InnoDB B-TREE 索引怎么定位一條記錄?
對于 SQL 語句的執行來說,定位 B-TREE 索引中的一條記錄,是個舉足輕重的能力。
InnoDB 是基于索引組織數據的,更新、刪除操作都需要先去索引中找到具體的記錄。
插入操作也需要先找到記錄要插入到索引的哪個位置。
查詢語句的 WHERE 條件能夠命中索引時,也需要先找到 WHERE 條件對應的掃描區間的第一條記錄,然后從這條記錄開始沿著索引頁內記錄之間的單向鏈表、索引頁之間的雙向鏈表依次讀取后續的記錄。
通過以上簡短的介紹,定位 B-TREE 索引中的記錄的重要性就顯而易見了。
本文是 MySQL 8 的第一篇文章,也是查詢優化器的開篇。希望通過本文的介紹,能為大家理解后續文章打下一些基礎。
本文內容基于 MySQL 8.0.29 源碼。
正文
1、 概述
更新、刪除、查詢操作定位索引中的一條記錄,插入操作找到要插入的位置,過程基本上是一樣的,源碼中也是在同一個方法中實現。
本文以 WHERE 條件能夠命中索引為前提,介紹查詢操作定位 WHERE 條件掃描區間的第一條記錄。
定位記錄過程中進行的二分法查找、順序查找,會涉及到索引頁的部分結構。
接下來會先用 2 個小節分別介紹掃描區間、以及和定位記錄過程相關的索引頁的部分結構。
2、什么是掃描區間?
掃描區間就是 WHERE 條件中,由字段、關系運算符(>、>=、<、<=、=)組成的,用于限定需要掃描記錄的范圍。
這個一句話描述太抽象,我們展開細說。
掃描區間可以按照不同維度分類:
- 按是否有界,可以分為有界區間、單側有界區間。
- 按開閉,可以分為開區間、閉區間、半開半閉區間。
- 特殊區間,單點區間。
有界區間
- 開區間,例如:WHERE a > 100 AND a < 200,掃描區間為 (100, 200)。
- 閉區間,例如:WHERE a >= 100 AND a <= 200,掃描區間為 [100, 200]。
- 左開右閉區間,例如:WHERE a > 100 AND a <= 200,掃描區間為 (100, 200]。
- 左閉右開區間,例如:WHERE a >= 100 AND a < 200,掃描區間為 [100, 200)。
單側有界區間
- 有下界,左開區間,例如:WHERE a > 100,掃描區間為 (100, +∞)。
- 有下界,左閉區間,例如:WHERE a >= 100,掃描區間為 [100, +∞)。
- 有上界,右開區間,例如:WHERE a < 200,掃描區間為 (-∞, 200)。
- 有上界,右閉區間,例如:WHERE a <= 200,掃描區間為 (-∞, 200]。
單點區間
- 只有一個值的區間,例如:WHERE a = 100,掃描區間為 [100, 100]。
3、索引頁結構
B-TREE 索引的根結點、內結點、葉結點,都是索引頁。
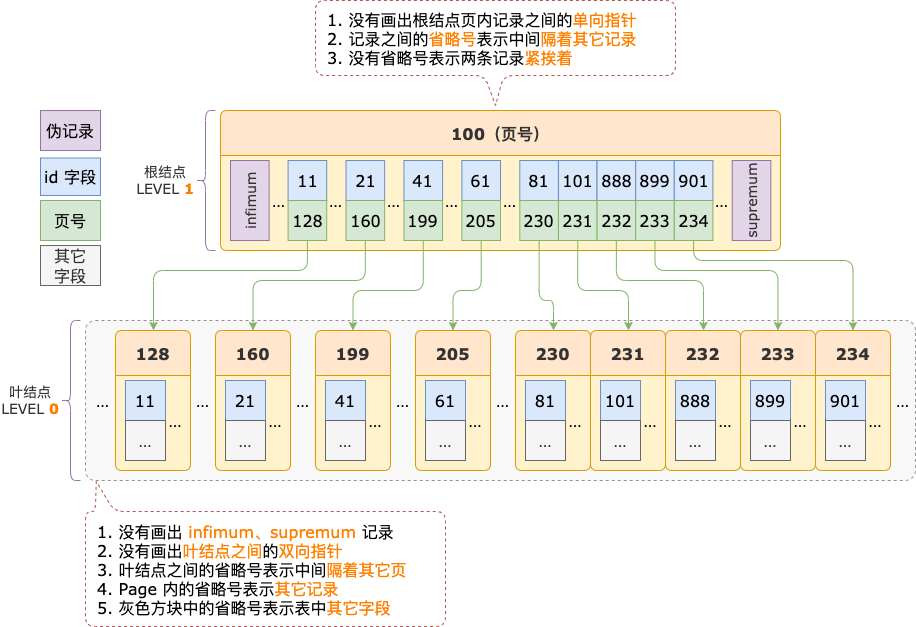
