一文講透數據庫與 Redis 緩存一致性問題
在真實的業務場景中,我們的業務的數據——例如訂單、會員、支付等——都是持久化到數據庫中的,因為數據庫能有很好的事務保證、持久化保證。
但是,正因為數據庫要能夠滿足這么多優秀的功能特性,使得數據庫在設計上通常難以兼顧到性能,因此往往不能滿足大型流量下的性能要求,像是 MySQL 數據庫只能承擔“千”這個級別的 QPS,否則很可能會不穩定,進而導致整個系統的故障。
但是客觀上,我們的業務規模很可能要求著更高的 QPS,有些業務的規模本身就非常大,也有些業務會遇到一些流量高峰,比如電商會遇到大促的情況。
而這時候大部分的流量實際上都是讀請求,而且大部分數據也是沒有那么多變化的,如熱門商品信息、微博的內容等常見數據就是如此。此時,緩存就是我們應對此類場景的利器。
1.緩存的意義
所謂緩存,實際上就是用空間換時間,準確地說是用更高速的空間來換時間,從而整體上提升讀的性能。
何為更高速的空間呢?
更快的存儲介質。通常情況下,如果說數據庫的速度慢,就得用更快的存儲組件去替代它,目前最常見的就是 Redis(內存存儲)。Redis 單實例的讀 QPS 可以高達 10w/s,90% 的場景下只需要正確使用 Redis 就能應對。
就近使用本地內存。就像 CPU 也有高速緩存一樣,緩存也可以分為一級緩存、二級緩存。即便 Redis 本身性能已經足夠高了,但訪問一次 Redis 畢竟也需要一次網絡 IO,而使用本地內存無疑有更快的速度。不過單機的內存是十分有限的,所以這種一級緩存只能存儲非常少量的數據,通常是最熱點的那些 key 對應的數據。這就相當于額外消耗寶貴的服務內存去換取高速的讀取性能。
2.引入緩存后的一致性挑戰
用空間換時間,意味著數據同時存在于多個空間。最常見的場景就是數據同時存在于 Redis 與 MySQL 上(為了問題的普適性,后面舉例中若沒有特別說明,緩存均指 Redis 緩存)。
實際上,最權威最全的數據還是在 MySQL 里的。而萬一 Redis 數據沒有得到及時的更新(例如數據庫更新了沒更新到 Redis),就出現了數據不一致。
大部分情況下,只要使用了緩存,就必然會有不一致的情況出現,只是說這個不一致的時間窗口是否能做到足夠的小。有些不合理的設計可能會導致數據持續不一致,這是我們需要改善設計去避免的。
這里的一致性實際上對于本地緩存也是同理的,例如數據庫更新后沒有及時更新本地緩存,也是有一致性問題的,下文統一以 Redis 緩存作為引子講述,實際上處理本地緩存原理基本一致。
緩存不一致性無法客觀地完全消滅
為什么我們幾乎沒辦法做到緩存和數據庫之間的強一致呢?
理想情況下,我們需要在數據庫更新完后把對應的最新數據同步到緩存中,以便在讀請求的時候能讀到新的數據而不是舊的數據(臟數據)。但是很可惜,由于數據庫和 Redis 之間是沒有事務保證的,所以我們無法確保寫入數據庫成功后,寫入 Redis 也是一定成功的;即便 Redis 寫入能成功,在數據庫寫入成功后到 Redis 寫入成功前的這段時間里,Redis 數據也肯定是和 MySQL 不一致的。如下兩圖所示:
 圖片
圖片
無法事務保持一致
所以說這個時間窗口是沒辦法完全消滅的,除非我們付出極大的代價,使用分布式事務等各種手段去維持強一致,但是這樣會使得系統的整體性能大幅度下降,甚至比不用緩存還慢,這樣不就與我們使用緩存的目標背道而馳了嗎?
