北大、騰訊提出文字logo生成模型,腦洞大開堪比設計師

文字標志(text logo)的設計非常依賴于設計師的創意和經驗,其中,如何安排每個文字元素的布局是一個核心問題。布局設計需要考慮到很多因素,如字形、文字語義、主題等。例如,不同的文字之間通常不能有形狀重疊;對于要強調語義的文字,通常使用較大的尺寸;斜切和旋轉等幾何變換可以分別體現力量感和歡樂感等主題。
業內現有的方案大多是設計一套易于執行的規則,按照一些預先設定好的模板來設計布局,但是生成的結果往往會比較單調且缺乏創意和美感。最近,北京大學王選計算機所和騰訊針對這個問題,提出了一種內容感知的文字標志圖像生成模型,從大量現有的文字 logo 中隱式地學習布局設計規則,從而能夠對任意輸入的字形生成新的 logo。
該工作已經被 CVPR2022 接收,相關數據集和代碼已經開源。

- 論文: https://arxiv.org/abs/2204.02701
- 數據集和代碼: https://github.com/yizhiwang96/TextLogoLayout
一、數據集
訓練 AI 模型通常需要大量的數據,然而業內尚不存在針對該任務的數據集。為了解決該問題,本文提出了 TextLogo3K 數據集,借助騰訊視頻平臺,收集、標注了 3,470 張精心挑選的文字 logo 圖,這些 logo 來源于電影、電視劇和動漫的封面圖。該數據集對字形進行了像素級別的精準標注,也標注了字形包圍框、字符類別。

圖 1 TextLogo3K 中 Logo 圖像的標注
同時,它們在原海報圖片中的位置和分割信息也一并提供:

圖 2 TextLogo3K 中海報圖像的標注
該數據集免費提供給用戶做學術研究使用(禁止任何商業用途)。除了文字 logo 生成,該數據集同樣可以應用于文本檢測和識別、藝術字體生成、紋理特效遷移、場景文字編輯等任務。
二、模型設計
2.1 流程框圖
本模型的流程框圖如下圖所示:
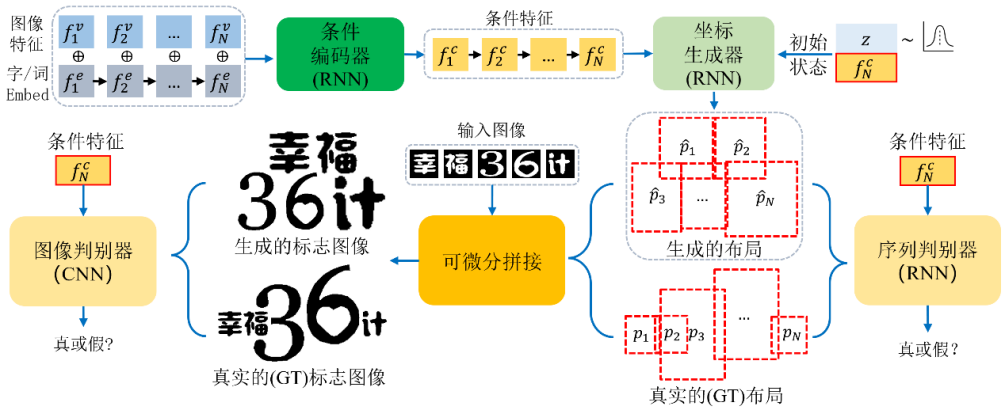
圖 3 本文模型流程框圖
本模型基于 Conditional GAN 來生成文字 logo,創新性地使用雙判別器結構(序列判別器和圖像判別器),對字形的軌跡序列和整體 logo 圖像分別做判別;同時借助可微分拼接(Differentiable Composition),構建位置坐標到 logo 圖像的可微分渲染過程。其主要的流程包括:
- 首先利用輸入元素的雙模態的特征(即字形視覺特征和文本語義特征),將其編碼成條件特征。
- 坐標生成器采用條件特征和一個隨機噪聲作為輸入, 為每個字符預測位置坐標,即字形外接框的中心點坐標,寬和高。
- 每個字符的位置坐標形成一條軌跡序列,故采用一個序列判別器去根據條件對序列和做真假判別。注意到本任務中坐標值是連續的,保證了序列判別器可以傳播梯度。
- 通過可微分拼接, 合并每個字形得到的 logo 圖像。
- 引入圖像判別器,作為序列判別器的補充,目的是進一步捕捉到標志圖像的細節信息,保證不同的字形之間不會有較大的重疊,字形間距合理等。
網絡的整體優化目標函數如下:
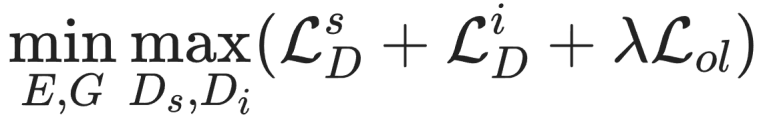
其中,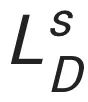 是序列判別器損失,
是序列判別器損失,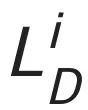 是圖像判別器損失,
是圖像判別器損失,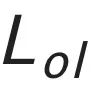 是顯式的字形重疊損失(詳情見論文)。E 代表條件編碼器,G 代表坐標生成器,
是顯式的字形重疊損失(詳情見論文)。E 代表條件編碼器,G 代表坐標生成器, 和
和 分別代碼表序列判別器和圖像判別器。其中,可微分拼接和雙判別器的具體技術細節在后續小節進一步介紹。
分別代碼表序列判別器和圖像判別器。其中,可微分拼接和雙判別器的具體技術細節在后續小節進一步介紹。
2.2 可微分拼接在獲得預測的幾何參數之后,需要進一步將每個字形圖像按照這些幾何參數拼接成一個文字 logo。更重要的是,這個拼接過程必須是可微分的,以讓整個模型可以端到端地被優化。為了達成這個目的,本文設計了一個基于 STN(Spatial Transform Networks)變種的可微分拼接方法。在原始的 STN 中,仿射變換參數是使用神經網絡直接直接預測。本文方法先預測得到了目標字形位置坐標,于是先建立原坐標到目標坐標的映射關系(下圖左),手動解出仿射變換的參數(下圖右)。通過這種方式,既可以保證目標字形的位置坐標在畫布的范圍之內,又可以利用 STN 的可微分采樣算法。

