













聊聊為什么MySQL索引使用B+樹

聚簇索引與非聚簇索引
不同的存儲引擎,數據文件和索引文件位置是不同的,但是都是在磁盤上而不是內存上,根據索引文件、數據文件是否放在一起而有了分類:
聚簇索引:數據文件和索引文件放在一起,例如:innodb。
每一個數據庫在磁盤上都會有一個對應的文件:
進去其中一個文件夾:
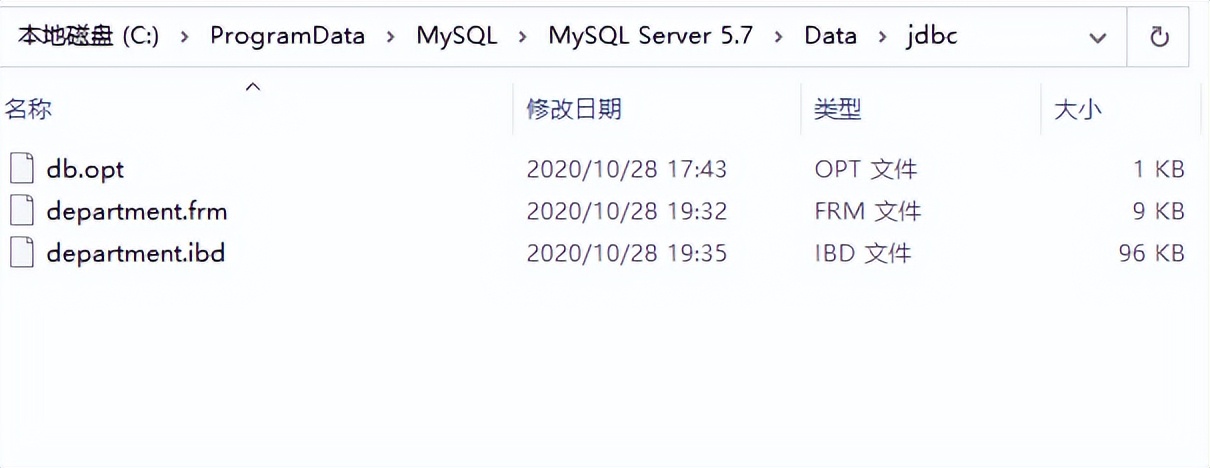
這其中:
- frm:存儲的是表結構。
- ibd:存儲數據文件和索引文件。
注意:mysql的innodb默認會將數據文件以及索引文件放在表格空間中,不會為每一個單獨的表保存一份數據文件,如果需要單獨保存,那么要將 innodb_file_per_table 設置為on。
非聚簇索引:數據和索引文件各自分開存放,例如:MyISAM
- frm 存儲表結構。
- MYI存儲索引數據。
- MYD 存儲實際數據。
索引備選存儲結構
- 哈希表。
- 二叉樹。
- B樹。
- B+樹。
HashMap(散列表)
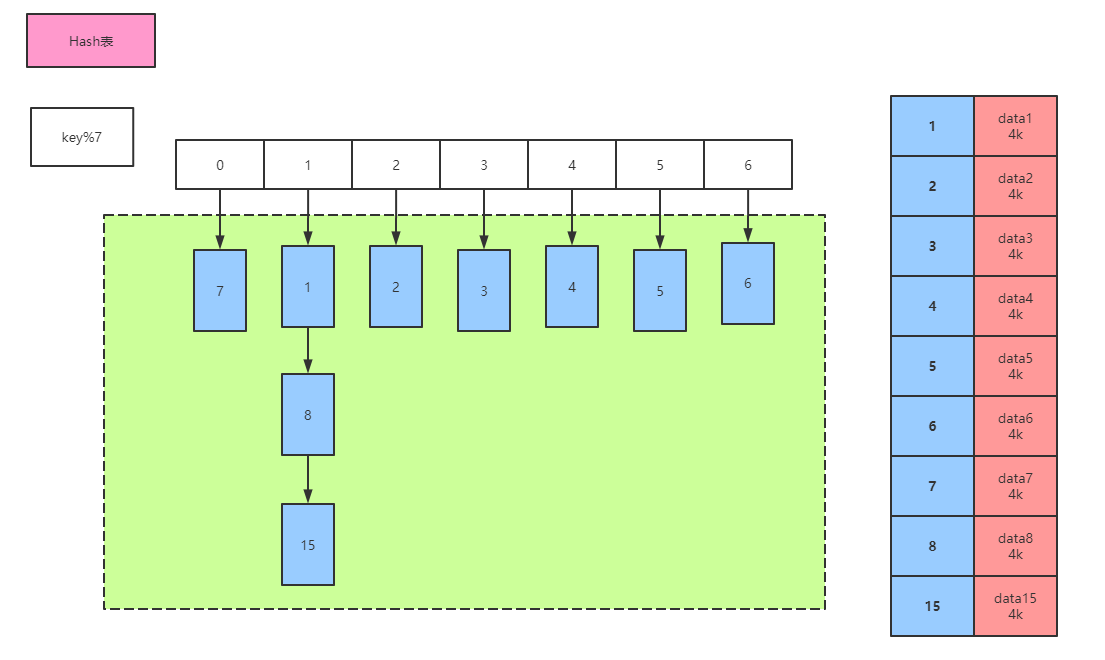
哈希表可以完成索引的存儲,每次添加索引需要計算指定列的hash值,取模運算后計算出下標,將元素插入下標位,使用場景:等值查詢,但是表格中的數據是無序數據(范圍查找比較消耗時間,需要進行遍歷操作),在企業中查詢更多是范圍查詢,不合適.另外,Hashmap作為索引的時候,需要全部加載到內存,消耗內存空間。于是考慮樹結構.
HashMap索引的限制:
