如何讓 Jupyter Notebook 自動導入代碼?

大家好,我是早起。
作為使用 Python 工作的數據科學家。每天我們都會啟動多個新的Jupyter筆記本,并且在會用到多個不同的庫,例如pandas、matplotlib等。
但是,在開始實際工作之前,我們總是需要為每一個 Notebook 寫一堆的導入代碼,雖然這不困難,但是卻很繁瑣,有時還需要查找對應的導入語句例如:
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
怎樣才能在啟動Jupyter 筆記本時自動加載這些代碼,讓我們只專注于使用這些庫?本文介紹兩種辦法。
方法一 : 修改配置文件
一個常見的方法就是通過修改Jupyter的配置文件來實現,這也是我在??之前文章中介紹過的方法??。
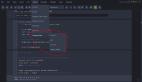
以macOS為例,你可以進入~/.ipython/profile_default文件夾(Windows下也可以在安裝目錄中找到對應的文件夾),如果找不到該目錄需在命令行執行ipython profile create生成配置文件:
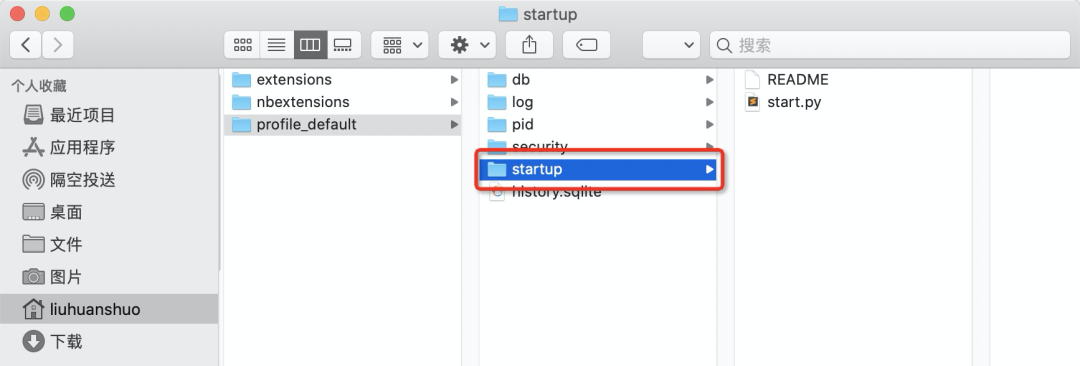
如上圖所示,在該文件夾下新建一個名為startup的文件夾(如果有則不用新建),之后進入startup文件夾新建一個Python腳本start.py,現在你可以在start.py中盡情的添加你每次啟動jupyter notebook后都需要手動敲入的那段代碼,之后保存即可:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from xgboost import XGBClassifier
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
.
