?譯者 | 朱先忠
審校 | 孫淑娟
當前,數據領域的挑戰不再是海量數據的處理能力。現代流媒體平臺的高性能以及新一代數據存儲允許將計算與存儲層分離,使得我們可以通過非常低的操作工作量來提高系統的可伸縮性。
如果我們還記得著名的大數據“五V”(容量、價值、多樣性、速度和準確性,即“Volume, Value, Variety, Velocity, and Veracity”)的話,那么,我們今天應該更清醒地認識到,準確性和價值對于今天的大多數公司來說仍然是一個挑戰。
數據管道是解決這一挑戰的基礎。大規模設計和構建數據管道不僅可以提高系統的開發速度,而且可以讓整個團隊都可以參與維護和理解。
數據卷的處理能力
幾年前,大數據領域面臨的技術挑戰主要表現在以下領域:
- 數據存儲倉庫(體積和速度方面):接收和管理大量數據。
- 數據處理計算層(速度方面):需要高性能計算層來啟動數千條數據管道,允許以非常快速的方式接收大量數據。
- 集成適配器(類型方面):開發適配器以與不同類型的數據庫組件集成。
IT團隊在開始開發第一條數據管道之前,往往耗費數年時間構建支持這些功能的數據平臺。之后,所有的努力都集中于在短時間內接收大量的數據。但這一切都發生在沒有關注真實商業價值的情況下。此外,操作這些數據平臺往往需要付出巨大的努力。
現在,隨著云技術方案的應用——開源社區、最新一代云軟件和新的數據架構模式的出現等,實現上述這些功能不再成為一種挑戰。
數據存儲倉庫
當前,已經存在多種方法可以提供高性能數據存儲庫,以便以低操作工作量實時管理大量數據。
n 數據倉庫:新一代數據倉庫將存儲層與計算層分離,并提供基于不同技術的新的可擴展功能,如NoSQL、數據湖或具有AI功能的關系數據倉庫。
- 關系數據庫:使用分片和內存功能的最新關系數據庫,提供OLTP和OLAP功能。
- 流媒體平臺:Apache Kafka或Apache Pulsar等平臺,能夠提供每秒處理數百萬個事件的能力,并支持構建實時管道。
在這種情況下,成功的關鍵是為企業的應用場景選擇最佳方案的問題。
計算層
當前計算層能夠提供以下功能,以支持執行大量并發管道:
- 無服務器:云平臺提供了簡單的按需擴展。
- 新數據存儲庫的計算層:與存儲分離,允許在數據庫上執行大部分操作,而不會像舊的內部部署系統那樣影響其他負載或擴展限制。
- Kubernetes:我們可以使用Kubernetes API動態創建作業容器作為Kubernetes Pods。
集成適配器
開源社區與新的云軟件供應商一起,提供了各種數據適配器來快速提取和加載數據。這簡化了不同軟件組件(如數據存儲庫、ERP和許多其他組件)之間的集成。
當前面臨的數據挑戰
大數據公司當前面臨的關鍵挑戰是如何以更全面和可靠的方式提供數據。數據處理是復雜性的主要因素之一。作為數據或業務分析師,除了在正確的時間獲得信息外,我們還需要了解所分析數據的元數據,以便做出決策。
- 這些數據意味著什么?它提供了什么數值?(數值方面)
- 如何計算數據?(數值方面)
- 數據的來源是什么?(數值方面)
- 數據的更新程度如何?(準確性方面)
- 數據的質量如何?(準確性方面)
在大型企業中,存在很多數據,但也有很多部門有時使用相似但不同的數據。例如,零售公司有兩種類型的庫存:
- 額定庫存:該庫存是理論庫存,基于采購訂單和交貨單。
- 真實庫存:此庫存代表他們在倉庫和商店中擁有的物品。
通常,由于遞送延遲或其他人為錯誤等多方面的原因,這兩種數值并不匹配。但是,庫存數據是計算例如銷售、銷售預測或庫存補充等指標的主要依據。根據理論庫存購買新貨物的決定可能會給公司造成數千美元的損失,并導致一種不可持續的狀況。但事實情況是,我們只能想象這些決定對其他部門(例如庫存健康度)的影響。
當分析師做出決策時,他們需要知道他們正在使用哪些數據來評估風險并做出有意識的選擇。接下來,我們討論的是如何將數據轉換為業務價值的問題。
數據管道扮演什么角色?
當我們坐在辦公室想象數據(或者閱讀高級文章)時,我們常常想到的只是一個其中包含幾個數據域的非常簡單的世界:
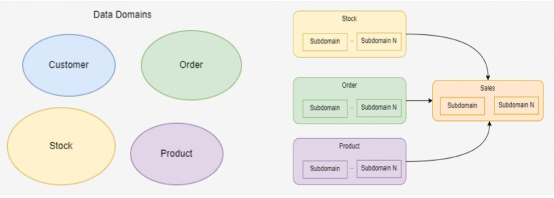
但現實情況往往遠比上面的情形更為復雜:
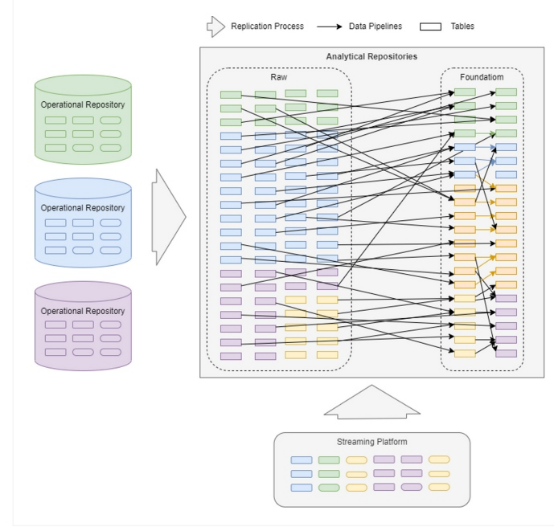
在大數據場景中,有數千條不同級別的數據管道在數據域或數據存儲庫之間不斷攝取和整合數據。數據管道是提供成功數據平臺的最重要組成部分之一;但是,即使在今天,我們在大規模構建數據管道方面也面臨著與多年前相同的挑戰,這體現在:
- 以動態和靈活的方式提供元數據,如歷史數據沿襲
- 實現數據分析師、數據工程師和公司股東之間的輕松協作
- 輕松向數據分析師和利益相關者提供有關數據質量和新鮮度的信息
大規模構建數據管道的挑戰是什么?
數據管道的目標主要集中在以下四個領域:
- 團隊協作和理解
- 動態數據沿襲
- 可觀測性
- 數據質量
團隊協作和理解
規則變化很快,公司必須快速適應。數據和信息比以往任何時候都更加重要。
為了快速提供價值,我們需要一個由數據科學家、數據工程師、分析師和公司股東組成的異構團隊共同工作。他們需要使用一種類似的語言才能變得更為敏捷。當我們所有的數據管道都使用Spark或Kafka Streams等技術構建時,技術人員和非技術人員之間的敏捷通信就太復雜了。
從數據到信息的旅程始于數據管道。
數據沿襲
元數據對于將數據轉換為業務信息非常重要。它提供了每個人都可以訪問的摘要沿襲,提高了數據的可見性、理解力和信心。我們必須動態提供這些信息,而不是通過永不改變的靜態文檔或永久持續的復雜檢查過程。
可觀測性
數據管道的可觀測性是一個重大挑戰。通常,可觀察性面向技術團隊,但我們需要提高所有利益相關者(業務分析師、數據分析師、數據科學家等)的可視性。
數據質量
我們需要改進我們處理數據的方式,并開始應用傳統軟件開發的最佳實踐。從數據到作為代碼的數據,我們可以借助版本控制、持續集成或測試等方法實現。
數據管道是如何發展的?
當我們研究新的數據技術趨勢時,我們可以觀察到存在于開源社區或商業軟件初創公司(如Airbyte、Meltano、dbt labs、DataHub或OpenLineage)中的一些積極舉措。
上面這些應用案例顯示了數據處理領域如何演變為:
- 利用新的數據存儲庫增強功能,從ETL(提取、轉換、加載)模型過渡到ELT(提取、加載、轉換)模型
- 提供以代碼形式管理數據的功能
- 提高數據理解和可觀察性
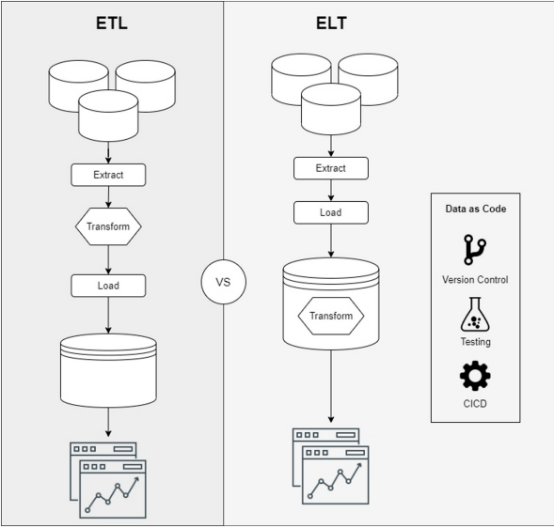
上述功能是使我們能夠大規模構建數據管道并提供業務價值的關鍵。
從數據準備到數據理解的歷程
理解是將數據轉化為信息的第一步。轉換層在這個過程中起著關鍵作用。通常,轉換層是瓶頸,因為數據工程師和業務分析師的語言不同,所以協作很復雜。然而,諸如dbt之類的新工具正試圖改進這一點。
什么是dbt?
dbt(數據構建工具,即“Data Build Tool”)是一種用于轉換層的開源CLI工具,它支持業務數據分析師和工程師在數據生命周期中使用通用語言以及軟件開發最佳實踐(如版本控制、連續集成/部署和連續測試)進行協作。
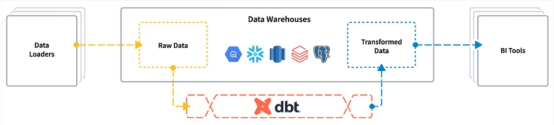
公司范圍內的通用語言
SQL是公司的通用語言,允許所有利益相關者在整個數據生命周期中參與討論。SQL使數據和業務分析師能夠使用版本控制工具通過SQL語句協作編寫或修改轉換。
ELT(提取、加載、轉換)
數據世界發生了很大變化。目前,大多數數據存儲庫都具有良好的性能和可擴展性。而且,新的場景改變了轉換過程的規則。在許多情況下,數據存儲庫比外部流程更適合工作。dbt執行ELT過程的轉換,利用新數據存儲庫的功能并在數據倉庫中運行數據轉換查詢。
數據作為代碼
dbt允許在Git存儲庫中以代碼的形式管理數據轉換,并應用持續集成最佳實踐。它提供了測試功能,包括基于SQL查詢的單元測試模塊,或使用宏對其進行擴展,以增加更復雜場景中的覆蓋率。
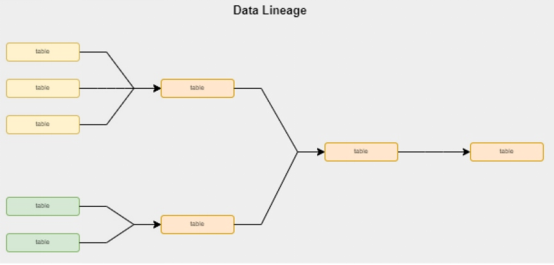
沿襲和元數據
dbt允許我們在每次運行數據轉換時動態生成數據沿襲和元數據。如今存在許多成熟的平臺(例如阿里云的DataHub或Datakin的OpenLineage)能夠與企業的業務進行集成,而且這些平臺都提供了豐富的企業可見性支持。
結論
近年來,很多大數據公司在提高數據處理性能和攝取能力方面都投入了大量精力,但質量和理解仍然是導致決策艱難的問題領域。如果我們不理解大量數據,或者數據質量很差,那么我們很快就會收到大量無關的數據。然而,為了提供增加業務價值的信息,必須有一層可擴展、可維護和可理解的數據管道。
請牢記:不做決定比根據不準確的數據做決定更好——尤其是當你沒有意識到數據是錯誤的時候。
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。早期專注各種微軟技術(編著成ASP.NET AJX、Cocos 2d-X相關三本技術圖書),近十多年投身于開源世界(熟悉流行全棧Web開發技術),了解基于OneNet/AliOS+Arduino/ESP32/樹莓派等物聯網開發技術與Scala+Hadoop+Spark+Flink等大數據開發技術。
原文標題:??Challenges to Designing Data Pipelines at Scale???,作者:Miguel Garcia?