一篇文章幫助小白快速入門 Spark

大家好,我是Tom哥。
互聯網時代,隨著業務數據化,數據越來越多。如何用好數據,做好數據業務化,我們需要有個利器。
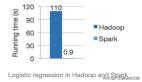
很多人都用過Hadoop,包含兩部分 HDFS 和 MapReduce,其中 MapReduce 是Hadoop的分布式計算引擎,計算過程中需要頻繁落盤,性能會弱一些。
今天,帶大家 快速熟悉一個大數據框架,Spark。
Spark 是內存計算引擎,性能更好一些。盛行自 2014年,支持 流計算 Streaming、數據分析 SQL、機器學習 MLlib、圖計算 GraphFrames 等多種場景。
語言支持很多,如 Python、Java、Scala、R 和 SQL。提供了種類豐富的開發算子,如 RDD、DataFrame、Dataset。
有了這些基礎工具,開發者就可以像搭樂高一樣,快速完成各種業務場景系統開發。
一、先來個體感
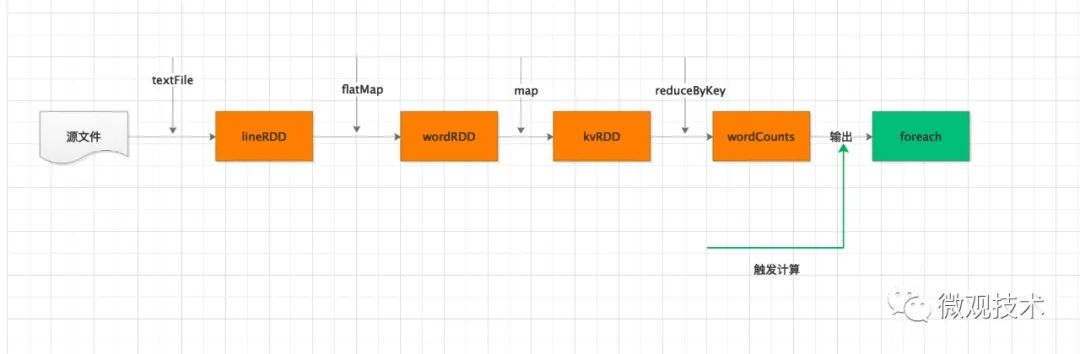
首先,我們看一個簡單的代碼示例,讓大家有個體感。
import org.apache.spark.rdd.RDD
val file: String = "/Users/onlyone/spark/demo.txt"
// 加載文件
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val kvRDD: RDD[(String, Int)] = wordRDD.map(word => (word, 1))
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
wordCounts.foreach(wordCount => println(wordCount._1 + " appeared " + wordCount._2 + " times"))
我們看到,入口代碼是從第四行的 spark 變量開始。
在 spark-shell 中 由系統自動創建,是 SparkSession 的實例化對象,可以直接使用,不需要每次自己 new 一個新對象。
SparkSession 是 Spark 程序的統一開發入口。開發一個 Spark 應用,必須先創建 SparkSession。
二、RDD
彈性分布式數據集,全稱 Resilient Distributed Datasets,是一種抽象,囊括所有內存和磁盤中的分布式數據實體,是Spark最核心的模塊和類。
RDD 中承載數據的基本單元是數據分片。在分布式計算環境中,一份完整的數據集,會按照某種規則切割成多份數據分片。這些數據分片被均勻地分發給集群內不同的計算節點和執行進程,從而實現分布式并行計算。
