













語言模型的冰山一角:微調是不必要, AI21 Labs探索凍結模型未開發潛力
目前,優化給定 NLP 任務性能的最佳方法通常是微調預訓練語言模型 (LM)。然而這樣做的一個副作用是,其他任務的性能會隨之下降。近年來,巨型預訓練語言模型 (LM) 在各種任務中展示出了令人驚訝的零樣本能力,使得眾多研究者產生這樣一個愿景,即單一的、多功能模型可以在不同的應用程序中得到廣泛應用。然而,當前領先的凍結(frozen)LM 技術,即保持模型權重不變,性能卻不如以任務相關方式修改權重的微調方法。反過來,如果研究者能夠忍受模型遺忘與損害多功能性,還需要考慮性能和多功能性之間的權衡。
來自 AI21 Labs 的研究者撰文《 STANDING ON THE SHOULDERS OF GIANT FROZEN LANGUAGE MODELS 》,論文的主要信息是,當前的凍結模型技術(例如 prompt tuning)只是冰山一角,那些更強大的方法利用凍結 LM 技術可以在具有挑戰性的領域中進行微調,而不會犧牲底層模型的多功能性。
為了證明這一點,作者介紹了三種利用凍結模型的新方法:依賴輸入提示調優(input-dependent prompt tuning);凍結閱讀器(frozen readers);循環語言模型(recursive LM),每種方法都大大改進了當前的凍結模型方法。事實上,作者的部分方法甚至在目前其主導的領域中優于微調方法。每種方法的計算成本都高于現有的凍結模型方法,但相對于單次通過一個巨大的凍結 LM 仍然可以忽略不計。這些方法中的每一種本身都構成了有意義的貢獻,但是通過將這些貢獻放在一起,該研究旨在讓讀者相信一個更廣泛的信息,該信息超出了任何給定方法的細節:凍結模型具有未開發的潛力,微調通常是不必要的。