- 哈希索引只包含哈希值和行指針,而不存儲字段值,所以不能使用索引中的值來避免讀取行。
- 哈希索引數據并不是按照索引值順序存儲的,所以也就無法用于排序。
- 哈希索引也不支持部分索引列匹配查找,因為哈希索引始終是使用索引列的全部內容來計算哈希值的。
- 哈希索引只支持等值比較查詢,包括=、IN()、<>(注意<>和<=>是不同的操作)。也不支持任何范圍查詢,例如WHERE price>100。
- 訪問哈希索引的數據非常快,除非有很多哈希沖突(不同的索引列值卻有相同的哈希值)。當出現哈希沖突的時候,存儲引擎必須遍歷鏈表中所有的行指針,逐行進行比較,直到找到所有符合條件的行。
- 如果哈希沖突很多的話,一些索引維護操作的代價也會很高。例如,如果在某個選擇性很低(哈希沖突很多)的列上建立哈希索引,那么當從表中刪除一行時,存儲引擎需要遍歷對應哈希值的鏈表中的每一行,找到并刪除對應行的引用,沖突越多,代價越大。
樹的發展緣由

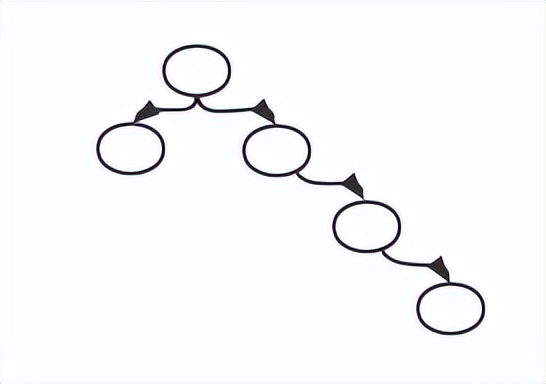
計算機領域的樹的特點是左子樹小于根節點,右子樹大于根節點,從左到右是有序的,多叉樹查找效率比較低,后來有了二叉樹,二叉樹接近二分查找(時間復雜度),但是會出現下面這種情況,變成了查詢時間復雜度高的鏈表查詢:
于是有了 平衡樹(AVL樹,要求左右結點高度差不大于于1),也就是插入數據之后,會自旋調整變成平衡樹,但是旋轉會影響插入的性能,也就是如果查詢多但是插入少的話可以用AVL樹,但是插入多的話就不適合,為了優化插入的時間復雜度,產生了紅黑樹,紅黑樹左右子節點高度差不超過一倍即可(例如左子樹高度4,那么右子樹高度可以是8),但是紅黑樹問題是:由于允許子樹高度差超過一倍,可能出現由于樹的深度過大而造成磁盤IO讀寫過于頻繁,進而導致效率低下的情況。
