













聊聊NFS為什么會Hang
昨天有個朋友咨詢一個問題,他通過NFS MOUNT了一個分布式文件系統,發現對這個文件系統df的時候經常hang死,他檢查了一番系統,發現內存使用率很高,大部分物理內存都被cache占用了。他想通過分析cache中都有哪些數據,通過這個分析來確認cache占用率高和NFS hang之間是否存在關聯關系。當時我的建議是首先不要把問題直接定位到OS內存上,如果系統不存在嚴重的SWAP,哪怕物理內存使用率達到98%,也是關系不大的。
實際上使用NFS文件系統,出現客戶端hang死,或者df命令HANG死的情況并不少見,我這些年里也遇到過多次。我遇到的NFS hang死問題的原因也十分復雜,不過大多數都與NFS BUG、網絡問題、系統資源消耗過高、IO負載過大等有關。
NFS客戶端訪問NFS文件hang住,一般來說有三種可能性,一種是客戶端出現問題,第二種是服務端出現問題,第三種是客戶端和服務端都存在問題。似乎這個總結有點太籠統了,也有點投機取巧,不過窮舉法是我們在針對未知問題分析的最重要的方法。如果我們不能窮舉所有的可能性,那么在問題診斷分析的時候就可能無法定位。在我多年的經驗里,很多當時認為十分靈異的問題,都是因為我們以前的知識面不足,無法窮舉到真正的故障路徑。
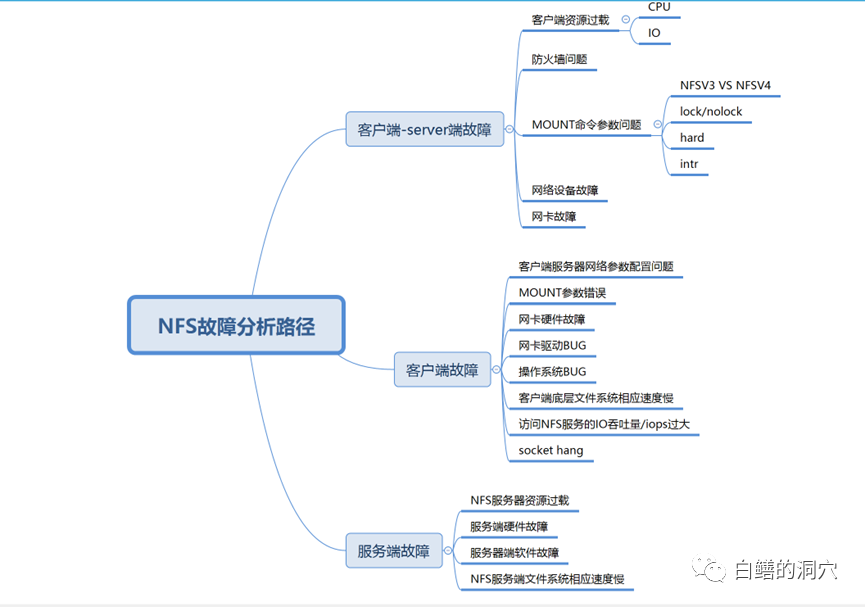
上面的思維導圖是我這些年遇到過的一些NFS HANG的情況,其中遇見最多的還是和網絡有關的,自從NFS V3/V4版本之后,NFS或者OS自身BUG導致的問題逐漸減少,而網絡方面遇到的問題逐漸變多起來。特別是防火墻問題,最近五六年里,我遇到的大型系統中的NFS問題大部分和防火墻有關。隨著企業對網絡安全的要求越來越高,防火墻也不斷地在調整策略,有時候有一條策略就會導致NFS的網絡包被防火墻過濾,從而導致NFS的故障。五六年前我遇到過一個客戶的NFS故障,只要訪問一個文件NFS就會HANG死,訪問其他文件就啥事沒有。當時實在沒辦法了只能用網絡抓包的方式去跟蹤,最后發現客戶最近上了一個敏感詞過濾的策略,因為這個文件名帶有敏感詞匯,因此網絡就丟包了。
實際上IP存儲專網建設十分重要,關鍵系統使用NFS的時候一定要使用IP存儲專網,最好不要經過防火墻,不過很多大企業對于跨機房訪問的網絡安全管理十分變態,防火墻是必須要經過的,一個NFS訪問經過至少兩個防火墻,一旦網絡安全管理員與存儲管理員之間沒有很好的溝通,那么因為防火墻導致的NFS問題那就少不了了。另外我們以前遇到的大多數NFS故障場景都沒有使用IPSAN專網,NFS使用的網絡是和業務網混合使用的,業務網出現的任何問題,都會引起NFS文件系統的抖動,從而導致NFS服務不穩定。
是否Socket hang的問題可以通過netstat命令來看是不是存在大量的TCP連接處于CLOSEWAIT狀態,如果存在這種情況,那么很可能你遇到了socket hang。Socket hang大多數和IO負載過高、客戶端或者服務器端OS相應慢或者某個OS bug有關。也可能和TCP的keepalive參數設置有關。
另外一點是我們是用NFS的環境中,可能還安裝了數據庫服務器、中間件服務器等,這些系統要求調整OS的網絡參數,而這些參數的調整很可能并不適合NFS服務。其中常見存在沖突的幾個參數如下:
- lnet.ipv4.tcp_keepalive_time
- lnet.ipv4.tcp_keepalive_intvl
- lnet.ipv4.tcp_keepalive_probes
- lnet.ipv4.tcp_tw_recycle = 0
- lnet.ipv4.tcp_tw_reuse = 0
- lnet.ipv4.tcp_retries1 = 3
- lnet.ipv4.tcp_retries2 = 15
實際上NFS HANG的問題分析因為涉及的原因很多,所以往往還是不容易定位的,不過如果df命令hang,而且是可重現的,那么分析起來還是有方法的。最好的防范就是使用strace去跟蹤df命令的堆棧。看看hang在什么地方,就比較容易定位問題了。
最后要說明的是,messages日志是一定要首要分析的,不管是客戶端還是服務端的messages日志都應該盡早去看。雖然說很可能我們看到的只是NFS命令超時這類的比較籠統的信息。





















