













No.2時序數據庫隨筆 - IoTDB核心技術剖析
原創
大家好,很開心在今天的峰會和大家一起分享ApacheIoTDB 的核心技術剖析的內容。

首先,還是簡單的自我介紹一下,我是孫金城,花名 金竹,來自阿里巴巴,從2016年開始一直投入在開源建設中,目前是ApacheFlinkPMC成員,ApacheBeamCommitter和ApacheIoTDB的PMC成員。同時也是Apache 軟件基金會的成員,ApacheMember。

那么,今天我們會有4個部分的內容,首先是和大家一起聊聊IoT領域的發展趨勢。

目前5G正當時,馬老師也曾說過,5G催化了IoT的發展,80%的5G利好會體現在物聯網領域。那么,這并不是一個預言而是一個現實,目前中國和美國工業互聯網,以及德國的工業4.0都在蓬勃發展中。
?

其實,早在2018年Gartner就評估出云向邊緣計算挺進是十大戰略技術趨勢,在2019年和2020年也連續強調賦權和賦能邊緣,云邊端一體成為IoT領域的典型架構。

同時,國務院在2017年就發布了工業互聯網的指導意見,并給出階段性的基建目標。
從數據庫領域的權威排名情況看,時序數據數據庫從2018年開始,熱度不斷攀升,同時涌現出很多優秀的時序數據庫產品,比如Influxdb,opentsdb以ApacheIoTDB。

目前時序數據庫有30多個,從架構的角度又可以分為三大類
第一類,以TimescaleDB為代表基于關系的時序數據庫
第二類,以OpenTSDB為代表的基于KV的時序數據庫
第三類,專門為時序數據數據而生的 InfluxDB和AapacheIoTDB。
那么這三類數據庫有怎樣的特點呢?

基于關系的時序數據庫是建立在B+tree的數據結構之上的,在寫入上有先天的局限。基于KV的時序數據庫在索引的建立上存儲弊端,導致查詢能力受限。那么基于LSMTree的InfluxDB和IoTDB在架構上都解決了高吞吐寫入問題,同時IoTDB官方也給出了一些性能測試數據。我們看到IoTDB不論是寫入還是查詢都有很大的優勢。那么這些造就這些優勢的本質是什么呢?就是我們今天要與大家分享的核心內容。

那么我們一起來看看IoTDB的核心技術點,這一部分可能會有點復雜,需要大家集中精力我們一起討論。

技術都是以解決實際問題為根本的,首先我們要看看IoT時序數據的領域問題有哪些。
時序數據的來源有多種,交通設施,智能樓宇,以及工況指標數據等。尤其在領域數據規模是一個不容忽視的現實問題,比如金風發電案例,2w個風機,每個風機500個測點,以50Hz的頻率進行采集,數據量達到了5億/秒的吞吐需求。
所以IoT領域的時序數據存儲計算涉及到了 存儲成本/寫入吞吐/查詢性能 三個非常重要的領域問題。

同時還有一個客觀存在的問題就是亂序問題,這個是青海大數據平臺在2018年真實數據情況,IoT工業領域的時序數據亂序是一種常態。

好,面對上面的問題IoTDB基于LSMtree的架構進行設計,LSM樹的核心思想就是放棄部分讀能力,換取寫入能力的最大化。核心思路其實非常簡單,就是假定內存足夠大,因此不需要每次有數據更新就必須將數據寫入到磁盤中,而可以先將最新的數據駐留在內存中,等到積累到一定程度后,再使用歸并排序的方式將內存中的數據合并追加到磁盤隊尾。我們來看一下這個基于LSM Tree的寫入過程:
一個數據寫入到來之后,先進行WAL的落盤。寫WAL是為了恢復,真正的有序寫入要將數據寫入內存,也就是Mem-Table,然后對Mem-Table進行排序,數據寫入到內存之后,就表示寫入成功了。
那么寫到內存之后會怎樣操作呢?就是要解決落盤問題。當內存數據到達一定規模,就需要寫入磁盤,LSM Tree的做法是將要刷磁盤的Mem-Table變成immutable,刷磁盤同時不影響寫入請求,在創建一個新的Mem-table。同時我們對持久化的數據進行合并和索引的建立。
那么查詢邏輯是怎么樣的呢?查詢邏輯最核心的是要查詢索引,首先在內存Mem-table里面查詢,然后在immutable Mem-table里面進行查找,然后是磁盤Flie里面進行查找。當然這里有Bloom filter輔助查詢。Bloom filter本質就是一個bitmap,每個key數據用k個獨立的hash就行計算,填充bitmap,數據查詢時候Bloomfilter說沒有一定沒有,Bloomfilter說有,不一定有,還要繼續索引查找。

