自適應批作業調度器:為 Flink 批作業自動推導并行度
?01引言
對大部分用戶來說,為 Flink 算子配置合適的并行度并不是一件容易的事。對于批作業,小的并行度會導致作業運行時間長,故障恢復慢,而不必要的大并行度會導致資源浪費,任務部署和數據 shuffle 開銷也會變大。
為了控制批作業的執行時長,算子的并行度應該和其需要處理的數據量成正比。用戶需要通過預估算子需要處理的數據量來配置并行度。但準確預估算子需要處理的數據量是一件很困難的事情:需要處理的數據量可能每天都在變化,作業中可能會存在大量的 UDF 和復雜算子導致難以判斷其產出的數據量。
為了解決這個問題,我們在 Flink 1.15 中引入了一種新的調度器:自適應批作業調度器(Adaptive Batch Scheduler)。自適應批作業調度器會在作業運行時根據每個算子需要處理的實際數據量來自動推導并行度。它會帶來以下好處:
- 大大降低批處理作業并發度調優的繁瑣程度;
- 可以根據處理的數據量為不同的算子配置不同的并行度,這對于之前只能配置全局并行度的 SQL 作業尤其有益;
- 可以更好的適應每日變化的數據量。
02用法
使 Flink 自動推導算子的并行度,需要進行以下配置:
- 啟用自適應批作業調度器;
- 配置算子的并行度為 -1。
2.1 啟用自適應批作業調度器
啟用自適應批作業調度器,需要進行以下配置:
- 配置 jobmanager.scheduler: AdaptiveBatch;
- 將 execution.batch-shuffle-mode 配置為 ALL-EXCHANGES-BLOCKING (默認值)。因為目前自適應批作業調度器只支持 shuffle mode 為 ALL-EXCHANGES-BLOCKING 的作業。
此外,還有一些相關配置來指定自動推導的算子并行度的上下限、預期每個算子處理的數據量以及 source 算子的默認并行度,詳情請參閱 Flink 文檔 [1]。
2.2 配置算子的并行度為 -1
自適應批作業調度器只會為用戶未指定并行度的算子(即并行度為默認值 -1)推導并行度。所以需要進行以下配置:
- 配置 parallelism.default: -1;
- 對于 SQL 作業,需要配置 table.exec.resource.default-parallelism: -1;
- 對于 DataStream/DataSet 作業,避免在作業中通過算子的 setParallelism() 方法來指定并行度;
- 對于 DataStream/DataSet 作業,避免在作業中通過 StreamExecutionEnvironment/ExecutionEnvironment 的 setParallelism() 方法來指定并行度。
03實現細節
接下來我們將介紹自適應批作業調度器的實現細節。在此之前,我們簡要介紹一下涉及到的一些術語概念:
- 邏輯節點(JobVertex)[2] 和邏輯拓撲(JobGraph)[3]:邏輯節點是為了更優的性能而將幾個算子鏈接到一起形成的算子鏈,邏輯拓撲則是多個邏輯節點連接組成的數據流圖。
- 執行節點(ExecutionVertex)[4] 和執行拓撲(ExecutionGraph)[5]:執行節點對應一個可部署物理任務,是邏輯節點根據并行度進行展開生成的。例如,如果一個邏輯節點的并行度為 100,就會生成 100 個對應的執行節點。執行拓撲則是所有執行節點連接組成的物理執行圖。
以上概念的介紹可以參見 Flink 文檔 [6]。需要注意的是,自適應批作業調度器是通過推導邏輯節點的并行度來決定該節點包含的算子的并行度的。
實現細節主要包括以下幾部分:
- 使調度器能夠收集執行節點產出數據的大小;
- 引入一個新組件 VertexParallelismDecider [7] 來負責根據邏輯節點需要處理的數據量計算其并行度;
- 支持動態構建執行拓撲,即執行拓撲從一個空的執行拓撲開始,然后隨著作業調度逐漸添加執行節點;
- 引入自適應批作業調度器來更新和調度執行拓撲。
后續章節會對以上內容進行詳細介紹。