圖 4 顯式求解仿射變換參數通常來說,在文字 logo 中不同字形之間不會有重疊(有一些故意的設計除外),因此不需要考慮每個字形之間的圖層關系。將每個字形變換的圖像直接進行加法操作,即可得到 logo 圖像,結合上述步驟,可微分拼接的整體過程都是可微分的。
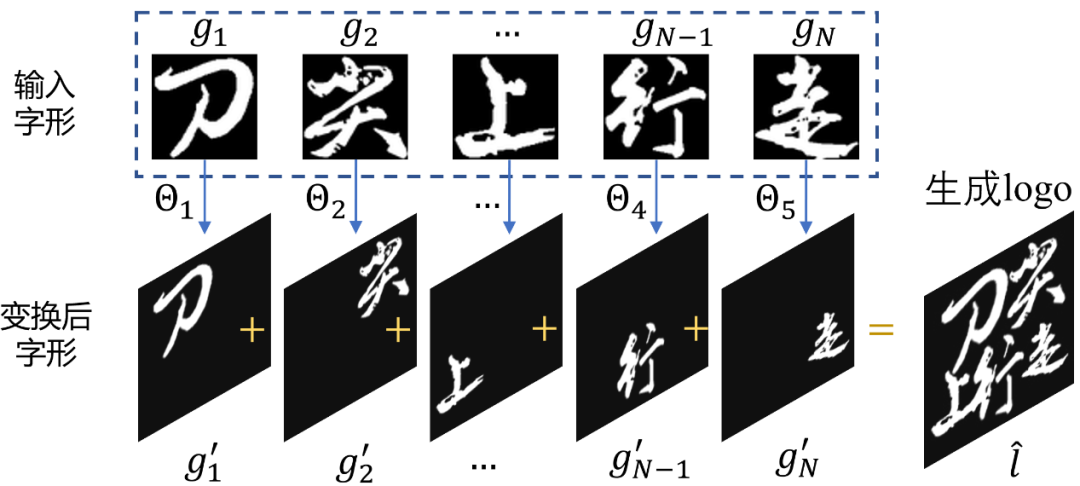
圖 5 根據求解參數合成 logo 圖像
2.3 雙判別器結構
字符的放置軌跡應該既符合人們的閱讀習慣,又呈現出多樣的風格。然而,這兩個特性不容易被圖像生成模型中常用的卷積神經網絡(CNNs)所捕獲到。為了解決這個問題,本文設計了一個雙判別器的模塊,包括一個序列判別器和一個圖像判別器。序列判別器以條件特征作為初始狀態,將幾何參數的序列作為輸入,去分析這個放置軌跡的合理性。序列判別器并不能夠捕捉到細粒度的信息(如筆畫等),因為它僅僅接收幾何參數作為輸入。于是,本模型引入圖像判別器去進一步探究 logo 圖像(人工設計的或者本模型生成的)的合理性,并預測它們的真假。根據業內的常見做法,將條件特征進行堆疊再放置到的第一個卷積層之后,用作判別條件。
三、實驗
3.1 布局生成結果展示
如圖 6 和圖 7 所示,本模型可以生成英文 logo 圖,也可以生成中文 logo。

