作者 | 開發套件團隊
基于字節跳動分布式治理的理念,數據平臺數據治理團隊自研了 SLA 保障平臺,目前已在字節內部得到廣泛使用,并支持了絕大部分數據團隊的 SLA 治理需求,每天保障的 SLA 鏈路數量過千,解決了數據 SLA 難對齊、難保障、難管理的問題。
一、背景介紹
SLA(Service Level Agreement):服務級別協議,對互聯網公司來說是網站服務可用性的保證。數據 SLA,即數據可用性保證,一般以數據產出時間作為 SLA。
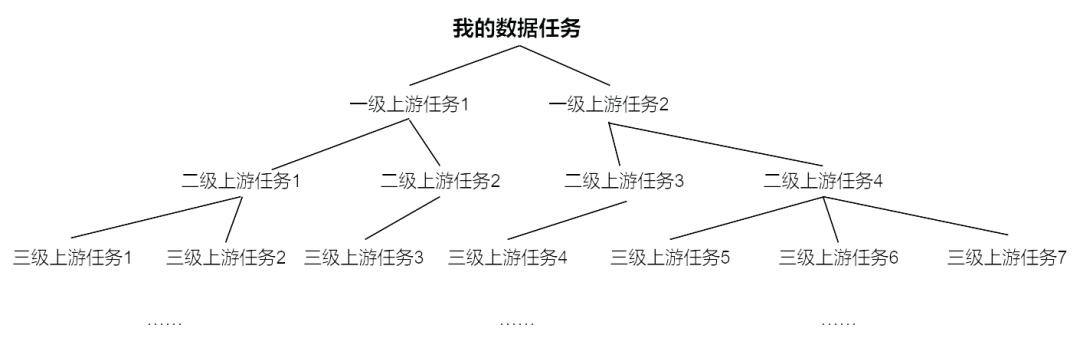
在海量數據任務開發場景中,因業務多樣化、數據量大、數據任務復雜等問題,導致數據任務鏈路依賴復雜、鏈路長、跨團隊節點依賴多,因此,在實際開發運維過程中,任務負責人為保證自身數據準時產出,會遇到如下困難:
- 溝通成本高:任務負責人嘗試與上游任務負責人約定 SLA,但由于上游任務數多(可至上千個),且跨越多個團隊,溝通成本非常高
- 權責不清晰:由于鏈路復雜,如何制定 SLA?誰來負責保障 SLA?
- 運維壓力大:無法及時發現上游任務延遲,導致下游任務負責人承擔絕大部分運維壓力,且運維效果較差,往往發現延遲已經錯過了補救的時間。
為解決上述問題,字節跳動數據平臺通過自研的 SLA 保障平臺,規范并推進各業務團隊進行任務鏈路治理,有效保障數據的 SLA,數據 SLA 達標率達到 99.1%。
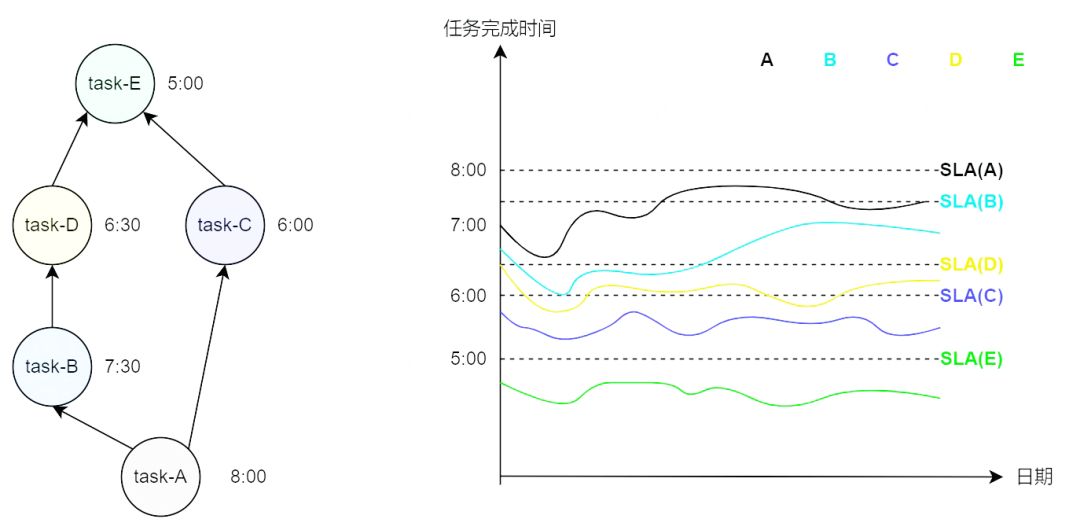
理想的一組任務的完成時間與對應 SLA 之間的關系如下圖所示,即各個任務及其上游任務都在對應的 SLA 之前完成,這也是平臺的治理目標。
二、應用場景
SLA 保障平臺除了解決上文的困難外,對不同的用戶還有以下使用場景:
