作者 | 李家俊
背景
本文分享的是 Bytedoc 3.0 關于集群交付方面的內容以及一些云原生的實踐:如何將 Bytedoc 3.0 與云原生的能力結合起來,交付用戶一個開箱即用的集群,與軟件層的能力相匹配,最大化展示 Bytedoc 3.0 具備的“彈性”能力。
面臨的問題
數據庫服務的使用者有兩方:用戶(業務)和 DBA(運維),運維能力不斷增強,才能給用戶更好的服務體驗。
用戶需求

運維需求

目標與思路
目標
為了解決上述問題,Bytedoc 3.0 軟件層已經實現了相關的能力,我們需要在交付層提供類似的能力,以匹配整體的“彈性”能力:
目標 1:數據庫能快速擴展/恢復從庫,秒級擴展數據庫的讀能力。擴容從庫實例自動化程度要高,擴容速度盡可能快;
目標 2:計算資源能夠按需擴展。對計算密集型業務,能快速擴展計算資源,而且能分配更多的資源供用戶使用,匹配實際負載;
目標 3:提升計算/存儲資源利用率,降低業務使用成本。
目標 4:更標準的交付能力與更高的交付質量,給用戶提供更好的數據庫服務。
實現思路
我們通過“Kubernetes 云原生”化來實現我們的目標:
Kubernetes 是業界通用的,用于自動部署,擴展和管理容器化應用程序的開源編排系統。簡單地說,它能夠系統化地打包、運行、管理你的服務,在這里是 Bytedoc 數據庫服務。這使得我們能夠結合已有的運維經驗和業界通用服務交付/管理解決方案,提供更好的、更高質量的數據庫服務,以發揮 Bytedoc 3.0 十足的"彈性"能力
在 ByteDoc 1.0 時期,大多數數據庫服務實例是直接部署到虛擬機上的,資源的分配受限于虛擬機規格的劃分,無法靈活地、按需要分配機器資源,導致大部分的機器資源空閑出來,無法得到有效利用;同時,因為計算與存儲的資源綁定,在 1.0 的自研部署平臺中,實現容器化部署十分困難,虛擬機部署的方案就一直保留下來。
直到 ByteDoc 3.0 的出現,將數據下沉存儲層,交付服務時,更多關注計算層方面的資源分配,使得容器化部署模式可行。結合 Kubernetes 對容器部署與管理的解決方案,我們將容器大部分自動化管理操作交由給 Kubernetes 控制器管理,專注于 ByteDoc 3.0 服務編排過程,如集群部署、從庫擴容等,以充分發揮 3.0 的"彈性"能力。
云原生實踐
服務云原生化,實際上是一個“遷移”的過程,將原有服務打包、運行、管理能力,以 Kubernetes 提供的解決方案為標準,重現出來。
在 Kubernetes 中,我們把 ByteDoc 3.0 集群定義為一種定制資源(CustomResource)。提供數據庫服務,實際上就是創建了一種資源;和 K8s 內置的工作負載資源一樣,定制資源也需要一個控制器來進行管理,通常把這類控制器稱作 Operator。
所以,ByteDoc 3.0 云原生實踐的關鍵是構建 ByteDoc Operator。
Kubernetes 基本概念
容器化部署
前面說到,Kubernetes 是一個容器編排系統,主要的職責是管理容器生命周期,所以實際的應用程序應該提前打包成一個容器鏡像,以便于交付給 K8s 來使用。
Pod
??https://kubernetes.io/zh/docs/concepts/workloads/pods/??