論文地址:https://arxiv.org/pdf/2204.10019.pdf
一般來講,對大型 LM 進行微調通常可以獲得出色的性能,但這種方法訓練代價昂貴。這篇論文表明,存在一個更好的替代方案:凍結一個單一的、巨大的預訓練 LM,并學習更小的神經模塊,可將 LM 專門用于不同的任務。更重要的是,這項研究表明可以將大型 LM 應用于實際問題,在這個階段中,特定任務的神經中間模塊的設計將會取代微調。其結果將是,微調通常是一種不必要的浪費,而關鍵是找到站在大型凍結語言模型的肩膀上的最佳方式。
依賴輸入提示調優
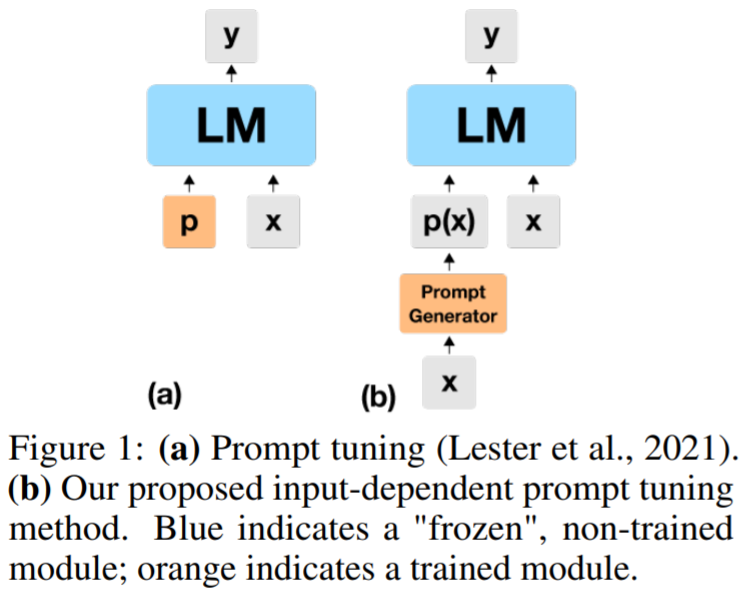
本節中,研究者提出了一種稱為依賴輸入提示調優 (ID-PT) 方法,可用于在保持凍結狀態的同時對 LM 進行大規模多任務處理。ID-PT 用來訓練一個非常小的外部網絡,該網絡接收來自眾多精選數據集之一作為輸入,并動態創建一個神經提示,使凍結的 LM 為處理這個輸入做好準備(參見圖 1)。
該研究使用 Sanh 等人的訓練集進行了實驗,并與他們的模型進行比較,這兩者都是公開可用的。該研究在凍結了 7B 參數 的 J1-Large 模型上執行了 ID-PT,并在僅對一半的訓練示例進行訓練后達到了 Sanh 等人的微調 11B 參數 T0++ 模型的性能。這表明無需微調,LM 也能取得較好的結果。維護和服務單個凍結的 LM 作為主干,并執行 ID-PT 以在不同的任務套件上對其進行外部調整。此外,正如在后面部分中展示的那樣,這啟用了一個新的工作流程,通過部署單個巨大的 LM 來支持各種不同的 NLP 應用程序。