圖 6 本模型在英文數據集上結果

圖 7 本模型在中文數據集上結果
其中,“ours”所在列表示本模型生成結果,“GT”表示設計師設計的結果。本模型生成的布局具有豐富的多樣性:
如(1)根據具體字形安排布局,如 “B + 偵探” 中,將 “+” 號巧妙地安排到 “B” 右下角和 “偵” 左下角之間;
(2)根據語義進行換行,如 “神探包青天” 和“春風十里不如你”。
3.2 與其他方法對比
本文與 2D 圖形布局生成工作 LayoutGAN(Li et al, ICLR 2018)和 layoutNet(Zheng et al, TOG 2019)進行了對比,這兩種方法沒有考慮到空間布局上的序列信息,以及輸入元素的自身本文語義信息,所以不能處理該任務。如圖 8 所示,本模型生成了更好的結果。

圖 8 與現有方法對比
3.3 布局風格分析
通過主成分分析方法(PCA),對隱空間噪聲 z 進行了可視化實驗,結果展示在圖 9 中。結果發現,(1)垂直的布局(B2, C2, H2, E3)傾向于落在平面的左邊;(2)水平的布局(A1-E1, H1, G2)傾向于落在平面的中間和上方;(3)多行的布局(A2, D2, E2, F2)傾向于落在平面的右下方;(4)不規則的布局(F1,G1)傾向落在平面的邊緣。隱空間噪聲 z 和輸入文本的長度變量是正交的。該可視化方法可以引導設計師探索布局風格的隱空間,幫助他們挑選喜歡的風格。
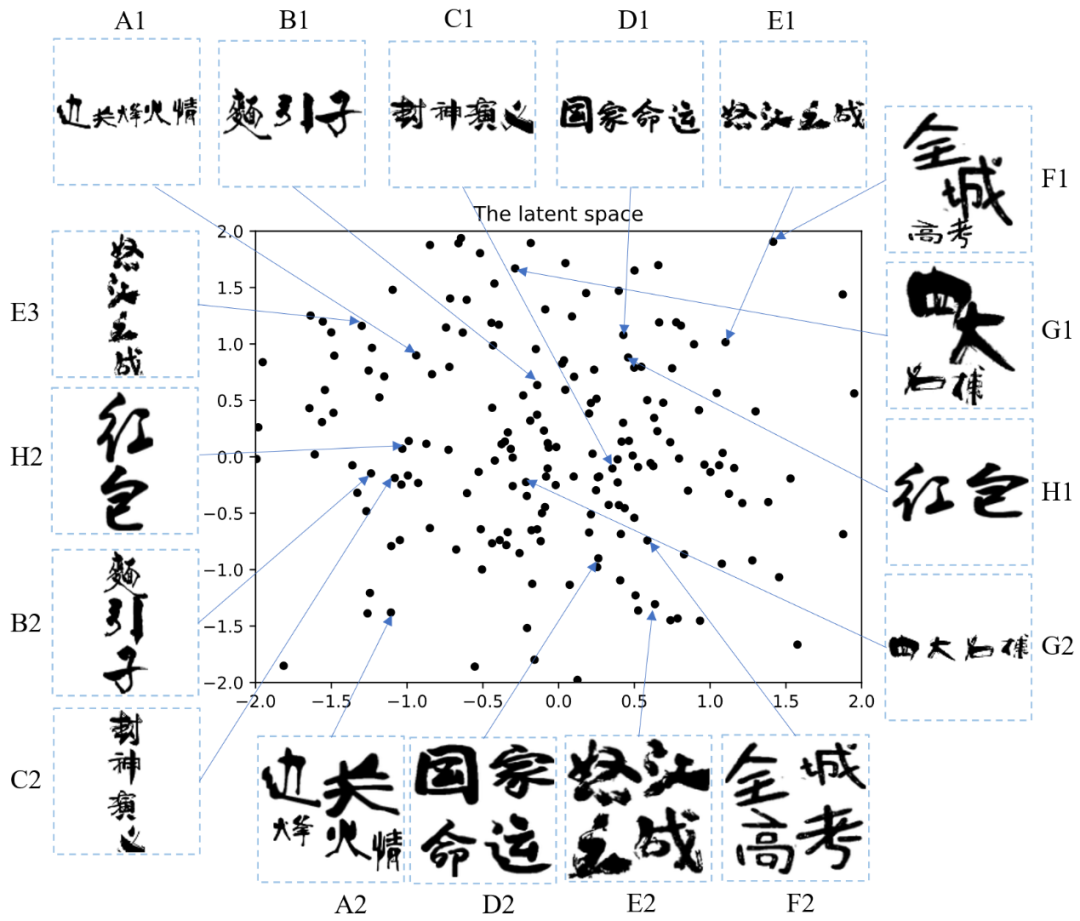
圖 9 隱空間噪聲 z 的可視化結果
3.4 主觀評價
本文開展了一項用戶調查,用于收集用戶對于本模型生成結果的主觀評價,用戶群體包括 27 個專業設計師和 52 個其他職業者。
