Nature子刊 | NUS、字節首次將AI元學習引入腦成像領域
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
近期,新加坡國立大學、字節跳動智能創作新加坡團隊等機構合作的一項技術成果被全球頂級學術期刊Nature的子刊Nature Neuroscience收錄。這項研究首次將人工智能領域的元學習方法引入到神經科學及醫療領域,能在有限的醫療數據上訓練可靠的AI模型,提升基于腦成像的精準醫療效果。

研究背景
腦成像技術是神經科學發展的一個重要領域,能夠直接觀察大腦在信息處理和應對刺激時的神經化學變化、從而對疾病的診斷和治療提供重要參照。理論上,基于腦成像的機器學習模型可應用于預測個人(individual)的一些非腦成像(non-brain-imaging)的表征特性(phenotypes) ,例如,流動智力 (fluid intelligence)、臨床結果(clinical outcomes)等,從而促進針對個人的精準醫療( precision medicine)。
一個現實的問題在于,雖然現在已經有英國生物銀行(UK Biobank)這樣的大規模人類神經科學數據集,在研究臨床人群或解決重點神經科學的問題時,幾十到上百人的小規模數據樣本依舊是常態。在精確標注的醫療數據量有限的情況下,很難訓練出一個可靠的機器學習模型來預測個人表征特性。
論文提出一個新的思路來解決這一數據匱乏所帶來的根本限制:在給定一個大規模(N>10,000)的帶有多種表征特性標注的腦成像數據集,可以將在該數據集上訓練的機器學習模型遷移到一個獨立的小規模(N<200)的帶有新的表征特性的數據集上,從而使得在新的數據集上訓練的模型能夠準確預測新的表征特性。
方法
研究者通過對先前的小樣本數據分析發現,個體的認知、心理健康、人口統計學和其他健康屬性等表征特性與大腦成像數據之間存在一種內在的相關性。這意味著,小數據集當中的某些獨特表型可能與大規模數據集當中的某些預先存在的特定表型相關,利用這種相關性,研究者提出了一個新的基于元學習的元匹配方法建立了一種框架機制,可利用大規模腦成像數據集來促進對小數據集當中一些全新的、未知的表型的預測,從而訓練出可靠的用于表征特性預測的機器學習模型。
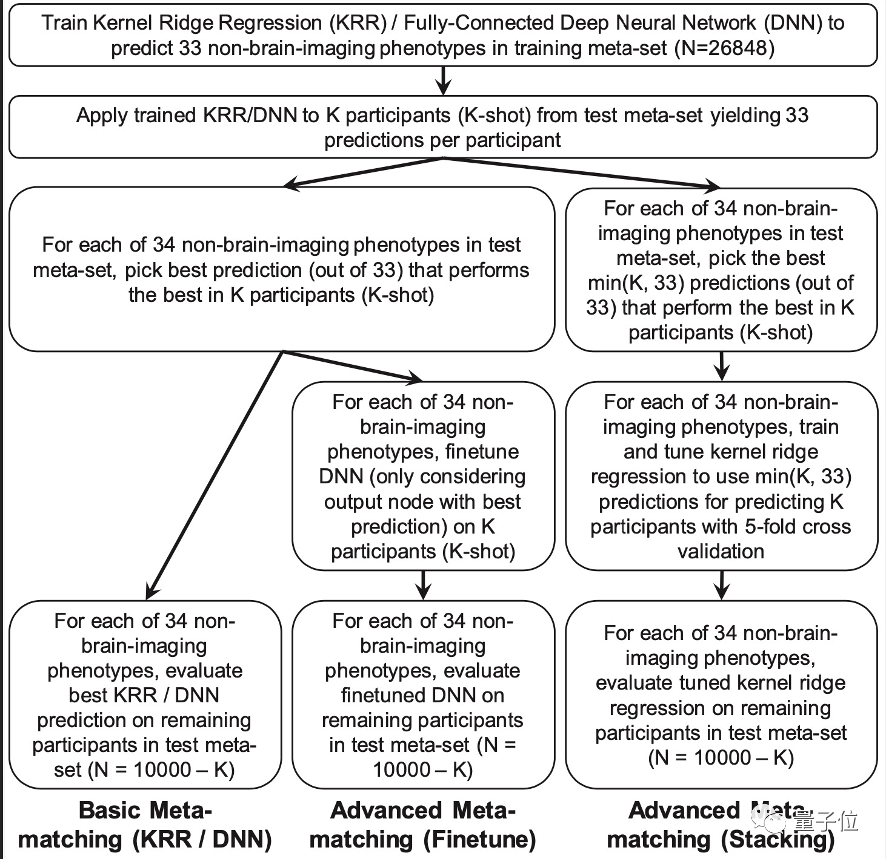
論文提出了一種新的元匹配(meta-matching)方法,來解決小規模數據集上的表征特性預測模型的訓練問題。元匹配是一種高度靈活的學習框架,可以用于各種不同的機器學習方法。論文主要研究了將元匹配方法應用于核嶺回歸(kernel ridge regression, KRR)以及全連接的深度神經網絡(DNN).
