掘地三尺搞定 Redis 與 MySQL 數據一致性問題

?Redis 擁有高性能的數據讀寫功能,被我們廣泛用在緩存場景,一是能提高業務系統的性能,二是為數據庫抵擋了高并發的流量請求,??點我 -> 解密 Redis 為什么這么快的秘密??。
把 Redis 作為緩存組件,需要防止出現以下的一些問題,否則可能會造成生產事故。
- ??Redis 緩存滿了怎么辦???
- ??緩存穿透、緩存擊穿、緩存雪崩如何解決???
- ??Redis 數據過期了會被立馬刪除么???
- ??Redis 突然變慢了如何做性能排查并解決???
- Redis 與 MySQL 數據一致性問題怎么應對?
今天「碼哥」跟大家一起深入探索緩存的工作機制和緩存一致性應對方案。
在本文正式開始之前,我覺得我們需要先取得以下兩點的共識:
- 緩存必須要有過期時間;
- 保證數據庫跟緩存的最終一致性即可,不必追求強一致性。
一、什么是數據庫與緩存一致性
數據一致性指的是:
- 緩存中存有數據,緩存的數據值 = 數據庫中的值。
- 緩存中沒有該數據,數據庫中的值 = 最新值。
反推緩存與數據庫不一致:
- 緩存的數據值 ≠ 數據庫中的值。
- 緩存或者數據庫存在舊的數據,導致線程讀取到舊數據。
為何會出現數據一致性問題呢?
把 Redis 作為緩存的時候,當數據發生改變我們需要雙寫來保證緩存與數據庫的數據一致。
數據庫跟緩存,畢竟是兩套系統,如果要保證強一致性,勢必要引入 ??2PC??? 或 ??Paxos?? 等分布式一致性協議,或者分布式鎖等等,這個在實現上是有難度的,而且一定會對性能有影響。
如果真的對數據的一致性要求這么高,那引入緩存是否真的有必要呢?
二、緩存的使用策略
在使用緩存時,通常有以下幾種緩存使用策略用于提升系統性能:
- ?
?Cache-Aside Pattern??(旁路緩存,業務系統常用) - ?
?Read-Through Pattern?? - ?
?Write-Through Pattern?? - ?
?Write-Behind Pattern??
1、Cache-Aside (旁路緩存)
所謂「旁路緩存」,就是讀取緩存、讀取數據庫和更新緩存的操作都在應用系統來完成,業務系統最常用的緩存策略。
(1)讀取數據

讀取數據邏輯如下:
- 當應用程序需要從數據庫讀取數據時,先檢查緩存數據是否命中。
- 如果緩存未命中,則查詢數據庫獲取數據,同時將數據寫到緩存中,以便后續讀取相同數據會命中緩存,最后再把數據返回給調用者。
- 如果緩存命中,直接返回。
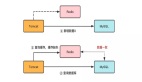
時序圖如下:

 旁路緩存讀時序圖
旁路緩存讀時序圖
優點
- 緩存中僅包含應用程序實際請求的數據,有助于保持緩存大小的成本效益。
- 實現簡單,并且能獲得性能提升。
實現的偽代碼如下:
String cacheKey = "公眾號:碼哥字節";
String cacheValue = redisCache.get(cacheKey);
//緩存命中
if (cacheValue != null) {
return cacheValue;
} else {
//緩存缺失, 從數據庫獲取數據
cacheValue = getDataFromDB();
// 將數據寫到緩存中
redisCache.put(cacheValue)
}
缺點
由于數據僅在緩存未命中后才加載到緩存中,因此初次調用的數據請求響應時間會增加一些開銷,因為需要額外的緩存填充和數據庫查詢耗時。
(2)更新數據
使用 ??cache-aside?? 模式寫數據時,如下流程。