為什么會出現這樣的情況,我們知道要獲取磁盤上數據,必須先通過磁盤移動臂移動到數據所在的柱面,然后找到指定盤面,接著旋轉盤面找到數據所在的磁道,最后對數據進行讀寫。磁盤IO代價主要花費在查找所需的柱面上,樹的深度過大會造成磁盤IO頻繁讀寫。根據磁盤查找存取的次數往往由樹的高度所決定,所以,只要我們通過某種較好的樹結構減少樹的結構盡量減少樹的高度,B樹可以有多個子女,從幾十到上千,可以降低樹的高度。
接下來考慮B樹(B-樹)。
B樹
B樹特點是,結點(非葉子結點)有可變數量的子節點(事先設定好),在一個節點中需要設置鍵值,因為子節點數量有一定的允許范圍,所以B樹不需要像其他自平衡查找樹那樣頻繁地重新保持平衡,B樹示意圖:
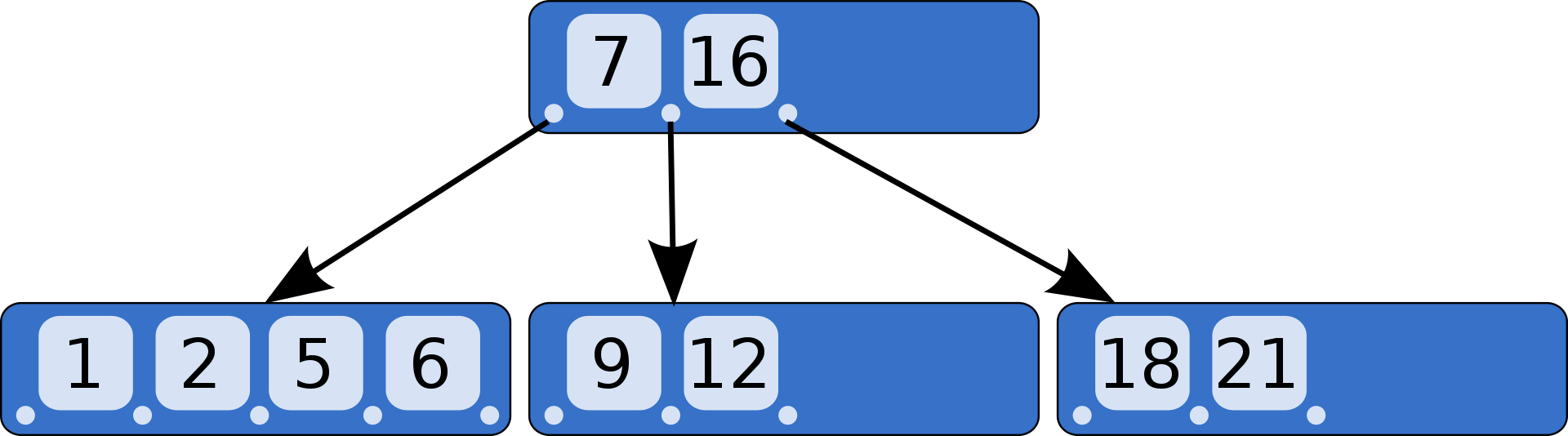
B樹特點:
1、所有鍵值分布在整顆樹中。
2、搜索有可能在非葉子結點結束,在關鍵字全集內做一次查找,性能逼近二分查找。
3、每個節點最多擁有m個子樹,最多有m-1個鍵值。
4、根節點至少有2個子樹。
5、分支節點至少擁有m/2顆子樹(除根節點和葉子節點外都是分支節點)。
6、所有葉子節點都在同一層、每個節點最多可以有m-1個key,并且以升序排列。
B樹鍵值攜帶數據
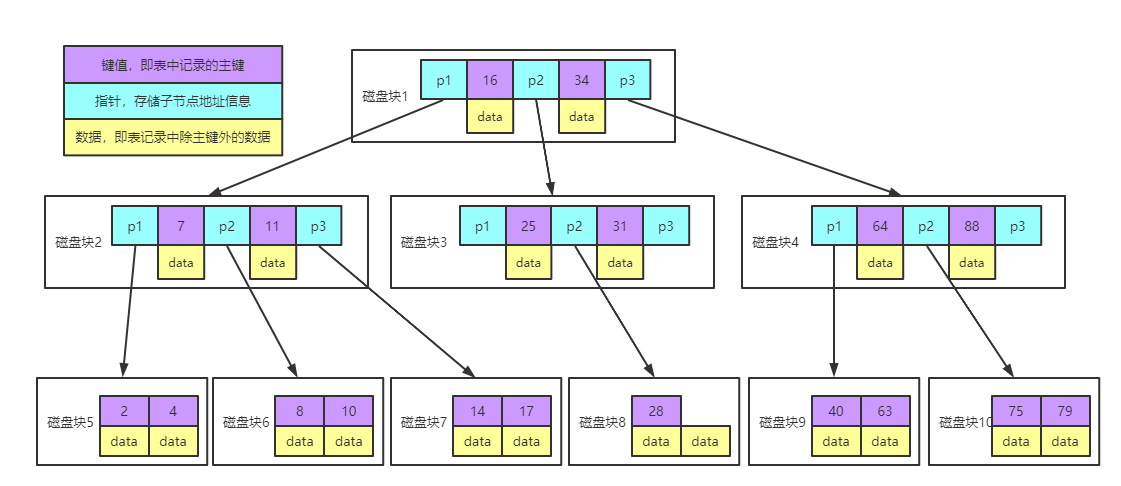
實例圖說明:
每個節點占用一個磁盤塊,一個節點上有兩個升序排序的關鍵字和三個指向子樹根節點的指針,指針存儲的是子節點所在磁盤塊的地址。兩個關鍵詞劃分成的三個范圍域對應三個指針指向的子樹的數據的范圍域。以根節點為例,關鍵字為 16 和 34,P1 指針指向的子樹的數據范圍為小于 16,P2 指針指向的子樹的數據范圍為 16~34,P3 指針指向的子樹的數據范圍為大于 34。
查找關鍵字過程:
1、根據根節點找到磁盤塊 1,讀入內存。【磁盤 I/O 操作第 1 次】。
2、比較關鍵字 28 在區間(16,34),找到磁盤塊 1 的指針 P2。
3、根據 P2 指針找到磁盤塊 3,讀入內存。【磁盤 I/O 操作第 2 次】。
4、比較關鍵字 28 在區間(25,31),找到磁盤塊 3 的指針 P2。
5、根據 P2 指針找到磁盤塊 8,讀入內存。【磁盤 I/O 操作第 3 次】。
6、在磁盤塊 8 中的關鍵字列表中找到關鍵字 28。
缺點:
1、每個節點都有key,同時也包含data,而每個頁存儲空間是有限的,如果data比較大的話會導致每個節點存儲的key數量變小
2、當存儲的數據量很大的時候會導致深度較大,增大查詢時磁盤io次數,進而影響查詢性能
B+樹
特點:
B+樹與B樹類似,但只有葉節點存放數據,其余節點用來索引,B-樹是每個索引節點都會有Data域.B-樹/B+樹的特點就是每層節點數目非常多,層數很少,目的就是為了就少磁盤IO次數,B-樹的每個節點都有data域(指針),這無疑增大了節點大小,說白了增加了磁盤IO次數(磁盤IO一次讀出的數據量大小是固定的,單個數據變大,每次讀出的就少,IO次數增多,一次IO多耗時),而B+樹除了葉子節點其它節點并不存儲數據,節點小,磁盤IO次數就少。這是優點之一。
