













二十分鐘了解K8S網絡模型原理
?對于好多剛接觸K8S,甚至是接觸K8S很長時間的同學,K8S網絡模型可以說是個很神秘的東西。那么對于這部分同學,恭喜你發現了本文,只要你花二十分鐘的時間,就保證你能輕松掌握K8S網絡模型原理。
01知識儲備
首先,我們提前熱身一下,學一點網絡基礎知識。
1.1 網絡命名空間
維基百科的定義是這樣的“Network namespaces virtualize the network stack”,意思就是說linux network namespace對network stack做了虛擬化。什么是network stack呢?網絡棧包括了網卡(network interface),回環設備(loopback device),路由表(routing tables)和iptables規則。打個比方,當你登錄一臺linux服務器時,你默認用的就是Host網絡棧。
1.2 網橋設備
網橋是在內核中虛擬出來的,可以將主機上真實的物理網卡(如eth0,eth1),或虛擬的網卡橋接上來。橋接上來的網卡就相當于網橋上的端口,端口收到的數據包都提交給這個虛擬的“網橋”,讓其進行轉發。
1.3 對設備
Veth Pair設備被創建出來后,總是以兩個虛擬網卡(Veth Peer)的形式成對出現,其中一張“網卡”發出的數據包可以直接在出現在對應的“網卡”上。Veth Pair常用作連接不同Network Namespace的網線。
1.4 VXLAN
VXLAN(Virtual extensible Local Area Network,虛擬擴展局域網),是由IETF定義的NVO3(Network Virtualization over Layer 3)標準技術之一,是對傳統VLAN協議的一種擴展。VXLAN的特點是將L2的以太幀封裝到UDP報文(即L2 over L4)中,并在L3網絡中傳輸。
VXLAN本質上是一種隧道技術,在源網絡設備與目的網絡設備之間的IP網絡上,建立一條邏輯隧道,將用戶側報文經過特定的封裝后通過這條隧道轉發。從用戶的角度來看,接入網絡的服務器就像是連接到了一個虛擬的二層交換機的不同端口上,可以方便地通信。
1.5 BGP(邊界網關協議)
邊界網關協議(Border Gateway Protocol,縮寫:BGP)是互聯網上一個核心的去中心化自治路由協議。它通過維護IP路由表或“前綴”表來實現自治系統(AS)之間的可達性,屬于矢量路由協議。BGP不使用傳統的內部網關協議(IGP)的指標,而使用基于路徑、網絡策略或規則集來決定路由。
02什么是微服務的可觀測性單機容器網絡
好了,經過上一章的熱身,大家對網絡基礎知識應該有了大致的了解。那么咱們接下來先嘗試探索一下單機容器網絡模型,這也是docker默認使用的單機容器網絡模型。
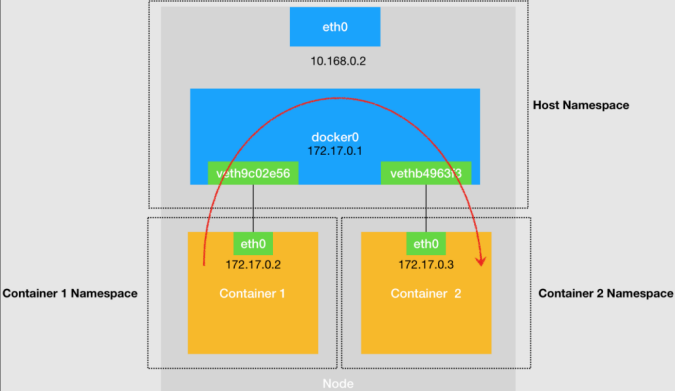
圖1 宿主機上不同容器通過網橋進行互通
單機容器網絡的示意圖如圖1,圖中給出了如下幾個關鍵點:
- 每個容器(Container)分別擁有自己的Network Namespace。
- 容器通過對設備,連接到宿主機的Host Network Namespace。對設備在容器Network Namespace這一端的“網卡”是eth0,eth0配置的ip即容器的ip。對設備連接Host Namespace的那一端掛載到網橋設備docker0。
- 網橋設備docker0,掛載著所有容器的對設備的Host Namespace這一端。并且,掛載在網橋上的設備,會被降級成網橋上的一個端口,端口的唯一作用就是轉發網橋或另一端對設備的數據包。
- 從Container1發送到Container2的數據包,首先經過Container1中的eth0,到達docker0網橋,docker0網橋經過二層轉發,將數據包發送到Container2對應的端口(Container2對設備的docker0網橋這一端),這樣數據包就被直接送到Container2中了。
上述就是單機容器網絡的基本原理,在對單機容器網絡模型有了初步的認識后,接下來我們進入正題,開始對K8S網絡模型的探索。
03K8S網絡模型
接觸過K8S的同學,大致都聽說過Flannel和Calico兩種網絡模型。但是,這兩種網絡模型具體是什么樣子,工作原理是什么,可能很多同學就比較困惑了。沒關系,接下來我們就開始對k8S網絡模型的探索吧!