現在重啟Jupyter Notebook后就可以直接使用pandas、numpy等我們配置好的庫!

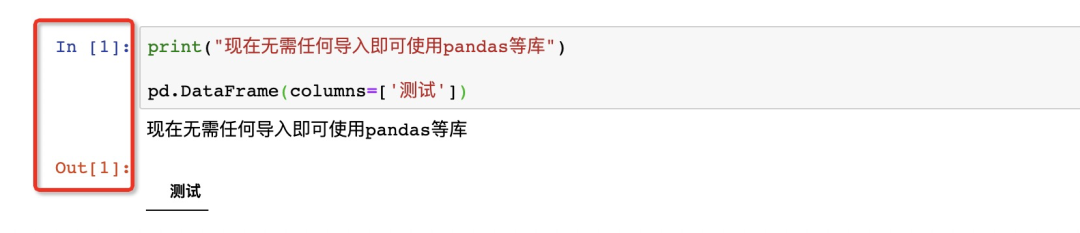
但這個方法也有一個弊端,就是由于文件缺少相關導入代碼,因此可能打包發給別人用時會無法執行,我們也不可能再次檢查所用的代碼然后手動導入一遍,所以只能在自己修改了配置文件的設備上用用。
方法二 : 使用 pyforest
這是我最近新發現的一個方法,由國外大神開發的一個插件,相比較修改配置文件,更適合小白操作。
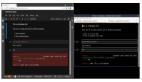
我們只需要在終端(命令行)執行以下代碼:
pip install --upgrade pyforest
python -m pyforest install_extensions
之后重啟Jupyter Notebook后便可以實現自動導入相關庫。
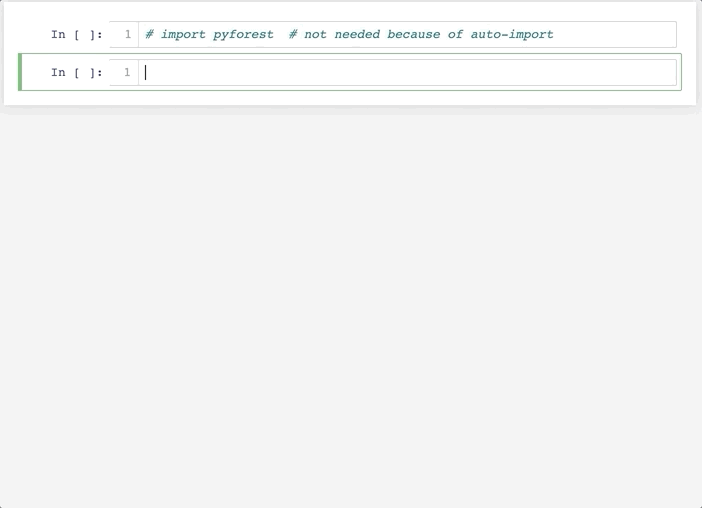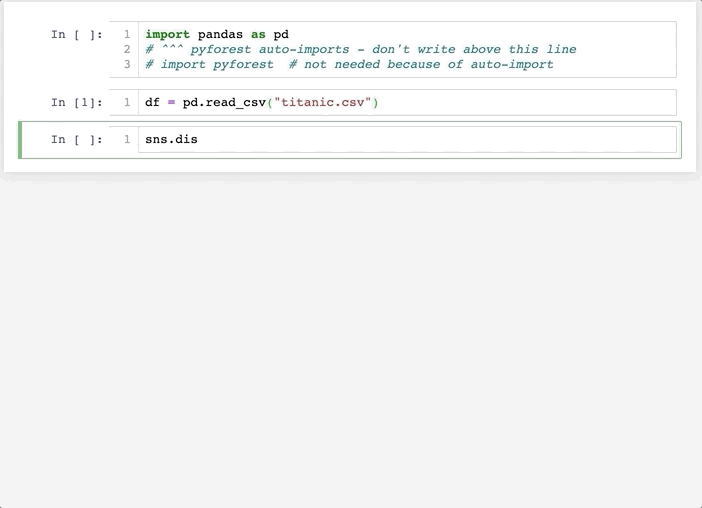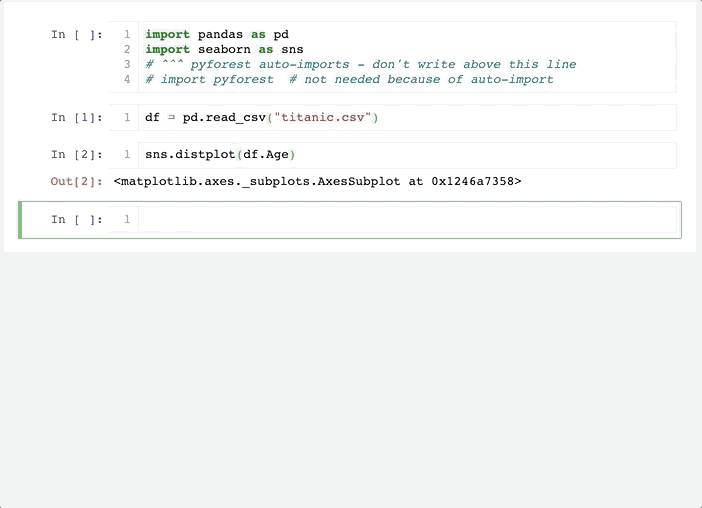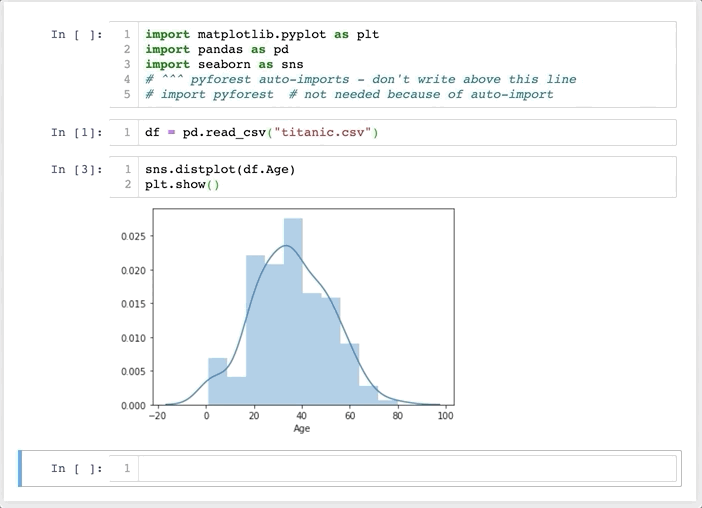
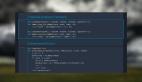
可以看到,這個方法和方法一的差別在于,他不是默認導入全部的依賴庫(避免了過多的內存占用),而是在你使用到這個庫時,自動在Notebook頭部添加對應的導入代碼,是不是很酷!
以pandas為例,當我們使用到pd.xxx便會在頭部添加import pandas as pd,而在使用它之前,變量pd只是pyforest占位符。
但使用別人配置好的缺點就是自己想額外添加一些第三方庫會比較困難,好在開發者已經預設了上百個常用庫,從數據分析到機器學習、深度學習都有,基本上不用額外設置,感興趣的話可以嘗試一下~