不過雖然無法做到強一致,但是我們能做到的是緩存與數據庫達到最終一致,而且不一致的時間窗口我們能做到盡可能短,按照經驗來說,如果能將時間優化到 1ms 之內,這個一致性問題帶來的影響我們就可以忽略不計。
 圖片
圖片
3.更新緩存的手段
通常情況下,我們在處理查詢請求的時候,使用緩存的邏輯如下:
data = queryDataRedis(key);
if (data ==null) {
data = queryDataMySQL(key); //緩存查詢不到,從MySQL做查詢
if (data!=null) {
updateRedis(key, data);//查詢完數據后更新MySQL最新數據到Redis
}
}也就是說優先查詢緩存,查詢不到才查詢數據庫。如果這時候數據庫查到數據了,就將緩存的數據進行更新。這是我們常說的 cache aside 的策略,也是最常用的策略。
這樣的邏輯是正確的,而一致性的問題一般不來源于此,而是出現在處理寫請求的時候。所以我們簡化成最簡單的寫請求的邏輯,此時你可能會面臨多個選擇,究竟是直接更新緩存,還是失效緩存?而無論是更新緩存還是失效緩存,都可以選擇在更新數據庫之前,還是之后操作。
這樣就演變出 4 個策略:更新數據庫后更新緩存、更新數據庫前更新緩存、更新數據庫后刪除緩存、更新數據庫前刪除緩存。下面我們來分別講述。
更新數據庫后更新緩存的不一致問題
一種常見的操作是,設置一個過期時間,讓寫請求以數據庫為準,過期后,讀請求同步數據庫中的最新數據給緩存。那么在加入了過期時間后,是否就不會有問題了呢?并不是這樣。
大家設想一下這樣的場景。
假如這里有一個計數器,把數據庫自減 1,原始數據庫數據是 100,同時有兩個寫請求申請計數減一,假設線程 A 先減數據庫成功,線程 B 后減數據庫成功。那么這時候數據庫的值是 98,緩存里正確的值應該也要是 98。
但是特殊場景下,你可能會遇到這樣的情況:
- 線程 A 和線程 B 同時更新這個數據。
- 更新數據庫的順序是先 A 后 B。
- 更新緩存時順序是先 B 后 A。
如果我們的代碼邏輯還是更新數據庫后立刻更新緩存的數據,那么——
updateMySQL();
updateRedis(key, data);就可能出現:數據庫的值是 100->99->98,但是緩存的數據卻是 100->98->99,也就是數據庫與緩存的不一致。而且這個不一致只能等到下一次數據庫更新或者緩存失效才可能修復。
時間 | 線程A(寫請求) | 線程B(寫請求) | 問題 |
T1 | 更新數據庫為99 | ||
T2 | 更新數據庫為98 | ||
T3 | 更新緩存數據為98 | ||
T4 | 更新緩存數據為99 | 此時緩存的值被顯式更新為99,但是實際上數據庫的值已經是98,數據不一致 |
當然,如果更新 Redis 本身是失敗的話,兩邊的值固然也是不一致的,這個前文也闡述過,幾乎無法根除。
 圖片
圖片
更新數據庫前更新緩存的不一致問題
那你可能會想,這是否表示,我應該先讓緩存更新,之后再去更新數據庫呢?類似這樣:
updateRedis(key, data);//先更新緩存
updateMySQL();//再更新數據庫這樣操作產生的問題更是顯而易見的,因為我們無法保證數據庫的更新成功,萬一數據庫更新失敗了,你緩存的數據就不只是臟數據,而是錯誤數據了。
 圖片
圖片
你可能會想,是否我在更新數據庫失敗的時候做 Redis 回滾的操作能夠解決呢?這其實也是不靠譜的,因為我們也不能保證這個回滾的操作 100% 被成功執行。
同時,在寫寫并發的場景下,同樣有類似的一致性問題,請看以下情況:
- 線程 A 和線程 B 同時更新同這個數據。
- 更新緩存的順序是先 A 后 B。
- 更新數據庫的順序是先 B 后 A。