3.1 Flannel網絡模型
在上一章中,介紹了單機容器網絡的原理。那么,要理解容器如何“跨主機通信”的原理,一定要從Flannel這個項目說起。Flannel項目是CoreOS公司推出的容器網絡方案,目前它支持三種后端實現:
- UDP
- VXLAN
- Host-gw
3.1.1 Flannel-UDP
UPD模式Flannel最早實現的一種方式,也是性能最差的,目前已被棄用。但是這種方式也是最直接,最容易理解的方式,所以我們從這種方式開始介紹。
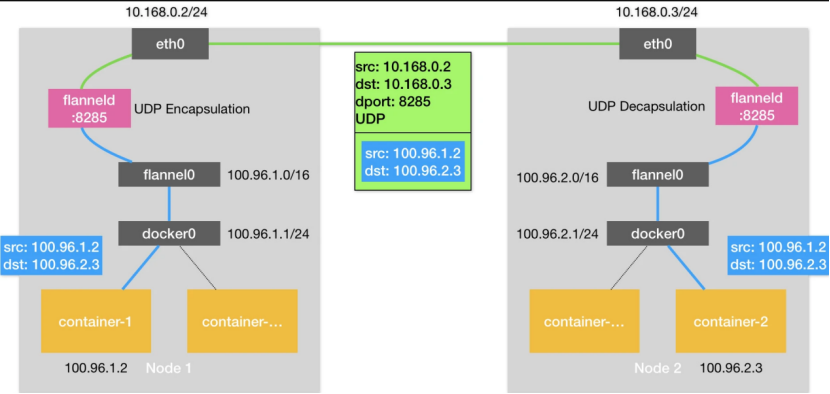
圖2 Flannel-UDP模式跨主機通信示意圖
圖2是Flannel-UDP模式的原理圖。與單機容器網絡相比,這里新增了一個flannel0設備和flanneld進程。flannel0設備是一個TUN設備,它的作用非常簡單,就是在系統內核和用戶應用程序之間傳包;flanneld進程的職責,就是封裝和解封裝。數據包是如何從Node1中的container-1容器發送到Node2的container-2容器的呢?
- 數據包從container-1,來到了網橋docker0上,由于數據包的目的地址不屬于網橋的網段,所以數據包經由docker0網橋,出現在宿主機上。
- 在宿主機的路由表中,去往100.96.0.0/16網段的包經由flannel0處理。flannel0收到數據包之后,將數據包送到flanneld進程,flanneld進程會對數據包封裝成一個UDP數據包,src和dst地址分別為兩個容器對應的宿主機的地址。這樣,數據包就可以到達Node2了。
- 數據包到達Node2的8285端口,即Node2上的flanneld進程,會被執行解封裝操作,之后數據包被發送到TUN設備,即flannel0設備。剩下的事情就簡單了,數據包經過docker0網橋到達container-2。
3.1.2 Flannel-VXLAN
經過上一小節的介紹,大家對Flannel-UDP模式大致了解了吧,那聰明的你們已經猜到為什么Flannel-UDP被棄用了吧?沒錯,因為效率太低了,數據包每次經過flannel0設備,都會經過內核態-用戶態-內核態的這一頓折騰。
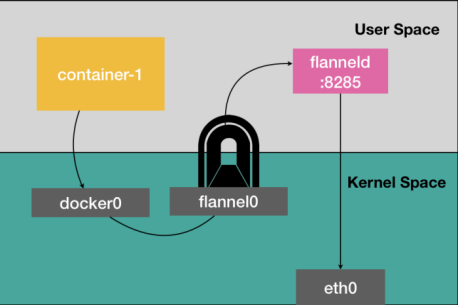
圖3 TUN設備示意圖
那有沒有辦法不要這么折騰呢?有,Flannel-VXLAN方案就解決了這個問題。Flannel-VXLAN方案用VXLAN技術替代了flannel0設備,讓數據包能夠在內核態上實現數據包的封裝和解封裝。
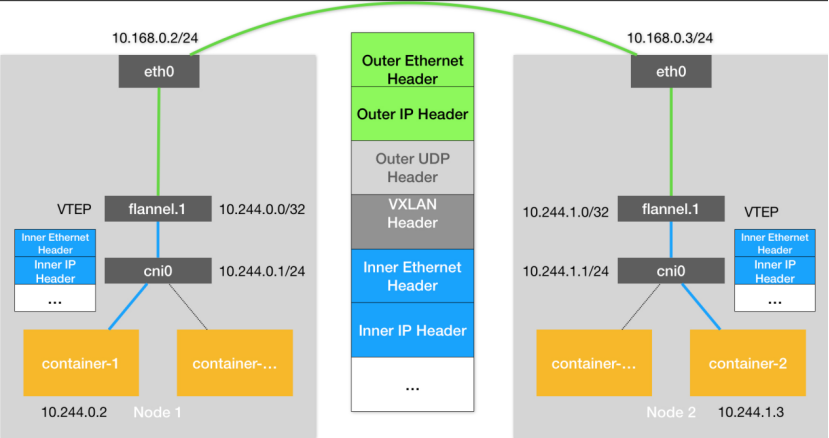
圖4 Flannel-VXLAN網絡模型示意圖
Flannel-VXLAN網絡模型的原理如圖4所示,你會發現,這和Flannel-UDP基本上的是一樣。事實也的確如此,Flannel-VXLAN是Flannel-UDP的升級版。這里需要交代一下他們之間的不同點。
- Flannel-UDP的TUN設備flannel0,升級成了VXLAN的VTEP設備。數據包的封裝和解封裝在內核態就能完成。
- 數據包的格式中,增加了VXLAN Header,這個Header的作用和Flannel-UDP的數據包中的dport:8285的作用是一樣的,當數據包來到Node2時,操作系統能根據VXLAN Header,把數據包直接給到flannel.1設備。
3.1.3 Flannel-host-gw
此時,聰明的你肯定會說,Flannel-VXLAN雖然效率提高了,但是還是用到了隧道技術,效率還是會受到影響,能不能不用隧道技術呢?答案是能。接下來我們繼續探索Flannel-host-gw網絡模型,一個基于三層的網絡方案。老規矩,上圖。
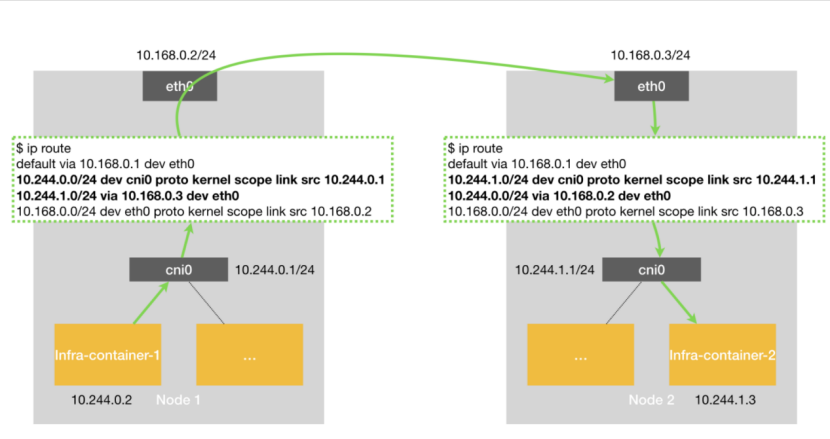
圖5 Flannel-host-gw網絡模型示意圖
圖5是Flannel-host-gw網絡模型,相比較之前的兩個網絡模型,隧道設備確實沒有了,取而代之的是一堆路由規則。那,數據包又是怎么從container1到container2的呢?
- 當數據包從container1到了網橋之后,通過Host網絡棧的路由表,發現去container2的路已經指明,經由eth0,達到Node2(10.168.0.3/24)即可。
- 當數據包到了Node2之后,通過Host網絡棧的路由表,找到cni0網橋,container2自然也就找到了。
肉眼可見,Flannel-host-gw的性能確實提高了很多,那為什么還要用Flannel-VXLAN呢?原因很明顯,Flannel-host-gw只支持宿主機在二層連通的網絡,并且,K8S的規模不能太大,否則每臺機器的路由表就太多了。
3.2 Calico網絡模型
經過上一小節的介紹,大家對Flannel應該有個大致的了解了。可能有人會問,除了Flannel,K8S還有別的網絡模型么。當然有了,下面我們開始探索Calico網絡模型。
3.2.1 Calico(非IPIP模式)
實際上Calico網絡模型的解決方案,幾乎和Flannel-host-gw是一樣的。不同的是Flannel-host-gw使用etcd來維護主機的路由表,而Calico則使用BGP(邊界網關協議)來維護主機的路由表。BGP協議的定義看著有點高深,換成通俗的說法,大家可以理解為在每個邊界網關都會都運行著一個小程序,它們會交換各自的路由信息,將需要的信息更新到自己的路由表里。BGP這個能力正好可以取代Flannel-host-gw利用Etcd維護主機上路由表的功能,并且更為強大。
除了BGP之外,Calico另外一個不同之處就在于它不需要維護一個網橋,Calico網絡模型如6所示:
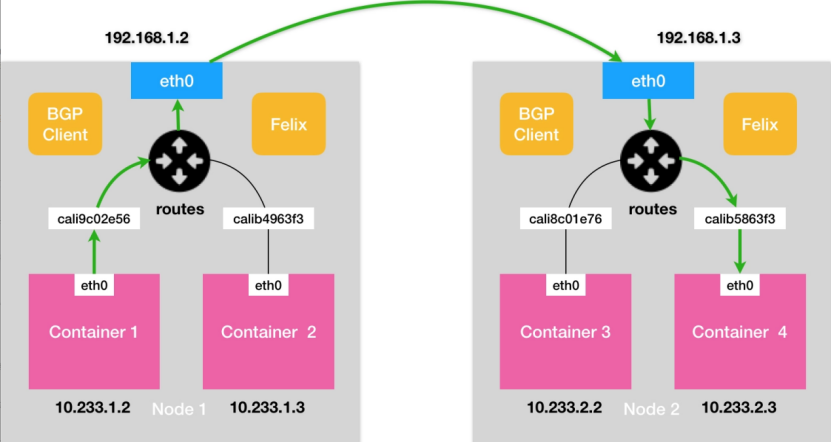
圖6 Calico網絡模型示意圖
圖6是Calico網絡模型示意圖,其中BGP Client和Felix的作用是和K8S集群其他節點交換路由信息,并更新Host網絡棧的路由信息。
由于沒有了網橋設備,每個對設備Host網絡棧的這一端,需要配置一條路由規則,將目的地址為對應Container的數據包轉入該對設備。對應的路由如下所示:
10.233.1.2 dev cali9c02e56 scope link
數據包是如何從Container1走到Container3的呢?過程基本上和Flannel-host-gw無異了。唯一區別就是數據包進出容器,不再依賴網橋,而是直接通過宿主機路由表找到容器的另一端對設備。
3.2.2 Calico(IPIP模式)
Calico聽著挺強大的,實則和Flannel-host-gw一樣,只支持宿主機二層聯通的情況。假設Container1和Container3的宿主機在不同的子網,那通過二層網絡是無法將數據包傳到下一跳的地址的。如圖7所示,Calico會在Node1創建這樣一條路由規則:
10.233.2.0/16 via 192.168.2.2 eth0
此時問題就出現了,下一跳是192.168.2.2,和Node1不在一個子網里,根本就找不到。
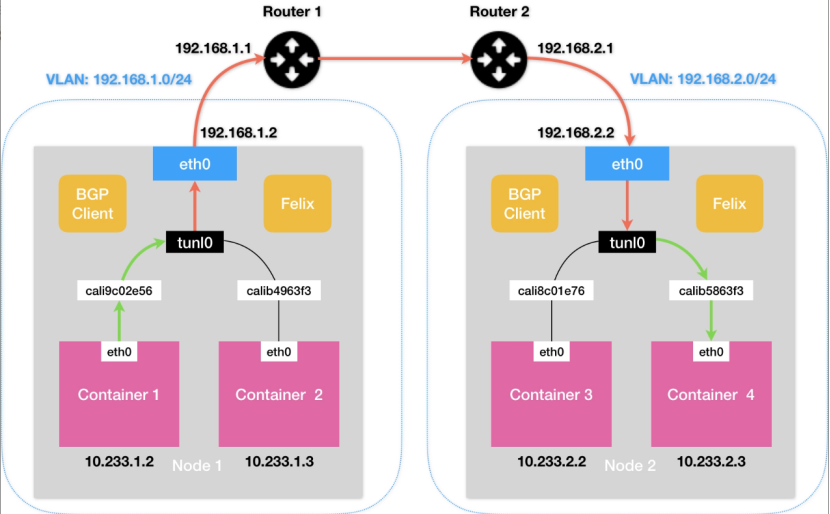
圖7 Calico(IPIP模式)網絡模型示意圖
Calico的IPIP模式解決了上述問題,在每一臺宿主機上,都會增加一個tunl0設備(IP隧道設備),并且會對應增加如下一條路由策略:
10.233.2.0/16 via 192.168.2.2 tunl0
這樣一來,Container1去往Container3的數據包就會經過tunl0設備的處理,tunl0設備會在源IP報頭之外新增一個外部IP報頭,拿本例來說,這個外部IP報頭的src和dst分別為Node1和Node2的IP,這樣,數據包就偽裝成了從Node1發到Node2的數據包。當數據包到達Node2之后,Node2上的tunl0會把外部IP報頭拿掉,從而拿到原始的IP包。
我知道,聰明的你此時肯定會有一個更好的想法,為什么不在Router1和Router2上也用BGP協議的方式,同步容器的IP路由信息呢?這樣宿主機上不就可以不用tunl0設備了么。這個方法確實很好,并且在一些場景也得到了應用。
03CNI網絡插件
最后,我再介紹一下CNI網絡插件。CNI(Container Network Interface)顧名思義,是K8S的網絡接口。這個接口的作用就是當K8S的 kubelet創建Pod時,dockershim會預先調用Docker API創建并啟動Infra容器,執行SetUpPod的方法。這個方法會為CNI網絡插件準備參數和環境變量,然后調用CNI插件為Infra容器配置網絡。CNI網絡插件僅需實現ADD和DEL兩種方法,分別對應Pod加入K8S網絡,以及Pod移出K8S網絡。
用大白話再解釋一遍,就是當Pod創建時,需要對網絡進行一些設置,包括前邊的提到的創建對設備,把對設備的一端掛載到網橋上,添加Pod以及主機的Network Namespace的路由規則等,這些操作當然可以由運維人員手動完成(不嫌累的話),CNI網絡插件就是一個腳本,自動對網絡進行設置。
Flannel和Calico各自都有專門的CNI插件,大家可以去Github上研究一下源碼,并親自部署一下試試。這里就不多介紹了,畢竟看再多的資料,都不如自己動手實踐一遍理解得深刻。?
