- 數據業務方:“我們團隊的業務很依賴一份重要數據,希望能對其進行保障,希望上游能承諾 SLA”
- 數據負責人:“我們團隊有很多對外承諾 SLA 的數據,希望能有一個平臺對 SLA 進行集中管理,并能提供一些統計大盤、風險分析等內容”
- 數據治理方:“我們希望能提升團隊內核心數據的數據質量,對齊進行 SLA 管理,及時發現風險,并進行事故復盤和改進,最終不斷優化數據質量”
根據以上不同角色需求,SLA 保障平臺提出自身解決方案。針對團隊數據治理需求,平臺提供完善的治理看板能力;針對任務鏈路復雜導致的 SLA 難達成,平臺通過各項優化,簡化了 SLA 達成流程;針對下游任務運維壓力大的問題,平臺優化通知體系,及時播報 SLA 狀態。
那么,SLA 保障平臺有哪些核心模塊?平臺是如何運轉的呢?
三、核心概念介紹
3.1 角色:
目前 SLA 保障平臺的核心角色有三類,分別是:
- 申報人:即 SLA 提申報的人,一般是數據業務方,其提申報的目的是保障業務數據的 SLA;
- 管理員:滿足數據治理方的需求設置的角色,負責申報的審核、批準、管理、統計、登記、復盤等,其目的是不斷優化所屬團隊的數據質量。
- 任務負責人:即待保障 SLA 數據鏈路中的任務 owner,負責確定及簽署所負責任務的 SLA,平臺會按照其簽署的 SLA 進行保障;
3.2 任務:
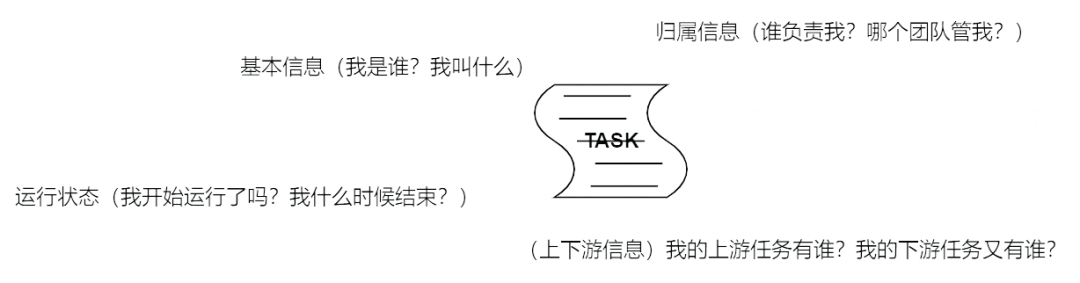
即產出數據的任務,通過數據任務的元信息,可構建整條數據生產鏈路的完整 DAG。在本平臺中,所涉及的任務元信息一般需要包含以下內容:
3.3 申報單
申報人提起的一次申報內容,被稱為一個“申報單”,一個申報單一般包含的核心內容如下:

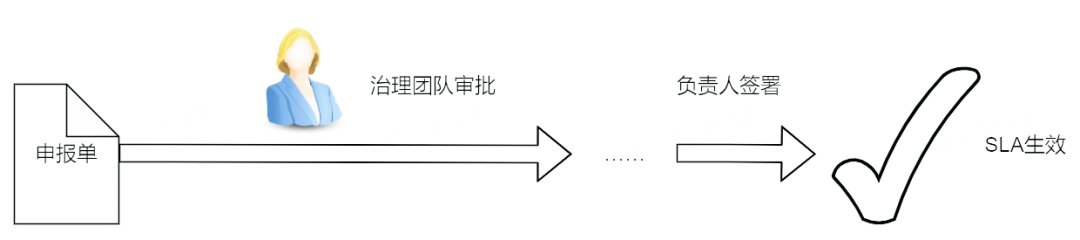