旁路緩存寫數據
- 寫數據到數據庫;
- 將緩存中的數據失效或者更新緩存數據;
使用 ??cache-aside?? 時,最常見的寫入策略是直接將數據寫入數據庫,但是緩存可能會與數據庫不一致。
我們應該給緩存設置一個過期時間,這個是保證最終一致性的解決方案。
如果過期時間太短,應用程序會不斷地從數據庫中查詢數據。同樣,如果過期時間過長,并且更新時沒有使緩存失效,緩存的數據很可能是臟數據。
最常用的方式是刪除緩存使緩存數據失效。
為啥不是更新緩存呢?
性能問題
當緩存的更新成本很高,需要訪問多張表聯合計算,建議直接刪除緩存,而不是更新緩存數據來保證一致性。
安全問題
在高并發場景下,可能會造成查詢查到的數據是舊值,具體待會碼哥會分析,大家別急。
2、Read-Through(直讀)
當緩存未命中,也是從數據庫加載數據,同時寫到緩存中并返回給應用系統。
雖然 ??read-through??? 和 ??cache-aside??? 非常相似,在 ??cache-aside?? 中應用系統負責從數據庫獲取數據和填充緩存。
而 Read-Through 將獲取數據存儲中的值的責任轉移到了緩存提供者身上。

Read-Through
Read-Through 實現了關注點分離原則。代碼只與緩存交互,由緩存組件來管理自身與數據庫之間的數據同步。
3、Write-Through 同步直寫
與 Read-Through 類似,發生寫請求時,Write-Through 將寫入責任轉移到緩存系統,由緩存抽象層來完成緩存數據和數據庫數據的更新,時序流程圖如下:

Write-Through
??Write-Through?? 的主要好處是應用系統的不需要考慮故障處理和重試邏輯,交給緩存抽象層來管理實現。
優缺點
單獨直接使用該策略是沒啥意義的,因為該策略要先寫緩存,再寫數據庫,對寫入操作帶來了額外延遲。
當??Write-Through??? 與 ??Read-Through??? 配合使用,就能成分發揮 ??Read-Through?? 的優勢,同時還能保證數據一致性,不需要考慮如何將緩存設置失效。
 Write-Through
Write-Through
這個策略顛倒了 ??Cache-Aside?? 填充緩存的順序,并不是在緩存未命中后延遲加載到緩存,而是在數據先寫緩存,接著由緩存組件將數據寫到數據庫。
優點
- 緩存與數據庫數據總是最新的;
- 查詢性能最佳,因為要查詢的數據有可能已經被寫到緩存中了。
缺點
不經常請求的數據也會寫入緩存,從而導致緩存更大、成本更高。
4、Write-Behind
這個圖一眼看去似乎與 ??Write-Through?? 一樣,其實不是的,區別在于最后一個箭頭的箭頭:它從實心變為線。
這意味著緩存系統將異步更新數據庫數據,應用系統只與緩存系統交互。
應用程序不必等待數據庫更新完成,從而提高應用程序性能,因為對數據庫的更新是最慢的操作。

