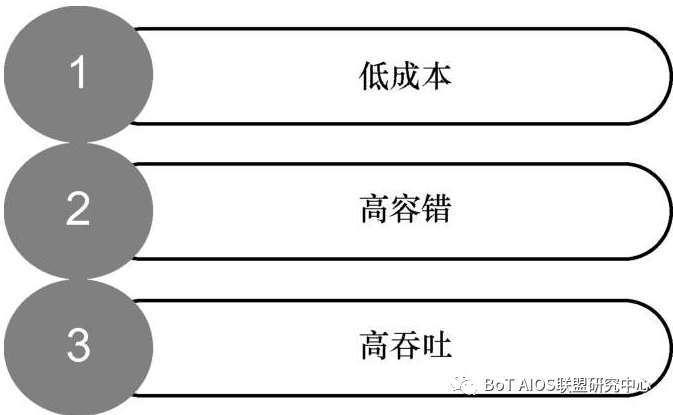
HDFS的特點
1).低成本
HDFS的分布式存儲服務是依靠數百個甚至數千個服務器共同工作實現的,這樣一來,在服務器出現故障時就只需要單獨維修這一臺機器就可以了。
如果是集中式的大型服務器,遇到故障的維修成本將要高許多。HDFS系統通過這種方式實現了低成本的目標。
2).高容錯
由于HDFS是眾多服務器協同工作,共同實現分布存儲,HDFS給每個數據文件都準備了兩個冗余備份,保證每個數據文件被存儲三次。
這樣即使某臺服務器出現故障,HDFS也可以在備份數據的幫助下繼續進行工作。
所以HDFS允許機器發生故障,具有高容錯的特點。
3).高吞吐
HDFS的訪問模型是“一次寫入多次讀寫”式的,只能夠在結尾追加描述數據的變動而不允許直接修改文件。
這樣就簡化了保證數據一致性的流程,實現了高吞吐的數據訪問。
雖然區塊鏈和大數據在存儲數據的實現技術上采用了不同的方式,但不能否認它們都是基于“分布式”的思想出發的:通過利用多個計算機,實現數據的分布式存儲。
這樣的存儲方式讓大數據技術有能力應對龐大的數據量,也讓區塊鏈實現了去中心化的共治。
3.分布式計算:MapReduce VS共識機制
分布式計算是一種新的計算方式,是指兩個或多個軟件之間互相共享信息,合作計算。
分布式計算方式不要求這些軟件在一臺計算機上運行,可以在多臺計算機上通過網絡連接共同運算。
簡單點來說,分布式計算就是將大量的數據分割成多個較小的單元,分派給多臺計算機分工計算,最后將所有結果進行匯總。
這種計算方式是云計算的技術基礎,對數據海量的大數據計算來說意義重大,因為創造一個算力足以應對PB級別的計算機幾乎是不可能的。
分布式計算的理論在很早以前就已經有科研人員在研究,但實踐方案并不多,也沒有得到廣泛應用。
直到谷歌公布了MapReduce之后,分布式計算的應用才開始得到廣泛關注。
在大數據領域,分布式計算的成功案例就有MapReduce。
MapReduce是云計算的核心技術,適用于大規模數據集(大于1 TB)的并行運算,在大數據的分布式運算中具有良好的表現。
同時MapReduce也是一種簡化的分布式編程技術,能夠有效提高復雜問題的并行處理效率。
而在區塊鏈中,分布式計算的思想體現在“共識機制”中。
區塊鏈的共識機制是區塊之間達成共識、寫入數據的手段,也是防止數據篡改的手段。
區塊鏈的共識機制有多種,比特幣區塊鏈采用的是“工作量證明”,意味著只有算力超過了51%的記賬區塊的計算機才有寫入下一筆數據的權利,這也大大降低了篡改交易記錄的可能。
分布式計算的核心在于不同計算機通過信息交換能夠最終達成一致的結論,區塊鏈的共識機制也剛好體現了這一點。
除了比特幣區塊鏈采用的“工作量證明”機制,“唐盛鏈”采用的GEAR協議也是共識機制的一種。
GEAR協議是由唐盛(北京)物聯技術有限公司自主研發的共識協議,由輪轉記賬、集體評估和齒輪共識路由三個子協議組成。
該協議充分考慮了區塊鏈上的數據結構特點和點對點溝通的信息交流模式,在實現數據同步共識時支持多種場景靈活運用。
把大數據和區塊鏈兩者的分布式計算應用結合起來看,會發現核心特點就在于數據的同步共享和負載平衡。
通過分布式計算,數據資源在所有的計算機上都有備份,方便實現稀有資源的共享;
也可以降低計算機的運行負載,減小計算機崩潰的可能;
同時還能夠通過調配,把程序放在最合適的計算機上執行。
斯坦福大學化學系的戈爾哈姆·理查德·切爾曼教授曾說:“分布式計算將加快整個人類的科學進程。”
隨著現代科技的進步,每個學科的科學研究都需要進行大量的計算:數學家希望得出圓周率的更精確值,生物學家希望計算機模擬出蛋白質的折疊過程,天文學家希望計算機分析天體軌跡……
人類未來社會的發展離不開各種數據的計算,而分布式計算成功在大數據領域和區塊鏈領域得到實踐應用將會對各界產生積極的影響。
無論是MapReduce還是共識機制,都充分展現了分布式計算的獨特優點:便宜且高效。
區塊鏈和大數據具有一個共同的關鍵詞,那就是“分布式”。
兩者在存儲和計算運行的手段上雖然各有千秋,卻都體現了分布式的思想。
通過分布式存儲數據,區塊鏈和大數據實現了降低成本和提高系統穩定性的目標;
通過分布式計算,區塊鏈和大數據實現了數據共享和并行運算以解放計算機壓力的目標。
因為區塊鏈和大數據在分布式思想上具有很多的共同點,兩者的共同發展也就有了基礎,這也是區塊鏈能夠在大數據領域得到大規模應用的前提條件。
