索引頁內部結構比較復雜,以后會有文章專門介紹整個索引頁的結構,接下來我們只介紹定位記錄需要用到的結構:偽記錄、記錄鏈表、槽(SLOT,也可以叫記錄分組)。
記錄鏈表
索引頁每條記錄的頭信息中,都有一個 2 字節的空間,保存著下一條記錄在當前索引頁中的偏移量。
偏移量,是記錄的數據(不包含記錄頭信息)的第一個字節的地址,減去索引頁的第一個字節的地址得到的數字。
InnoDB 索引頁最大可以設置為 64K,2 字節就可以表示索引頁中任何一個字節的偏移量。
這個 2 字節的空間,叫作 next_record,通過 next_record 可以把索引頁中的記錄串起來形成一個單向鏈表。
從任何一條記錄開始,一直往后遍歷,都能到達當前索引頁中的最后一條記錄。
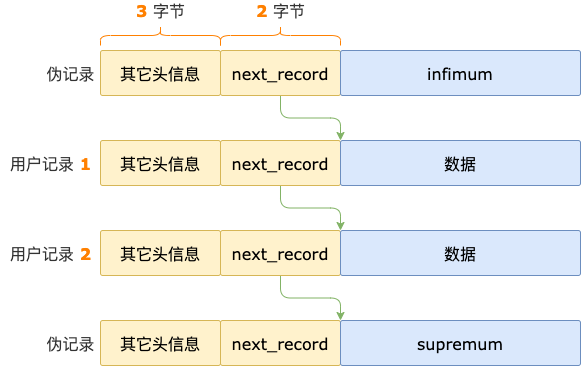
偽記錄
偽記錄指的是索引頁中,不是由用戶插入,而是 InnoDB 偷偷插入的記錄。
不管索引頁中是否有用戶插入的記錄(用戶記錄),每個索引頁中都會有 2 條偽記錄:
- infimum,索引頁中的第一條記錄。
索引頁中有用戶記錄時,infimum 的 next_record 指向第一條用戶記錄。
索引頁中沒有用戶記錄時,infimum 的 next_record 指向 supremum 記錄。
- supremum,索引頁中的最后一條記錄。
槽(SLOT)
索引頁中的 槽 分為 3 種類型:
- infimum 槽,只包含一條記錄,就是 infimum 偽記錄。
- supremum 槽,包含 1 ~ 8 條記錄,最后一條是 supremum 偽記錄,其余的是用戶記錄。
- 普通槽,包含 4 ~ 8 條用戶記錄。
每個槽占用 2 字節,保存著該槽對應的 N 條記錄中,最大的那條記錄在當前索引頁中的偏移量。
最大記錄指的是槽中按照索引字段升序排序的最后一條記錄。
索引頁中的槽,存儲在索引頁的一個專門的區域,這個區域叫作頁目錄(Page Directory)。
頁目錄區域中的槽是按照倒序排序,并且是緊挨著存儲的,第一個槽的位置在最后,第二個槽的位置在倒數第二個,依此類推,最后一個槽的位置在第一個。

4、定位掃描區間的第一條記錄
(1)抽象過程描述
B+ 樹索引包含根結點、內結點、葉結點,在一棵 3 層的 B+ 樹中定位掃描區間的第一條記錄,大體流程如下:
- 從根結點開始,確定記錄在哪個內結點中。
- 進入內結點,確定記錄在哪個葉結點中。
- 進入葉結點,確定記錄的位置。
隨著 B+ 樹的層級增多或減少,以上步驟也會相應的增多或減少。
上述流程中的每一個步驟,內部過程是一樣的,都需要先進行二分法查找、再進行順序查找。
最后,如果是根結點和內結點,就再進入下一個步驟;如果是葉結點,就沒有然后了。
二分法查找、順序查找過程如下:
第 1 步,通過二分法查找,確定記錄屬于哪個槽。
每個索引頁的頭信息中有一個 2 字節的區域,存放著當前索引頁中有多少個槽,這個區域的名字叫作 PAGE_N_DIR_SLOTS。
