信息抽取里程碑式突破!NLP要迎來大規(guī)模落地了?
AI領域的工作突破通常有三類:
- 屠爆了學術界榜單,成為該領域?qū)W術層面的新SOTA
- 實現(xiàn)了大一統(tǒng),用一個架構實現(xiàn)對該領域諸多子任務的統(tǒng)一建模,刷新建模認知
- 將NB的學術界新SOTA變成一件人人可傻瓜式使用的開源工具利器,帶領該領域大規(guī)模落地開花
要單獨實現(xiàn)其中的任何一點,都是一件很有挑戰(zhàn)的事情。如果我說,在信息抽取領域,不久前的一個工作同時做到了這三種突破呢?這次,先倒著講。先講第三點——
一個刷新認知的信息抽取開源工具
信息抽取是一個行業(yè)應用價值很高的技術,卻因為任務難度大,落地成本居高不下。像金融、政務、法律、醫(yī)療等行業(yè),有大量的文檔信息需要人工處理,比如政務人員處理市民投訴,工作人員需要從中快速提取出被投訴方、事件發(fā)生地點、時間、投訴原因等結構化信息,非常費時費力。若信息抽取技術能低成本、高性能的實現(xiàn)落地,可以大大提升諸多行業(yè)的生產(chǎn)效率,節(jié)約人力成本。如今這個想法,迎來了史無前例的可能性。話不多說,直接上代碼,上效果!
# 實體抽取
from pprint import pprint
from paddlenlp import Taskflow
schema = ['時間', '選手', '賽事名稱'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奧會自由式滑雪女子大跳臺決賽中中國選手谷愛凌以188.25分獲得金牌!")) # Better print results using pprint
>>>
[{'時間': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'賽事名稱': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奧會自由式滑雪女子大跳臺決賽'}],
'選手': [{'end': 31,'probability': 0.8981548639781138,'start': 28,'text': '谷愛凌'}]}]
僅用三行代碼就實現(xiàn)了精準實體抽取?
再來試試更困難的事件抽取任務:
# 事件抽取
schema = {'地震觸發(fā)詞': ['地震強度', '時間', '震中位置', '震源深度']} # Define the schema for event extraction
ie.set_schema(schema) # Reset schema
ie('中國地震臺網(wǎng)正式測定:5月16日06時08分在云南臨滄市鳳慶縣(北緯24.34度,東經(jīng)99.98度)發(fā)生3.5級地震,震源深度10千米。')
>>>
[{'地震觸發(fā)詞':
[{'end': 58,'probability': 0.9987181623528585,'start': 56,'text': '地震',
'relations':
{'地震強度': [{'end': 56,'probability': 0.9962985320905915,'start': 52,'text': '3.5級'}],
'時間': [{'end': 22,'probability': 0.9882578028575182,'start': 11,'text': '5月16日06時08分'}],
'震中位置': [{'end': 50,'probability': 0.8551417444021787,'start': 23,'text': '云南臨滄市鳳慶縣(北緯24.34度,東經(jīng)99.98度)'}],
'震源深度': [{'end': 67,'probability': 0.999158304648045,'start': 63,'text': '10千米'}]}
}]
}]
同樣易用而精準!感興趣的小伙伴可以通過以下傳送門自行安裝體驗。
歡迎大家提前碼住鏈接,建議訪問Github點個Star ?https://github.com/PaddlePaddle/PaddleNLP
當然,我們在自行測試的時候可能會覺得,短短的三行代碼就可以任意DIY抽取了,這未免有點夸大?