在元匹配的學習框架中,大規模的訓練數據被分為元訓練集 (training meta-set) 以及元測試集 (testing meta-set)。這兩個數據集包含不同的個體和表征特性標注。元訓練集被用來訓練DNN預測模型,而元測試集則用來評估當前DNN模型在新的表征特性上的預測準確率(也即泛化性能)。特別的,隨機挑選的K個(K<5)個體數據被選作測試樣本。而在元測試集上表現最好的一個DNN輸出節點(output node)將被保留,而其他節點被移除。之后在該K個測試個體數據,微調(fine-tune)該保留的節點以及DNN模型之前與該節點相連的隱藏層參數。注意與一般的元學習或者微調策略不同的是,這里只微調DNN模型中的一個子網絡,而不是微調整個模型參數。該過程將被重復M次,直到DNN模型在元測試集上預測穩定為止。
在完成上述的元訓練過程以后,得到的DNN模型已具有了較強的在新的預測任務上的泛化能力。該模型可以直接遷移到新的表征特性數據集上,用少量的標注樣本進行訓練,即可有較好的預測性能。
實驗設置
論文在英國生物銀行(UK Biobank)和人類連接組計劃(Human Connectome Project)數據集上進行了測評。所有數據的使用均已經過了相關研究部門批準。其中 UK Biobank 包含36,848名參與者的結構MRI以及靜息fMRI腦成像數據,以及被篩選出的67個非腦成像的表征特性。而HCP包含 1,019 名參與者的結構MRI以及靜息fMRI數據,以及被篩選出的58個表征特性。所篩選的表征特性涵蓋了意識(cognition)、情緒(emotion)以及個人特質(personality)。
UK Biobank數據集被用作訓練集,用于使用元匹配來訓練預測模型。其被隨機分為元訓練集(26,848名參與者,33個表征特性)以及元測試集(10,000名參與者,34個表征特性)。而HCP數據集則被用作測試集、測試預測模型在新的表征特性上的預測準確率。其被隨機分為K個參與者用于訓練以及(1,019-K)個參與者用來測試。其中K取值為19,20,50,100和200.
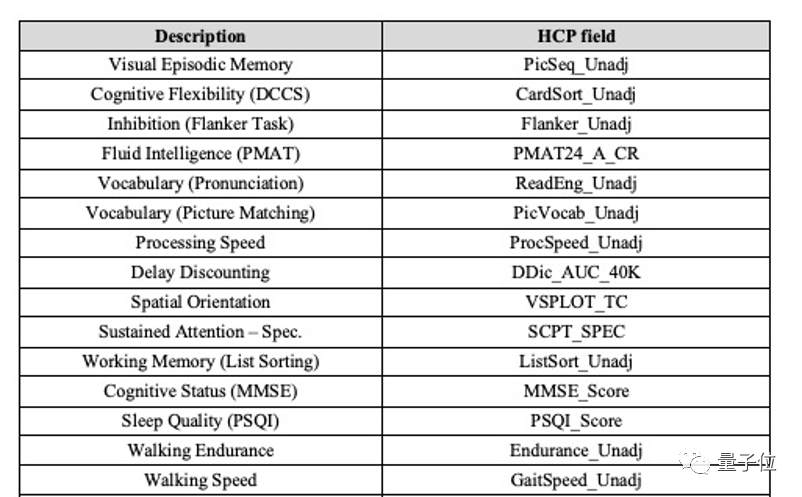
△ 圖. HCP表據集表形特性示例
實驗結論
上述方法已經在英國生物銀行(UK Biobank)的 36,848 名參與者和來自人類連接組計劃(Human Connectome Project)的 1,019 名參與者的樣本評估中顯示出有效性。
在BioBank測試集上性能超過經典的核嶺回歸(KRR)
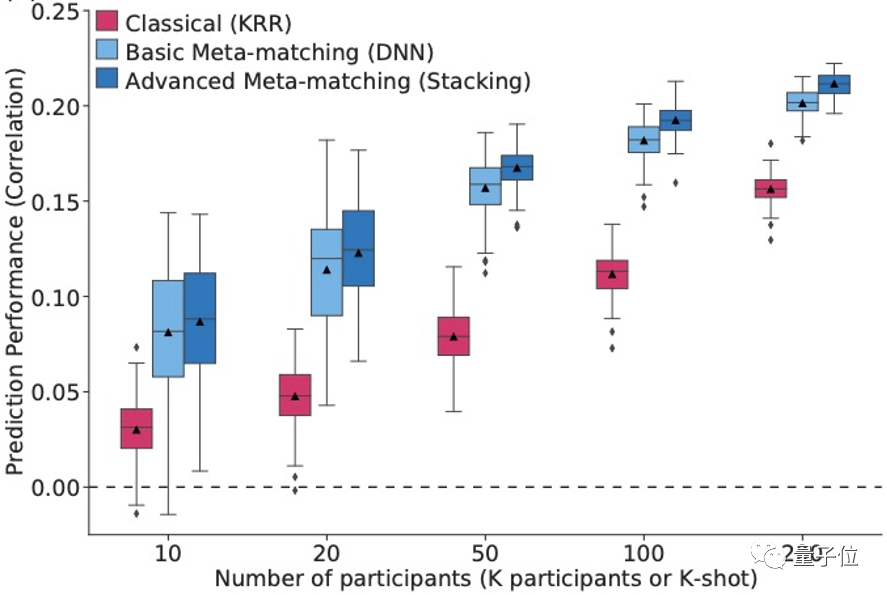