ID-PT 架構如圖 2 所示,它由 3 個組件組成:(1)凍結基于 T5 的編碼器;(2) 一個學習提示,用于在提示生成器中提示調優凍結 T5 編碼器的功能(總共 330K 學習參數);(3) 一個學習的交叉注意力網絡,將 T5 編碼器的可變長度輸出序列(長度等于輸入 x 的長度)轉換為固定長度的提示 p (x)。
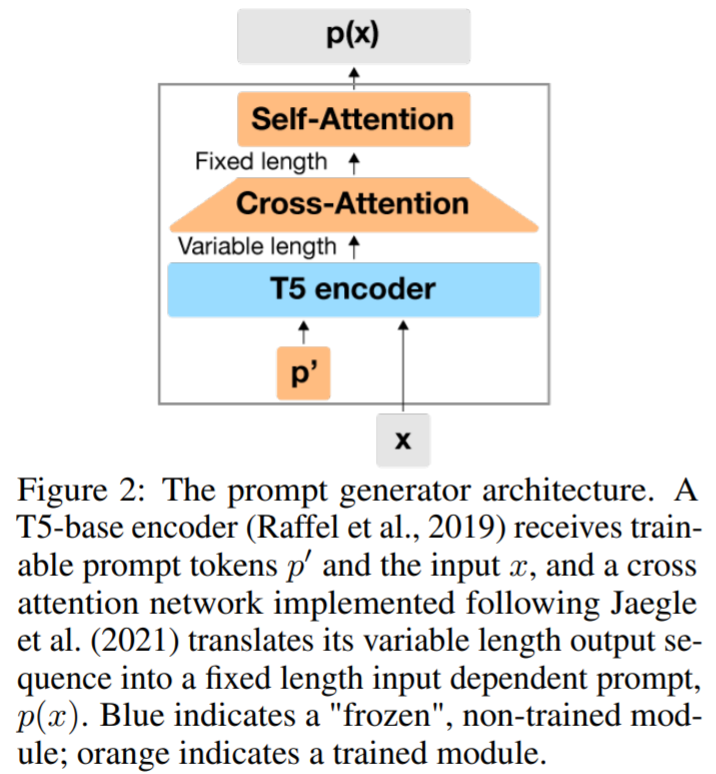
表 1 顯示了每個任務集群以及跨數據集的 ID-PT + J1-Large 和 T0++ 的平均測試集分數。這兩個模型看起來相當,在一些任務集群上表現出較小的性能差異,而另一些則表現出更高的方差:ID-PT + J1-Large 在情感和釋義任務集群中表現更好,而 T0++ 在結構 - 文本和摘要任務集群中優于 ID-PT + J1-Large。總體而言,ID-PT + J1-Large 在跨數據集的測試分數平均值中略超過 T0++ 的表現。
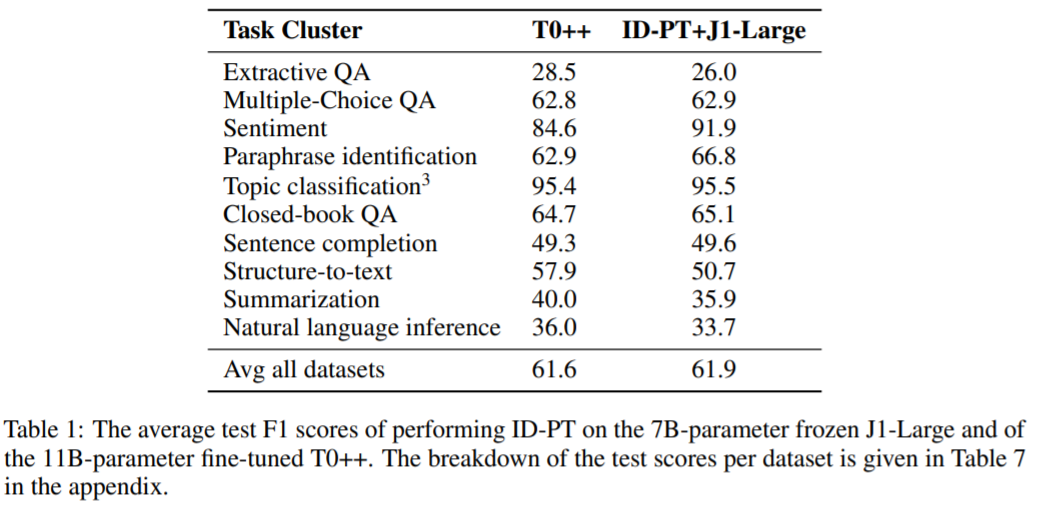
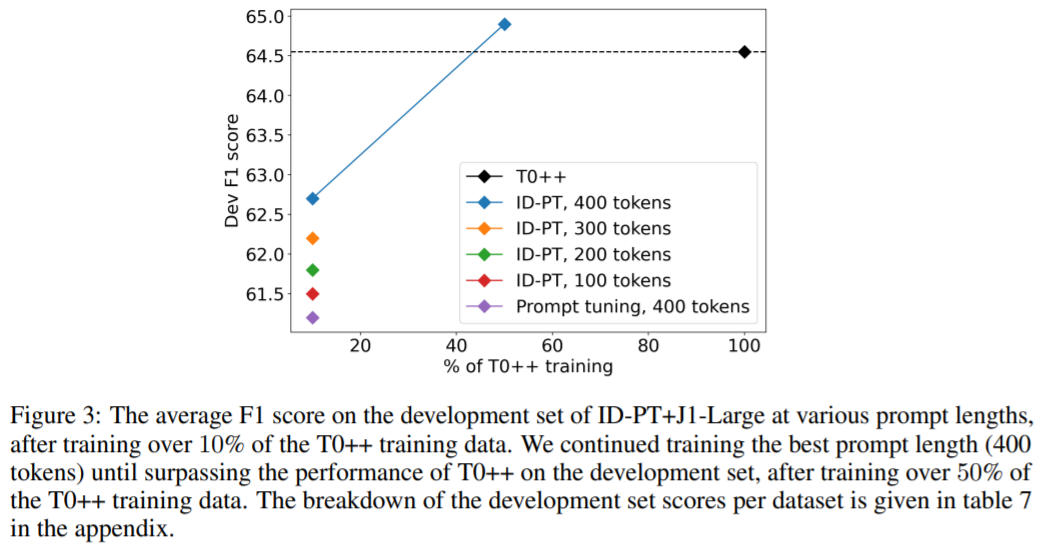
圖 3 顯示了該研究在訓練期間不同點觀察到的 ID-PT + J1-Large 的平均開發集分數:
凍結閱讀器
依賴于小型檢索增強閱讀器的一個固有缺點是,它們沒有大型 LM 的世界知識或推理能力。因此,需要將強大的監督學習檢索與大型 LM 結合。為了解決這個問題,該研究使用了一個外部重排序(external re-ranking)模塊,以增加在適合凍結 LM 的上下文窗口的少量通道中獲得答案的機會。雖然檢索器相關性分數是根據問題和段落的單獨密集表示來計算的,但重排序器會在聯合處理問題和文章后預測每個文檔的相關性分數。提示調優凍結的 LM 以從出現在其上下文中的重排序的文檔中提取答案。
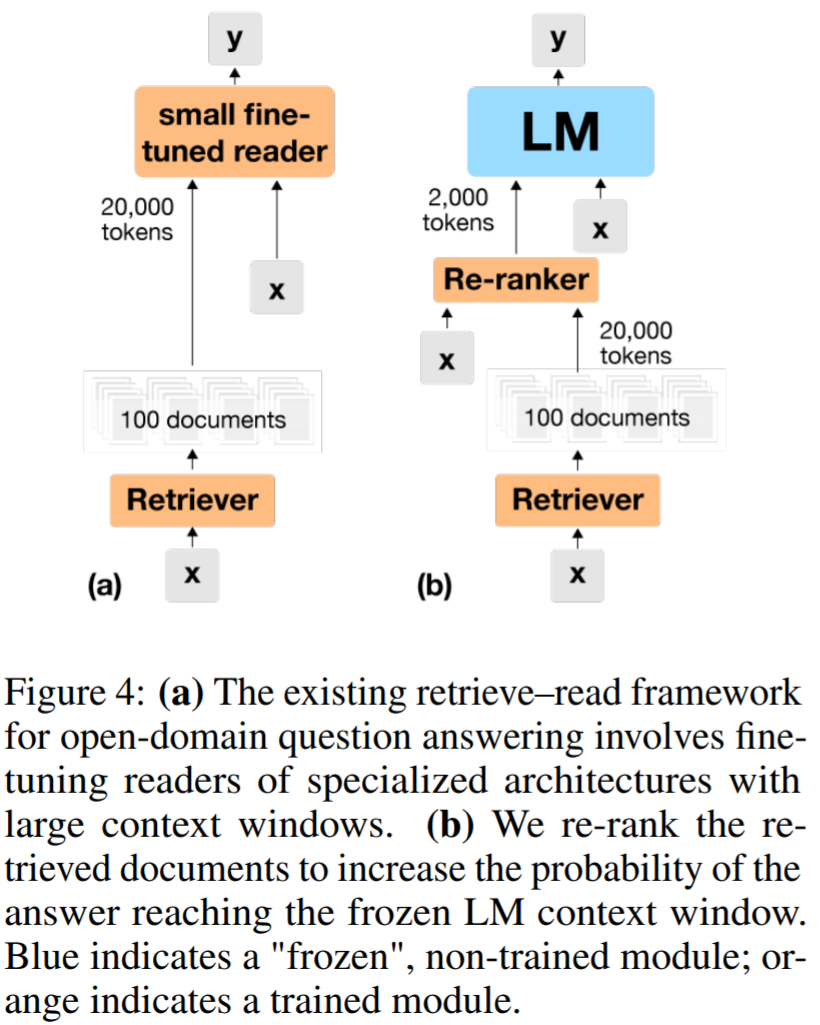