另一個優點是: B+樹所有的Data域在葉子節點,一般來說都會進行一個優化,就是將所有的葉子節點用指針串起來。這樣遍歷葉子節點就能獲得全部數據,這樣就能進行區間訪問啦。在數據庫中基于范圍的查詢是非常頻繁的,而B樹不支持這樣的遍歷操作。
圖示:
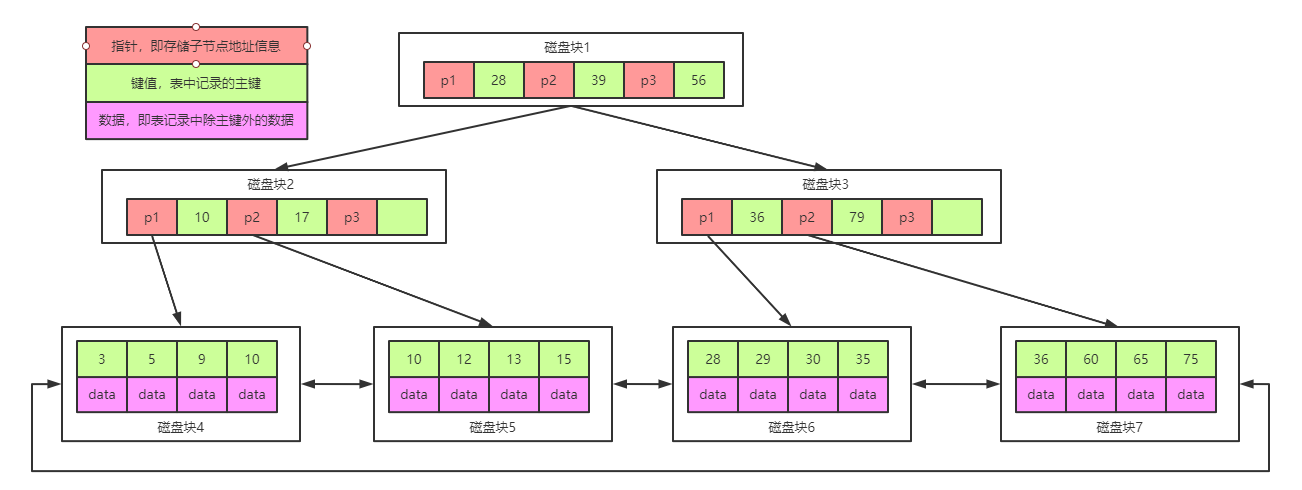
B+Tree是在BTree的基礎之上做的一種優化,變化如下:
1、B+Tree每個節點可以包含更多的節點,這個做的原因有兩個,第一個原因是為了降低樹的高度,第二個原因是將數據范圍變為多個區間,區間越多,數據檢索越快
2、非葉子節點存儲key,葉子節點存儲key和數據
3、葉子節點兩兩指針相互連接(符合磁盤的預讀特性),順序查詢性能更高
注意:在B+Tree上有兩個頭指針,一個指向根節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即數據節點)之間是一種鏈式環結構。因此可以對 B+Tree 進行兩種查找運算:一種是對于主鍵的范圍查找和分頁查找,另一種是從根節點開始,進行隨機查找。
1、InnoDB是通過B+Tree結構對主鍵創建索引,然后葉子節點中存儲記錄,如果沒有主鍵,那么會選擇唯一鍵,如果沒有唯一鍵,那么會生成一個6位的row_id來作為主鍵。
2、如果創建索引的鍵是其他字段,那么在葉子節點中存儲的是該記錄的主鍵,然后再通過主鍵索引找到對應的記錄,叫做回表。


