Write-Behind
這種策略下,緩存與數據庫的一致性不強,對一致性高的系統不建議使用。
三、旁路緩存下的一致性問題分析
業務場景用的最多的就是 ??Cache-Aside?? (旁路緩存) 策略,在該策略下,客戶端對數據的讀取流程是先讀取緩存,如果命中則返回;未命中,則從數據庫讀取并把數據寫到緩存中,所以讀操作不會導致緩存與數據庫的不一致。
重點是寫操作,數據庫和緩存都需要修改,而兩者就會存在一個先后順序,可能會導致數據不再一致。針對寫,我們需要考慮兩個問題:
- 先更新緩存還是更新數據庫?
- 當數據發生變化時,選擇修改緩存(update),還是刪除緩存(delete)?
將這兩個問題排列組合,會出現四種方案:
- 先更新緩存,再更新數據庫;
- 先更新數據庫,再更新緩存;
- 先刪除緩存,再更新數據庫;
- 先更新數據庫,再刪除緩存。
接下來的分析大家不必死記硬背,關鍵在于在推演的過程中大家只需要考慮以下兩個場景會不會帶來嚴重問題即可:
- 其中第一個操作成功,第二個失敗會導致什么問題?
- 在高并發情況下會不會造成讀取數據不一致?
為啥不考慮第一個失敗,第二個成功的情況呀?
你猜?
既然第一個都失敗了,第二個就不用執行了,直接在第一步返回 50x 等異常信息即可,不會出現不一致問題。
只有第一個成功,第二個失敗才讓人頭痛,想要保證他們的原子性,就涉及到分布式事務的范疇了。
1、先更新緩存,再更新數據庫
 先更新緩存再更新數據庫
先更新緩存再更新數據庫
如果先更新緩存成功,寫數據庫失敗,就會導致緩存是最新數據,數據庫是舊數據,那緩存就是臟數據了。
之后,其他查詢立馬請求進來的時候就會獲取這個數據,而這個數據數據庫中卻不存在。
數據庫都不存在的數據,緩存并返回客戶端就毫無意義了。
該方案直接 ???Pass??。
2、先更新數據庫,再更新緩存
一切正常的情況如下:
- 先寫數據庫,成功;
- 再 update 緩存,成功。
更新緩存失敗
這時候我們來推斷下,假如這兩個操作的原子性被破壞:第一步成功,第二步失敗會導致什么問題?
會導致數據庫是最新數據,緩存是舊數據,出現一致性問題。
該圖我就不畫了,與上一個圖類似,對調下 Redis 和 MySQL 的位置即可。
高并發場景
謝霸歌經常 996,腰酸脖子疼,bug 越寫越多,想去按摩推拿放提升下編程技巧。
疫情影響,單子來之不易,高端會所的技師都爭先恐后想接這一單,高并發啊兄弟們。
在進店以后,前臺會將顧客信息錄入系統,執行 ??set xx的服務技師 = 待定??的初始值表示目前無人接待保存到數據庫和緩存中,之后再安排技師按摩服務。
如下圖所示:

高并發先更新數據庫,再更新緩存
- 98 號技師先下手為強,向系統發送?
?set 謝霸歌的服務技師 = 98?? 的指令寫入數據庫,這時候系統的網絡出現波動,卡頓了,數據還沒來得及寫到緩存。 - 接下來,520 號技師也向系統發送?
?set 謝霸哥的服務技師 = 520??寫到數據庫中,并且也把這個數據寫到緩存中了。 - 這時候之前的 98 號技師的寫緩存請求開始執行,順利將數據?
?set 謝霸歌的服務技師 = 98?? 寫到緩存中。
最后發現,數據庫的值 = ??set 謝霸哥的服務技師 = 520???,而緩存的值= ??set 謝霸歌的服務技師 = 98??。
520 號技師在緩存中的最新數據被 98 號技師的舊數據覆蓋了。
所以,在高并發的場景中,多線程同時寫數據再寫緩存,就會出現緩存是舊值,數據庫是最新值的不一致情況。
該方案直接 pass。
如果第一步就失敗,直接返回 50x 異常,并不會出現數據不一致。
3、先刪緩存,再更新數據庫
按照「碼哥」前面說的套路,假設第一個操作成功,第二個操作失敗推斷下會發生什么?高并發場景下又會發生什么?
第二步寫數據庫失敗
假設現在有兩個請求:寫請求 A,讀請求 B。
寫請求 A 第一步先刪除緩存成功,寫數據到數據庫失敗,就會導致該次寫數據丟失,數據庫保存的是舊值。
接著另一個讀請 B 求進來,發現緩存不存在,從數據庫讀取舊數據并寫到緩存中。
高并發下的問題