并不是,該接口實際上是向大家展示了一個通用的開放域信息抽取范式,即一個開放域信息抽取的API接口,也就是說,給定任意要抽取的實體、關系、事件等類型(schema),“提示”模型從文本中抽取出對應的目標。
例如在第一個示例中,我們希望從文本中抽取出時間、選手和賽事名稱這三種實體,將其作為schema參數(shù)傳給Taskflow后,將“提示”模型從文本中精準抽取這三類實體。這樣,就做到了對任何信息抽取需求都能夠應對自如。
這波操作放在2022年還是讓人感覺有點夢幻了。要知道,市面上的信息抽取工具大多只能做特定領域的封閉域(有限預定義的schema)抽取,效果還很難保證,更不必說打造成三行代碼即可完成調(diào)用的開放域工具了。
這不禁讓人好奇,這個開源工具的背后是怎么做到的呢?我找PaddleNLP內(nèi)部人士了解到,關鍵有二:
- 一個發(fā)表在ACL2022,屠遍信息抽取榜單的大一統(tǒng)信息抽取諸多子任務的技術UIE
- 首個知識增強語言模型——ERNIE 3.0
關于第一點,本文的下一章會做重點闡述,在此稍留作懸念。關于第二點,我們知道,知識對于信息抽取任務至關重要,而ERNIE 3.0不僅參數(shù)量大,還吸納了千萬級別實體的知識圖譜,可以說是中文NLP方面最有“知識量”的SOTA底座。在ERNIE 3.0的基礎上,如果再構造一個面向開放域信息抽取的二階段SOTA預訓練上層建筑呢?強強聯(lián)合,便是這個工具帶來夢幻體驗的密碼。
需要注意的是,這個包含強大知識儲備的NLP基座和夢幻的信息抽取架構均集成到了PaddleNLP中,PaddleNLP卻又不止是一個SOTA收納箱,其還提供了非常易用的模型壓縮部署方案、大模型加速技術、產(chǎn)業(yè)場景應用范例,做了扎實的易用性優(yōu)化和性能優(yōu)化。一句話總結,打造中文NLP應用的神器。
值得關注的是,UIE不僅具備驚艷的zero-shot開放域信息抽取能力,還有強大的小樣本定制訓練能力。
作者在互聯(lián)網(wǎng)、醫(yī)療、金融三個行業(yè)關系、事件抽取任務上測試了小樣本定制訓練效果:
 在金融場景,僅僅加了5條訓練樣本,uie-base模型F1值提升了25個點。也就是說,即使工具在某些case或某些場景下表現(xiàn)欠佳,人工標幾個樣本,丟給模型后就會有大幅的表現(xiàn)提升。這個強大的Few-Shot能力則是工具在大量長尾場景落地的最后一公里保障。
在金融場景,僅僅加了5條訓練樣本,uie-base模型F1值提升了25個點。也就是說,即使工具在某些case或某些場景下表現(xiàn)欠佳,人工標幾個樣本,丟給模型后就會有大幅的表現(xiàn)提升。這個強大的Few-Shot能力則是工具在大量長尾場景落地的最后一公里保障。
挖掘該工具更多的潛力和驚喜,請進傳送門:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
接下來還有第2點——
一個大一統(tǒng)信息抽取諸多子任務的架構
信息抽取領域的任務繁多,從大的任務類型上,可分為實體抽取、關系抽取、事件抽取、評價維度抽取、觀點詞抽取、情感傾向抽取等,而若要具體到每個任務類型下的抽取domain和schema定義,則更是無窮無盡了。