讀取 PAGE_N_DIR_SLOTS 的值,得到槽的數量,然后減 1,計算出槽的最大序號:high = PAGE_N_DIR_SLOTS - 1,由此,我們就得到了二分法的初始狀態的上邊界。
初始狀態的下邊界,就是第一個槽(infimum 槽)的序號,low = 0。
二分法查找可能會進行 0 ~ N 輪(N >= 1),每一輪查找,都會先通過 mid = (low + high) / 2 計算出中間位置。
然后,判斷要查找的記錄是在 low 區間(low ~ mid),還是在 high 區間(mid ~ high)。
最后,根據判斷結果,進入 low 區間或 high 區間,查找范圍就縮小了一半,繼續進行下一輪查找,依此類推,直到 low 和 high 的值不滿足循條件 high - low > 1,二分法查找結束。
這里的二分法,不僅要支持單點掃描區間,還要支持大于、大于等于、小于、小于等于這些范圍掃描區間,不能找到一條滿足掃描區間的記錄之后就馬上停下來,而是要等到 low 和 high 的值不滿足循環條件,才能結束二分法查找的過程。
二分法查找結束時,要查找的記錄總是屬于high 槽(上邊界 high 對應的槽),low 槽 總是 high 槽的前一個槽。這對于第 2 步順序查找能夠順利的找到記錄在槽中的位置很關鍵。
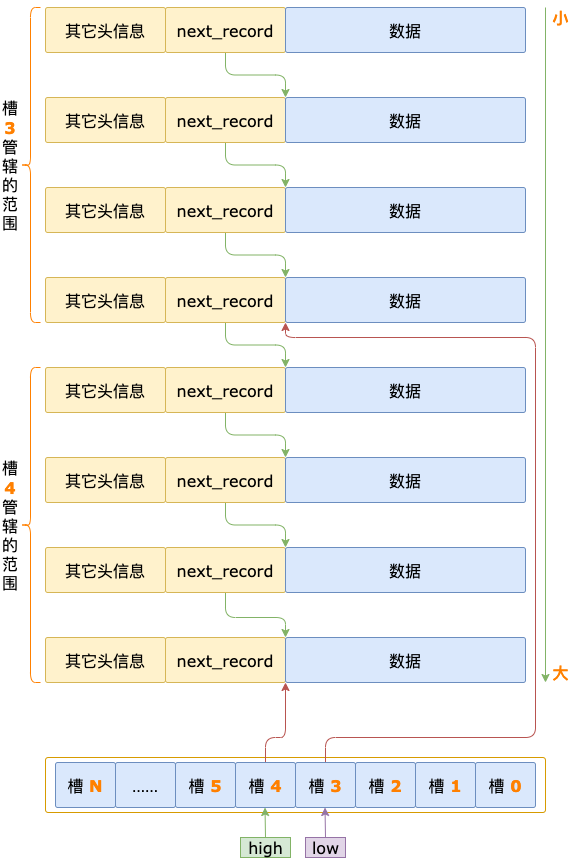
第 2 步,確定記錄所在的槽之后,沿著每條記錄頭信息中的 next_record 順序查找,確定記錄在槽中的位置。
以二分法查找結束時的狀態為基礎,繼續進行順序查找。
從 low 槽的最大記錄開始,通過頭信息中的 next_record 讀取下一條記錄。
比較下一條記錄中索引字段值和掃描區間的字段值,判斷下一條記錄是不是掃描區間的第一條記錄。
如果是,順序查找過程結束。
如果不是,繼續讀取下一條記錄,并判斷是否是掃描區間的第一條記錄,依此類推,直到要讀取的下一條記錄是 high 槽中的最大記錄,查找過程結束。
接下來,我們通過一個例子來把上面描述的抽象過程具體化。
(2)準備一棵 B+ 樹
有一個主鍵索引,包含一個 int 類型的 id 字段,結構為 B+ 樹,包含 2 層:根結點、葉結點,索引結構如下圖所示:
我們以定位 id >= 700 查詢條件對應的掃描區間 [700, +∞) 的第一條記錄為例,來分析在 B+ 樹索引中定位掃描區間的第一條記錄的過程。
(3)記錄在哪個葉結點?
示例索引的 B+ 樹,包含根結點、葉結點兩層,定位掃描區間的第一條記錄,從根結點開始。
根據抽象過程描述的步驟,先通過二分法查找確定 [700, +∞) 掃描區間的第一條記錄在哪個槽。
示例索引的 B+ 樹,根結點中有 8 個槽,初始狀態下,二分法的上下邊界分別為:low = 0、high = 8 - 1 = 7。
二分法查找
第 1 輪,計算中間位置 mid = (low + high) / 2 = (0 + 7) / 2 = 3,得到 low 區間(low ~ mid => 0 ~ 3)、high 區間(mid ~ high => 3 ~ 7)。
