服務出現明顯的變慢,該如何診斷處理?
作者:故里
從類似CPU的這種硬件底層,判斷類似Cache-Miss之類的問題和調優機會,出發點是指令級別優化。這往往門檻比較高,需要掌握專業的技能,還得專業的工具配合,一般出現在新平臺移植或者追求極致性能的時候才會進行。
在日常工作中,應用出現性能問題是不可避免的,絕大部分公司都沒有專門的性能團隊,出現問題還是需要我們自己去排查處理,所以掌握基本的性能知識和技能就顯得很有必要,也是開發工程師進階的必要條件,能否快準狠的定位解決問題,也是對知識、技能和能力的檢驗。
今天我們來討論的問題是,服務出現明顯的變慢,該如何診斷處理?
首先我們要確定服務是突然變慢還運行一段時間后觀察到變慢?類似的變慢是經常出現還是偶發的?還有對慢的定義是什么?是否可以理解為系統對其他方面的請求的延時變長?
在理清楚問題的癥狀后,更有利于分析問題的具體原因,大概有以下思路:
- 檢查應用本身的錯誤日志,看是否在系統變慢的時候存在大量錯誤日志,來判斷是否出現意外的程序錯誤。對于分布式系統,很多公司都會有日志、性能監控系統,使用一些Java診斷工具也可以用于診斷,監控應用是否大量出現某種類型的異常。
- 監控Java服務本身,查看GC日志里面是否觀察到頻繁的Full GC等,可以利用jstat等工具獲取內存使用的統計信息,利用jstack等工具檢查是否出現死鎖等。
- 如果還不能定位問題,可以使用性能檢測工具Profiling,因為它對系統是有侵入性的,非必要,不建議在生產系統進行。
- 定位到問題,采取相應的補救措施,然后驗證是否解決,如果沒有解決,重復上面的操作。
接下來我們來了解一下業內廣泛的性能分析方法論。方法論總結為兩類:
- 自上而下。從應用頂層,逐步深入到具體的不同模塊,或者更近一步的技術細節單元,找到可能的問題和解決方法,這也是最常見的性能分析方法,也是大部分人的選擇。
- 自下而上。從類似CPU的這種硬件底層,判斷類似Cache-Miss之類的問題和調優機會,出發點是指令級別優化。這往往門檻比較高,需要掌握專業的技能,還得專業的工具配合,一般出現在新平臺移植或者追求極致性能的時候才會進行。
我們重點看第一種,自上而下。各個階段的思路以及使用的工具等。
分析系統的性能,我們常從CPU、內存和IO等入手,這幾點是重點關注項。對于CPU,如果是Linux環境,可以先用top命令查看負載情況:
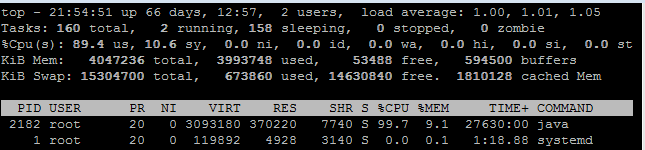
可以看到,平均負載的三個值并不高,也沒有升高的跡象,可以先不特別關注,接下來分析最耗費CPU的Java線程,步驟如下:
利用top命令獲取相應的pid,-H代表thread模式,也可以配合grep命令更精確定位。
top -H然后轉換成16進制。
printf "%x" your_pid最后利用jstack獲取的線程棧,對比相應的ID即可。也可以用vmstat,查看上下文切換的數量,比如指定時間間隔為1,收集20次
vmstat -1 -20
如果上下文切換非常高,并且系統中高很多,就表明可能存在不合理的線程調度導致的,可以用pidstat進一步分析定位。
除了CPU,內存和IO也有很多注意事項:
- 利用free之類查看內存的使用情況。
- 進一步判斷 swap 使用情況,top命令輸出中Virt作為虛擬內存使用量,就是物理內存(Res)和 swap 求和,所以可以反推 swap 使用。顯然,JVM 是不希望發生大量的 swap 使用的。
- 對于 IO 問題,既可能發生在磁盤IO,也可能是網絡IO。例如,利用iostat等命令有助于判斷磁盤的健康狀況。
責任編輯:武曉燕
來源:
故里學Java