何愷明組新論文:只用ViT做主干也可以做好目標檢測
研究概覽

論文鏈接:https://arxiv.org/pdf/2203.16527.pdf
當前的目標檢測器通常由一個與檢測任務無關的主干特征提取器和一組包含檢測專用先驗知識的頸部和頭部組成。頸部 / 頭部中的常見組件可能包括感興趣區域(RoI)操作、區域候選網絡(RPN)或錨、特征金字塔網絡(FPN)等。如果用于特定任務的頸部 / 頭部的設計與主干的設計解耦,它們可以并行發展。從經驗上看,目標檢測研究受益于對通用主干和檢測專用模塊的大量獨立探索。長期以來,由于卷積網絡的實際設計,這些主干一直是多尺度、分層的架構,這嚴重影響了用于多尺度(如 FPN)目標檢測的頸 / 頭的設計。
在過去的一年里,視覺 Transformer(ViT)已經成為視覺識別的強大支柱。與典型的 ConvNets 不同,最初的 ViT 是一種簡單的、非層次化的架構,始終保持單一尺度的特征圖。它的「極簡」追求在應用于目標檢測時遇到了挑戰,例如,我們如何通過上游預訓練的簡單主干來處理下游任務中的多尺度對象?簡單 ViT 用于高分辨率圖像檢測是否效率太低?放棄這種追求的一個解決方案是在主干中重新引入分層設計。這種解決方案,例如 Swin Transformer 和其他網絡,可以繼承基于 ConvNet 的檢測器設計,并已取得成功。