下圖展示了在UK Biobank元測試集 基于Pearson’s相關系數的準確性比較。在所有的樣本數量設置上(K值),所提出的元匹配方法在34個表征特性準確率大幅超過經典的KRR方法 (偽發現率FDR q<0.05). 例如在fMRI研究中常見的樣本數量K=20 (20-shot),基本的DNN meta-matching 方法準確率超過KRR 100% (0.124 vs. 0.052). 而如果采用coefficient of determinant (COD)作為性能指標,DNN meta-matching方法則超過KRR 400% .

在HCP小規模新數據集上顯著超過KRR
為了測試元匹配在全新的測試集上的表現,論文進一步測試了其在HCP數據集上的性能。發現同樣的,所提出的元匹配方法準確率大幅超過經典的KRR方法。例如在K=20時,元匹配方法準確率超過KRR 100% (0.123 vs. 0.047). 而在K=100時,以COD為指標,元匹配方法準確率超過KRR 800%.
討論與總結
考慮到所提出的元匹配方法是利用表征特性之間的相關性來輔助預測,其背后的預測機制有可能是非因果的。然后該研究的主要目標是提高預測準確率,并且即使是非因果預測,所得到的預測模型也有很多的應用場景。例如,抗抑郁藥物至少要4周以上才會起效,而少于50%的病人會對第一次給藥反應良好。因此,即使是非因果的預測,提高表征特性的預測能力在臨床上仍具有巨大價值。
論文所提出的元匹配方法,是基于機器學習領域中的元學習,多任務學習以及遷移學習等。例如在DNN模型上先訓練再微調可認為是遷移學習的一種形式。但是,值得注意的是,實驗表明最大的準確率提升是來自于論文提出的核心算法—元匹配。當然,更先進的機器學習算法有希望在這個方向上帶來更大的預測準確率的提升。
雖然最初的腦成像數據集來自于年輕健康的成年人,現在有越來越多的數據集側重不同的人群,例如老年人、兒童、不同的疾病等。論文提出的方法在將來也可以用于其他人群數據集的表征特性預測,例如最近的ABCD數據集包含了精神健康癥狀。
字節跳動智能創作團隊是字節跳動音視頻創新技術和業務中臺,覆蓋了機器學習、計算機視覺、圖形學、語音、拍攝編輯、特效、客戶端、服務端工程等技術領域,在部門內部實現了前沿算法—工程系統—產品全鏈路的閉環,旨在以多種形式向公司內部各業務線以及外部合作客戶提供業界前沿的內容理解、內容創作、互動體驗與消費的能力和行業解決方案。
智能創作基礎研究團隊旨在探索前沿機器學習以及計算機視覺、自然語言處理技術,解決人工智能領域里的挑戰性問題。
Nature Neuroscience是神經生物學領域最頂級的刊物之一,該雜志發表的論文涉及神經科學的各個領域,包括分子、細胞、系統、行為、認知和計算研究。