那么,IoTDB架構設計是對LSM的優化加強,針對IoT時序數據亂序問題進行了重點設計考慮,從內存到文件存儲都有有序和亂序數據的特殊處理,更大程度的解決亂序問題。同時IoTDB具有查詢優化機制,可以為用戶提供極致的查詢性能。這些從宏觀的角度我們可以感知IoTDB的優秀,但是具體細節上有怎樣的設計考慮呢,我們接下來看細節。

IoTDB本質是一個數據庫,是一個存儲系統,那么最終數據是以文件的方式進行存儲管理,IoTDB設計了自己的TsFile格式,那么怎樣的文件格式設計才能滿足高效的寫入和快速的讀取呢?

首先以實際的查詢需求來反推TsFile的文件格式,通常我們更希望同一個設備的數據存儲在一起,并且每一個Measurement信息在磁盤上連續存儲是最高效的。
所以,在邏輯上IoTDB將一個設備的數據抽象為一個ChunkGroup,每個ChunkGroup進行獨立的云數據管理。
同時,對每個Measurement數據集中存儲到一個Chunk中。

同時,在實際的工業場景中,我們大多會根據時間區間查詢某些工況信息。
所以我們也需要針對時間區間進行抽象,IoTDB里面將chunk數據按時間區間再劃分為若干的Page信息。
那么,這樣的數據結構抽象,本質上是在最終達到怎樣的目的呢?
那就是充分利用邊緣端有限的內存資源,最大程度的減少磁盤的IO。我們以最優的方式構建索引樹。
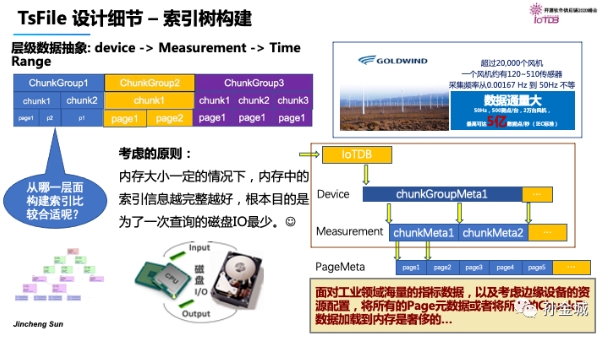
那么,索引樹的節點信息保存那一層的數據抽象信息比較合適呢?是保存pange信息?還是chunk信息,還是全部信息,在有限的資源情況下,如何取舍?
那么這個取舍的原則就是,在內存大小一定的情況下,內存中的索引信息越完整越好。根本目的是為了減少磁盤IO。
既然page是細粒度的數據塊,那么是否可以將所有page的元信息進行索引樹構建呢?
其實通過剛才的風機案例,我們會發現工業場景7*24小時的不間斷數據采集,每秒5億的數據點,會形成海量的page,將page作為索引樹節點信息,構建的樹將將是一個巨大的樹,即便是將所有chunk信息都加載到內存也是一個巨大的挑戰。
那么最初,我們是利用了Device和Measurement的粒度進行索引信息的構建的。也就是我們針對ChunkGroup和Chunk進行Meta信息的構建。

這是IoTDB0.8版本TsFile的完整結構,其中包括了data和tsFile的Meta信息/Device的Metat信息/Chunk的Meta信息。查詢一個設備工況信息時候對文件的讀取過程是這樣的:
第一,讀取4個字節的MetaSize,
第二,根據Meta的內容,進行二分查找,設備信息,比如d信息。
第三,根據Device的MetadataIndex的offset定位到Device的Meta數據。
第四,讀取當前設備下所有的ChunkMeta信息到內存。
那么,這里在實際的生產過程中我遇到了一個設備有幾十萬的工況數據采集,加載與當前查詢無關的Chunk信息也是一種極大的性能消耗。那么如何解決呢?