舉個例子。線程 A 希望把計數器置為 0,線程 B 希望置為 1。而按照以上場景,緩存確實被設置為 1,但數據庫卻被設置為 0。
所以通常情況下,更新緩存再更新數據庫是我們應該避免使用的一種手段。
更新數據庫前刪除緩存的問題
那如果采取刪除緩存的策略呢?也就是說我們在更新數據庫的時候失效對應的緩存,讓緩存在下次觸發讀請求時進行更新,是否會更好呢?同樣地,針對在更新數據庫前和數據庫后這兩個刪除時機,我們來比較下其差異。
最直觀的做法,我們可能會先讓緩存失效,然后去更新數據庫,代碼邏輯如下:
deleteRedis(key);//先刪除緩存讓緩存失效
updateMySQL();//再更新數據庫這樣的邏輯看似沒有問題,畢竟刪除緩存后即便數據庫更新失敗了,也只是緩存上沒有數據而已。然后并發兩個寫請求過來,無論怎么樣的執行順序,緩存最后的值也都是會被刪除的,也就是說在并發寫寫的請求下這樣的處理是沒問題的。
然而,這種處理在讀寫并發的場景下卻存在著隱患。
還是剛剛更新計數的例子。例如現在緩存的數據是 100,數據庫也是 100,這時候需要對此計數減 1,減成功后,數據庫應該是 99。如果這之后觸發讀請求,緩存如果有效的話,里面應該也要被更新為 99 才是正確的。
那么思考下這樣的請求情況:
- 線程 A 更新這個數據的同時,線程 B 讀取這個數據。
- 線程 A 成功刪除了緩存里的老數據,這時候線程 B 查詢數據發現緩存失效。
- 線程 A 更新數據庫成功。
時間 | 線程A(寫請求) | 線程B(讀請求) | 問題 |
T1 | 刪除緩存值 | ||
T2 | 1.讀取緩存數據,緩存缺失,從數據庫讀取數據100 | ||
T3 | 更新數據庫中的數據X的值為99 | ||
T4 | 將數據100的值寫入緩存 | 此時緩存的值被顯式更新為100,但是實際上數據庫的值已經是99了 |
可以看到,在讀寫并發的場景下,一樣會有不一致的問題。
針對這種場景,有個做法是所謂的“延遲雙刪策略”,就是說,既然可能因為讀請求把一個舊的值又寫回去,那么我在寫請求處理完之后,等到差不多的時間延遲再重新刪除這個緩存值。
時間 | 線程A(寫請求) | 線程C(新的讀請求) | 線程D(新的讀請求) | 問題 |
T5 | sleep(N) | 緩存存在,讀取到緩存舊值100 | 其他線程可能在雙刪成功前讀到臟數據 | |
T6 | 刪除緩存值 | |||
T7 | 緩存缺失,從數據庫讀取數據的最新值(99) |
這種解決思路的關鍵在于對 N 的時間的判斷,如果 N 時間太短,線程 A 第二次刪除緩存的時間依舊早于線程 B 把臟數據寫回緩存的時間,那么相當于做了無用功。而 N 如果設置得太長,那么在觸發雙刪之前,新請求看到的都是臟數據。
更新數據庫后刪除緩存
那如果我們把更新數據庫放在刪除緩存之前呢,問題是否解決?我們繼續從讀寫并發的場景看下去,有沒有類似的問題。
時間 | 線程A(寫請求) | 線程B(讀請求) | 線程C(讀請求) | 潛在問題 |
T1 | 更新主庫 X = 99(原值 X = 100) | |||
T2 | 讀取數據,查詢到緩存還有數據,返回100 | 線程C實際上讀取到了和數據庫不一致的數據 | ||
T3 | 刪除緩存 | |||
T4 | 查詢緩存,緩存缺失,查詢數據庫得到當前值99 | |||
T5 | 將99寫入緩存 |
可以看到,大體上,采取先更新數據庫再刪除緩存的策略是沒有問題的,僅在更新數據庫成功到緩存刪除之間的時間差內——[T2,T3)的窗口 ,可能會被別的線程讀取到老值。
而在開篇的時候我們說過,緩存不一致性的問題無法在客觀上完全消滅,因為我們無法保證數據庫和緩存的操作是一個事務里的,而我們能做到的只是盡量縮短不一致的時間窗口。
在更新數據庫后刪除緩存這個場景下,不一致窗口僅僅是 T2 到 T3 的時間,內網狀態下通常不過 1ms,在大部分業務場景下我們都可以忽略不計。因為大部分情況下一個用戶的請求很難能再 1ms 內快速發起第二次。