在這項工作中,何愷明等研究者追求的是一個不同的方向:探索僅使用普通、非分層主干的目標檢測器。如果這一方向取得成功,僅使用原始 ViT 主干進行目標檢測將成為可能。在這一方向上,預訓練設計將與微調需求解耦,上游與下游任務的獨立性將保持,就像基于 ConvNet 的研究一樣。這一方向也在一定程度上遵循了 ViT 的理念,即在追求通用特征的過程中減少歸納偏置。由于非局部自注意力計算可以學習平移等變特征,它們也可以從某種形式的監督或自我監督預訓練中學習尺度等變特征。
研究者表示,在這項研究中,他們的目標不是開發新的組件,而是通過最小的調整克服上述挑戰。具體來說,他們的檢測器僅從一個普通 ViT 主干的最后一個特征圖構建一個簡單的特征金字塔(如圖 1 所示)。這一方案放棄了 FPN 設計和分層主干的要求。為了有效地從高分辨率圖像中提取特征,他們的檢測器使用簡單的非重疊窗口注意力(沒有 shifting)。他們使用少量的跨窗口塊來傳播信息,這些塊可以是全局注意力或卷積。這些調整只在微調過程中進行,不會改變預訓練。
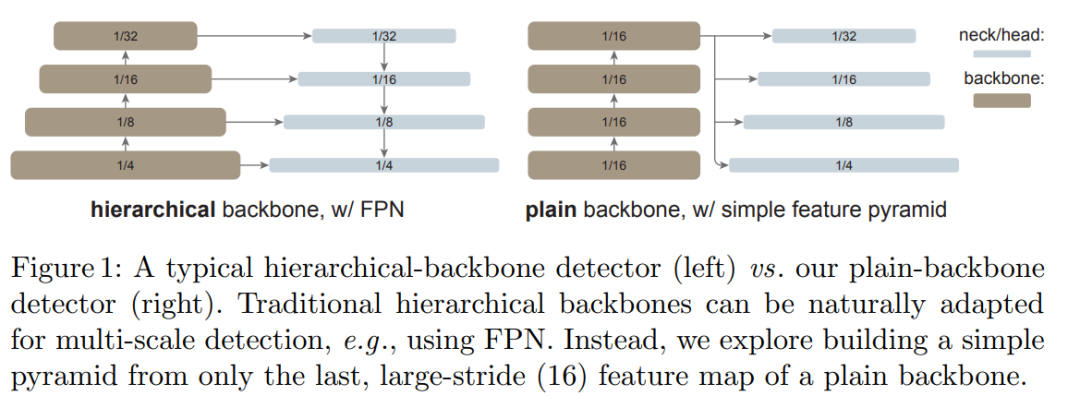
這種簡單的設計收獲了令人驚訝的結果。研究者發現,在使用普通 ViT 主干的情況下,FPN 的設計并不是必要的,它的好處可以通過由大步幅 (16)、單一尺度圖構建的簡單金字塔來有效地獲得。他們還發現,只要信息能在少量的層中很好地跨窗口傳播,窗口注意力就夠用了。
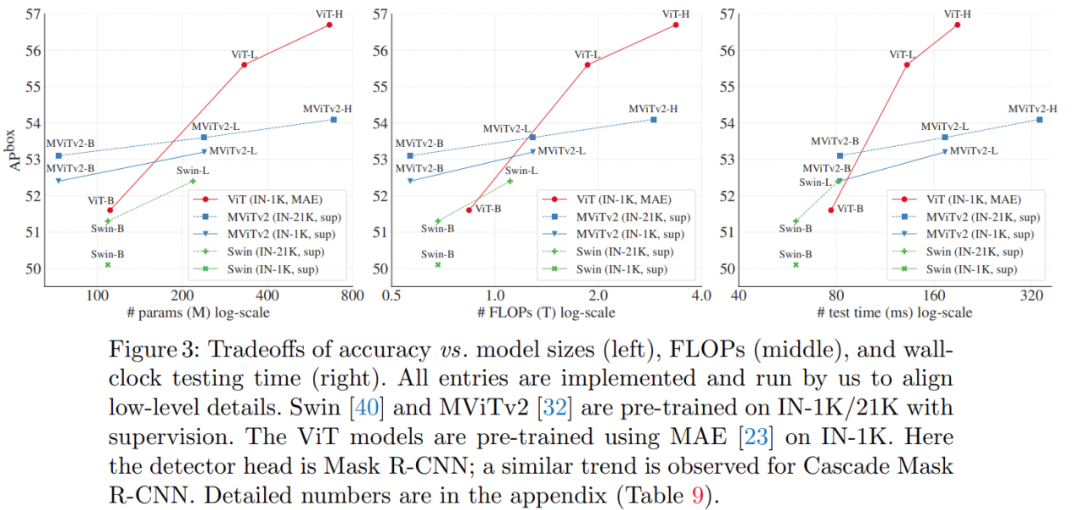