使用了 20 對測試圖片(模型生成和人工設計的),讓用戶(1)選擇哪個是 AI 生成的:下表中的 “準確率” 表示用戶挑出本模型結果的概率,越低越好;(2)選擇自己更傾向于哪個:下表中的 “選擇率” 表示用戶選擇本模型結果的概率,越高越好;(3)給 AI 生成的質量打分(1-5):體現為下表中的“生成質量”,越高越好。
從結果可以看出本模型取得了不錯的效果,平均準確率接近 50%,平均選擇率 40%。我們也觀察到設計師群體更容易鑒別出 AI 結果,對質量要求也更苛刻,說明本工作還有進一步提升的空間。
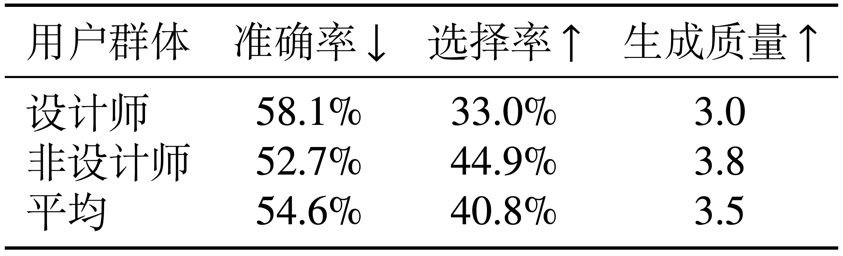
表 1 主觀調查結果
3.5 logo 圖生成系統
受字體生成模型和紋理遷移模型的啟發,本文也建立了一個全自動的文字 logo 圖生成系統。該系統首先根據用戶輸入的文本和主題生成對應的字體,接著,將合成的字形圖像和文本送到本文提出的布局生成網絡中,得到字形擺放的布局,最后使用紋理遷移模型得到修飾后的 logo 圖像。圖 10 展示了一些合成的樣例, 證明了本系統的有效性。

圖 10 logo 圖像生成系統
四、結論
本文提出了一種用于合成文字 logo 圖的布局生成模型。該模型創新性地提出了一個雙判別器的模塊,用于同時評估字符的放置軌跡和渲染后文字 logo 圖的細節信息。
同時,本文提出一種可微分拼接的方法,構建了布局參數到文字 logo 的可微分渲染過程。本文構建了一個大規模的數據集 TextLogo3K,并實施大量實驗來驗證模型的有效性,該數據同樣可以應用于其他任務。引言部分中每對 logo 圖像,左邊是 AI 生成的,右邊是人工設計的,你猜對了嗎?