Go-Zero 的自適應熔斷器

這篇文章來說說熔斷。
熔斷和限流還不太一樣,限流是控制請求速率,只要還能承受,那么都會處理,但熔斷不是。
在一條調用鏈上,如果發現某個服務異常,比如響應超時。那么調用者為了避免過多請求導致資源消耗過大,最終引發系統雪崩,會直接返回錯誤,而不是瘋狂調用這個服務。
本篇文章會介紹主流熔斷器的工作原理,并且會借助 go-zero 源碼,分析 googleBreaker 是如何通過滑動窗口來統計流量,并且最終執行熔斷的。
工作原理
這部分主要介紹兩種熔斷器的工作原理,分別是 Netflix 開源的 Hystrix,其也是 Spring Cloud 默認的熔斷組件,和 Google 的自適應的熔斷器。
Hystrix is no longer in active development, and is currently in maintenance mode.
注意,Hystrix 官方已經宣布不再積極開發了,目前處在維護模式。
Hystrix 官方推薦替代的開源組件:Resilience4j,還有阿里開源的 Sentinel 也是不錯的替代品。
hystrixBreaker
Hystrix 采用了熔斷器模式,相當于電路中的保險絲,系統出現緊急問題,立刻禁止所有請求,已達到保護系統的作用。

系統需要維護三種狀態,分別是:
- 關閉: 默認狀態,所有請求全部能夠通過。當請求失敗數量增加,失敗率超過閾值時,會進入到斷開狀態。
- 斷開: 此狀態下,所有請求都會被攔截。當經過一段超時時間后,會進入到半斷開狀態。
- 半斷開: 此狀態下會允許一部分請求通過,并統計成功數量,當請求成功時,恢復到關閉狀態,否則繼續斷開。
通過狀態的變更,可以有效防止系統雪崩的問題。同時,在半斷開狀態下,又可以讓系統進行自我修復。
googleBreaker
googleBreaker 實現了一種自適應的熔斷模式,來看一下算法的計算公式,客戶端請求被拒絕的概率。

參數很少,也比較好理解:
- requests:請求數量。
- accepts:后端接收的請求數量。
- K:敏感度,一般推薦 1.5-2 之間。
通過分析公式,我們可以得到下面幾個結論,也就是產生熔斷的實際原理:
- 正常情況下,requests 和 accepts 是相等的,拒絕的概率就是 0,沒有產生熔斷。
- 當正常請求量,也就是 accepts 減少時,概率會逐漸增加,當概率大于 0 時,就會產生熔斷。如果 accepts 等于 0 了,則完全熔斷。
- 當服務恢復后,requests 和 accepts 的數量會同時增加,但由于 K * accepts 增長的更快,所以概率又會很快變回到 0,相當于關閉了熔斷。
總的來說,googleBreaker 的實現方案更加優雅,而且參數也少,不用維護那么多的狀態。
go-zero 就是采用了 googleBreaker 的方案,下面就來分析代碼,看看到底是怎么實現的。
接口設計
接口定義這部分我個人感覺還是挺不好理解的,看了好多遍才理清了它們之間的關系。
其實看代碼和看書是一樣的,書越看越薄,代碼會越看越短。剛開始看感覺代碼很長,隨著看懂的地方越來越多,明顯感覺代碼變短了。所以遇到不懂的代碼不要怕,反復看,總會看懂的。

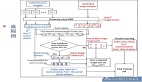
首先來看一下 breaker 部分的 UML 圖,有了這張圖,很多地方看起來還是相對清晰的,下面來詳細分析。
這里用到了靜態代理模式,也可以說是接口裝飾器,接下來就看看到底是怎么定義的:
// core/breaker/breaker.go
internalThrottle interface {
allow() (internalPromise, error)
doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
}
// core/breaker/googlebreaker.go
type googleBreaker struct {
k float64
stat *collection.RollingWindow
proba *mathx.Proba
}這個接口是最終實現熔斷方法的接口,由 googleBreaker 結構體實現。
// core/breaker/breaker.go
throttle interface {
allow() (Promise, error)
doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error
}
type loggedThrottle struct {
name string
internalThrottle
errWin *errorWindow
}
func newLoggedThrottle(name string, t internalThrottle) loggedThrottle {
return loggedThrottle{
name: name,