我們打包好的容器最后會運行在 Pod 中,由 Pod 管理起來。
Pod 是 K8s 中內置的最基本的資源之一,也是最小部署的計算單元,可以類比于一些共享機器資源的容器組。
如果一個 Pod (內的容器)因異常導致退出,通常情況下,這個 Pod 會被刪除銷毀,高級 workload 會新建一個全新的 Pod 來代替它,而不是“重啟”該 Pod。
高級 workload
通常情況下,我們構建的 Operator 不會去直接創建 Pod;而是使用 K8s 提供的高級 workload 資源,他們會幫我們把 Pod 創建出來,并提供一些基本的資源管理能力。
Deployment:
維護一組給定數量的、完全相同的 Pod,通常用于無狀態服務。
StatefulSet:
同樣維護一組 Pod,特別的是,每個 Pod 都有穩定的網絡標示;在此情景下,如果一個 Pod 被銷毀重建,在外部使用者看來,該 Pod 是進行“重啟”了,所以通常用于有狀態的服務。
如何與 K8s 交互
Kubernetes 控制面的核心是 API 服務器。API 服務器負責提供 HTTP API,以供用戶、集群中的不同部分和集群外部組件相互通信。
一般而言,我們與 K8s 交互是通過“聲明式”,而非“動作命令式”。
# sample.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
minReadySeconds: 6
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
ByteDoc 3.0 在 Kubernetes 上的架構
