數據中臺為什么不好搞?
從 2015 年阿里提出“大中臺”的數據中臺戰略,到 2019 年大廠及中臺服務商“大興”數據中臺,再到 2021 年大廠又開始拆中臺。數據中臺從小甜甜變成牛夫人僅僅用了 2 年時間,為什么這么快數據中臺就不香了?(說明:數據中臺的概念比較模糊,有些人說是業務概念,有些人說是技術概念,這里我們僅從技術的角度討論,即認為數據中臺是技術概念)
數據中臺為什么難搞?
從技術上講,中臺的架構挺合理的。在前臺和后臺之間夾一個中臺,屏蔽后臺的數據存儲,應對前面沒完沒了的變化需求。前臺跟著界面走,天生就穩定不了,總是有五花八門的數據請求,這是必然的事情。后臺應該主要負責數據存儲,把不同形式和規模的數據以合適的方式整理好,大數據倒騰起來動靜太大,要求有一定的穩定性。如果前臺的請求都要求后臺直接做,那后臺管的事就太多了。應對靈活請求和規整數據存儲在一定程度上是兩個優化目標不同的需求,同一個團隊在同一套硬件上同時對付這兩件事,容易發生精神分裂。而且,后臺是被許多前臺共享的,如果直接向前臺提供靈活數據服務,還可能導致各個前臺之間的耦合程度太高,維護成本立即陡增。同樣的,把這些數據處理放在前臺也不合適,一方面不太安全,另一方面,前臺團隊也是忙著讓界面如何更好看使用更流暢,沒太多工夫琢磨數據的事情。有了中臺就好很多了,后臺專心管存儲,前面專心管界面,前后臺之間的差距由中臺負責抹平。分工明確,各司其職,效率自然提高。
既然架構合理,那為啥搞不下去?
原因呢,說啥的都有,不過大都沒說到點子上。因為說這些話的大都不寫代碼,寫代碼的又大都輪不到來說話。技術上的根本原因在于,業界就沒有準備好能讓數據中臺落地的技術!
中臺向前臺提供數據服務。啥是數據服務呢?就是收到請求后返回一些合適的數據回去,那咋弄出返回的數據呢?計算!就是把以前在后臺讓數據庫做的事搬到中臺完成。
那么,你打算讓我用什么技術來寫這些計算代碼呢?
Java?開玩笑呢?寫個稍復雜些的分組匯總就可能好幾百行,你讓我怎么提高效率?還想迅速應對前臺變化?這代碼我連寫帶調得好幾天,下禮拜再見吧。
中臺要干的這些任務,也是之前數據庫干的事,絕大多數都是結構化數據相關的計算。而 Java 這些高級語言基本上沒什么好用的結構化數據計算類庫,原先用 SQL 幾句幾十句話能搞定的事,現在用 Java 就得幾百甚至上千行代碼了。代碼長了,不僅難寫,還容易錯。而且,Java 程序員的成本也挺高啊,效率沒提高,錢倒花多了,那又何苦?
你可能會說,Java 支持 Stream 以后這些問題就都能解決啊。Stream 看著挺好,但實際用起來完全不是那么回事。Stream 的中間計算結果和最終結果都要事先定義,而結構的定義和賦值都很麻煩,如果不定義,閱讀和使用又不直觀。而且 Stream 雖然支持 lambda 語法,但接口規則比較復雜,代碼沒短多少閱讀障礙卻顯著增加。Stream 的結構化對象如 record\entiry\Map 都不方便,根本原因還是在于 Java 缺乏專業的結構化數據對象,缺少來自底層的有力支持。
與 Stream 類似,Kotlin 計算能力不足也是由于缺乏專業的結構化數據對象導致的。無法支持動態數據結構、難以真正簡化 Lambda 語法、無法直接引用字段等等。同時 Kotlin 也缺乏一些重要的基本函數,比如關聯計算,開發者仍然要硬編碼完成計算,對于多個基本計算組合而成的業務算法,開發過程仍然困難。
但是,貌似有些大廠的中臺架構實施得不錯,這又咋解釋?