更令人驚訝的是,在某些情況下,研究者開發的名為「ViTDet」的普通主干檢測器可以媲美領先的分層主干檢測器(如 Swin、MViT)。通過掩蔽自編碼器(MAE)預訓練,他們的普通主干檢測器可以優于在 ImageNet-1K/21K 上進行有監督預訓練的分層檢測器(如下圖 3 所示)。
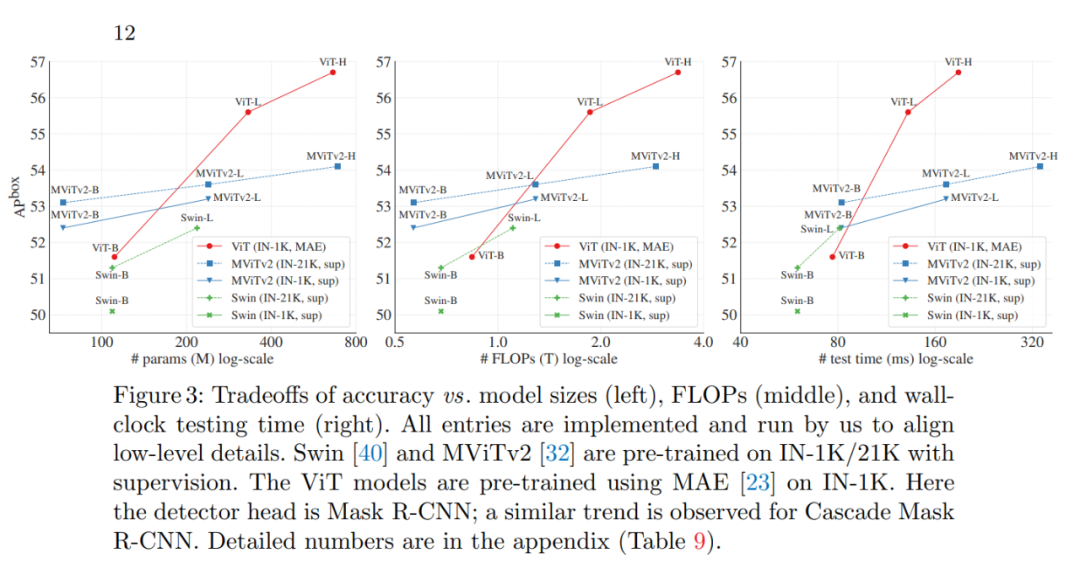
在較大尺寸的模型上,這種增益要更加顯著。該檢測器的優秀性能是在不同的目標檢測器框架下觀察到的,包括 Mask R-CNN、Cascade Mask R-CNN 以及它們的增強版本。
在 COCO 數據集上的實驗結果表明,一個使用無標簽 ImageNet-1K 預訓練、帶有普通 ViT-Huge 主干的 ViTDet 檢測器的 AP^box 可以達到 61.3。他們還在長尾 LVIS 檢測數據集上展示了 ViTDet 頗具競爭力的結果。雖然這些強有力的結果可能部分來自 MAE 預訓練的有效性,但這項研究表明,普通主干檢測器可能是有前途的,這挑戰了分層主干在目標檢測中的根深蒂固的地位。
方法細節
該研究的目標是消除對主干網絡的分層約束,并使用普通主干網絡進行目標檢測。因此,該研究的目標是用最少的改動,讓簡單的主干網絡在微調期間適應目標檢測任務。經過改動之后,原則上我們可以應用任何檢測器頭(detector head),研究者選擇使用 Mask R-CNN 及其擴展。
簡單的特征金字塔
FPN 是構建用于目標檢測的 in-network 金字塔的常見解決方案。如果主干網絡是分層的,FPN 的動機就是將早期高分辨率的特征和后期更強的特征結合起來。這在 FPN 中是通過自上而下(top-down)和橫向連接來實現的,如圖 1 左所示。