RDD 包含 4大屬性:
- 數據分片,partitions。
- 分片切割規則, partitioner。
- RDD 依賴關系, dependencies。
- 轉換函數,compute。
RDD 表示的是分布式數據形態,RDD 到 RDD 之間的轉換,本質上是數據形態上的轉換,這里面的一個重要角色就是算子。
三、算子
算子分為兩大類,Transformations 和 Actions。
- Transformations 算子:通過函數方法對數據從一種形態轉換為另一種形態。
- Actions 算子:收集計算結果,或者將數據物化到磁盤。

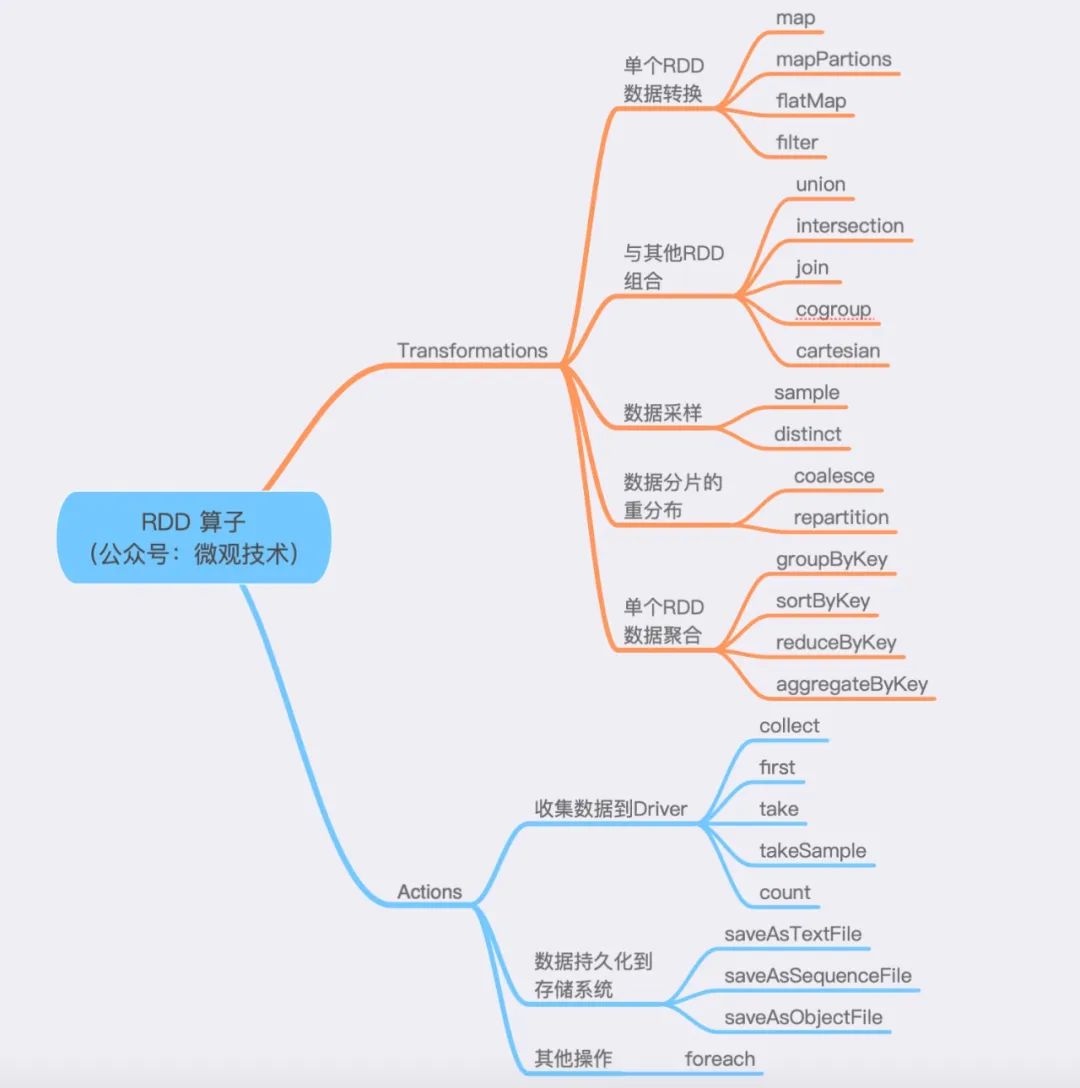
劃重點:mapPartitions 與 map 的功能類似,但是mapPartitions 算子是以數據分區為粒度初始化共享對象,比如:數據庫連接對象,S3文件句柄等。
結合上面的兩類算子,Spark 運行劃分為兩個環節:
- 不同數據形態之間的轉換,構建計算流圖 (DAG)。
- 通過 Actions 類算子,以回溯的方式去觸發執行這個計算流圖。

題外話,回溯在Java 中也有引入,比如 Stream 流也是類似機制。
一個流程可能會引入很多算子,但是他們并不會立即執行,只有當開發者調用了 Actions 算子,之前調用的轉換算子才會執行。這個也稱為 延遲計算。
延遲計算是 Spark 分布式運行機制的一大亮點。可以讓執行引擎從全局角度來優化執行流程。
四、分布式計算
Spark 應用中,程序的入口是帶有 SparkSession 的 main 函數。
SparkSession 提供了 Spark 運行時的上下文,如 調度系統、存儲系統、內存管理、RPC 通信),同時為開發者提供創建、轉換、計算分布式數據集的開發 API。
運行這個 SparkSession 的main函數的JVM進程,我們稱為 Driver。
Driver 職責:
解析用戶代碼,構建 DAG 圖,然后將計算流圖轉化為分布式任務,將任務分發給集群的 Executor 執行。定期與每個 Executor 通信,及時獲取任務的進展,從而協調整體的執行進度。
Executors 職責:
調用內部線程池,結合事先分配好的數據分片,并發地執行任務代碼。每個 Executors 負責處理 RDD 的一個數據分片子集。
分布式計算的核心是任務調度,主要是 Driver 與 Executors 之間的交互。
Driver 的任務調度依賴于 DAGScheduler、TaskScheduler 和 SchedulerBackend。
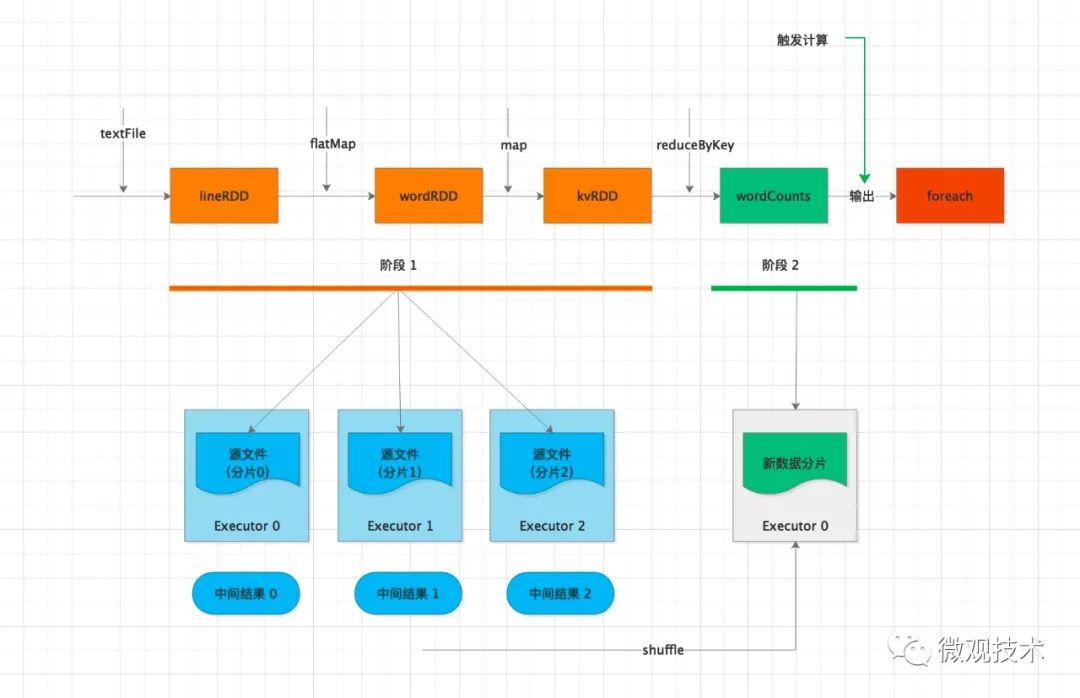