但是真實場景下,還是會有一個情況存在不一致的可能性,這個場景是讀線程發現緩存不存在,于是讀寫并發時,讀線程回寫進去老值。并發情況如下:
時間 | 線程A(寫請求) | 線程B(讀請求--緩存不存在場景) | 潛在問題 |
T1 | 查詢緩存,緩存缺失,查詢數據庫得到當前值100 | ||
T2 | 更新主庫 X = 99(原值 X = 100) | ||
T3 | 刪除緩存 | ||
T4 | 將100寫入緩存 | 此時緩存的值被顯式更新為100,但是實際上數據庫的值已經是99了 |
總的來說,這個不一致場景出現條件非常嚴格,因為并發量很大時,緩存不太可能不存在;如果并發很大,而緩存真的不存在,那么很可能是這時的寫場景很多,因為寫場景會刪除緩存。
所以待會我們會提到,寫場景很多時候實際上并不適合采取刪除策略。
總結四種更新策略
終上所述,我們對比了四個更新緩存的手段,做一個總結對比,其中應對方案也提供參考,具體不做展開,如下表:
策略 | 并發場景 | 潛在問題 | 應對方案 |
更新數據庫+更新緩存 | 寫+讀 | 線程A未更新完緩存之前,線程B的讀請求會短暫讀到舊值 | 可以忽略 |
寫+寫 | 更新數據庫的順序是先A后B,但更新緩存時順序是先B后A,數據庫和緩存數據不一致 | 分布式鎖(操作重) | |
更新緩存+更新數據庫 | 無并發 | 線程A還未更新完緩存但是更新數據庫可能失敗 | 利用MQ確認數據庫更新成功(較復雜) |
寫+寫 | 更新緩存的順序是先A后B,但更新數據庫時順序是先B后A | 分布式鎖(操作很重) | |
刪除緩存值+更新數據庫 | 寫+讀 | 寫請求的線程A刪除了緩存在更新數據庫之前,這時候讀請求線程B到來,因為緩存缺失,則把當前數據讀取出來放到緩存,而后線程A更新成功了數據庫 | 延遲雙刪(但是延遲的時間不好估計,且延遲的過程中依舊有不一致的時間窗口) |
更新數據庫+刪除緩存值 | 寫+讀(緩存命中) | 線程A完成數據庫更新成功后,尚未刪除緩存,線程B有并發讀請求會讀到舊的臟數據 | 可以忽略 |
寫+讀(緩存不命中) | 讀請求不命中緩存,寫請求處理完之后讀請求才回寫緩存,此時緩存不一致 | 分布式鎖(操作重) |
從一致性的角度來看,采取更新數據庫后刪除緩存值,是更為適合的策略。因為出現不一致的場景的條件更為苛刻,概率相比其他方案更低。
那么是否更新緩存這個策略就一無是處呢?不是的!
刪除緩存值意味著對應的 Key 會失效,那么這時候讀請求都會打到數據庫。如果這個數據的寫操作非常頻繁,就會導致緩存的作用變得非常小。而如果這時候某些 Key 還是非常大的熱 Key,就可能因為扛不住數據量而導致系統不可用。
如下圖所示:

刪除策略頻繁的緩存失效導致讀請求無法利用緩存
所以做個簡單總結,足以適應絕大部分的互聯網開發場景的決策:
- 針對大部分讀多寫少場景,建議選擇更新數據庫后刪除緩存的策略。
- 針對讀寫相當或者寫多讀少的場景,建議選擇更新數據庫后更新緩存的策略。
4.最終一致性如何保證?
緩存設置過期時間
第一個方法便是我們上面提到的,當我們無法確定 MySQL 更新完成后,緩存的更新/刪除一定能成功,例如 Redis 掛了導致寫入失敗了,或者當時網絡出現故障,更常見的是服務當時剛好發生重啟了,沒有執行這一步的代碼。
這些時候 MySQL 的數據就無法刷到 Redis 了。為了避免這種不一致性永久存在,使用緩存的時候,我們必須要給緩存設置一個過期時間,例如 1 分鐘,這樣即使出現了更新 Redis 失敗的極端場景,不一致的時間窗口最多也只是 1 分鐘。
這是我們最終一致性的兜底方案,萬一出現任何情況的不一致問題,最后都能通過緩存失效后重新查詢數據庫,然后回寫到緩存,來做到緩存與數據庫的最終一致。
5.如何減少緩存刪除/更新的失敗?