先刪緩存,再寫數據庫
- 還是 98 號技師先下手為強,系統接收請求把緩存數據刪除,當系統準備將?
?set 肖菜雞的服務技師 = 98??寫到數據庫的時候發生卡頓,來不及寫入。 - 這時候,大堂經理向系統執行讀請求,查下肖菜雞有沒有技師接待,方便安排技師服務,系統發現緩存中沒數據,于是乎就從數據庫讀取到舊數據?
?set 肖菜雞的服務技師 = 待定??,并寫到緩存中。 - 這時候,原先卡頓的 98 號技師寫數據?
?set 肖菜雞的服務技師 = 98??到數據庫的操作完成。
這樣子會出現緩存的是舊數據,在緩存過期之前無法讀取到最數據。肖菜雞本就被 98 號技師接單了,但是大堂經理卻以為沒人接待。
該方案 pass,因為第一步成功,第二步失敗,會造成數據庫是舊數據,緩存中沒數據繼續從數據庫讀取舊值寫入緩存,造成數據不一致,還會多一次 cahche。
不論是異常情況還是高并發場景,會導致數據不一致。miss。
4、先更新數據庫,再刪緩存
經過前面的三個方案,全都被 pass 了,分析下最后的方案到底行不行。
按照「套路」,分別判斷異常和高并發會造成什么問題。
該策略可以知道,在寫數據庫階段失敗的話就直返返回客戶端異常,不需要執行緩存操作了。
所以第一步失敗不會出現數據不一致的情況。
刪緩存失敗
重點在于第一步寫最新數據到數據庫成功,刪除緩存失敗怎么辦?
可以把這兩個操作放在一個事務中,當緩存刪除失敗,那就把寫數據庫回滾。
高并發場景下不合適,容易出現大事務,造成死鎖問題。
如果不回滾,那就出現數據庫是新數據,緩存還是舊數據,數據不一致了,咋辦?
所以,我們要想辦法讓緩存刪除成功,不然只能等到有效期失效那可不行。
使用重試機制。
比如重試三次,三次都失敗則記錄日志到數據庫,使用分布式調度組件 xxl-job 等實現后續的處理。
在高并發的場景下,重試最好使用異步方式,比如發送消息到 mq 中間件,實現異步解耦。
亦或是利用 Canal 框架訂閱 MySQL binlog 日志,監聽對應的更新請求,執行刪除對應緩存操作。
高并發場景
再來分析下高并發讀寫會有什么問題……

先寫數據庫后刪緩存
- 98 號技師先下手為強,接下肖菜雞的這筆生意,數據庫執行?
?set 肖菜雞的服務技師 = 98??;還是網絡卡頓了下,沒來得及執行刪除緩存操作。 - 主管 Candy 向系統執行讀請求,查下肖菜雞有沒有技師接待,發現緩存中有數據?
?肖菜雞的服務技師 = 待定??,直接返回信息給客戶端,主管以為沒人接待。 - 原先 98 號技師接單,由于卡頓沒刪除緩存的操作現在執行刪除成功。
讀請求可能出現少量讀取舊數據的情況,但是很快舊數據就會被刪除,之后的請求都能獲取最新數據,問題不大。
還有一種比較極端的情況,緩存自動失效的時候又遇到了高并發讀寫的情況,假設這會有兩個請求,一個線程 A 做查詢操作,一個線程 B 做更新操作,那么會有如下情形產生:

緩存忽然失效
- 緩存的過期時間到期,緩存失效。
- 線程 A 讀請求讀取緩存,沒命中,則查詢數據庫得到一個舊的值(因為 B 會寫新值,相對而言就是舊的值了),準備把數據寫到緩存時發送網絡問題卡頓了。
- 線程 B 執行寫操作,將新值寫數據庫。
- 線程 B 執行刪除緩存。
- 線程 A 繼續,從卡頓中醒來,把查詢到的舊值寫到入緩存。
碼哥,這咋玩,還是出現了不一致的情況啊。
不要慌,發生這個情況的概率微乎其微,發生上述情況的必要條件是:
- 步驟 (3)的寫數據庫操作要比步驟(2)讀操作耗時短速度快,才可能使得步驟(4)先于步驟(5)。
- 緩存剛好到達過期時限。
通常 MySQL 單機的 QPS 大概 5K 左右,而 TPS 大概 1k 左右,(ps:Tomcat 的 QPS 4K 左右,TPS = 1k 左右)。
數據庫讀操作是遠快于寫操作的(正是因為如此,才做讀寫分離),所以步驟(3)要比步驟(2)更快這個情景很難出現,同時還要配合緩存剛好失效。
所以,在用旁路緩存策略的時候,對于寫操作推薦使用:先更新數據庫,再刪除緩存。
四、一致性解決方案有哪些?
最后,針對 Cache-Aside (旁路緩存) 策略,寫操作使用先更新數據庫,再刪除緩存的情況下,我們來分析下數據一致性解決方案都有哪些?
1、緩存延時雙刪
如果采用先刪除緩存,再更新數據庫如何避免出現臟數據?
采用延時雙刪策略。
- 先刪除緩存。
- 寫數據庫。
- 休眠 500 毫秒,再刪除緩存。
這樣子最多只會出現 500 毫秒的臟數據讀取時間。關鍵是這個休眠時間怎么確定呢?
延遲時間的目的就是確保讀請求結束,寫請求可以刪除讀請求造成的緩存臟數據。
所以我們需要自行評估項目的讀數據業務邏輯的耗時,在讀耗時的基礎上加幾百毫秒作為延遲時間即可。
2、刪除緩存重試機制
緩存刪除失敗怎么辦?比如延遲雙刪的第二次刪除失敗,那豈不是無法刪除臟數據。
使用重試機制,保證刪除緩存成功。
比如重試三次,三次都失敗則記錄日志到數據庫并發送警告讓人工介入。
在高并發的場景下,重試最好使用異步方式,比如發送消息到 mq 中間件,實現異步解耦。
 重試機制
重試機制
第(5)步如果刪除失敗且未達到重試最大次數則將消息重新入隊,直到刪除成功,否則就記錄到數據庫,人工介入。
該方案有個缺點,就是對業務代碼中造成侵入,于是就有了下一個方案,啟動一個專門訂閱 數據庫 binlog 的服務讀取需要刪除的數據進行緩存刪除操作。
3、讀取 binlog 異步刪除

binlog異步刪除
- 更新數據庫;
- 數據庫會把操作信息記錄在 binlog 日志中;
- 使用 canal 訂閱 binlog 日志獲取目標數據和 key;
- 緩存刪除系統獲取 canal 的數據,解析目標 key,嘗試刪除緩存。
- 如果刪除失敗則將消息發送到消息隊列;
- 緩存刪除系統重新從消息隊列獲取數據,再次執行刪除操作。
總結
緩存策略的最佳實踐是 Cache Aside Pattern。分別分為讀緩存最佳實踐和寫緩存最佳實踐。
讀緩存最佳實踐:先讀緩存,命中則返回;未命中則查詢數據庫,再寫到數據庫。
寫緩存最佳實踐:
- 先寫數據庫,再操作緩存;
- 直接刪除緩存,而不是修改,因為當緩存的更新成本很高,需要訪問多張表聯合計算,建議直接刪除緩存,而不是更新,另外,刪除緩存操作簡單,副作用只是增加了一次 chache miss,建議大家使用該策略。
在以上最佳實踐下,為了盡可能保證緩存與數據庫的一致性,我們可以采用延遲雙刪。
防止刪除失敗,我們采用異步重試機制保證能正確刪除,異步機制我們可以發送刪除消息到 mq 消息中間件,或者利用 canal 訂閱 MySQL binlog 日志監聽寫請求刪除對應緩存。
那么,如果我非要保證絕對一致性怎么辦,先給出結論:
沒有辦法做到絕對的一致性,這是由 CAP 理論決定的,緩存系統適用的場景就是非強一致性的場景,所以它屬于 CAP 中的 AP。
所以,我們得委曲求全,可以去做到 BASE 理論中說的最終一致性。
其實一旦在方案中使用了緩存,那往往也就意味著我們放棄了數據的強一致性,但這也意味著我們的系統在性能上能夠得到一些提升。
所謂 tradeoff 正是如此。