計算過程:
Driver 通過 foreach 這個 Action 算子,觸發計算流圖的執行,上圖自左向右執行,以 shuffle 為邊界,創建、分發分布式任務。
其中的 textFile、flatMap、map 三個算子合并成一份任務,分發給每一個 Executor。Executor 收到任務后,對任務進行解析,把任務拆解成 textFile、flatMap、map 3 個步驟,然后分別對自己負責的數據分片進行處理。
每個 Executor 執行完得到中間結果,然后向 Driver 匯報任務進度。接著 Driver 進行后續的聚合計算,由于數據分散在多個分片,會觸發 shuffle 操作。
shuffle 機制是將原來多個 Executor中的計算結果重新路由、分發到同一個 Executor,然后對匯總后的數據再次處理。在集群范圍內跨進程、跨節點的數據交換。可能存在網絡性能瓶頸,需要特別關注。
在不同 Executor 完成數據交換之后,Driver 分發下一個階段的任務,對單詞計數。
同一個key的數據已經分發到相同的 Executor ,每個 Executor 獨自完成計數統計。
最后,Executors 把最終的計算結果統一返回給 Driver。
劃重點:DAG 到 Stages 的拆分過程,以 Actions 算子為觸發起點,從后往前回溯 DAG,以 Shuffle 為邊界劃分 Stages。
收集結果:
收集結果,按照收集的路徑不同,主要分為兩類:
- 把計算結果從各個 Executors 收集到 Driver 端。
- 把計算結果通過 Executors 直接持久化到文件系統。如:HDFS 或 S3 分布式文件系統。
五、調度系統
1、DAGScheduler
根據用戶代碼構建 DAG,以 Shuffle 為邊界切割 Stages。每個Stage 根據 RDD中的Partition分區個數決定Task的個數,然后構建 TaskSets,然后將 TaskSets 提交給 TaskScheduler 請求調度。
2、TaskScheduler
按照任務的本地傾向性,挑選出 TaskSet 中適合調度的 Task,然后將 Task 分配到 Executor 上執行。
3、SchedulerBackend
通過ExecutorDataMap 數據結構,來記錄每一個計算節點中 Executors 的資源狀態,如 RPC 地址、主機地址、可用 CPU 核數和滿配 CPU 核數等。
4、Task
運行在Executor上的工作單元。
5、Job
SparkContext提交的具體Action操作,常和Action對應。
6、Stage
每個Job會被拆分很多組任務(task),每組任務被稱為Stage,也稱 TaskSet。