萬一刪除緩存這一步因為服務重啟沒有執行,或者 Redis 臨時不可用導致刪除緩存失敗了,就會有一個較長的時間(緩存的剩余過期時間)是數據不一致的。
那我們有沒有什么手段來減少這種不一致的情況出現呢?這時候借助一個可靠的消息中間件就是一個不錯的選擇。
因為消息中間件有 ATLEAST-ONCE 的機制,如下圖所示。
 圖片
圖片
我們把刪除 Redis 的請求以消費 MQ 消息的手段去失效對應的 Key 值,如果 Redis 真的存在異常導致無法刪除成功,我們依舊可以依靠 MQ 的重試機制來讓最終 Redis 對應的 Key 失效。
而你們或許會問,極端場景下,是否存在更新數據庫后 MQ 消息沒發送成功,或者沒機會發送出去機器就重啟的情況?
這個場景的確比較麻煩,如果 MQ 使用的是 RocketMQ,我們可以借助 RocketMQ 的事務消息,來讓刪除緩存的消息最終一定發送出去。而如果你沒有使用 RocketMQ,或者你使用的消息中間件并沒有事務消息的特性,則可以采取消息表的方式讓更新數據庫和發送消息一起成功。事實上這個話題比較大了,我們不在這里展開。
6.如何處理復雜的多緩存場景?
有些時候,真實的緩存場景并不是數據庫中的一個記錄對應一個 Key 這么簡單,有可能一個數據庫記錄的更新會牽扯到多個 Key 的更新。還有另外一個場景是,更新不同的數據庫的記錄時可能需要更新同一個 Key 值,這常見于一些 App 首頁數據的緩存。
我們以一個數據庫記錄對應多個 Key 的場景來舉例。
假如系統設計上我們緩存了一個粉絲的主頁信息、主播打賞榜 TOP10 的粉絲、單日 TOP 100 的粉絲等多個信息。如果這個粉絲注銷了,或者這個粉絲觸發了打賞的行為,上面多個 Key 可能都需要更新。只是一個打賞的記錄,你可能就要做:
updateMySQL();//更新數據庫一條記錄
deleteRedisKey1();//失效主頁信息的緩存
updateRedisKey2();//更新打賞榜TOP10
deleteRedisKey3();//更新單日打賞榜TOP100這就涉及多個 Redis 的操作,每一步都可能失敗,影響到后面的更新。甚至從系統設計上,更新數據庫可能是單獨的一個服務,而這幾個不同的 Key 的緩存維護卻在不同的 3 個微服務中,這就大大增加了系統的復雜度和提高了緩存操作失敗的可能性。最可怕的是,操作更新記錄的地方很大概率不只在一個業務邏輯中,而是散發在系統各個零散的位置。
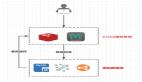
針對這個場景,解決方案和上文提到的保證最終一致性的操作一樣,就是把更新緩存的操作以 MQ 消息的方式發送出去,由不同的系統或者專門的一個系統進行訂閱,而做聚合的操作。如下圖:
 圖片
圖片
不同業務系統訂閱 MQ 消息單獨維護各自的緩存 Key
7.通過訂閱 MySQL binlog 的方式處理緩存
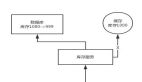
上面講到的 MQ 處理方式需要業務代碼里面顯式地發送 MQ 消息。還有一種優雅的方式便是訂閱 MySQL 的 binlog,監聽數據的真實變化情況以處理相關的緩存。
例如剛剛提到的例子中,如果粉絲又觸發打賞了,這時候我們利用 binlog 表監聽是能及時發現的,發現后就能集中處理了,而且無論是在什么系統什么位置去更新數據,都能做到集中處理。
目前業界類似的產品有 Canal,具體的操作圖如下:
 圖片
圖片
利用 Canel 訂閱數據庫 binlog 變更從而發出 MQ 消息,讓一個專門消費者服務維護所有相關 Key 的緩存操作
到這里,針對大型系統緩存設計如何保證最終一致性,我們已經從策略、場景、操作方案等角度進行了細致的講述,希望能對你起到幫助。