表 2 顯示了在將文檔打包到 LM 的上下文窗口中時使用重排序器的實用性。當使用 DPR 作為檢索系統時,該研究將 LM 輸入的召回率(即答案出現在凍結 LM 的上下文窗口中的問題的百分比)從 77.2% 提高了 到 80.4%,從而將下游性能(通過精確匹配衡量)提高 2.1 個百分點(從 46.6% 到 48.7%)。同樣,該研究觀察到在利用 Spider+BM25 等更強大的檢索器時,重新排名可以獲得顯著收益。
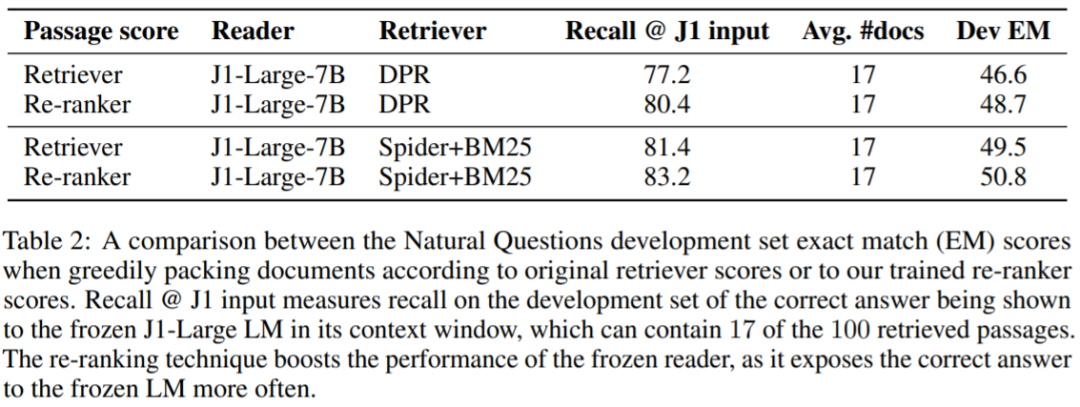
表 3 顯示了該系統在 NQ 測試集上與各種生成基線對比結果。凍結 J1-Grande-17B 閱讀器獲得了最好的結果,超越 FiD 模型得分。
總體來說,該結果表明巨大的凍結語言模型可作為 ODQA 的優秀閱讀器,也不會落后于更精細的、突出的、經過微調的閱讀器。
將循環應用于凍結 LM 模型
現有的基于 Transformer 的 LM 的應用程序只通過 LM 運行一次給定輸入。盡管這是一種很自然的選擇,在大部分其他 DNN 應用程序中,研究者從 LM 設計模式的差異中找到了機會。由于 LM 的輸入和輸出空間都使用的是自然語言,而且由于相同的 LM 可以提供多種功能,因此原則上可以將 LM 重新應用到自己的輸出中,這種操作被稱為「LM 循環」。
在這一部分,研究者提出了兩種不同的方法將該思路付諸實踐(圖 5),并給出了實驗證據,證明每一種方法都可以產生顯著的收益。在第 4.1 節中,提供了一種文本方法,其中輸出文本在第一次通過凍結 LM 并重新插入相同的凍結 LM 之后進行采樣。在第 4.2 節中,提出了一種神經方法,在這種方法中,一個可訓練的小型網絡通過相同的凍結 LM 將凍結 LM 輸出處的向量表征映射到下一次迭代的向量表征輸入。
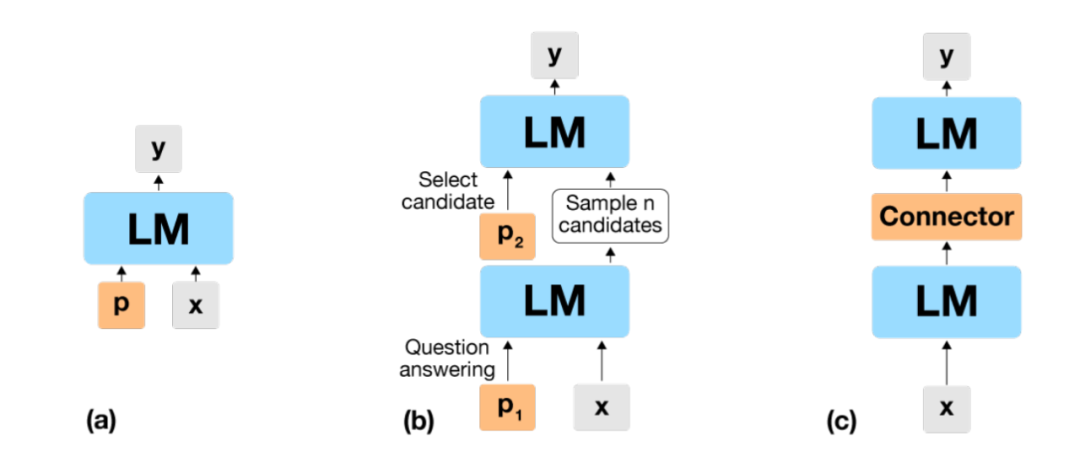