internalThrottle: t,
errWin: new(errorWindow),
}
}這個是實現了日志收集的結構體,首先它實現了 throttle 接口,然后它包含了一個字段 internalThrottle,相當于具體的熔斷方法是代理給 internalThrottle 來做的。
// core/breaker/breaker.go
func (lt loggedThrottle) allow() (Promise, error) {
promise, err := lt.internalThrottle.allow()
return promiseWithReason{
promise: promise,
errWin: lt.errWin,
}, lt.logError(err)
}
func (lt loggedThrottle) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
return lt.logError(lt.internalThrottle.doReq(req, fallback, func(err error) bool {
accept := acceptable(err)
if !accept && err != nil {
lt.errWin.add(err.Error())
}
return accept
}))
}所以當它執行相應方法時,都是直接調用 internalThrottle 接口的方法,然后再加上自己的邏輯。
這也就是代理所起到的作用,在不改變原方法的基礎上,擴展原方法的功能。
// core/breaker/breaker.go
circuitBreaker struct {
name string
throttle
}
// NewBreaker returns a Breaker object.
// opts can be used to customize the Breaker.
func NewBreaker(opts ...Option) Breaker {
var b circuitBreaker
for _, opt := range opts {
opt(&b)
}
if len(b.name) == 0 {
b.name = stringx.Rand()
}
b.throttle = newLoggedThrottle(b.name, newGoogleBreaker())
return &b
}最終的熔斷器又將功能代理給了 throttle。
這就是它們之間的關系,如果感覺有點亂的話,就反復看,看的次數多了,就清晰了。
日志收集
上文介紹過了,loggedThrottle 是為了記錄日志而設計的代理層,這部分內容來分析一下是如何記錄日志的。
// core/breaker/breaker.go
type errorWindow struct {
// 記錄日志的數組
reasons [numHistoryReasons]string
// 索引
index int
// 數組元素數量,小于等于 numHistoryReasons
count int
lock sync.Mutex
}
func (ew *errorWindow) add(reason string) {
ew.lock.Lock()
// 記錄錯誤日志內容
ew.reasons[ew.index] = fmt.Sprintf("%s %s", time.Now().Format(timeFormat), reason)
// 對 numHistoryReasons 進行取余來得到數組索引
ew.index = (ew.index + 1) % numHistoryReasons
ew.count = mathx.MinInt(ew.count+1, numHistoryReasons)
ew.lock.Unlock()
}
func (ew *errorWindow) String() string {
var reasons []string
ew.lock.Lock()
// reverse order
for i := ew.index - 1; i >= ew.index-ew.count; i-- {
reasons = append(reasons, ew.reasons[(i+numHistoryReasons)%numHistoryReasons])
}
ew.lock.Unlock()
return strings.Join(reasons, "\n")
}核心就是這里采用了一個環形數組,通過維護兩個字段來實現,分別是 index 和 count。
count 表示數組中元素的個數,最大值是數組的長度;index 是索引,每次 +1,然后對數組長度取余得到新索引。
我之前有一次面試就讓我設計一個環形數組,當時答的還不是很好,這次算是學會了。
滑動窗口
一般來說,想要判斷是否需要觸發熔斷,那么首先要知道一段時間的請求數量,一段時間內的數量統計可以使用滑動窗口來實現。