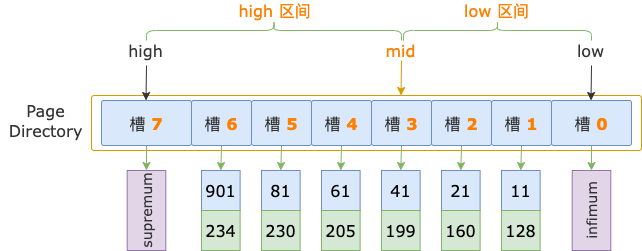
中間位置對應槽 3(序號為 3 的槽),其最大記錄的 id = 41,小于掃描區間左端點值 700,說明 id >= 700 的第一條記錄(后面就直接稱為第一條記錄了)位于 high 區間。
修改下邊界值,low = mid = 3,進入 high 區間。
第 2 輪,計算中間位置 mid = (low + high) / 2 = (3 + 7) / 2 = 5,得到 low 區間(3 ~ 5)、high 區間(5 ~ 7)。
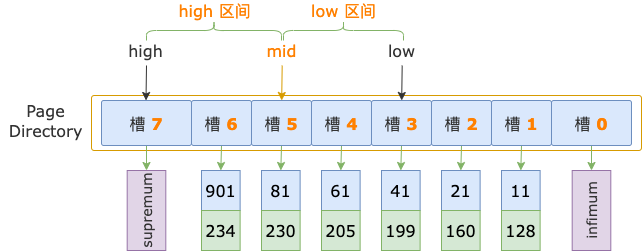
中間位置對應槽 5,其最大記錄的 id = 81,小于掃描區間左端點值 700,說明第一條記錄位于 high 區間。
修改下邊界值,low = mid = 5,進入 high 區間。
第 3 輪,計算中間位置 mid = (low + high) / 2 = (5 + 7) / 2 = 6,得到 low 區間(5 ~ 6)、high 區間(6 ~ 7)。
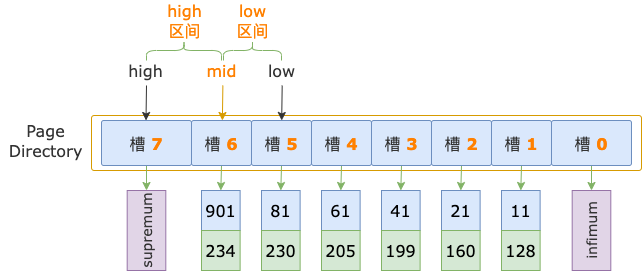
中間位置對應槽 6,其最大記錄的 id = 901,大于掃描區間左端點值 700,說明第一條記錄位于 low 區間。
修改上邊界值,high = mid = 6。
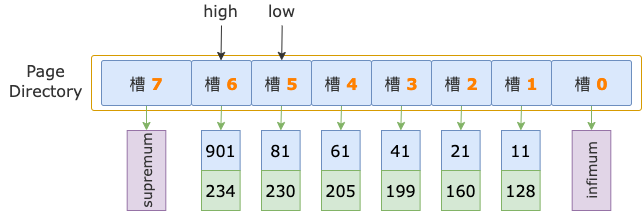
然后,high - low = 6 - 5 = 1,不滿足循環條件 high - low > 1,二分法查找結束。
掃描區間左端點值 700,大于槽 5的最大記錄的 id 值(81),小于槽 6的最大記錄的 id 值(901),說明第一條記錄屬于槽 6 的管轄范圍(此時,槽 6 就是 high 槽)。
接下來,就要進入順序查找的主場,去尋找第一條記錄在槽中的位置了。
順序查找
二分法查找結束時,low = 5(槽 5),其最大記錄的 id = 81;high = 6(槽 6),其最大記錄的 id = 901。
二分法查找過程中,已經確定了掃描區間左端點值 700 在槽 6中,所以,在順序查找過程中,不需要讀取 id = 81 這條記錄(槽 5的最后一條記錄),而是從這條記錄的下一條記錄,也就是槽 6 的第一條記錄開始。
第 1 輪,讀取 id = 81 的下一條記錄,得到 id = 101 的記錄,101 小于掃描區間左端點值 700,還需要繼續讀取下一條記錄進行比較。
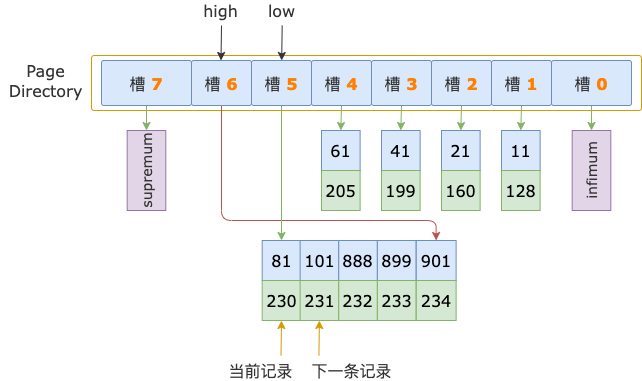
第 2 輪,讀取 id = 101 的下一條記錄,得到 id = 888 的記錄,888 大于掃描區間左端點值 700,也就鎖定了 id >= 700 的第一條記錄,位于 id 為 101 ~ 888 的記錄之間,也就是在 id = 888 之前。
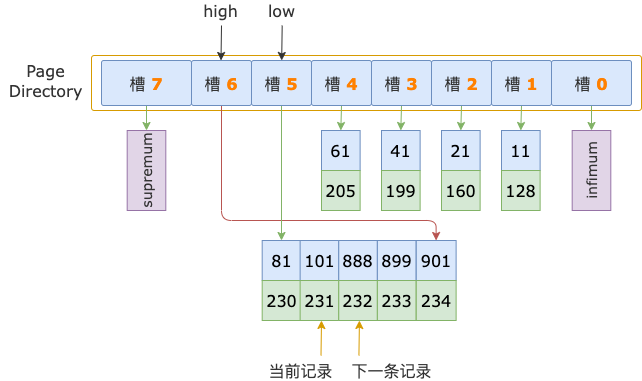