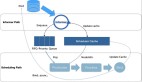
圖 1 - 自動推導并行度的整體結構
3.1 收集執行節點產出的數據量
自適應批作業調度器是根據邏輯節點需要處理的數據量來決定其并行度的,因此需要收集上游節點產出的數據量。為此,我們引入了一個 numBytesProduced 計數器來記錄每個執行節點產出的數據分區(ResultPartition)的數據量,并在執行節點運行完成時將累計值發送給調度器。
3.2 為邏輯節點決定合適的并行度
我們引入了一個新組件 VertexParallelismDecider 來負責為邏輯節點計算并行度。計算算法如下:
假設
- V 是用戶配置的期望每個執行節點處理的數據量;
- totalBytenon-broadcast 是邏輯節點需要處理的非廣播數據的總量;
- totalBytesbroadcast 是邏輯節點需要處理的廣播數據的總量;
- maxBroadcastRatio 是每個執行節點處理的廣播數據的比例上限;
- normalize(x) 是一個輸出與 x 最接近的 2 的冪的函數。
計算并行度的公式如下:

值得注意的是,我們在這個公式中引入了兩個特殊處理:
- 限制每個執行節點處理的廣播數據的比例;
- 將并行度調整為 2 的冪。
此外,上述公式不能直接用來決定 source 節點的并行度,因為 source 節點不會消費數據。為了解決這個問題,我們引入了配置選項 jobmanager.adaptive-batch-scheduler.default-source-parallelism,允許用戶手動配置 source 節點的并行度。請注意,并非所有 source 都需要此選項,因為某些 source 可以自己推導并行度(例如,HiveTableSource,詳情請參閱 HiveParallelismInference),對于這些source,更推薦由它們自己推導并行度。
3.2.1 限制每個執行節點處理的廣播數據的比例
我們在公式限制每個執行節點處理的廣播數據上限比例為 maxBroadcastRatio。 即每個執行節點處理的非廣播數據至少為 (1-maxBroadcastRatio) * V。如果不這樣做,當廣播數據的數據量接近 V 時,即使非廣播數據的量非常小,也可能會被計算出很大的并行度,這是不必要的,會導致資源浪費和任務部署的開銷變大。
通常情況下,一個執行節點需要處理的廣播數據量會小于要處理的非廣播數據。 因此,我們將 maxBroadcastRatio 默認設置為 0.5。目前,這個值是硬編碼在代碼中的,我們后續會考慮將其改為可配置的。
3.2.2 將并行度調整為 2 的冪
normalize 函數會將并行度調整為最近的 2 的冪,這樣做是為了避免引入數據傾斜。為了更好的理解本節,我們建議您先閱讀子分區動態映射部分。
以圖 4(b)為例,A1/A2 產生 4 個子分區,B 最終被決定的并行度為 3。這種情況下,B1 將消費 1 個子分區,B2 將消費 1 個子分區,B3 將消費 2 個子分區。我們假設不同子分區的數據量都相同,這樣 B3 需要消費的數據量是 B1/B2 的 2 倍,從而導致了數據傾斜。
為了解決這個問題,我們需要讓所有下游執行節點消費的子分區數量都一樣,也就是說上游產出的子分區數量應該是下游邏輯節點并行度的整數倍。為簡單起見,我們希望用戶指定的最大并行度為 2^N(如果不是則會被自動調整到不超過配置值的 2^N),然后將下游邏輯節點的并行度調整到最接近的 2^M(M <= N),這樣就可以保證子分區被下游均勻消費。
不過這只是一個臨時的解決方案,最終應該通過自動負載均衡來解決,我們將在后續版本中實現。
3.3 動態構建執行拓撲
在引入自適應批作業調度器之前,執行拓撲是以靜態方式構建的,也就是在調度開始前執行拓撲就被完全創建出來了。為了使邏輯節點并行度可以在運行時決定,執行拓撲需要支持動態構建。
3.3.1 向執行拓撲動態添加節點和邊
動態構建執行拓撲是指一個 Flink 作業從一個空的執行拓撲開始,然后隨著調度逐步附加執行節點,如圖 2 所示。
執行拓撲由執行節點和執行邊(ExecutionEdge)組成。只有在以下情況下,才會將邏輯節點展開創建執行節點并將其添加到執行拓撲:
- 對應邏輯節點的并行度已經被確定(以便 Flink 知道應該創建多少個執行節點);
- 所有上游邏輯節點都已經被展開(以便 Flink 通過執行邊將新創建的執行節點和上游執行節點連接起來)。