調度系統的核心思想:數據不動、代碼動。
六、內存管理
Spark 的內存分為 4 個區域,Reserved Memory、User Memory、Execution Memory 和 Storage Memory。

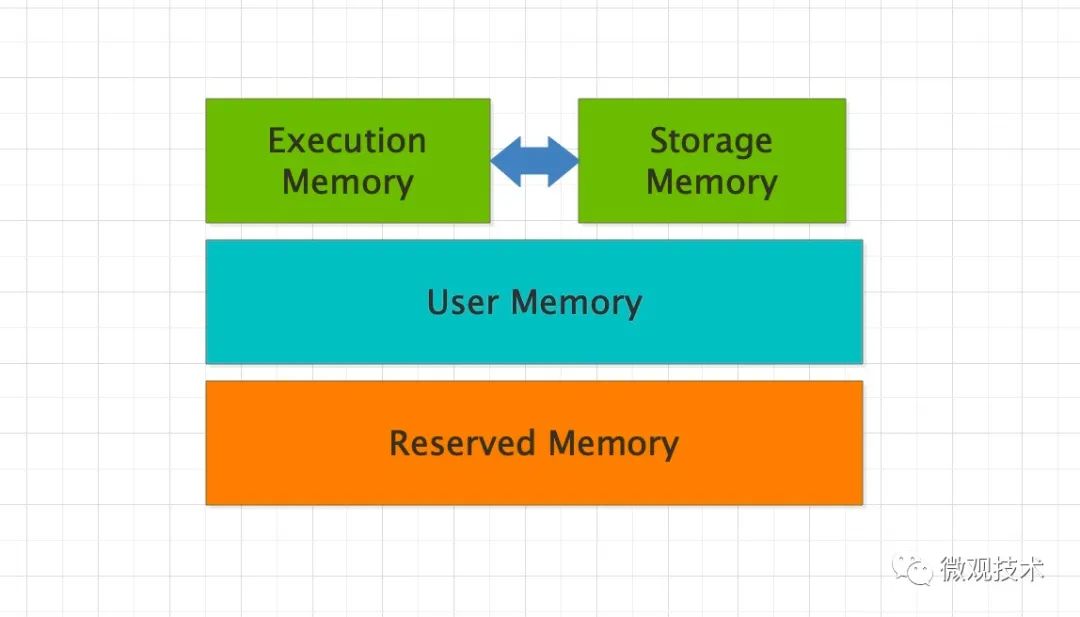
- Reserved Memory:固定為 300MB,Spark 預留的,用來存儲各種 Spark 內部對象的內存區域。
- User Memory:存儲開發者自定義的數據結構,例如 RDD 算子中引用的數組、列表、映射。
- Execution Memory:執行分布式任務。分布式任務的計算,主要包括數據的轉換、過濾、映射、排序、聚合、歸并等。
- Storage Memory:緩存分布式數據集,如 RDD Cache、廣播變量等。
整個內存區域,Execution Memory 和 Storage Memory 最重要。在 1.6 版本之后,Spark 推出了統一內存管理模式,這兩者可以相互轉化。
七、共享變量
Spark 提供兩類共享變量,分別是廣播變量(Broadcast variables)和累加器(Accumulators)。
1、廣播變量
val list: List[String] = List("Tom哥", "Spark")
// sc為SparkContext實例
val bc = sc.broadcast(list)
廣播變量的用法很簡單,通過調用 SparkContext 下的 broadcast 即可完成廣播變量的創建。
如果要讀取封裝的共享數據內容,調用它的 bc.value 函數。
好奇寶寶會問,既然 list 可以獲取字符串列表,為什么還要封裝廣播變量呢?
答案:
Driver 端對普通的共享變量的分發是以 Task 為粒度的,系統中有多少個 Task,變量就需要在網絡中分發多少次,存在巨大的內存資源浪費。
使用廣播變量后,共享變量分發的粒度以 Executors 為單位,同一個 Executor 內多個不同的 Tasks 只需訪問同一份數據拷貝即可。也就是說,變量在網絡中分發與存儲的次數,從 RDD 的分區數,減少為集群中 Executors 的個數。
2、累加器
累加器也是在 Driver 端定義,累計過程是通過在 RDD 算子中調用 add 函數為累加器計數,從而更新累加器狀態。
應用執行完畢之后,開發者在 Driver 端調用累加器的 value 函數,獲取全局計數結果。
Spark 提供了 3 種累加器,longAccumulator、doubleAccumulator 和 collectionAccumulator ,滿足不同的業務場景。