首先看一下滑動窗口的定義:
// core/collection/rollingwindow.go
type RollingWindow struct {
lock sync.RWMutex
// 窗口大小
size int
// 窗口數據容器
win *window
// 時間間隔
interval time.Duration
// 游標,用于定位當前應該寫入哪個 bucket
offset int
// 匯總數據時,是否忽略當前正在寫入桶的數據
// 某些場景下因為當前正在寫入的桶數據并沒有經過完整的窗口時間間隔
// 可能導致當前桶的統計并不準確
ignoreCurrent bool
// 最后寫入桶的時間
// 用于計算下一次寫入數據間隔最后一次寫入數據的之間
// 經過了多少個時間間隔
lastTime time.Duration // start time of the last bucket
}再來看一下 window 的結構:
type Bucket struct {
// 桶內值的和
Sum float64
// 桶內 add 次數
Count int64
}
func (b *Bucket) add(v float64) {
b.Sum += v
b.Count++
}
func (b *Bucket) reset() {
b.Sum = 0
b.Count = 0
}
type window struct {
// 桶,一個桶就是一個時間間隔
buckets []*Bucket
// 窗口大小,也就是桶的數量
size int
}有了這兩個結構之后,我們就可以畫出這個滑動窗口了,如圖所示。

現在來看一下向窗口中添加數據,是怎樣一個過程。
func (rw *RollingWindow) Add(v float64) {
rw.lock.Lock()
defer rw.lock.Unlock()
// 獲取當前寫入下標
rw.updateOffset()
// 向 bucket 中寫入數據
rw.win.add(rw.offset, v)
}
func (rw *RollingWindow) span() int {
// 計算距離 lastTime 經過了多少個時間間隔,也就是多少個桶
offset := int(timex.Since(rw.lastTime) / rw.interval)
// 如果在窗口范圍內,返回實際值,否則返回窗口大小
if 0 <= offset && offset < rw.size {
return offset
}
return rw.size
}
func (rw *RollingWindow) updateOffset() {
// 經過了多少個時間間隔,也就是多少個桶
span := rw.span()
// 還在同一單元時間內不需要更新
if span <= 0 {
return
}
offset := rw.offset
// reset expired buckets
// 這里是清除過期桶的數據
// 也是對數組大小進行取余的方式,類似上文介紹的環形數組
for i := 0; i < span; i++ {
rw.win.resetBucket((offset + i + 1) % rw.size)
}
// 更新游標
rw.offset = (offset + span) % rw.size
now := timex.Now()
// align to interval time boundary
// 這里應該是一個時間的對齊,保持在桶內指向位置是一致的
rw.lastTime = now - (now-rw.lastTime)%rw.interval
}
// 向桶內添加數據
func (w *window) add(offset int, v float64) {
// 根據 offset 對數組大小取余得到索引,然后添加數據
w.buckets[offset%w.size].add(v)
}
// 重置桶數據
func (w *window) resetBucket(offset int) {
w.buckets[offset%w.size].reset()
}我畫了一張圖,來模擬整個滑動過程:

主要經歷 4 個步驟:
- 計算當前時間距離上次添加時間經過了多少個時間間隔,也就是多少個 bucket。
- 清理過期桶數據。
- 更新 offset,更新 offset 的過程實際就是模擬窗口滑動的過程。
- 添加數據。
比如上圖,剛開始 offset 指向了 bucket[1],經過了兩個 span 之后,bucket[2] 和 bucket[3] 會被清空,同時,新的 offset 會指向 bucket[3],新添加的數據會寫入到 bucket[3]。
再來看看數據統計,也就是窗口內的有效數據量是多少。
// Reduce runs fn on all buckets, ignore current bucket if ignoreCurrent was set.
func (rw *RollingWindow) Reduce(fn func(b *Bucket)) {
rw.lock.RLock()
defer rw.lock.RUnlock()
var diff int
span := rw.span()
// ignore current bucket, because of partial data
if span == 0 && rw.ignoreCurrent {
diff = rw.size - 1
} else {
diff = rw.size - span
}
// 需要統計的 bucket 數量,窗口大小減去 span 數量
if diff > 0 {
// 獲取統計的起始位置,span 是已經被重置的 bucket
offset := (rw.offset + span + 1) % rw.size
rw.win.reduce(offset, diff, fn)
}
}
func (w *window) reduce(start, count int, fn func(b *Bucket)) {
for i := 0; i < count; i++ {
// 自定義統計函數
fn(w.buckets[(start+i)%w.size])
}
}統計出窗口數據之后,就可以判斷是否需要熔斷了。
執行熔斷
接下來就是執行熔斷了,主要就是看看自適應熔斷是如何實現的。
// core/breaker/googlebreaker.go
const (
// 250ms for bucket duration
window = time.Second * 10
buckets = 40
k = 1.5
protection = 5
)窗口的定義部分,整個窗口是 10s,然后分成 40 個 bucket,每個 bucket 就是 250ms。
// googleBreaker is a netflixBreaker pattern from google.
// see Client-Side Throttling section in https://landing.google.com/sre/sre-book/chapters/handling-overload/
type googleBreaker struct {
k float64
stat *collection.RollingWindow
proba *mathx.Proba
}
func (b *googleBreaker) accept() error {
// 獲取最近一段時間的統計數據
accepts, total := b.history()
// 根據上文提到的算法來計算一個概率
weightedAccepts := b.k * float64(accepts)
// https://landing.google.com/sre/sre-book/chapters/handling-overload/#eq2101
dropRatio := math.Max(0, (float64(total-protection)-weightedAccepts)/float64(total+1))
// 如果小于等于 0 直接通過,不熔斷
if dropRatio <= 0 {
return nil
}
// 隨機產生 0.0-1.0 之間的隨機數與上面計算出來的熔斷概率相比較
// 如果隨機數比熔斷概率小則進行熔斷
if b.proba.TrueOnProba(dropRatio) {
return ErrServiceUnavailable
}
return nil
}
func (b *googleBreaker) history() (accepts, total int64) {
b.stat.Reduce(func(b *collection.Bucket) {
accepts += int64(b.Sum)
total += b.Count
})
return
}以上就是自適應熔斷的邏輯,通過概率的比較來隨機淘汰掉部分請求,然后隨著服務恢復,淘汰的請求會逐漸變少,直至不淘汰。
func (b *googleBreaker) allow() (internalPromise, error) {
if err := b.accept(); err != nil {
return nil, err
}
// 返回一個 promise 異步回調對象,可由開發者自行決定是否上報結果到熔斷器
return googlePromise{
b: b,
}, nil
}
// req - 熔斷對象方法
// fallback - 自定義快速失敗函數,可對熔斷產生的err進行包裝后返回
// acceptable - 對本次未熔斷時執行請求的結果進行自定義的判定,比如可以針對http.code,rpc.code,body.code
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error {
if err := b.accept(); err != nil {
// 熔斷中,如果有自定義的fallback則執行
if fallback != nil {
return fallback(err)
}
return err
}
defer func() {
// 如果執行req()過程發生了panic,依然判定本次執行失敗上報至熔斷器
if e := recover(); e != nil {
b.markFailure()
panic(e)
}
}()
err := req()
// 上報結果
if acceptable(err) {
b.markSuccess()
} else {
b.markFailure()
}
return err
}熔斷器對外暴露兩種類型的方法:
簡單場景直接判斷對象是否被熔斷,執行請求后必須需手動上報執行結果至熔斷器。
func (b *googleBreaker) allow() (internalPromise, error)復雜場景下支持自定義快速失敗,自定義判定請求是否成功的熔斷方法,自動上報執行結果至熔斷器。
func (b *googleBreaker) doReq(req func() error, fallback func(err error) error, acceptable Acceptable) error個人感覺,熔斷這部分代碼,相較于前幾篇文章,理解起來是更困難的。但其中的一些設計思想,和底層的實現原理也是非常值得學習的,希望這篇文章能夠對大家有幫助。
參考文章:
- https://juejin.cn/post/7030997067560386590。
- https://go-zero.dev/docs/tutorials/service/governance/breaker。
- https://sre.google/sre-book/handling-overload/。
- https://martinfowler.com/bliki/CircuitBreaker.html。