圖 5: (a) Prompt 調優使一次通過凍結的 LM;(b) 文本循環 LM 方法 (Section 4.1) 使用凍結的 LM 一次采樣 n 個候選答案,然后再次采樣正確的答案;(c) 神經循環 LM 方法 (Section 4.2) 涉及一個訓練好的連接器,該連接器將第一個 LM 關口的輸出嵌入轉換為第二個 LM 關口的輸入嵌入。藍色表示「凍結」,未經訓練的模塊;橙色代表訓練過的模塊。
在 closed-book 設置的開放域問答上,研究者評估了 LM 循環方法,其中重點關注了 Natural Questions benchmark (Kwiatkowski et al., 2019)。研究者用 7B 參數的 LM J1-Large 進行了實驗,結果表明,通過模型的兩次迭代,這兩種方法都比傳統的凍結模型方法(只使用一次凍結模型)獲得了實質性收益,而且神經循環 LM 的性能優于文本循環 LM。
值得注意的是,通過兩次迭代 7B 參數模型,神經循環 LM 模型接近了 17B 參數 LMJ1-Grande 單次通過的性能。
通過循環地將 LM 應用于其自身的輸出來提高性能,這一前景有可能變成為服務于 LM 的商業化游戲規則改變者。如果一個 LM 在某項任務上的表現不令人滿意,現有的垂直性能改進就是預訓練一個更大的 LM。然而,預訓練越來越大的 LM 很快就變得昂貴起來,而且即使在評估時間部署巨大的模型也是昂貴的。此外,只有在某些任務或任務中的某些輸入時才需要改進性能。通過在自身輸出上重新應用現有的 LM 進行改進,只需要單次前向通過成本的一半,或者在需要時獲得雙倍的計算量,這是一個比預訓練更集中、成本更低的選擇,并部署一個規模為原來兩倍的模型。
更多研究細節可參考原論文。


