四、申報簽署流程詳解
SLA 保障的前提是先達成 SLA 協議。在 SLA 保障平臺中,以申報單簽署的形式達成 SLA 協議。平臺核心特點是優化了 SLA 達成的流程,先通過 “系統卡點計算” 減少待簽署任務的數量,再通過 “SLA 推薦計算” 自動簽署部分任務,最后為剩下的待簽署任務智能提供合適的 SLA,進一步降低簽署成本。
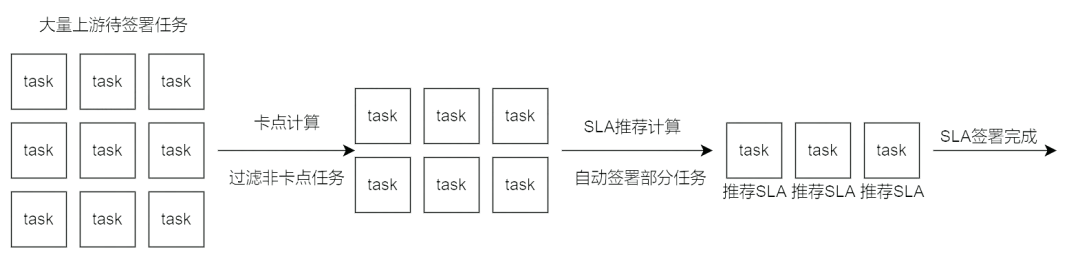
在申報簽署環節中,各個環節的變化將通過通知模塊傳遞信息給相應負責人,實時通知降低信息交流成本,加速了 SLA 的達成。
4.1 流程簡介

上圖為申報簽署的一般流程,在實際操作時,如任務鏈路變化、SLA 時間商討待確認等特殊情況,申報簽署流程會有微調。
首先需要申報人填寫申報單,在申報人提交后,系統會根據申報單中的申報任務拉取上游的所有任務,構成一個完整的 DAG,并進行任務鏈路分析。鏈路分析的結果是后續算法的前提,也是管理員審批時的重要參考因素,可以讓用戶快速了解到自身任務在鏈路中所處的位置及上下游運行情況。
在理想情況下,為保證申報任務順利推進,需要該任務的所有上游任務都簽署 SLA 才算完成簽署。而鏈路復雜導致的上游任務多、跨團隊溝通成本高、SLA 難以確定等問題,成了整體 SLA 達成的最大阻礙。通過“卡點計算”與“SLA 推薦計算”可以跨越此阻礙。
4.2 卡點計算
本系統采取一定的“卡點策略”,計算出此 DAG 中的部分需要被簽署的任務,此類任務稱為“卡點任務”,這個過程稱之為“卡點計算”。計算得到卡點任務后,在簽署過程中可以忽略其他任務,從而大大降低簽署成本。
一個申報單會關聯多個任務(即該申報任務及其上游的卡點任務),同理一個任務也會關聯多個申報單,因為在一個 DAG 中,申報任務可能從任意節點起,因此二者是 N:N 的關系。
