













李飛飛團隊將ViT用在機器人身上,規劃推理最高提速512倍,還cue了何愷明的MAE
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
人類的預測能力+ViT,會產生什么樣的化學反應?
會讓機器人的行動規劃能力又快又準。

這是李飛飛團隊的最新研究——MaskViT,通過MVM,掩碼視覺建模對Transformer進行預訓練,從而建立視頻預測模型。

結果顯示,MaskViT不僅能生成256*256視頻,還可以讓機器人行動規劃的推理速度最高提高了512倍。


來看看這是項什么樣的研究?
從人類身上找靈感
神經科學領域的研究表明,人類的認知、感知能力是有一種預測機制來支持的。
這種對世界的預測模型,可以用來模擬、評估和選擇不同的可能行動。
對人類來說,這一過程是快速和準確的。
如果能賦予機器人類似的預測能力。那么他們就可以在復雜的動態環境中快速規劃、執行各類任務。
比如,通過視覺模型來預測控制,也許就是一種方式,但也對算力和準確性提出了更高的要求。
于是,李飛飛團隊就想到了最近諸多進展的ViT架構,以及以何愷明MAE為代表的基于MVM,Masked Visual Modeling這一自監督預訓練表征。
但具體要操作起來,仍有不少的技術挑戰。
一方面,全局注意力機制的復雜度與輸入序列長度的平方呈正比,導致視頻處理成本過高。
另一方面,視頻預測任務和自回歸掩碼視覺預訓練之間存在不一致。實際測試時,模型必須從頭預測完整的未來幀序列,導致視頻預測質量不好。
基于這樣的背景,李飛飛團隊提出了MaskViT——通過掩碼視覺建模對Transformer進行預訓練,從而建立視頻預測模型。

具體有兩種設計決策。
首先,為了提高記憶和訓練效率,使用了兩種類型的窗口注意力:空間注意力和時空注意力。
其次,訓練過程中掩碼的token比例是可變的。
在推理階段,視頻是通過迭代細化生成的,其中按照掩碼調度函數逐步降低掩碼率。

實驗結果
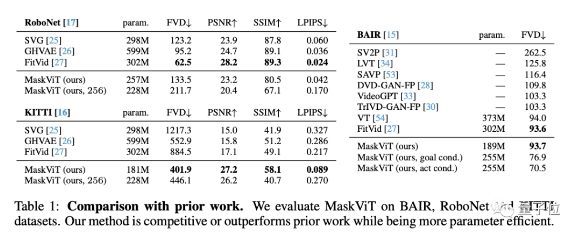
研究團隊在三個不同數據集,以及四個不同指標來評估了MaskViT。
結果顯示,跟以往先進的方法比較,MaskViT都表現出了更好的性能,可生成分辨率達256 × 256的視頻。

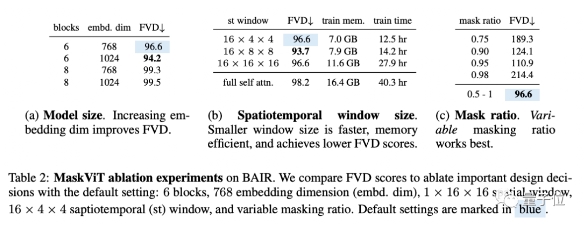
還在BAIR進行了消融實驗。

隨后,團隊還展示了真實機器人使用MaskViT進行實時規劃的效果。

推理速度最高可提升512倍。

研究人員表示,本次工作表明,可以通過最小的領域知識,利用掩碼視覺建模的一般框架,賦予像智能體強大的預測模型。
但同時表示,也具有一定的局限性。
比如在每幀量化時會出現閃爍偽影,尤其是在RoboNet這種有靜態背景的視頻中。

還有如果要擴大視頻預測的規模,也仍然具有挑戰性,特別是那種有大量攝像機運動的場景。
未來,他們將探索把這一視頻預測方法整合到更復雜的規劃算法中。
值得一提的是,在今年5月,何愷明團隊曾提出過視頻版MAE,并發現最佳掩蔽率高達 90%。

論文鏈接:
https://arxiv.org/abs/2206.11894
項目鏈接:
https://maskedvit.github.io/
何愷明論文:
https://arxiv.org/abs/2205.09113





