可能是大廠人才多,Java 代碼積累豐富吧,搞起這些計算就容易一點了。而且,事實是這些互聯網大廠雖然大,業務復雜度卻遠遠趕不上傳統行業,大廠能搞得通的事,你可未必能搞得通。更何況大廠又開始拆中臺了不是?
不用 Java,那咱還繼續用 SQL 行不?
嗯,那得在中臺也放個數據庫,把一堆數據從后臺搬出來再移到中臺來。搬多少數據呢?貌似所有的數據都有可能用于計算,那得把整個后臺的數據都搬過來。然則這玩意兒還能叫中臺?不就是把后臺挪了個位置而已,純粹吃飽了撐的嘛。
在沒有不依賴于數據庫的、可被集成嵌入的、支持多樣數據源、簡單方便且豐富強大的結構化數據計算能力之時,數據中臺就是空想,架構好看,但無法落地。強行上中臺,除非你的業務足夠簡單,否則就是只會讓開發成本上升而效率下降,靈活性一點沒增加,麻煩事卻一大堆。
數據中臺受制于計算能力。必須要具有上述特征的計算引擎之后,才能讓數據中臺的合理架構真正發揮作用,也才能讓數據中臺實打實地落地、開花、結果。
開源 SPL:數據中臺計算引擎
開源計算引擎 SPL 具備數據中臺需要的所有特性,不僅提供了不依賴數據庫的完備計算能力,開放的計算體系還可以直接基于多樣數據源進行計算,同時豐富的計算類庫和敏捷語法可以很方便完成復雜結構化數據計算,SPL 優秀的集成性確保了可以方便地被分布到數據中臺的各個環節以處理數據,助力數據中臺發揮應有的效力。
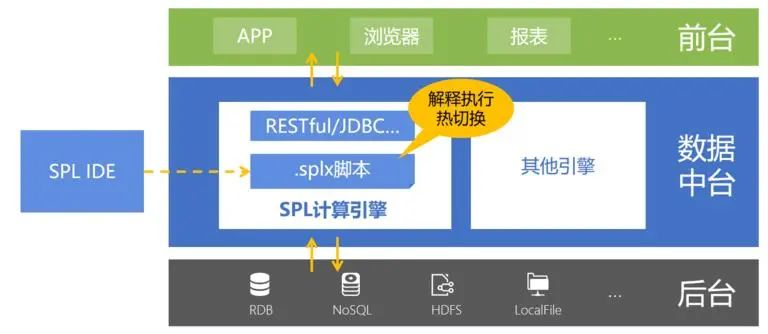
邏輯上 SPL 介于應用和數據源之間實施數據處理,對上提供計算服務,對下屏蔽多樣性數據源差異,完美貼合數據中臺的結構。SPL 提供了標準 JDBC/ODBC/RESTful 接口,可以像調用存儲過程一樣請求 SPL 計算結果。JDBC 調用 SPL 代碼示例:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
熱切換能力
SPL 采用解釋執行機制,天然支持熱切換。這樣對于穩定性差、經常需要新增修改的中臺數據處理需求非常友好。SPL 服務腳本與 Java 程序獨立,外置在 Java 之外,修改和維護都可以獨立進行,腳本修改上傳后就能實時生效,保證中臺可以不中斷地提供服務。
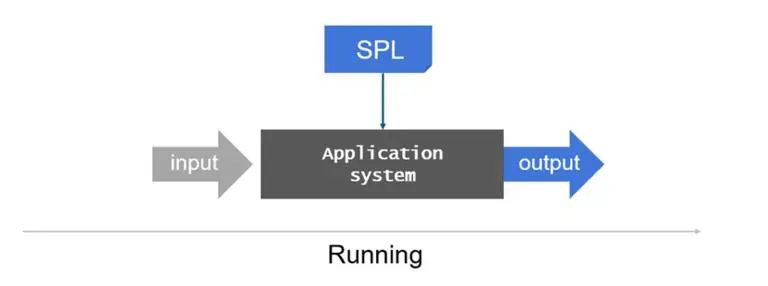
使用 SPL 實現中臺中的數據處理邏輯,可以有效地降低數據服務和框架之間的耦合性。整個中臺架構也更為合理。
敏捷語法
作為專業的數據計算引擎,SPL 為結構化數據處理設計了專門的敏捷計算語法,通過 SPL 語法可以快速實現數據處理任務,及時響應前臺多變的數據請求。在敏捷語法與過程計算的支持下,即使原來使用 SQL 難以完成的復雜計算(更不用說 Java 了),用 SPL 也可以輕松實現。比如要根據股票記錄查詢某只股票最長連續上漲天數,SQL(oracle)的寫法如下:
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when price>lag(price) over(order by tradeDate) then 0 else 1 end changeSign from AAPL) )
group by unRiseDays)
可以嘗試一下讀懂這句 SQL,是不是很繞?這是由 SQL 的特性(缺乏離散性、集合化不徹底等)決定的。同樣的思路,SPL 寫起來就簡單多了,不用繞來繞去了:

數據從數據庫中取出(數據源是什么都可以,下面會說到 SPL 的開放性),計算在計算引擎 SPL 中完成,符合數據中臺的目標。
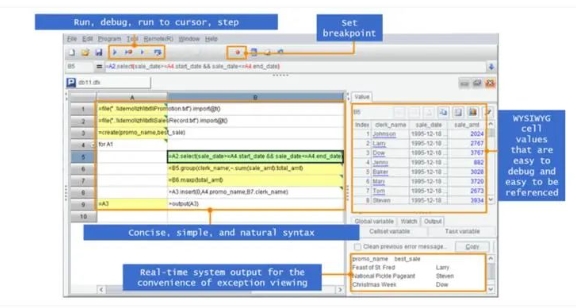
SPL 還提供了簡潔易用的 IDE 環境,在 IDE 中不僅可以很方便編碼調試,過程計算的每步計算結果都可以實時查看,網格式編碼代碼天然整齊,通過格子名稱引用中間計算結果無需定義變量,十分方便。
強計算
數據中臺的計算引擎需要獨立的計算能力。SPL 作為獨立的計算引擎,計算能力不依賴數據庫,提供了十分豐富的結構化計算類庫,擁有完備的計算能力。分組匯總、循環、過濾、集合運算、有序計算等應有盡有。

SPL 還提供了很多高性能算法來保證計算效率,內外存計算、索引機制、遍歷復用等很多在業界內首次使用的算法,同時支持并行計算進一步提升計算性能。
開放性
SPL 還具備非常開放的計算能力,可以對接多種數據源,RDB、NoSQL、CSV、Excel、JSON/XML、Hadoop、RESTful、Webservice 都可以直接對接并進行混合計算,不需要借助數據庫,數據實時性和計算實時性都可以很好保障。

我們知道,不同數據源有各自的優勢,RDB 計算能力較強,但 IO 吞吐能力弱;NoSQL 的 IO 效率高,但計算能力很弱;而文本等文件數據完全沒有計算能力,但使用非常靈活。SPL 不僅可以基于這些數據源混合計算,在實施計算時還可以充分保留原有數據源的優勢。除了原生計算語法,SPL 也提供 SQL 支持(相當 SQL92 標準),可以使用 SQL 查詢文本、Excel、NoSQL 等非 RDB 數據源,這樣就極大方便了熟悉 SQL 的應用開發人員。
總結一下,數據中臺落地的關鍵在于計算引擎,而計算引擎需要具備獨立且完備的計算能力、應對多樣性數據源的開放性、開發的高效性以應對不停變化的前臺需求,還能支持熱切換以確保中臺持續提供服務。從這些方面來看,SPL 的確是數據中臺計算引擎的不二之選。