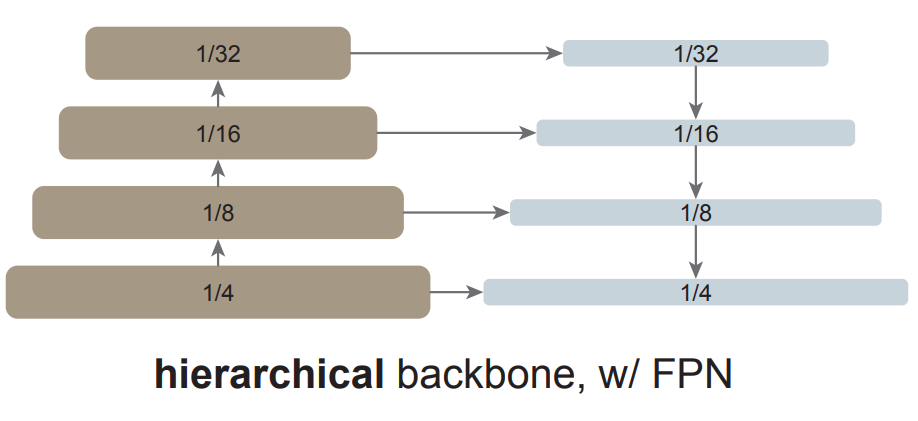
如果主干網絡不是分層網絡,那么 FPN 動機的基礎就會消失,因為主干網絡中的所有特征圖都具有相同的分辨率。該研究僅使用主干網絡中的最后一張特征圖,因為它應該具有最強大的特征。
研究者對最后一張特征圖并行應用一組卷積或反卷積來生成多尺度特征圖。具體來說,他們使用的是尺度為 1/16(stride = 16 )的默認 ViT 特征圖,該研究可如圖 1 右所示,這個過程被稱為「簡單的特征金字塔」。
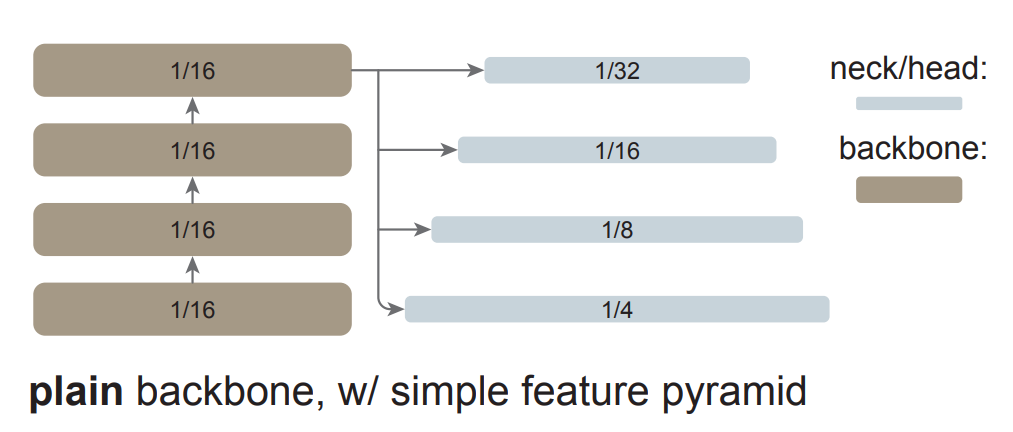
從單張特征圖構建多尺度特征圖的策略與 SSD 的策略有關,但該研究的場景涉及對深度、低分辨率的特征圖進行上采樣。在分層主干網絡中,上采樣通常用橫向連接進行輔助,但研究者通過實驗發現,在普通 ViT 主干網絡中橫向連接并不是必需的,簡單的反卷積就足夠了。研究者猜想這是因為 ViT 可以依賴位置嵌入來編碼位置,并且高維 ViT patch 嵌入不一定會丟棄信息。
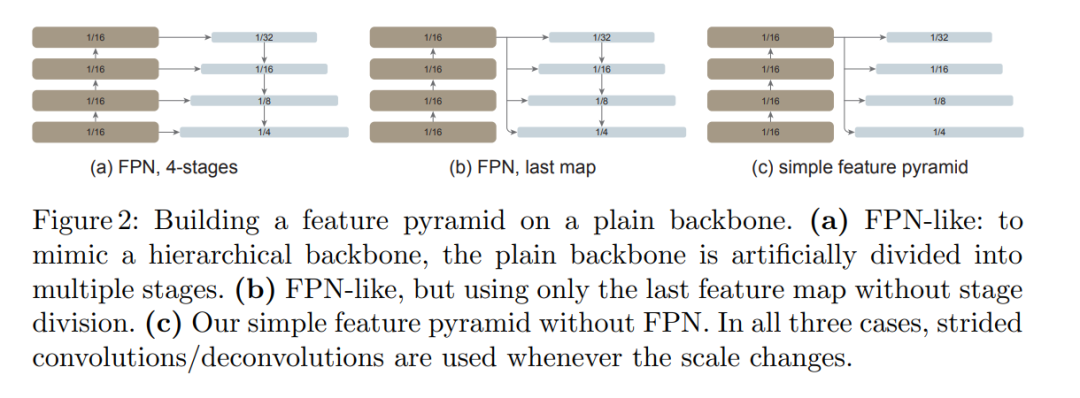
如下圖所示,該研究將這種簡單的特征金字塔與同樣建立在普通主干網絡上的兩個 FPN 變體進行比較。在第一個變體中,主干網絡被人為地劃分為多個階段,以模仿分層主干網絡的各個階段,并應用橫向和自上而下的連接(圖 2(a))。第二個變體與第一個變體類似,但僅使用最后一張特征圖(圖 2(b))。該研究表明這些 FPN 變體不是必需的。
主干網絡調整
目標檢測器受益于高分辨率輸入圖像,但在整個主干網絡中,計算全局自注意力對于內存的要求非常高,而且速度很慢。該研究重點關注預訓練主干網絡執行全局自注意力的場景,然后在微調期間適應更高分辨率的輸入。這與最近使用主干網絡預訓練直接修改注意力計算的方法形成對比。該研究的場景使得研究者能夠使用原始 ViT 主干網絡進行檢測,而無需重新設計預訓練架構。
該研究探索了使用跨窗口塊的窗口注意力。在微調期間,給定高分辨率特征圖,該研究將其劃分為常規的非重疊窗口。在每個窗口內計算自注意力,這在原始 Transformer 中被稱為「受限」自注意力。
與 Swin 不同,該方法不會跨層「移動(shift)」窗口。為了允許信息傳播,該研究使用了極少數(默認為 4 個)可跨窗口的塊。研究者將預訓練的主干網絡平均分成 4 個塊的子集(例如對于 24 塊的 ViT-L,每個子集中包含 6 個),并在每個子集的最后一個塊中應用傳播策略。研究者分析了如下兩種策略:
- 全局傳播。該策略在每個子集的最后一個塊中執行全局自注意力。由于全局塊的數量很少,內存和計算成本是可行的。這類似于(Li et al., 2021 )中與 FPN 聯合使用的混合窗口注意力。
- 卷積傳播。該策略在每個子集之后添加一個額外的卷積塊來作為替代。卷積塊是一個殘差塊,由一個或多個卷積和一個 identity shortcut 組成。該塊中的最后一層被初始化為零,因此該塊的初始狀態是一個 identity。將塊初始化為 identity 使得該研究能夠將其插入到預訓練主干網絡中的任何位置,而不會破壞主干網絡的初始狀態。
這種主干網絡的調整非常簡單,并且使檢測微調與全局自注意力預訓練兼容,也就沒有必要重新設計預訓練架構。
實驗結果
消融研究
在消融研究中,研究者得到了以下結論:
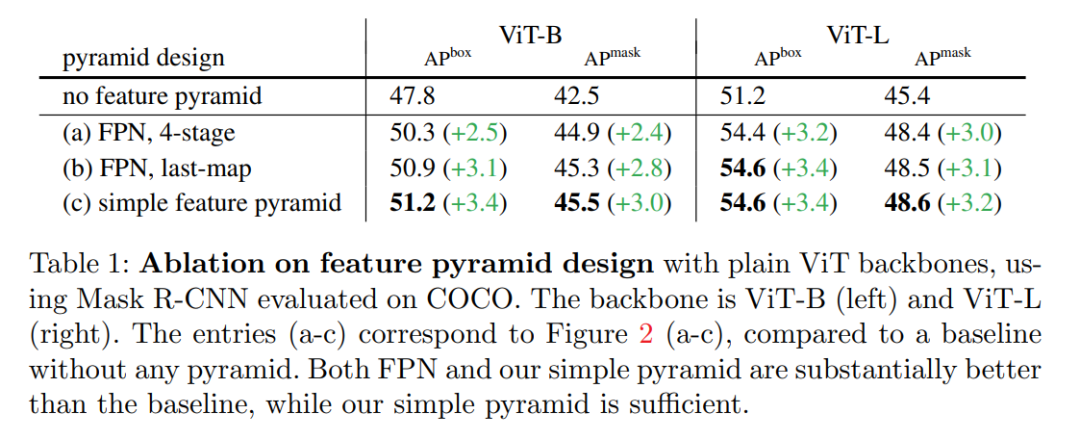
1、一個簡單的特征金字塔就足夠了。在表 1 中,他們比較了圖 2 所示的特征金字塔構建策略。
2、在幾個傳播塊的幫助下,窗口注意力就足夠了。表 2 總結了本文提出的主干調整方法。簡而言之,與只有窗口注意力、無跨窗口傳播塊的基線(圖中的「none」)相比,各種傳播方式都可以帶來可觀的收益。
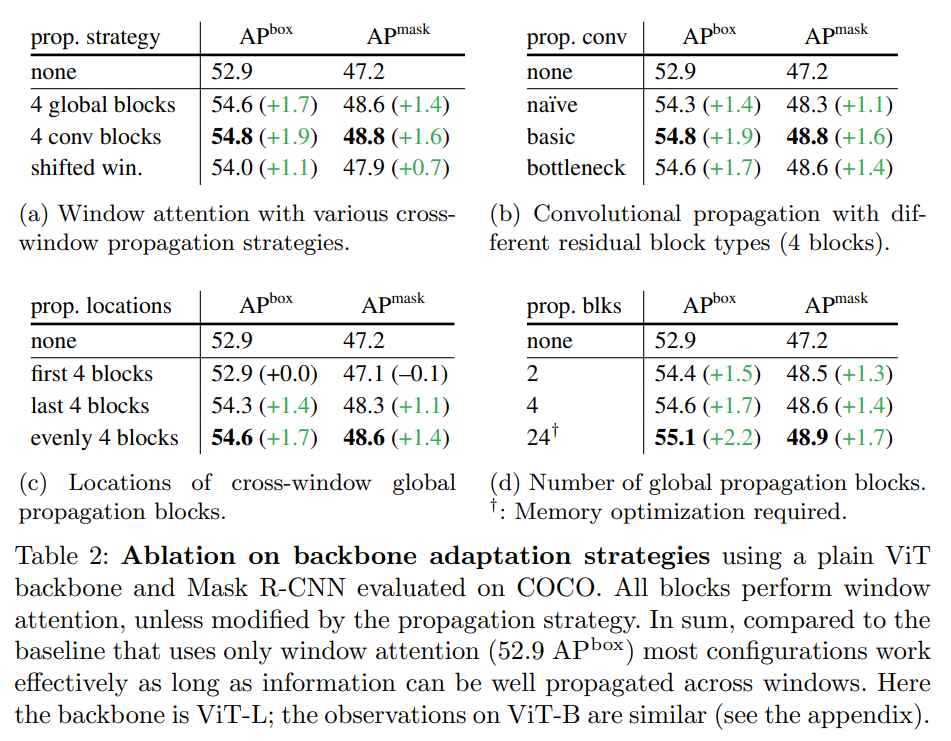
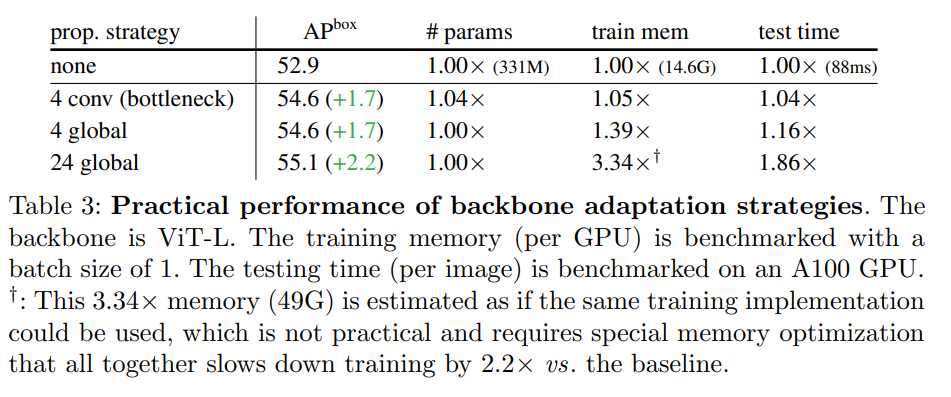
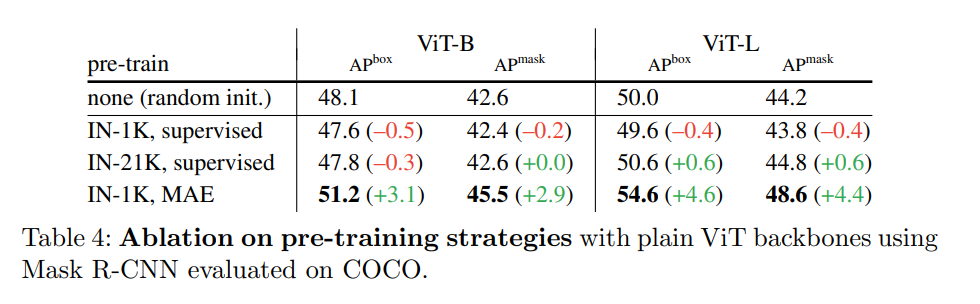
3、掩蔽自編碼器可以提供強大的預訓練主干。表 4 比較了主干預訓練的策略。
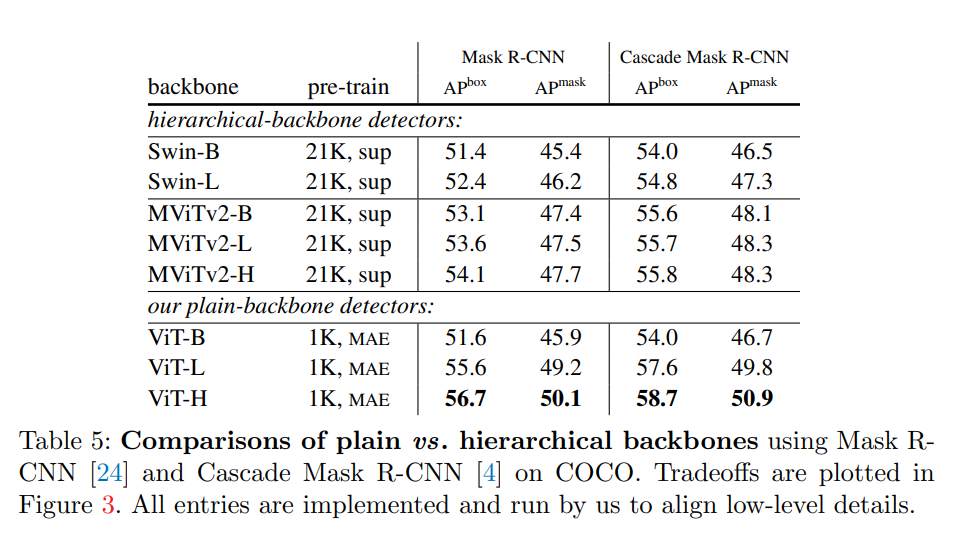
與分層主干的對比
下表 5 顯示了與分層主干網絡的比較結果。
下圖 3 顯示了幾種模型的準確率與模型尺寸、FLOPs 和測試時間三者的關系。
與之前系統的對比
下表 6 給出了幾種方法在 COCO 數據集上的系統級比較結果。