然而,id = 888 這條記錄,是其所在的葉結點索引頁的第一條用戶記錄。
id >= 700 的第一條記錄,不可能和 id = 888 這條記錄同處于一個索引頁了,只能立足于這個索引頁的前一個索引頁。
根結點中 id = 101 是 id = 888 的前一條記錄,id = 101 所在的葉結點索引頁就是 id = 888 所在的葉結點索引頁的前一頁了。
最終,id >= 700 的第一條記錄,也就位于 id = 101 這條記錄所在的葉結點索引頁中了。
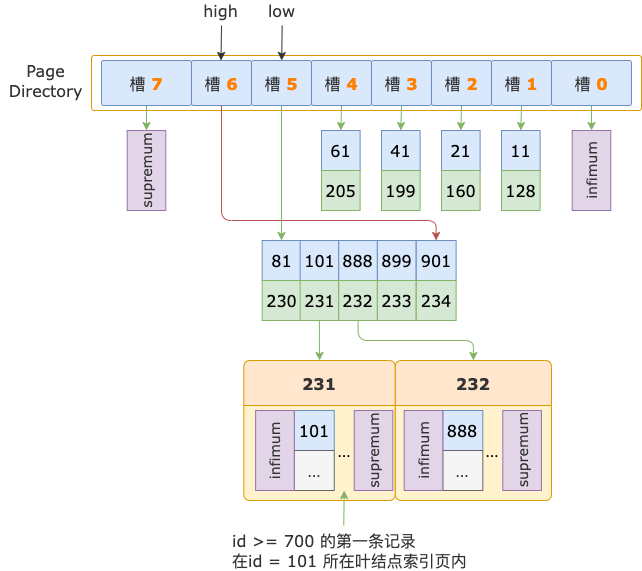
至此,經過 2 輪比較,就已經確定了 id >= 700 的第一條記錄所在的葉結點索引頁了,順序查找過程結束。
接下來,從 id = 101 這條記錄中讀取其對應的葉結點索引頁的頁號,進入葉結點。
(4)記錄在葉結點的哪個位置?
示例索引的 B+ 樹,葉結點中有 10 個槽,初始化狀態下,二分法查找的上下邊界分別為:low = 0,high = 10 - 1 = 9。
二分法查找
第 1 輪,計算中間位置 mid = (low + high) / 2 = (0 + 9) / 2 = 4,得到 low 區間(low ~ mid => 0 ~ 4)、high 區間(mid ~ high => 4 ~ 9)。
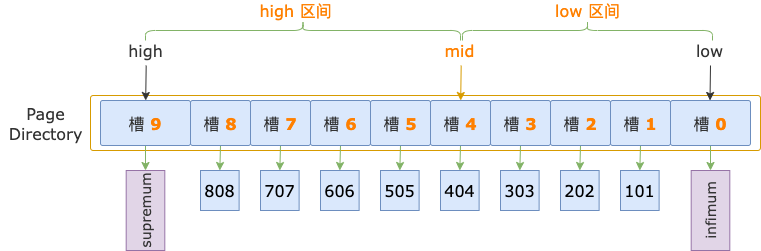
中間位置對應槽 4,其最大記錄的 id = 404,小于掃描區間左端點值 700,說明 id >= 700 的第一條記錄(簡稱為第一條記錄)位于 high 區間。
修改下邊界值,low = mid = 4,進入 high 區間。
第 2 輪,計算中間位置 mid = (low + high) / 2 = (4 + 9) / 2 = 6,得到 low 區間(4 ~ 6)、high 區間(6 ~ 9)。
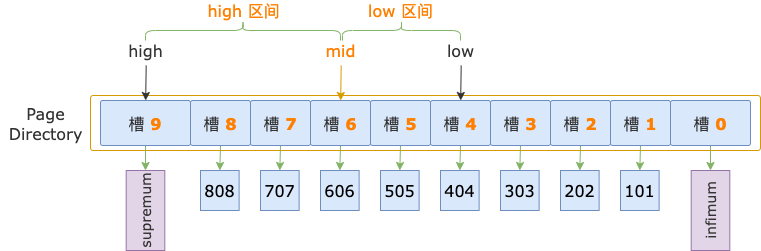
中間位置對應槽 6,其最大記錄的 id = 606,小于掃描區間左端點值 700,說明第一條記錄位于 high 區間。
修改下邊界值,low = mid = 6,進入 high 區間。
第 3 輪,計算中間位置 mid = (low + high) / 2 = (6 + 9) / 2 = 7,得到 low 區間(6 ~ 7)、high 區間(7 ~ 9)。
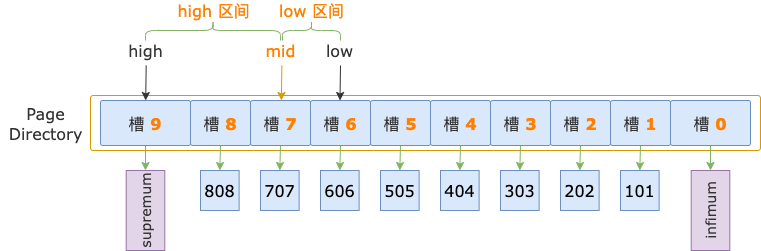
中間位置對應槽 7,其最大記錄的 id = 707,大于掃描區間左端點值 700,說明第一條記錄位于 low 區間。
修改上邊界值,up = mid = 7,此時,high - low = 7 - 6 = 1,不滿足循環條件 up - low > 1,循環結束。
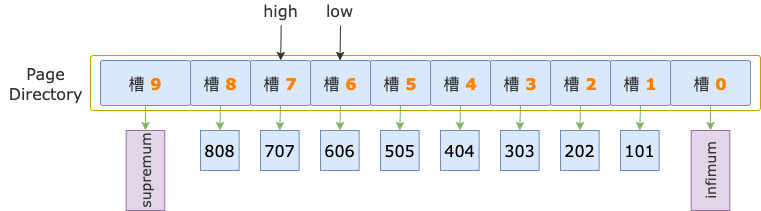