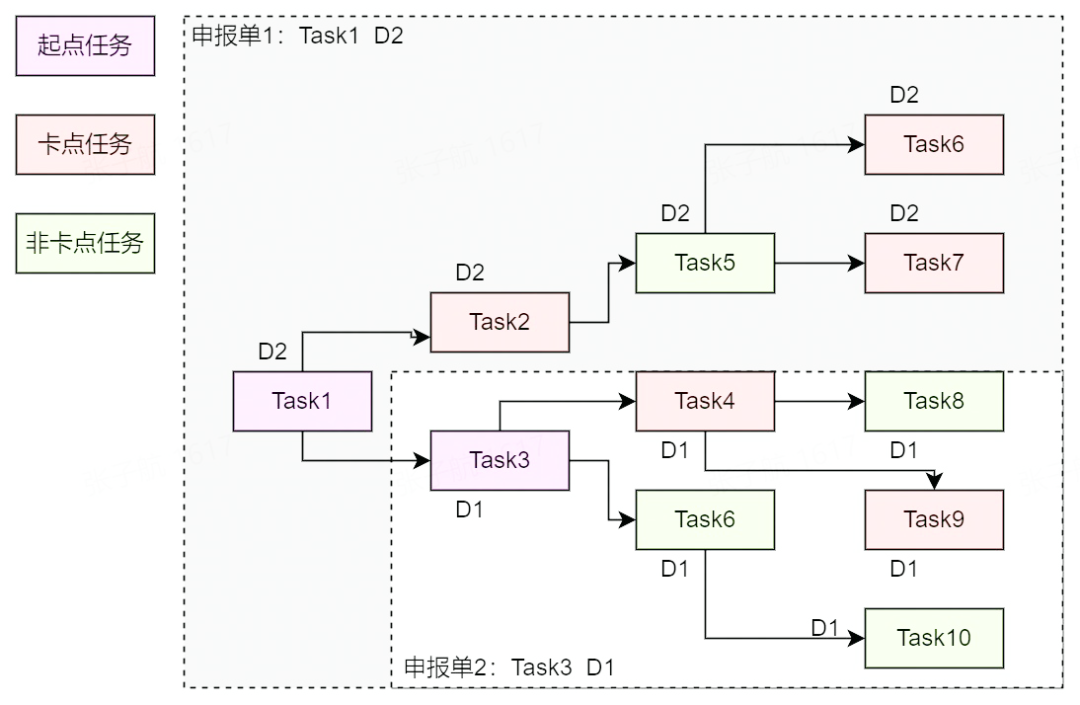
當兩個申報單有部分任務列表重合時,如 Task4 關聯了兩個申報單,該任務的申報方、治理團隊等數據是兩個申報單的去重合集,而等級則取所有申報單中最高者。
4.3 SLA 推薦計算
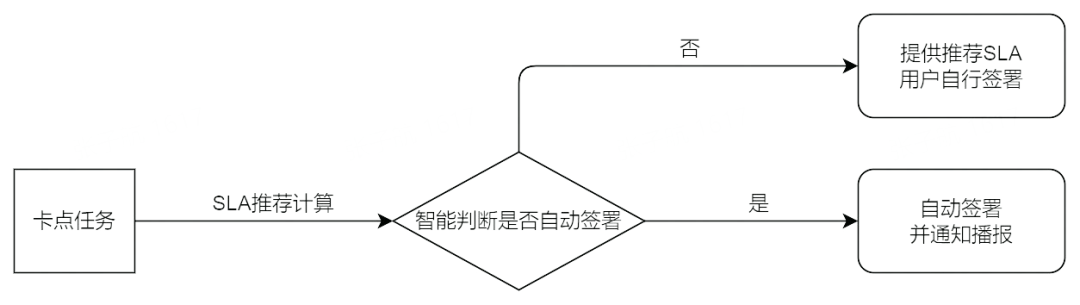
利用任務及其上下游任務的歷史運行信息,再結合推薦算法,得到該任務的推薦 SLA,這個過程稱之為SLA 推薦計算。
在負責人簽署 SLA 之前,SLA 推薦算法會智能計算每個任務的推薦的 SLA,并以此進一步通過算法自動簽署部分待簽署的任務,進一步降低簽署成本。據平臺數據統計,此功能可以自動簽署近40% 的 SLA,是最核心的功能之一。
而對于剩余的待簽署任務,會將算法推薦的 SLA 提供給任務負責人。任務負責人可以直接選擇直接用這個 SLA 簽署,也可以自行決定 SLA。一般情況下,智能推薦的 SLA 已經能滿足絕大多數的需求,通過推薦 SLA,任務負責人更快的做出簽署決定,再次降低了簽署成本。
4.4 系統保障監控
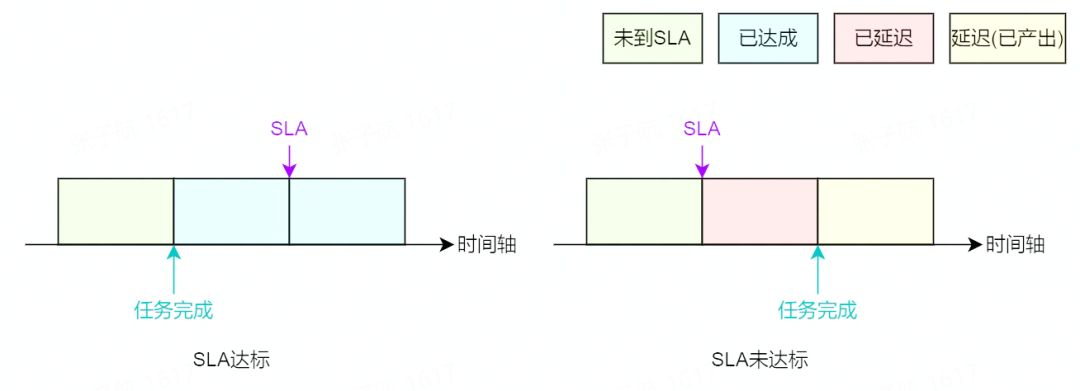
當一個申報單完成簽署之后,平臺將對申報單中的任務進行保障服務。保障服務的核心就是通過監控 SLA 的狀態變化及時播報消息通知,為相應負責人及時提供一手資料,以此降低運維成本。對于一個離線任務,評價其 SLA 主要是依據其完成時間和其所承諾的 SLA 來判斷,SLA 的狀態分為四種,分別是:
- 未到 SLA:即當前時間,任務未產出,且還未到 SLA 時間(繼續監控);
- 已達成:即任務已完成,且完成時間在所承諾的 SLA 之前(發送就緒通知);