因此,以往信息抽取的落地是非常困難、成本高昂的,公司不僅要為每個細分的任務類型和domain標數(shù)據(jù)、開發(fā)模型、專人維護,而且部署起來也非常費力且消耗大量機器資源。
此外,各個子任務也不是完全割裂的,傳統(tǒng)的子任務專用設計使得任務之間的通用知識難以共享,一座座“信息孤島”的力量總是有限的,甚至有偏的。但現(xiàn)在不是了。由中科院軟件所和百度共同提出的一個大一統(tǒng)諸多任務的開放域信息抽取技術UIE,發(fā)表在ACL 2022的SOTA技術,直接上圖: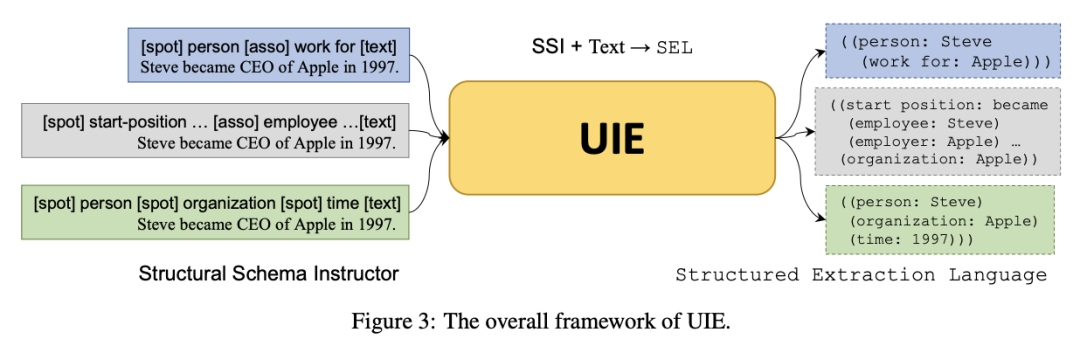
簡單來說,UIE借鑒近年來火熱的Prompt概念,將希望抽取的Schema信息轉(zhuǎn)換成“線索詞”(Schema-based Prompt)作為模型輸入的前綴,使得模型理論上能夠適應不同領域和任務的Schema信息,并按需抽取出線索詞指向的結果,從而實現(xiàn)開放域環(huán)境下的通用信息抽取。
例如上圖中,假如我們希望從一段文本中抽取出“人名”的實體和“工作于”的關系,便可以構造[spot] person [asso] work for的前綴,連接要抽取的目標文本[text] ,作為整體輸入到UIE中。
那么這里關鍵的UIE模型是如何訓練得到的呢?
UIE作者在預訓練模型MLM loss的基礎上又巧妙的構造了2個任務/loss:
- 文本-結構預訓練$L_{pair}$:給定一個<文本,結構>對,基于抽取出的schema通過隨機采樣spots和asso的方式來構造schema負例,將schema負例與原始的schema(正例)拼接得到meta-schema,最后再拼接上文本,來預測結構。作者表示這樣可以避免模型在預訓練階段暴力記憶三元組,得到通用的文本-結構的映射能力
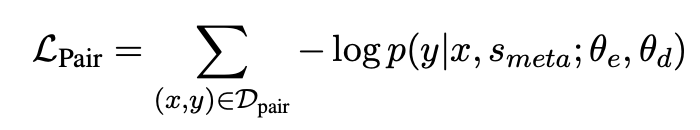
- 結構生成預訓練$L_{record}$:這個任務是為了訓練decoder的結構輸出能力,將輸出結構SEL作為decoder的優(yōu)化目標,來學到嚴謹?shù)腟EL規(guī)則
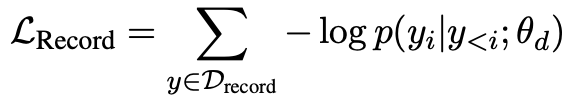
通過2個loss的聯(lián)合預訓練,便得到了強大的UIE模型。值得注意的是,盡管原論文使用了T5模型作為backbone,基于生成架構。實際上為了發(fā)揮模型在中文任務上的最大潛力,且讓模型的推理效率變得可接受(畢竟生成任務還是太重了),在本文第一章提到的PaddleNLP信息抽取方案中,使用了強大的ERNIE 3.0模型+抽取式(閱讀理解)架構。
因此在中文任務上效果更佳,推理速度更快。對更多細節(jié)感興趣的小伙伴,可以看原論文或在文末掃碼海報預約UIE講解直播~論文鏈接:?https://arxiv.org/pdf/2203.12277.pdf
最后講第1點——
不小心,刷了13個SOTA
UIE在各類IE任務的數(shù)據(jù)集上表現(xiàn)怎么樣呢?