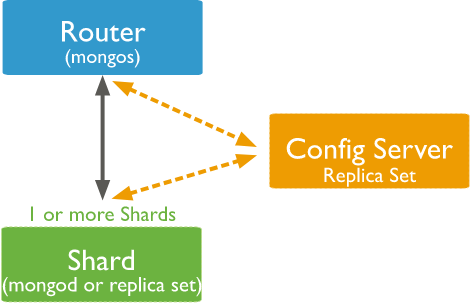
(ByteDoc 經典架構,由三部分組成)
mongos:
- 代理層,負責轉發、簡單處理用戶請求;
- 需要感知 Config Server,從中獲取 Shard 的拓撲;
config server:
- 復制集模式,區分主從;
- 存儲集群元信息,包括每個 shard 內實例的地址;
shard:
- 復制集模式,區分主從;
- server 層,處理用戶請求;
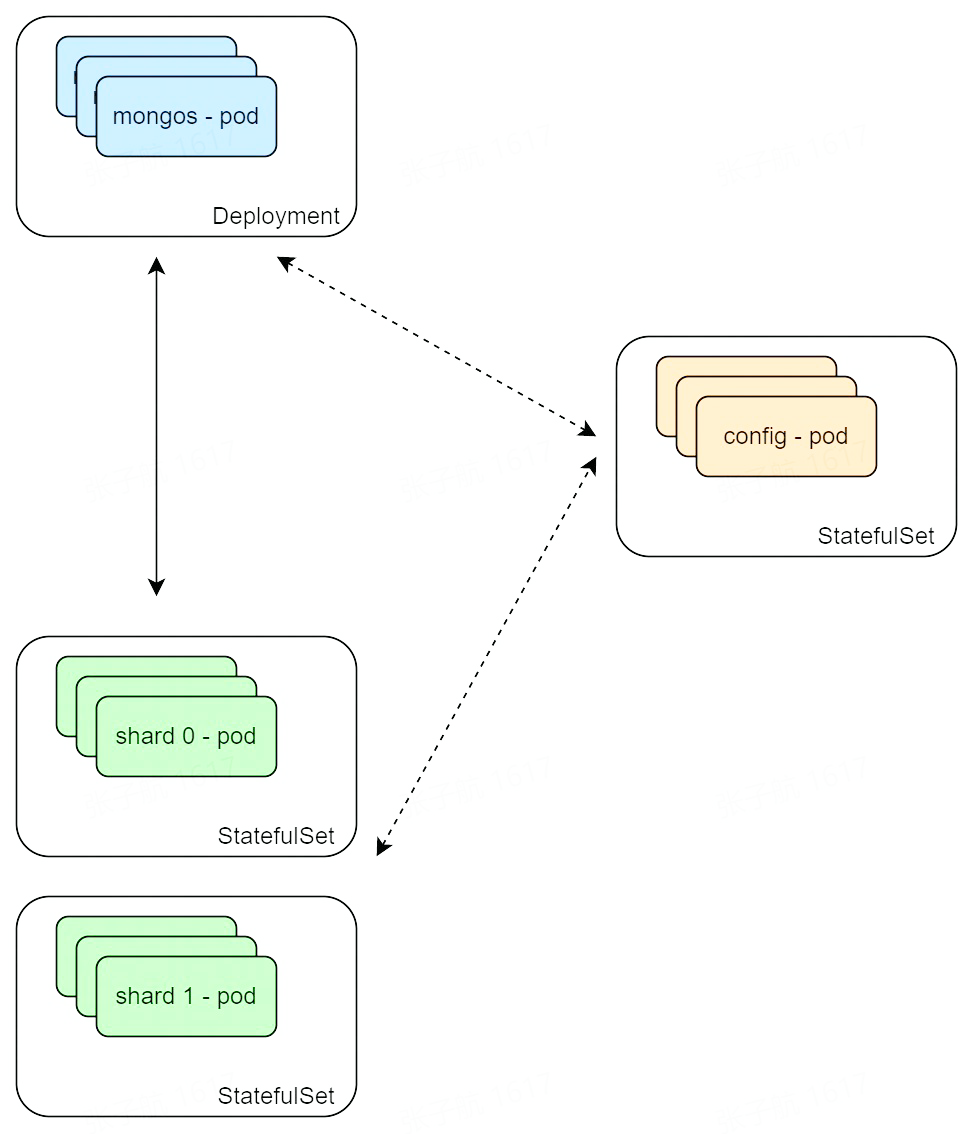
- mongos - deployment,對應無狀態的服務
- config server/shard - statefulset,對應有狀態的服務
對于 mongo 的復制集,復制集成員需要用一個網絡標示(host、dns、服務發現、headless service 等)注冊進配置中,才能與其他復制集成員進行通信;所以在這里,我們使用 StatefulSet 提供的穩定的網絡標示作為成員名稱,保證數據庫實例(對應的 pod)故障恢復后,以同樣的身份加入到復制集中,正常地提供服務。
聯邦模式
多機房場景下的架構
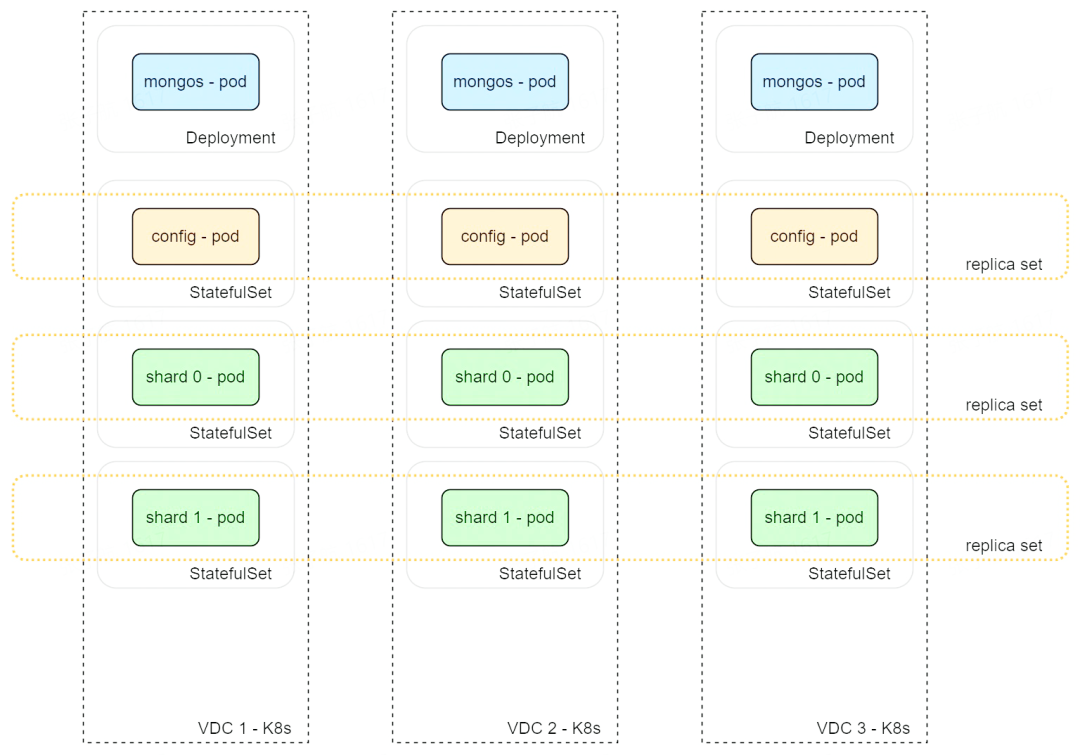
實際上,上述 ByteDoc 3.0 集群是在單機房下的架構,在線上生產環境中,還要考慮多機房容災的場景;在多機房場景下,我們希望一個 3 副本的集群,每個計算實例是分別部署在不同的機房,但是這些副本又是需要在同一個復制集中的,在參考了幾種跨 K8s 方案后,我們采取了下面的多機房架構:
有哪些候選的跨 K8s 的方案?