掃描區間左端點值 700,大于槽 6 的最大記錄的 id(606),小于槽 7 的最大記錄的 id(707),說明第一條記錄屬于槽 7 的管轄范圍(此時,槽 7就是 high 槽)。
接下來,就要去尋找第一條記錄在槽中的位置了。
順序查找
二分法查找結束時,low = 6(槽 6),其最大記錄的 id = 606;high = 7(槽 7),其最大記錄的 id = 707。
二分法查找過程中,已經確定了第一條記錄在槽 7 的范圍內,所以,在順序查找過程中,不需要讀取 id = 606 這條記錄(槽 6 的最后一條記錄),而是從這條記錄的下一條記錄,也就是槽 7 的第一條記錄開始。
第 1 輪,讀取 id = 606 的下一條記錄,得到 id = 666 的記錄,666 小于掃描區間左端點值 700,還需要讀取下一條記錄進行比較。
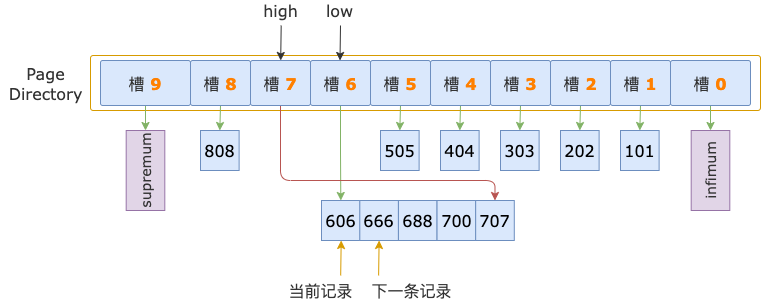
第 2 輪,讀取 id = 666 的下一條記錄,得到 id = 688 的記錄,688 小于掃描區間左端點值 700,繼續讀取下一條記錄。
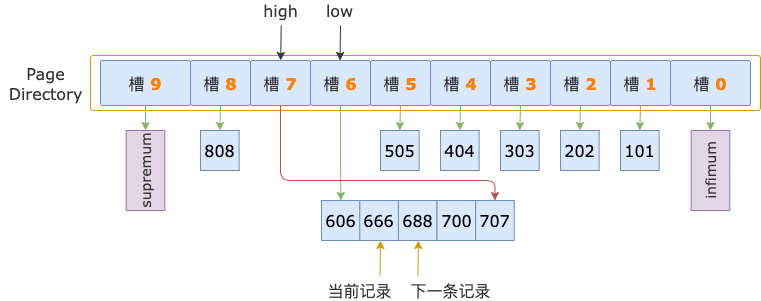
第 3 輪,讀取 id = 688 的下一條記錄,得到 id = 700 的記錄,700 等于掃描區間左端點值 700, 滿足 id >= 700 條件。
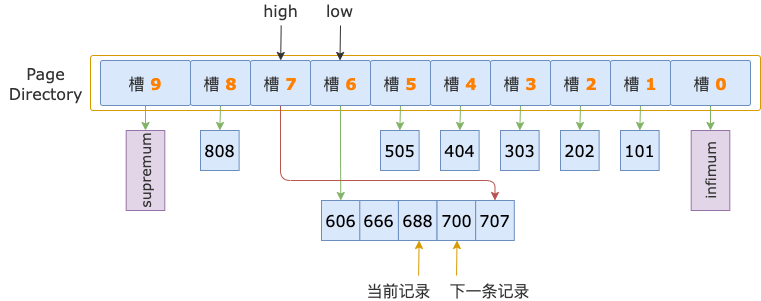
至此,經過 3 輪比較,已找到 id >= 700 對應的掃描區間 [700, +∞) 的第一條記錄,葉結點的順序查找過程結束,定位掃描區間的第一條記錄的整個過程也結束了。
5、 性能優化
前面介紹二分法查找定位槽、順序查找定位記錄位置的過程中,都涉及到對掃描區間字段值和索引字段值進行比較,但是我們沒有更進一步介紹比較的過程。
如果只是常規的比較,無非是循環掃描區間的字段,逐個和索引中對應的字段進行比較,這也就不需要再多說什么了。
但是,InnoDB 對比較的過程進行了優化,對于已經比較過的字段、字段前面的部分內容,盡可能避免進行重復比較,從而提升二分法查找、順序查找過程的執行效率,以提升性能。
InnoDB 對于葉結點的優化相比于根結點、內結點來說更進一步,我們分兩個小節分別介紹對于根結點 & 內結點、葉結點的二分法查找、順序查找的優化。
(1)根結點、內結點優化

我們基于上圖索引頁中槽的示例數據,以查詢條件 i1 >= 160 and i2 >= 44 為例,來分析定位掃描區間左端點 160, 44(用這個代表掃描區間的第一條記錄) 在哪個槽中的過程。
初始狀態下,二分法查找的上下邊界為:low = 0,high = 13。
二分法查找
第 1 輪,計算中間位置 mid = (low + high) / 2 = (0 + 13) / 2 = 6,得到 low 區間(low ~ mid => 0 ~ 6)、high 區間(mid ~ high => 6 ~ 13)。
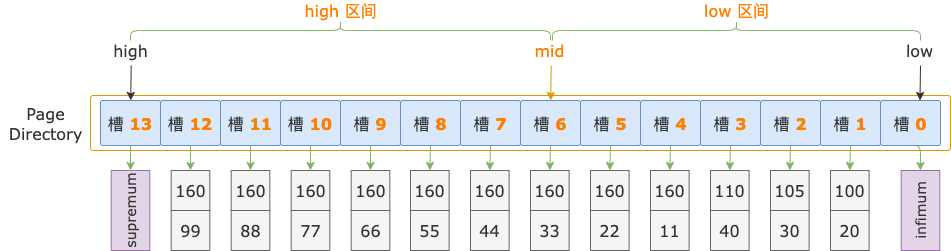