- 已延遲:即任務未完成,且當前時間已在所承諾的 SLA 之后(發送延遲通知);
已延遲(產出):即任務已完成,但完成時間在所承諾的 SLA 之后(發送延遲產出通知);
從下圖可以看到在任務達成、未達成兩種情況下,隨著時間的推移,其 SLA 狀態的變化。
SLA 的實時狀態是數據業務方所需要的重要信息,因此平臺會所有任務的 SLA 進行監控,并在 SLA 狀態變化時實時對相關人員發送通知,相關人員根據收到的通知知曉 SLA 的具體情況,并能做出應對措施。
五、復盤管理詳解
復盤管理是本平臺提供的響應式治理服務的實現方式,是數據治理方的重點關注對象。復盤管理又分為問題管理與事故管理,問題管理側重于“為什么”——即整理分析 SLA 破線的原因,事故管理側重于“怎么做”——即 SLA 破線事故之后該怎么治理。
5.1 問題管理
問題管理模塊的整體目標是滿足數據治理團隊對 SLA 問題的登記管理,支持對登記后的問題數據進行不同維度根因數據分析,輔助用戶對問題根因進行治理,沉淀治理問題經驗。
平臺在進行系統保障監控時,會在 SLA 延遲時進行通知播報,并持續提醒負責人進行問題登記。在問題登記時,平臺提供了一組根因樹輔助登記,明確問題根因類別,方便統計分析。任務負責人進行問題登記后,累積數據展示在問題看板上,數據治理方由此做問題分析歸納總結。
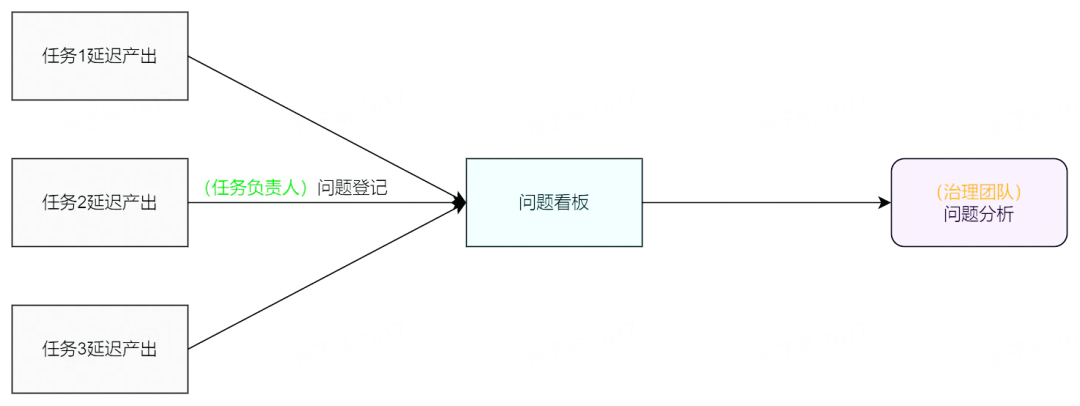
平臺保證了 SLA 延遲記錄與問題之間是一一對應的關系,并在問題看板上關聯了 SLA 詳情信息,包括任務鏈路、負責人、任務起止時間等。
問題登記往往是一個從多到少的過程,前期出現的問題在逐一治理解決后,將對后期的治理起到很好的參考警示作用,它的數據價值如下:
- 不同 SLA 問題類型的趨勢分布,針對性的治理問題
- 相同根因引發了多少 SLA 問題,涉及影響多少數據資產
- 哪些數據資產經常出現 SLA 問題,問題的分類以及是什么根因造成的
- SLA 問題經驗總結,方便類似問題發生后,后期做推薦輔助快速定位根因
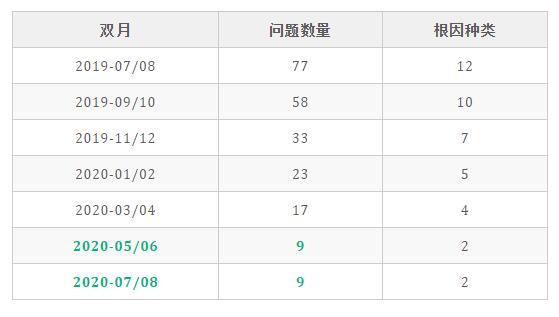
根據平臺運營的記錄顯示,常見的問題有資源隊列阻塞、上游任務故障、數據傾斜等。某數據團隊雙月問題登記總結如下,問題數量和問題根因種類得到了有效的收斂:
5.2 事故管理
事故管理用于記錄 SLA 破線事故的復盤與改進管理,每個事故至少對應一條 SLA 問題記錄,而每個 SLA 問題不一定會造成事故。
事故可以在任意節點進行,一般在 SLA 破線并造成實際的業務影響之后,需要進行事故登記,事故登記同樣會關聯相關的 SLA 信息。一個事故的處理流程如下所示:
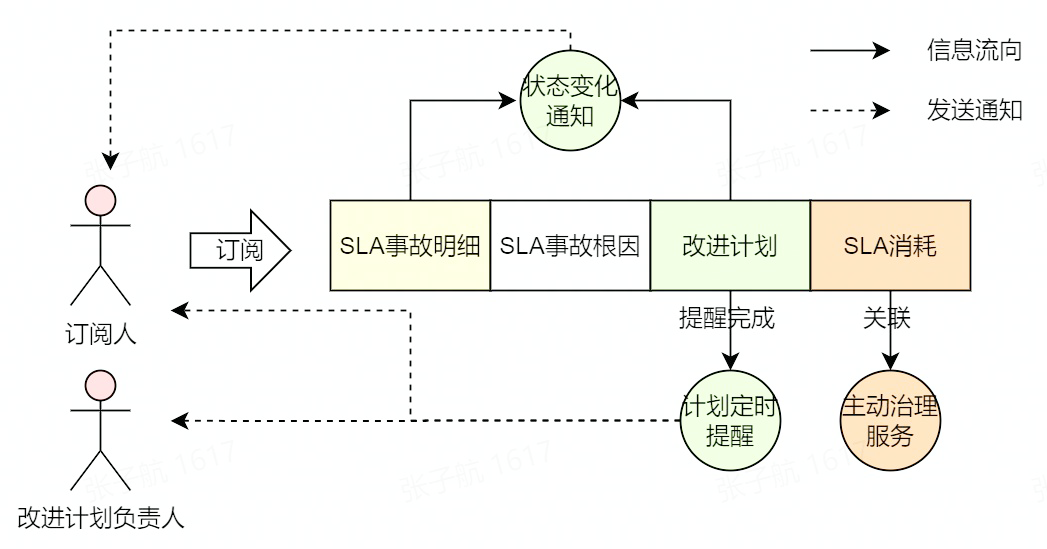
如圖所示,事故主要包含 SLA 事故明細、SLA 事故根因、改進計劃及 SLA 消耗這幾部分,在這其中可以關注以下幾點:
- 事故在登記時,會根據事故明細確認事故根因,并讓相應負責人提出改進計劃
- 用戶可以訂閱事故,在事故的復盤狀態及其改進計劃的完成狀態變化時,都會通知訂閱人
- 任務的改進計劃在完成前,每日都會提醒計劃負責人,直到計劃完成為止
SLA 事故管理平臺的數據是數據治理方治理成果的重要依據,也是整個 SLA 保障平臺使用效果的體現,它的數據價值如下:
- 對事故的復盤歸檔管理,方便后期隨時查閱,定位相關 SLA 信息
- 針對不同數據團隊發生 SLA 事故的整體情況進行對比查看,互相借鑒
- 對事故的改進計劃管理跟蹤,驗收 SLA 的治理效果