首先是常規(guī)設定下,4類抽取任務,13個經(jīng)典測試集與SOTA的對比:
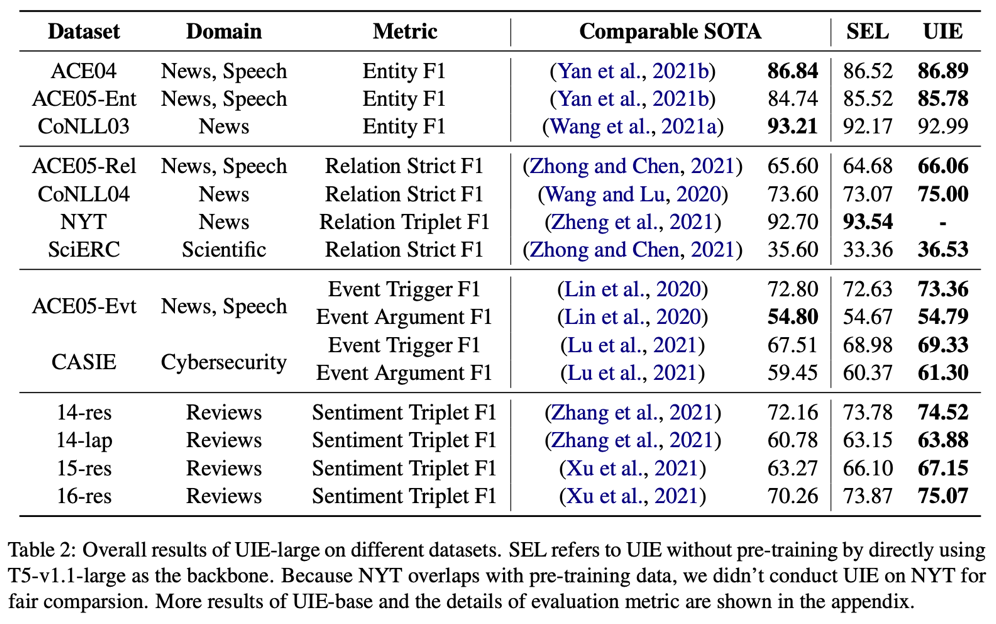
表格右數(shù)第二列是未經(jīng)過UIE預訓練的結果(基于T5+SEL直接微調(diào)),右數(shù)第一列是UIE預訓練后微調(diào)的結果,可以看出SEL+強大生成模型就可以在信息抽取的統(tǒng)一建模方面取得很強的效果,而經(jīng)過UIE預訓練后則進一步提升了模型表現(xiàn)。
我們知道,模型經(jīng)過微調(diào),其實會弱化不同預訓練策略帶來的模型差異。因此UIE預訓練的價值在小樣本方面得到了更加酣暢淋漓的體現(xiàn):
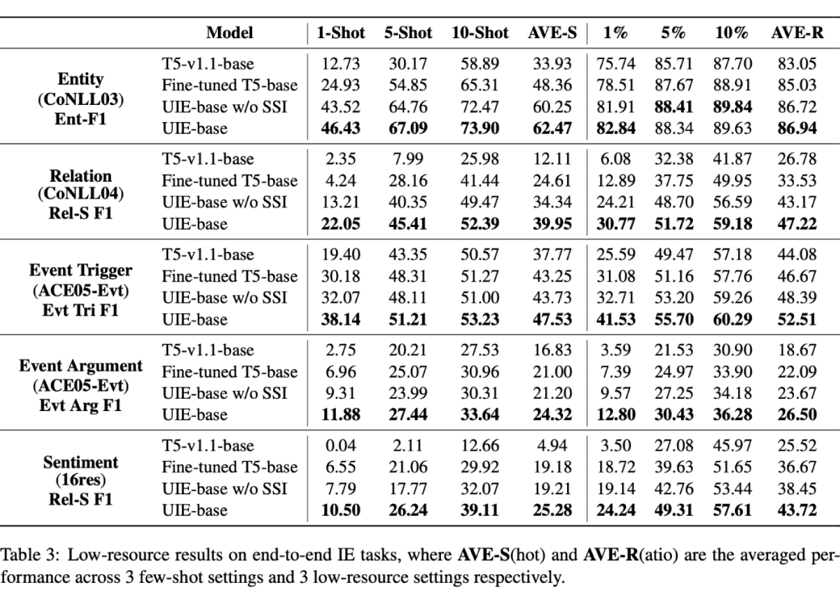
經(jīng)過UIE預訓練后,模型的小樣本學習能力得到了極大的提升,這便是UIE工具具備強大定制化能力,進而實現(xiàn)中長尾行業(yè)落地的關鍵。