1、社區提供的 Federation V1 方案(deprecated,后續改進為 V2 方案)
- 主要提供兩個主要能力來支持管理多個集群:跨集群同步資源 & 跨集群服務發現
2、云原生 SRE 團隊提供的通用 operator 方案
spec:
charts:
- name: nginx
chart: charts/nginx
values: '"replicaCount": "{{ .replica_count | default 1 }}"'
cluster:
- placement:
- names:
- cluster-sample
execJobs:
- name: ls
command:
- ls
- "-l"
mustBefore:
- chart.nginx
var:
replica_count: '2'
- 定義一系列的 chart、K8s 集群、執行任務、變量
- 通過通用 operator 在多個 K8s 集群上完成資源部署、任務執行
3、MongoDB 官方提供的跨 K8s 方案
- 通過 mongodb 額外的 k8s-agent 完成跨 K8s 集群場景下,復制集與集群的構建
- 代碼未開源
為什么選擇了現在這種方案?
我們當前的方案實際上和社區的 Federation 方案比較相似,通過以下的能力搭建完整的 ByteDoc 3.0 集群:
- 資源復制:operator 連接 worker K8s,創建基本相同的資源
- 服務發現:分具體的網絡場景,如果使用 overlay 網絡,可以使用社區支持的無頭服務(headless service);如果是走 underlay 網絡,則需要額外的服務發現能力
- 組建 ByteDoc 集群:將實例組建為集群的核心邏輯,比較復雜,不太容易通過任務的形式實現
因此,我們選擇這種 Meta Operator 的方案,通過 worker K8s 創建資源,后續 Operator 完成集群的搭建工作。
達到期望狀態
spec:
global:
chartVersion: "1.0.0.0"
bytedocVersion: "3.0"
image: "example_image"
mongos:
replicaCount: 2
resources:
limits:
cpu: "4"
memory: 2Gi
requests:
cpu: "1"
memory: 1Gi
shard:
shardsCount: 1
replicaCount: 4