以下是某個團隊的雙月事故統計:
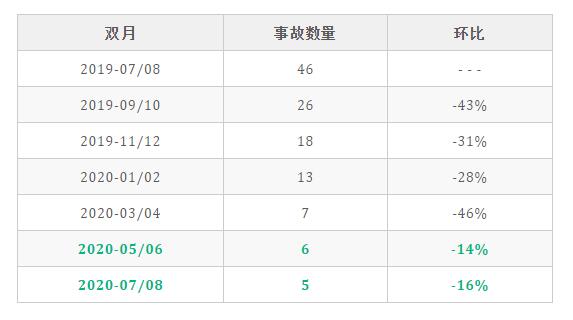
通過上述數據可知,本平臺有效保障了核心任務的穩定產出,輔助降低了穩定性事故發生的概率,現在每雙月該類型事故數量長期維持在個位數。
六、平臺架構總結
平臺整體主要分為基礎組件、規劃式治理服務、響應式治理服務三大塊,系統組件架構圖如下:
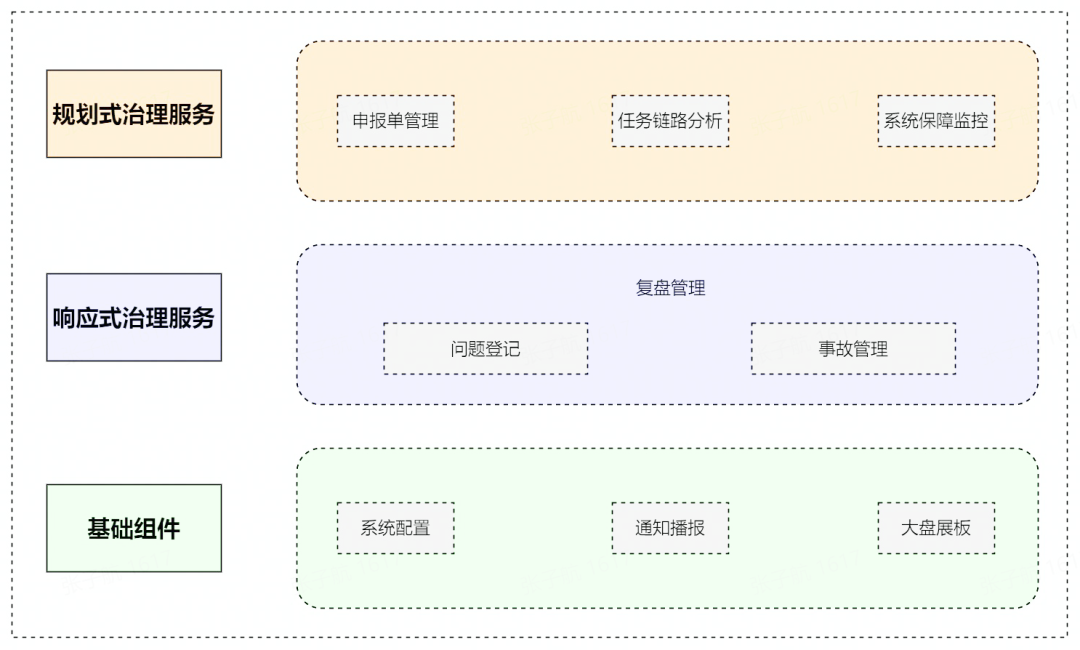
6.1 規劃式治理服務
所謂“規劃式治理”,即在問題發現前治理,通過主動規劃約定 SLA 的形式保障任務產出。規劃式治理是 SLA 相關問題發現的過程。
規劃式治理服務即“提供以申報單簽署的方式達成 SLA 協議的服務”,包括在此過程中申報單的生命周期管理操作,申報任務的鏈路分析,以及達成 SLA 之后的系統保障監控,服務于“申報簽署流程”。
6.2 響應式治理服務
響應式治理是指通過復盤管理模塊對 SLA 相關的事故/問題進行登記、管理、復盤的過程。在發現 SLA 相關問題之后,需要對問題進行處理,形成一個完整的閉環,在發現問題后進行的治理成為響應式治理。
響應式治理服務模塊抽象出問題登記和事故管理兩個模塊,更加靈活的服務于數據 SLA 的問題歸因與事故統計。
6.3 基礎組件
基礎組件提供了配置、播報、看板等基本功能模塊服務,為規劃式、響應式治理服務提供了必要支撐,是整體 SLA 保障服務不可或缺的一環。
6.3.1 系統配置
治理團隊配置
治理團隊為 SLA 的管理團隊,每個申報單都需要綁定一個治理團隊,治理團隊主要負責審批申報單。
數據團隊配置
數據團隊為數據的歸屬方,一個數據團隊對應一個業務團隊,數據團隊的設計保障了各個業務團隊獨立治理的需求。平臺通過對數據團隊的靈活配置支持,可以更細粒度的劃分數據與任務的歸屬,解決權責不清的問題。