未來解決上面的問題,提供極致的查詢性能,我們需要優化Meta信息的利用,在0.10版本我們根據設備和工況信息構建一顆B+Tree。假設一個設備有150個Measurement采集,我們從0.8到0.10進行了meta信息優化。
首先是對Chunk信息進行細粒度的時間切片,如圖的TimeSeriesmeta;
更重要的是,我們對 Measurement進行了更高一層的邏輯抽象,LEAF_MEASUREMENT節點,這樣我們就可以構建一顆索引樹。
這樣的索引樹,當我們查詢某個設備的某個Measurement信息時候,比如查詢s0,那么優化后的索引結構,我們不需要將設備下的所有的Measurement的Meta信息全部讀取,我們只需要讀取s0-s9的數據就可以了。那么,這里內容的理解需要有一點磁盤數據塊管理和讀取的知識背景,磁盤數據塊管理和B+Tree的數據結構性感內容大家可以掃描二維碼,查看更細節的內容剖析。

如果大家理解剛才對Measurement的中間層抽象優化的話,那么相信大家同樣會秒懂,對于設備很多的情況下,也可以對設備的Meta信息進行一層INTERNAL_DEVICE節點抽象的原因了。
這樣IoTDBv0.10對DEVICE和MESUREMENT進行了中間節點優化抽象,進而優化內存的利用/數據的解析和降低磁盤IO的成本,極大的提高查詢性能。

這個就是v0.10版本中完整的TsFile的數據結構。我們以一個具體的查詢來完整的梳理一下查詢邏輯:
假設我們要查詢 時間區間在(20,80)的設備d1的s1的采集點信息:SELECT sensor_1 FROM root.device_1 WHERE time > 20 and time < 80
- 讀取TsFile的MetaDataSize信息
- 根據MetaDataSize和offset獲取MetaData的位置
- 根據TsFile的MetaData獲取IndexNodes的Offset信息我們要查詢device_1的信息,根據device的offset信息2535讀取MetadataIndexNodes的data內容
- 我們要查詢sensor_1的信息,根據sensor_1的offset信息2175讀取TimeseriesMetadata信息
- 我們要查詢時間區間是(20,80)的信息,根據offset1487,讀取Chunk信息
- 根據ChunkHeader的offset12讀取ChunkHeader內容
最后順序讀取Chunk里面的PageHeader,如果Page的時間區間在(20,80),那么就來讀取PageData
雖然查找的步驟很多,但是內部是B+Tree的索引結構,并輔助bloom filter等加速機制,查詢性能還是非常棒的!!!

那么其實IoTDB整體還是非常復雜的,內部細節很多,上面我們介紹的是Meta設計和讀取過程細節,對于IoTDB在寫上的設計也是很巧妙的,也有很多的細節需要和大家進行介紹。
會涉及到ChunkGourp/chunk/等部分的細致考慮,今天我們不進行展開,后續我會在公眾中為大家細致剖析。

從細節跳出來我們在宏觀上了解IoTDB的話,我們會發現IoTDB不僅在數據的讀寫上有優勢,而且還對工業標準進行了集成,也更加注重和大數據生態的集成。非常適合企業構建云邊端一體的存儲計算體系平臺。

好的,下面我們快速了解一下IoTDB的現狀和未來規劃。

IoTDB已經在2020年的9月份得到了最權威的開源社區的認可,成為了Apache 頂級項目。Apache 開源社區對項目的畢業控制非常嚴格,IoTDB成為頂級項目足以證明其優秀和潛力。

剛才我們也提到,ApacheIoTDB 非常注重工業領域標準集成,與Apache 頂級項目PLC4X有很好的生態集成和線下互動。

得到了多方的認可,包括工信部的認可和業界肯定,在2020年度也成為了開源中國,年度最受歡迎的開源項目。

關于未來的規劃,圖中棕色部分是已經具備的功能,橙色部分是目前社區重點規劃的部分。那么更多的功能規劃和開發也歡迎在做的各位進行積極參與。J

好,接下來我們快速看一下IoTDB的現有投產應用案例。

那么目前IoTDB已經投產與各種工業領域,包括風電行業,工程機械,氣象大數據平臺和城市軌道等項目中,其中在中車青島四方車輛的合作項目中,一臺IoTDB實例替換了老系統的10多條Cassandra實例。每天管理4000億的數據點信息。

同時,IoTDB在德國和美國也有推廣和應用,如圖是IoTDB在德國的行業應用。

當然,還有更多的應用案例在進行中。。。

作者介紹
孫金城,51CTO社區編輯,Apache Flink PMC 成員,Apache Beam Committer,Apache IoTDB PMC 成員,ALC Beijing 成員,Apache ShenYu 導師,Apache 軟件基金會成員。關注技術領域流計算和時序數據存儲。