圖 2 - 動態構建執行拓撲
3.3.2 子分區動態映射
在引入自適應批作業調度器之前,在部署執行節點時,Flink 需要知道其下游邏輯節點的并行度。因為下游邏輯節點的并行度決定了上游執行節點需要產出的子分區數量。以圖 3 為例,下游 B 的并行度為 2,因此上游的 A1/A2 需要產生 2 個子分區,索引為 0 的子分區被 B1 消費,索引為 1 的子分區被 B2 消費。

圖 3 - 靜態執行拓撲消費子分區的方式
但顯然,這不適用于動態圖,因為當部署上游執行節點時,下游邏輯節點的并行度可能尚未確定(即部署 A1/A2 時,B 的并行度還未確定)。為了解決這個問題,我們需要使上游執行節點產生的子分區數量與下游邏輯節點的并行度解耦。
我們通過以下方法實現解耦:將上游執行節點產生子分區的數量設置為下游邏輯節點的最大并行度(最大并行度是一個可配置的固定值),然后在下游邏輯節點并行度被確定后,將這些子分區均分給不同的下游執行節點進行消費。也就是說,部署下游執行節點時,每個下游執行節點都會被分配到一個子分區范圍來消費。假設 N 是下游邏輯節點并行度,P 是子分區的數量。對于第 k 個下游執行節點,消費的子分區范圍應該是:

以圖 4 為例,B 的最大并行度為 4,因此 A1/A2 有 4 個子分區。然后如果B的確定并行度為 2,則子分區映射將為圖 4(a),如果B的確定并行度為 3,則子分區映射將為圖 4(b)。

圖 4 - 動態執行拓撲消費子分區的方式
3.4 動態更新并調度執行拓撲
自適應批作業調度器調度作業的方式和默認調度器基本相同,唯一的區別是:自適應批作業調度器是從一個空的執行拓撲開始調度,在處理任何調度事件之前,都會嘗試決定所有邏輯節點的并行度,然后嘗試為邏輯節點生成對應的執行節點,并通過執行邊連接上游節點,更新執行拓撲。
調度器會在每次調度之前嘗試按照拓撲順序決定所有邏輯節點的并行度:
- 對于 source 節點,其并行度會在開始調度之前就進行確定;
- 對于非 source 節點,需要在其所有上游節點數據產出完成后才能確定其并行度。
然后,調度程序將嘗試按照拓撲順序將邏輯節點展開生成執行節點。一個可以被展開的邏輯節點應該滿足以下條件:
- 該邏輯節點并行度已確定;
- 所有上游邏輯節點都已經被展開。
04未來展望 - 自動負載均衡
運行批作業時,可能會出現數據傾斜(某個執行節點需要處理的數據遠多于其他執行節點),這會導作業出現長尾現象,拖慢作業的完成速度。如果 Flink 可以自動改善或者解決這個問題,可以給用戶很大的幫助。
一種典型的數據傾斜情況是某些子分區的數據量明顯大于其他子分區。這種情況可以通過劃分更細粒度的子分區,并根據子分區大小來平衡工作負載來解決(如圖 5)。自適應批作業調度器的工作可以被認為是邁向它的第一步,因為自動重新平衡的要求類似于自適應批作業調度器,它們都需要動態圖的支持和結果分區大小的采集。
基于自適應批作業調度器的實現,我們可以通過增加最大并行度(為了更細粒度的子分區)和簡單地更改子分區范圍劃分算法(為了平衡工作負載)來解決上述問題。在目前的設計中,子分區范圍是按照子分區的個數來劃分的,我們可以改成按照子分區中的數據量來劃分,這樣每個子分區范圍內的數據量可以大致相同,從而平衡下游執行節點的工作量。

圖 5 - 自動負載均衡
注釋
[1] https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/deployment/elastic_scaling/#adaptive-batch-scheduler
[2] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobVertex.java
[3] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/jobgraph/JobGraph.java
[4] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionVertex.java
[5] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/executiongraph/ExecutionGraph.java
[6] https://nightlies.apache.org/flink/flink-docs-master/zh/docs/internals/job_scheduling/#jobmanager-數據結構
[7] https://github.com/apache/flink/blob/release-1.15/flink-runtime/src/main/java/org/apache/flink/runtime/scheduler/adaptivebatch/VertexParallelismDecider.java?