訂閱配置
訂閱管理是配置訂閱信息的平臺,本平臺的訂閱為 SLA 監控的通知播報,通過訂閱管理可以將通知指定發動到個人或者群組。訂閱管理是 SLA 監控保障服務不可或缺的一環。
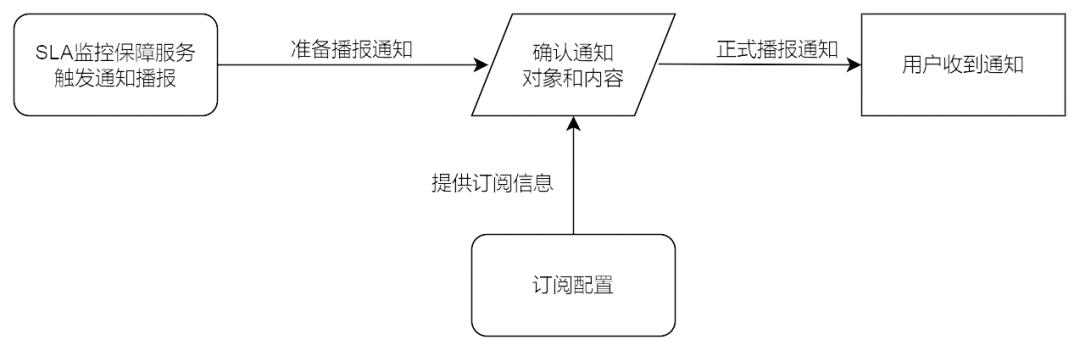
6.3.2 通知播報
通知播報是本平臺所提供的基礎通知能力,是降低溝通成本、實現保障服務、提升用戶體驗的重要手段。在重要節點變更、用戶操作、SLA 狀態變化等情況下,都會進行通知播報。通知播報形式多樣,根據不同的場景,有普通文本消息、加急消息、卡片通知、郵件通知、電話通知等。
6.3.3 SLA 大盤展板
SLA 大盤展板是數據治理方最為關心的部分,展板提供當日 SLA 整體統計信息、SLA 延遲趨勢分析信息、SLA 等級分布明細、任務健康度明細、團隊 SLA 達成信息統計等豐富信息,是很多團隊數據治理指標重要參照來源。
七、未來展望
未來字節跳動數據治理團隊將持續打磨 SLA 保障平臺,在卡點策略優化、SLA 推薦算法優化、基于 SLA 的任務管理機制上持續提升技術能力:
- 卡點策略優化:卡點計算作為優化簽署流程中核心一環,卡點策略優化代表著簽署流程進一步的簡化,未來可以探索利用更多有效的信息優化卡點策略。
- SLA 推薦算法優化:SLA 推薦算法是本平臺的核算算法之一,已經申請了專利。隨著業務的拓展,以及不同種類任務的支持,此算法還有廣闊的提升空間,如進一步提升自動簽署率,進一步提升準確率等。
- 基于 SLA 的任務管理機制:任務簽署 SLA 信息之后,即可依托 SLA 信息進行資源調度優化,并進行資源分配傾斜。
同時,文中闡述的部分能力已經通過火山引擎 DataLeap 產品向企業客戶開放,歡迎關注。