config:
replicaCount: 3
placement:
- name: vdc1
vdc: "vdc1"
那么 ByteDoc Operator 到底執行了什么邏輯呢?Operator 其實也滿足 K8s 控制器的設計理念,也就是,每個資源對象有一個期望狀態,operator 需要把資源對象調整至期望狀態,這個調整過程稱為 Reconcile。
再仔細探究一下,ByteDoc 集群分為 3 個組件,只要 Mongos、config server、shard 三個組件都達到期望狀態,最后將組件“連接”起來,整個集群也達到期望狀態了;
所以我們可以將整個集群的 Reconcile,分解為對若干個模塊 Reconcile,當每個小的模塊都達到期望狀態,整個集群也達到了期望狀態,bytedoc operator 大致是基于這樣的設計理念。
所以,我們的 operator 大致流程如下:
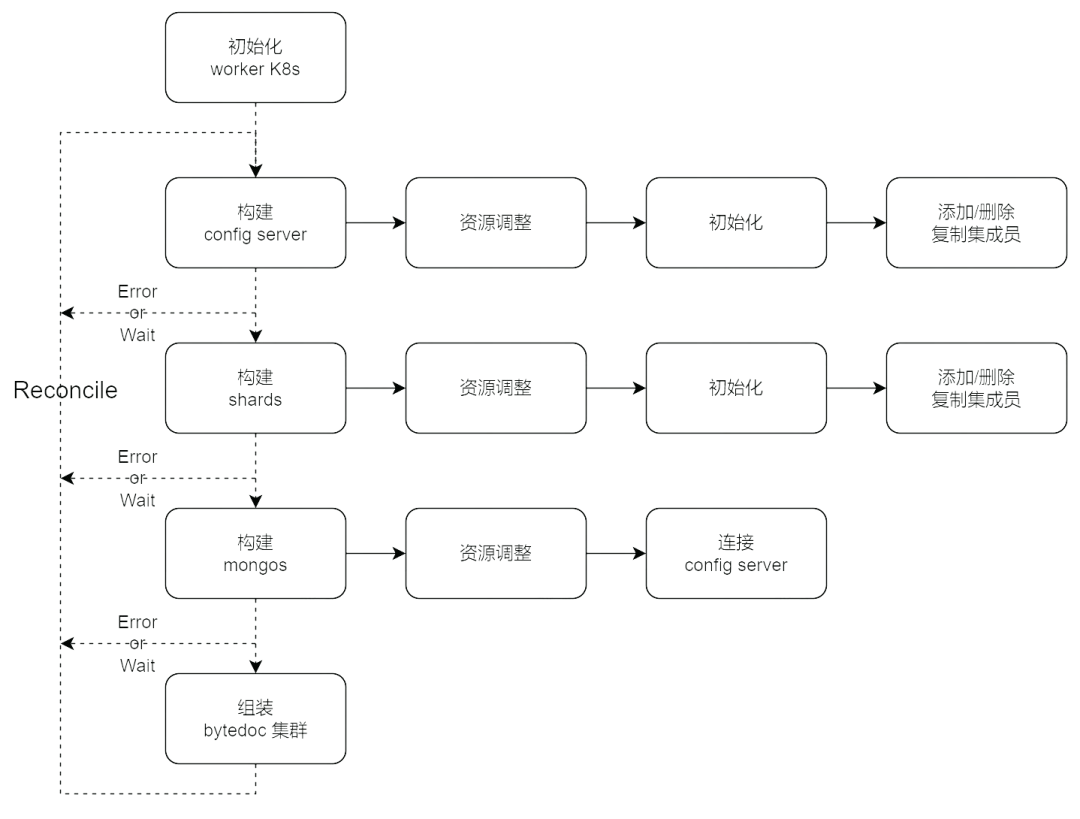
狀態管理 - Status
Status 顧名思義就是用來存儲一個資源對象當前狀態的,可以充當狀態機或小型存儲使用。可以用來實現:
- 一次性操作的完成情況:如初始化是否完成
- 鏡像/服務版本
- 組件 status
- 集群升級進度控制
- 備份進度控制
- 資源變更是否完成
- 通常記錄在字段 observedGeneration
- 當我們對集群 CR 做變更時,metadata 中的 generation 計數會 +1,operator 需要在達到這次變更的期望狀態時,設置相等的 observedGeneration 計數,以方便查詢 CR 變更已完成。
- 等等
status:
replica_set:
ll2022-shard-0:
inline:
added_as_shard: true
initialized: true
read_only_ready: true
ready: 3
size: 3
status: ready
placement:
vdc1:
ready: 3
size: 3
status: ready
vdc: vdc1
資源模板化管理 - Helm
上面說到,ByteDoc 每個組件實際上用了 K8s 內置的資源來管理的,一般情況下,我們不需要從頭編寫整個 CR 的 yaml 文件,更多的是調整一個固定模板里的動態參數,比如 mongos 的實例數,CPU、Mem 資源限制等。
從此出發,工程實現上就有兩種方向:
- 將 yaml 模板硬編碼到代碼中,通過變量替換,生成目標的資源文件;
- 將 yaml 模板以文件的形式存放,通過字符替換,生成目標的資源文件;
模板渲染與資源發布
我們采用的是第二種方法的一個較為優雅的版本,用 Helm (code)管理內置資源文件的渲染和發布 在 operator 鏡像中,我們按照 helm 的標準,維護了一系列 charts 文件。
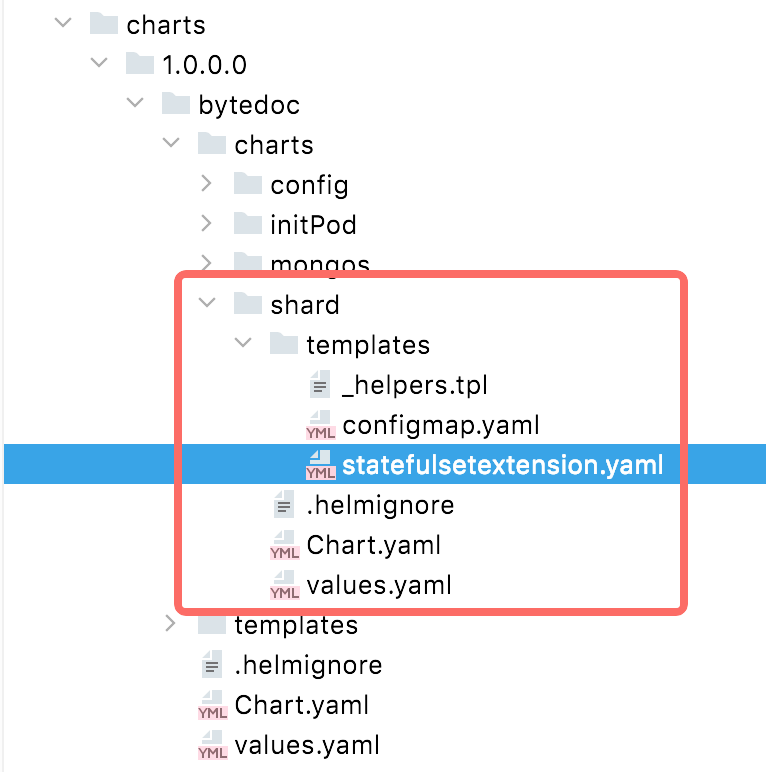
在創建資源時,利用 helm sdk,將參數渲染到 charts 模板中,生成實際的資源 yaml,接著發布到 worker K8s 集群中,operator 只需要等待資源完全 ready 就可以繼續執行變更了。
模板版本管理
另一個優雅的地方在于,此方案可以存放不同版本的 charts 模板,按版本劃分為不同的目錄;
當我們需要發布一個新版本的 charts 模板時,舊版本的服務并不會受到影響;而新創建的服務可以使用新版本的 charts 模板。
防止誤操作
引入 K8s 幫助我們交付/管理集群有很多便利之處,但實際上也是一把雙刃劍,可以不經意地誤操作多數集群,導致數據庫服務可用性受損。
可能的場景包括:
- 誤刪除集群資源對象 -> 導致服務下線
- 誤縮容實例至 0 -> 無實例提供服務
- 誤刪除 CRD -> 導致所有對應資源對象刪除,所有服務下線
Finalizers
??https://kubernetes.io/zh/docs/concepts/overview/working-with-objects/finalizers/??
這是一個 K8s 防止誤刪除原生的解決方案,它是一個標示位,任何涉及刪除的操作,都需要檢查是否存在 finalizers。
- 當 finalizer 存在時,經過 API Server 的刪除資源的請求都會被 block 住,直到 finalizer 被清除;
- 通常 finalizer 標記由對應的 operator 管理,在每次變更發生時,檢查并添加 finalizer 標記;
- 當接收到刪除請求時,判斷是否滿足刪除條件。在我們的場景下,一般需要等待 7 天的刪除冷靜期,所以如果遇到誤刪除操作,我們是有 7 天的時間進行恢復的;
實例數量縮容下限
這是一個很簡單的方案,在接收到 CR 縮容變更時,檢查其數量是否 > 0,不接受 = 0 的縮容,避免極端情況下,無可用實例的情況。
容災能力

實踐效果