中間位置對應槽 6,其最大記錄的 i1 = 160、i2 = 33,逐個比較掃描區間左端點和槽 6 的最大記錄的 i1、i2 字段值,以確定掃描區間左端點位于 low 區間還是 high 區間。
先比較 i1 字段值,掃描區間左端點的 i1 字段值和索引中的 i1 字段值都等于 160。
接著比較 i2 字段的值,掃描區間左端點的 i2 字段值(44)大于索引記錄中的 i2 字段值(33),說明掃描區間左端點值 160, 44 位于 high 區間(槽 6 ~ 13)。
修改下邊界值,low = mid = 6,進入 high 區間。
第 2 輪,計算中間位置 mid = (low + high) / 2 = (6 + 13) / 2 = 9,得到 low 區間(6 ~ 9)、high 區間(9 ~ 13)。
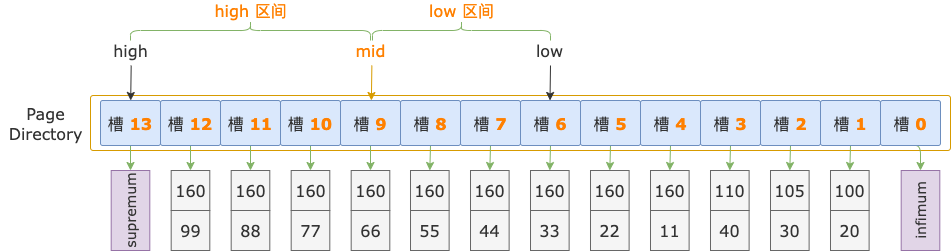
中間位置對應槽 9,其最大記錄的 i1 = 160,i2 = 66,逐個比較掃描區間左端點和槽 9 的最大記錄的 i1、i2 字段值,以確定掃描區間左端點位于 low 區間還是 high 區間。
先比較 i1 字段值,掃描區間左端點的 i1 字段值和索引記錄中的 i1 字段值都等于 160。
接著比較 i2 字段的值,掃描區間左端點的 i2 字段值(44)小于索引記錄中的 i2 字段值(66),說明掃描區間左端點值 160, 44 位于 low 區間(槽 6 ~ 9)。
修改上邊界值,high = mid = 9,進入 low 區間。
第 3 輪,計算中間位置 mid = (low + high) / 2 = (6 + 9) / 2 = 7,得到 low 區間(6 ~ 7)、high 區間(7 ~ 9)。
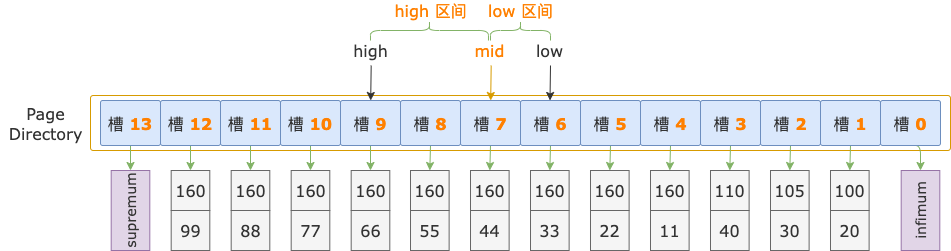
中間位置對應槽 7,其最大記錄的 i1 = 160,i2 = 44。
按照第 1、2 輪的套路,接下來該逐個比較掃描區間左端點和槽 7 的最大記錄的 i1、i2 字段值了。
但是 ……,重點來了,經過第 1 輪比較,確定了掃描區間左端點值 160, 44 位于槽 6 ~ 13 之間;經過第 2 輪比較,確定了掃描區間左端點值 160, 44 位于槽 6 ~ 9 之間。
取交集可得:掃描區間左端點值 160, 44 位于槽 6 ~ 9 之間。
從前面的示意圖中可見,槽 6 ~ 9 之間,每個槽的最大記錄的 i1 字段值都是 160,掃描區間左端點的 i1 字段值也是 160。
在這個范圍內,不管接下來要進行多少輪比較,都能夠很確定的知道記錄的 i1 字段值是等于掃描區間左端點的 i1 字段值的。
既然在比較之前就已經能確定比較的結果是相等的,也就不用比較了 i1 字段的值了。
二分法查找結束之后,后面的順序查找過程,也是在這個范圍之內,也都可以不用比較 i1 字段的值了。
好了,這一節我們要講的是 InnoDB 對定位過程的優化,目標已經達成,對于上面的例子,剩下的二分法查找和順序查找過程,就不再接著往下分析了。
