我是如何將一個老系統的Kafka消費者服務的性能提升近百倍的?
如果問你,如何提高kafka隊列中的消息消費速度呢?
答案很簡單,topic多分幾個分片,然后使用消費者組(Consumer Group)去消費topic即可。
如果加個條件,對同一個對象的操作請求必須要嚴格按照順序進行處理呢?
答案也不難,topic分片之后,生產者定制分發策略,保證同一對象的操作請求都分發到同一個分片中,這樣每個消費者就都是在按照順序消費各自分片中的數據啦~
如果再加上一些條件:
這個消費者消費速度極慢、慢到需要100ms才能處理完一條消息,即使topic分100片也不滿足不了要求;
每個對象的操作請求數量存在嚴重傾斜的現象,有的分片消息數量很大,有的分片消息量很少,可能有的分片一直積壓、有的分片卻很閑;
請求操作很重要,需要確保每條請求都被可靠消費,要保證事務最終一致性;
數十年的老系統,業務錯綜復雜,項目方不允許涉及業務邏輯以及整體架構的大改…
當上述各種條件疊加到一起,要求將消費性能明顯提升,如果是你,會如何破局呢?

前段時間,應業務部門的要求,給他們的一個線上歷史系統做個并發性能提升的方案,就遇到了上述各種要求疊加在一起的棘手情況。
先簡單說下遇到的業務場景:
一個互動類的論壇的帖子評論處理場景,要求每個帖子的評論請求操作都必須要嚴格遵循一定的順序(比如可能會有評論刪除、引用評論、回復評論等操作,所以請求順序必須要嚴格按照順序處理),帖子評論的操作請求發送到kafka里面,然后評論服務消費kafka處理各個請求,這個評論消費者服務消費太慢,需要提升下并發效率。
增加分片與消費者數量
正式開始著手去整改優化。
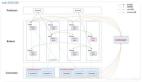
首先是常規調整:根據kafka自身的機制,將topic進行分片調整,拆分為N個分片,然后增設消費者組,在消費者組內部署與分片數相等的消費者服務節點,這樣每個消費者可以處理一個分片,這樣整個評論的消費性能就會提升N倍。

那么,這里為什么要強調消費者組里的服務節點數要等于topic分片數呢?這里提一下kafka中Consumer Group中消費者數量與topic分片數之間的相關邏輯。
看一下不同的消費者數量與topic分片數對應的處理消費場景:


所以說,消費者組里面的消費者數量并不是越多越好,而是受到了topic的分片數量的限制的:
消費者數量太少,會導致一個消費者需要消費多個分片的數據,造成某一個消費者消費壓力提升;
消費者數量太多,會導致有的消費者并不會消費任何數據,浪費部署資源。
也是基于這一點,上述我們的方案中,規劃消費者組里的消費者數量與topic的分片數一致,這樣可以保證每個消費者消費1個分片,達到最大效率協調。
再補充個知識點:為什么kafka要限制每個分片最多只能有1個消費者組里的消費者在處理呢?
因為消費者拉取消息需要提供offset, limit。如果offset放在broker端,那么一定會產生額外的通信開銷;如果offset放在Consumer端,如果在一個組有多個消費者,就需要有一個協調者,集中式的管理,解決鎖沖突,如果不解決沖突,那么勢必會產生重復消費、無用的消費,從而導致資源浪費。所以說,從性能與復雜度的取舍上,Kafka采用了相對簡單的一種解決策略。
保證分片內寫入順序
通過上一章的方式,增加了topic分區數以及消費者組中消費者數量,對kafka中消息并行消費的效率是提升了,但是問題又來了:順序問題!
前面說過,由于業務明確要求確保順序消費,而kafka只是保證分片內的消費順序是固定的,但是不同分片之間的消費順序是無法保證的。
對業務進行分析發現,業務要求的順序處理,其實是有條件的順序處理。即對于同一個帖子的所有評論相關的操作必須要同步處理,對于不同帖子的評論相關操作并沒有順序的要求。那么問題就簡單了,只要保證同一個帖子的所有評論相關操作請求都被分發到同一個topic分區內即可!
生產者寫入消息到kafka的topic時,kafka將依據不同的策略將數據分配到不同的分區中:
- 輪詢分區策略
- 隨機分區策略
- 按key分區分配策略
- 自定義分區策略
這里采用自定義分區策略,因為每個評論操作請求中都攜帶有一個原始帖子ID字段,所以分發策略也很簡單,直接帖子ID % 分片數將消息進行分發,這樣同一個帖子ID的評論操作就都可以到同一個分片中,這樣順序的問題就解決了。

所以,對上一環節給定的初步方案進行優化,補充下生產者端的定制化分發策略的要求,保證同一個帖子的評論操作都會到同一個Topic分片中:

方案設計到這里,似乎已經是解決了并發消費的問題了。但是后來實際壓測之后,結果令人大跌眼鏡。
單消費者速度提升
按照前面給出的方案,部署了DEMO環境進行壓測(拆分成4個分片,部署4個消費者),最終發現集群消費速度的確是翻了4倍、但是整體并發量依舊是低的可憐,4臺機器最終消費并發量甚至不到100!?
心靈受到暴擊之后,去分析下單個消費者節點的運行情況,發現壓測過程中整個機器CPU、IO、MEM、線程數都非常低、毫無任何波動。問業務方要了代碼權限,下載了代碼并走讀了一遍Consumer服務的代碼邏輯才發現其中玄機。
其實該業務整體交互邏輯其實很簡單,從kafka獲取一個消息,然后進行消費。但是這個消費邏輯,是需要按順序調用10余個周邊系統的HTTP接口!這也難怪CPU、內存、IO都非常低了,整個進程中只有一個線程在處理業務、而這個線程大部分時間都是處于IO等待狀態。
所以要想提升整體集群的消費能力,要么無限擴機器、要么就提升單節點的消費能力 —— 顯然前者是不可能的,只能選擇后者。而對于單線程、多IO操作的場景,提升并發性能,首先想到的就是改為多線程并發處理。但是多線程并發的時候,又會涉及到如何保證順序消費的問題。
對前面的方案進行優化,給出如下方案:

在前面方案的基礎上,主要是對消費者端的實現邏輯進行了調整:
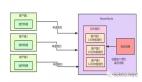
在消費者內部,區分Consumer Thread和Work Thread,Consumer Thread負責從kafka拉取消息,而Work Thread負責真正的消費邏輯處理。
單機內存中維護若干個隊列,每個隊列對應一個Work Thread,負責消費該隊列中的數據;
Consumer Thread基于親緣性分發策略對消息進行二次分發,保證相同帖子ID的請求分發到不同的內部隊列中。
再進行壓測,設置單個消費者服務Work Thread數量為100,集群內4個消費者服務,整體消費速度達到了7000。單節點的消費性能從原來的20提升到1700,提升了近80倍!
如何保證消息不丟失
經過將單機的消費模式改為多線程的方式,目前并發消費性能的問題是解決了,可是可靠性的問題又出現了。
原先的時候,消費者從kafka拉取一條消息,然后消費完成后,給kafka一個ack應答,然后去拉取下一條消息,這樣即使消費者中途宕機了,kafka依舊可以將消息分發給下一個可用的消費者去處理,可以保證請求消息不會丟失掉。
而前面的方案,消費者服務從kafka拉取到消息之后,并沒有等待處理完成,就繼續從kafka拉取消息然后緩存在本機內存中等待work thread慢慢消費,這個時候,如果機器宕機,所有緩存的消息將全部丟失!
為了解決上述問題,考慮將kafka應答機制改為手動提交ack。但是由于多個線程之間亂序的處理kafka上的數據,各個線程已經處理的offset值是不一樣的。如下示意圖:

為了保證消息可靠不丟失,采用如下策略:定期手動提交當前的offset信息,提交的offset值,選擇當前節點已處理的最小offset值(對于上面示意圖,即提交1002這個offset值),可以通過在內存中緩存下處理的offset列表的方式實現,如下如實現策略:

正常情況下,提交的offset值不會有什么作用或影響,但是一旦出現異常情況,導致當前節點進程不可用,kafka重平衡將當前分片分給另一個消費者進行消費的時候,另一個消費者會從最后一次提交的offset位置開始繼續往后消費。這樣便解決了數據丟失的問題,保證了數據可靠。
但是,另一個問題又出現了:重復消費。好在,雖然這個業務系統是十多年前構建的,但是至少分布式消費者該有的一個關鍵特性還是具備的,那就是冪等,所以這個問題就不用考慮了。
數據積壓不可控場景兜底
到這里,總該一切都沒問題了吧?
是,也不是。正常情況下是沒問題了,但是作為一個"核心"系統,極端的異常情況的保命策略還需要考慮下。
舉個例子,如果突然有一條帖子爆火,這條帖子的評論量遠超其余帖子的評論量,甚至遠超整個系統的額定最大負載請求量,這樣會出現個問題:
- kafka某一個分片數據量積壓嚴重,其余分片很空閑
- 該條火爆的帖子的相關評論請求,阻塞了與該帖子分配到同一分區的其余帖子的評論處理。
這個原計劃做一個動態伸縮的分片分發策略,但考慮到此場景過于極端,當前系統實施起來性價比不高,所以本著適當設計的原則,放棄了原先方案,改為了簡單的手動處理 + 補償服務方式,如下:

一旦出現未預料到的異常,導致系統積壓已經超過正常的處理范圍了,且已經遠超系統可以正常恢復的限度,為了保證現有業務盡快的恢復正常,可以先跳過積壓的請求,先保證新過來的請求正常被處理,然后啟動補償進程,慢慢消費之前積壓的消息。
有一說一:
這個地方是整個方案里面我自己不太滿意的一個實現,屬于遷就現實的一種妥協方案,寫這篇文檔的時候,自己還是打算近期將這部分按照一個更優的方案進行實現。如果您也有興趣了解或者有更好的建議思路,歡迎聯系我,我們一起掰扯下。
總結梳理
至此呢,為了解決kafka消費者消費能力太慢場景的集群并發性能提升方案就全部設計完成了,業務要求的各種要求約束也都可以滿足了,最終實現了在業務邏輯沒有變的情況下,整體集群的性能提升了上百倍。整體的改動內容如下: