梯度下降引發AI大牛們“激辯”,網友:每個人的答案都值得一看
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
最近,DeepMind的一位AI研究員在推特上拋出了一個問題:
機器學習中最美/最優雅的點子是什么?
之所以會有這樣的疑問,是因為他發現數學家和物理學家們就經常談論美學,機器學習領域卻很少這樣,也很好奇為什么。

很快,大家就給出了自己的答案。
但其中的一條回復卻引發了很大的討論,連LeCun等大佬都忍不住參與進來了。
這個答案就是來自前谷歌大腦的研究員Chris Olah所提出的“梯度下降法最美論”。
那么這到底是怎么一回事呢?
“梯度下降是機器學習中最優雅的idea”
所謂梯度下降法,就是一種尋找目標函數最小化的方法,它利用梯度信息,經過不斷迭代調整參數來尋找合適的目標值。
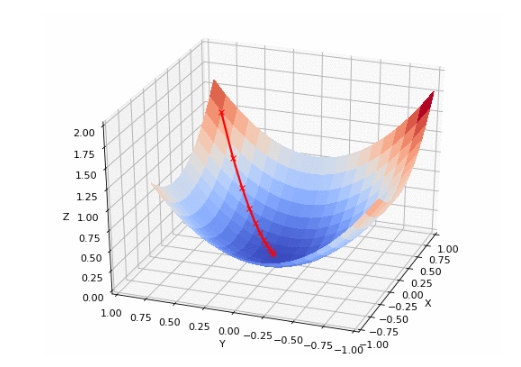

這一思想更形象地解釋就是下山。
假設當你站在山上時霧很大,想盡快下山的你卻無法看清下山路線,那么就只能利用周圍的環境信息走一步算一步,也就是以當前位置為準,找到最陡峭的地方往下走。重復這個計算過程,就能達到山谷。
我們在求解機器學習算法的模型參數時,為了讓所得模型可以更好地捕捉到數據中蘊含的規律,進行更準確地預測,一般會最小化損失函數得到參數估計值。
梯度下降法就是此時最常用的優化算法,而且它對于復雜模型也很適用。
認為梯度下降法是機器學習中最優雅理論的Chris Olah,一直致力于對人工神經網絡進行逆向工程的工作,曾先后就職于OpenAI和谷歌大腦,現在是一家主攻大型模型安全性的初創公司的聯合創始人。

他給出這一答案的理由是:
簡單的梯度下降就可以創造出令人驚嘆的結構和性能。

這一回復得到了近1700人的點贊支持。
就連LeCun都轉發起來,稱自己四十年來都在說服身邊搞理論的同事相信梯度下降法擁有多么不可思議的力量。

彷佛一下子找到“知音”的LeCun話匣子打開,分享了自己20多年前的一樁趣事。
他說,在2000年舉辦的NeurIPS會議晚宴中,一位非常杰出的ML科學家就提出一個類似問題:
“我們在機器學習中學到的最重要的東西是什么?”
當時他就回答“梯度下降”。
誰知這位前輩聽完卻一臉匪夷所思,那神情顯得“自己”這一答案好像特別蠢一樣……

△ 或許就像這樣吧
然而,事實證明,LeCun說的完全沒錯。
他還舉證稱,“我的一位朋友用3行隨機梯度下降法就可以替代復雜的傳統方法解決凸問題(SVM、CRF)”。
有理有據,這位朋友(Léon Bottou)的博客鏈接也被甩出來了。


總的來說,關于“梯度下降法最優雅理論”這一觀點,大家基本沒有什么異議。
真正引起討論的還是Chris Olah小哥那句“機器學習的美是生物學之美,而不是數學或者物理學之美”。
插曲:機器學習之美是生物學之美?
小哥解釋說,自己一開始也認為機器學習的美體現在復雜的數學和巧妙的證明上,但后來才漸漸發現不是這樣的,他給出了以下理由和具體例子來支撐他的觀點。
首先在他看來,機器學習中的很多理論應用到神經網絡中都可以“發現”非常漂亮的圖像,比如用梯度下降得到的分組卷積圖。

“看起來很像一些早期生物有沒有?”
小哥驚呼自己從中感受到了自然科學家感受過的美,因此覺得機器學習的美也是生物學的美。
除此之外,他還覺得:
訓練大模型就像是到一個偏遠的島嶼去觀察那里的生物。

因此“每個模型的結構都有著自己的魅力世界,等待我們去觀察和發現”。
(就是說,怎么突然升華起來了。)
順理成章,他將梯度下降法比作生物學中的進化,認為它們都是通過簡單的過程就能產生具有高度復雜性的東西。
而且他思來想去,覺得還是生物學是用來類比的最佳范例,因此機器學習也可以從其中獲得啟發。
小哥這些言論一出,每一條都收到了幾十到上百的點贊,但更多的人表示有點匪夷所思,不敢茍同。其中就包括大名鼎鼎的“嘴炮”馬庫斯。
他很直白地表示,你說梯度下降很牛沒錯,但它和生物學基本沒什么聯系吧。

與此同時也有網友反駁道,就拿反向傳播機制來說,我們的大腦根本都不存在這個東西,怎么能說機器學習和生物學很像呢?

“我覺得梯度下降還是一個數學問題,和進化無關;并且我還得說一句,數學之美遠超進化和生物學之美,更別提梯度下降比進化聰明了幾個數量級呢。”有人進一步回懟。

反對聲是七嘴八舌……
小哥眼看情況愈演愈烈,樓越堆越高,按耐不住,出來解釋了。
他稱,自己這個類比確實不完美,可能也存在表述不準確的原因。但無論如何,這些結論都不涉及解釋人工神經網絡的生物學合理性。除此之外,一切都是他的直覺感受,大家隨意接受和反駁就好。
好吧,這就是一個開放問題,經不經得起推敲還很難說。
只得說他提出來的梯度學習最優雅確實目前點贊次數最多的一個答案。
那么,我們還是回到問題本身,看看除了梯度下降,還有什么機器學習理論被大家奉為“至美”吧。
還有哪些idea很優雅?
一位即將進入華盛頓大學讀博士的學生認為是“高斯過程“(Gaussian Process, GP),對他來說,這是構建模型過程中最精粹的“精髓”。
一位就職于Zoom的AI從業者表示,深度學習的框架和系統中有太多優雅的東西了:
往低了說,GPU加速操作算一個;
往高了說,可微分編程/Pytorch的自動求導(autograd)/反向傳播都可以算這個范圍內;

來自Yoshua Bengio的MILA實驗室的一位研究員則表示,當然是機器學習中的擴展定律(scaling laws)了,“那種簡單到驚掉人下巴的美!”
一位擁有博士學位的網友:“我也覺得答案太多了,硬要我說,我選激活函數和ConNet架構。因為它們歸根結底和矩陣和微積分很像。”
還有人的答案是:置信傳播算法(belief propagation)、流形學習(manifold learning)、bottleneckz自動編碼器、神經網絡中的不變性和等變性編碼等等。
當然,簡單又通用的Transformer也必須得有一票。

這里就不一一列舉了。
不過,也有人認為機器學習根本談不上什么優不優雅。
“畢竟在得到最終結果之前,你得經歷各種報錯和bug的折磨。要我說,我還是覺得物理學中的諾特定理是最優雅的東西。”

所以,這就是我們很少談論機器學習之美的原因嗎?
也不止如此,有人就表示:
即使機器學習到了2022年,你也不能在沒法確保能達到一個有趣結果的情況下就隨意“鼓搗”寶貴的GPU,這樣的話,誰還在乎機器學習到底優不優雅呢?

emmm,似乎真相了……
不過總而言之,不少人都表示DeepMind研究員提出的這個問題非常好,大家的評論也都很有意思,值得一讀。

最后,你覺得機器學習中存在美的東西嗎?
如果有,你pick哪一個呢?