(2)葉結點優化
如果能夠在二分法查找過程中鎖定一個范圍,葉結點的二分法查找、順序查找過程,不但能跳過前面 N 個已經比較過并且相等的字段,還能更進一步,跳過第 N + 1 個字段中已經比較過并且相等的前 M 字節。
不過,跳過已經比較過的字節有一些限制,只能應用于以下字段:
- tinyint、int、smallint、mediumint、bigint、tinyblob、blob、mediumblob、longblob、binary、varbinary 類型的字段。
- InnoDB B-TREE 根結點、內結點的記錄中指向子結點索引頁的頁號。
- InnoDB B-TREE 葉結點記錄中的 DB_ROW_ID、DB_TRX_ID、DB_ROLL_PTR 字段。
以上這些類型的字段,在二分法查找和順序查找的過程中,源碼中是要循環字段內容,逐字節進行比較的。
我們還是以一個具體例子來說明:
有一個 B-TREE 索引,包含 2 個字段,i1 為 int 類型,b1 為 blob 類型,如下圖所示:
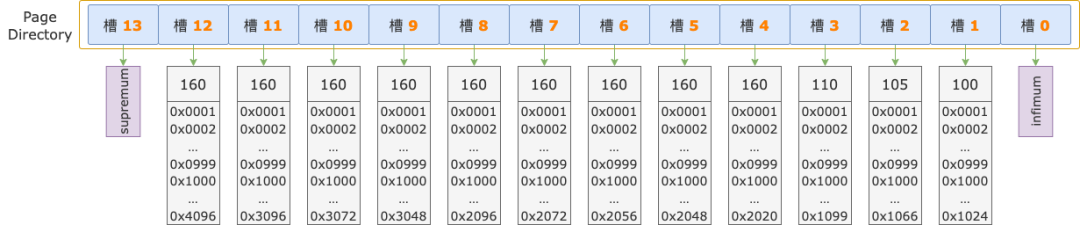
假設掃描區間左端點的 i1 字段值為 160,b1 字段值的前 1000 字節為 0x001 0x002 … 0x999 0x1000。
再次假設,經過前 2 輪比較已經鎖定了掃描區間的左端點值在 槽 6 ~ 槽 9 之間,這個區間內所有記錄的 i1 字段值都是 160,所有記錄的 b1 字段前 1000 字節都是 0x001 0x002 … 0x999 0x1000。
如果在第 3 輪及以后的二分法查找、順序查找過程中,只能跳過已經比較過的 i1 字段,對于 b1 字段,每次都要從第 1 個字節開始比較,前 1000 字節的逐字節比較就重復了。
按照我們前面介紹的場景,在鎖定范圍內(槽 6 ~ 9),掃描區間左端點的 i1 字段和所有記錄的 i1 字段值都相等;b1 字段前 1000 字節也都相等,也不用比較,是可以跳過的。
那么,在二分法查找的后續比較、順序查找過程中,只需要從 b1 字段的第 1001 字節開始比較,又能更多的避免一些重復的比較操作了。
6、總結
正式進入本文主題內容之前,2、3 小節先介紹了掃描區間的定義,以及舉例說明了每種類型的掃描區間;然后介紹了索引頁中和本文關聯比較大的結構:記錄鏈表、偽記錄、槽(SLOT)。
4 小節先對二分法查找定位槽、順序查找定位槽中的記錄進行抽象的過程描述,然后,以一個 2 層的 B-TREE 索引為例,詳細分析了二分法查找定位槽、順序查找定位槽中記錄的每一步。
5 小節介紹了 InnoDB 為了減少二分法查找定位槽、順序查找定位槽中記錄的過程中的比較次數,在鎖定一個范圍之后,對于根結點、內結點,能夠跳過已經比較過并確認為相等的字段;對于葉結點,除了能跳過字段,還能跳過字段中已經比較過并確認為相等的前面的部分字節。
本文轉載自微信公眾號「一樹一溪」,可以通過以下二維碼關注。轉載本文請聯系一樹一溪公眾號。